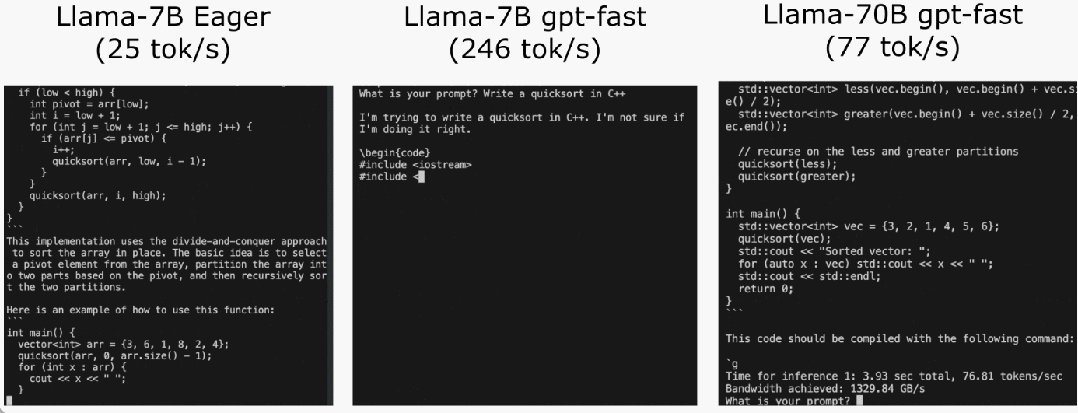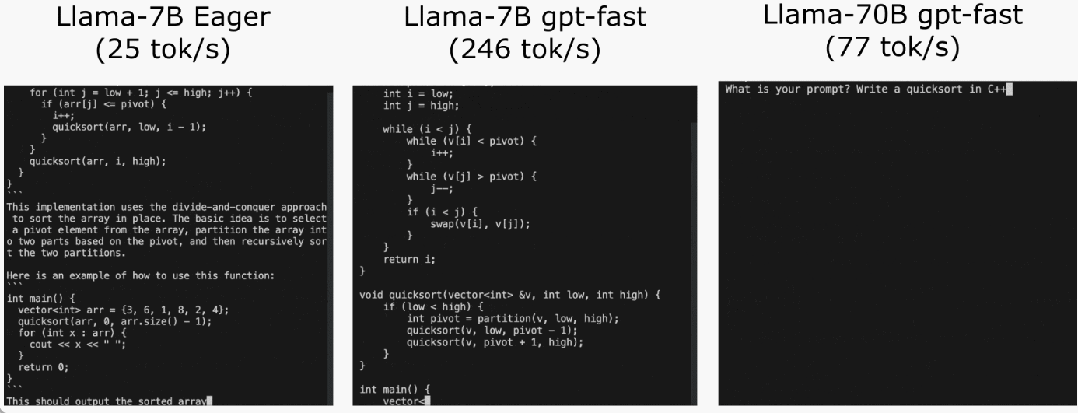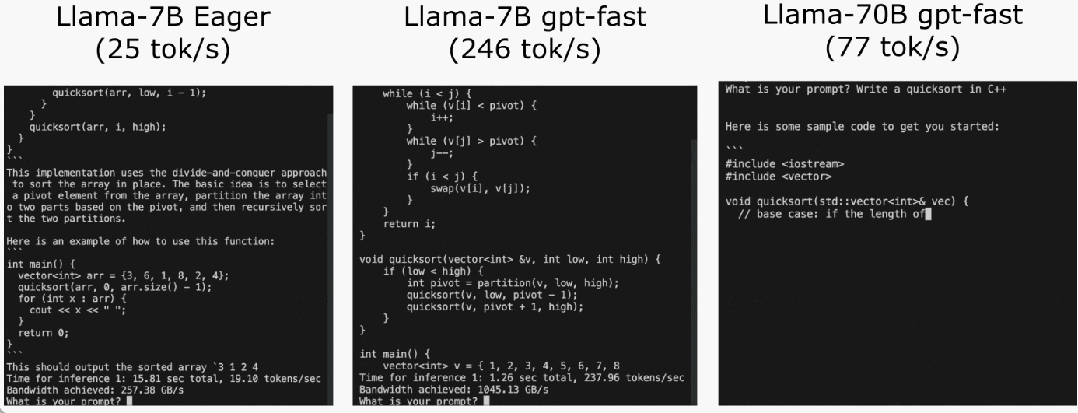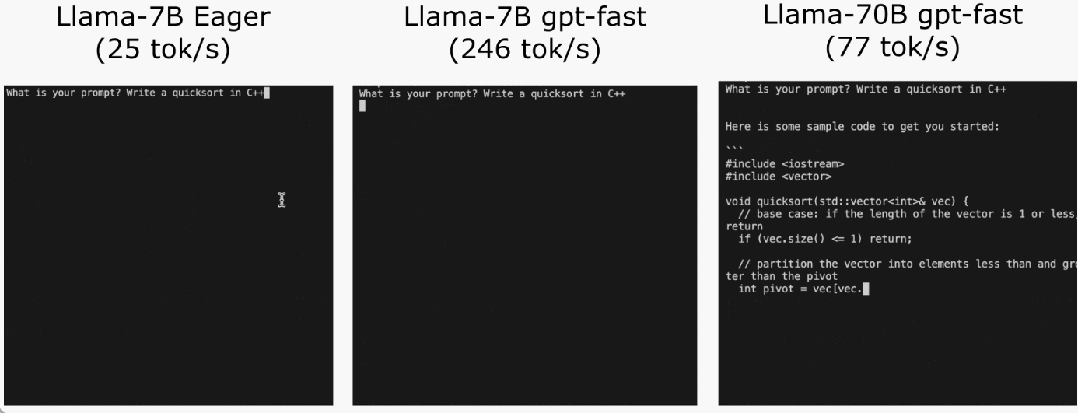
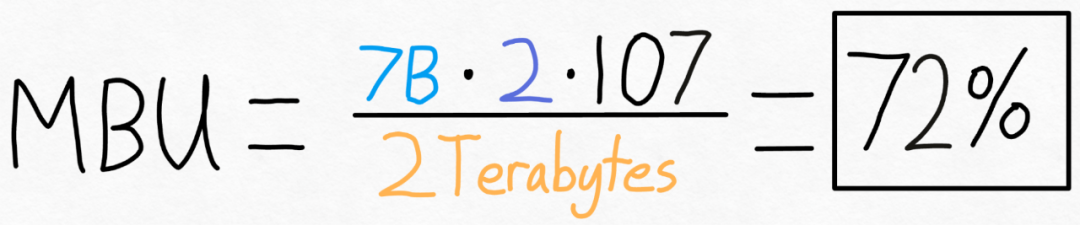PyTorch 팀이 대규모 모델 추론을 가속화하는 방법을 직접 가르쳐드립니다.
지난해 생성 AI가 빠르게 발전했습니다. 그 중에서도 텍스트 생성은 항상 llama.cpp, vLLM, MLC-LLM 등과 같은 많은 오픈 소스 프로젝트에서 이루어졌습니다. 더 나은 결과를 얻기 위해 지속적인 최적화가 진행되고 있습니다. 기계 학습 커뮤니티에서 가장 인기 있는 프레임워크 중 하나인 PyTorch는 자연스럽게 이 새로운 기회를 포착하고 지속적으로 최적화했습니다. 모든 사람이 이러한 혁신을 더 잘 이해할 수 있도록 PyTorch 팀은 순수 네이티브 PyTorch를 사용하여 생성 AI 모델을 가속화하는 방법에 초점을 맞춘 일련의 블로그를 특별히 설정했습니다. 
코드 주소: https://github.com/pytorch-labs/gpt-fast 먼저 결과를 살펴보겠습니다. 팀은 LLM을 다시 작성했으며 1000줄 미만의 순수 네이티브 PyTorch 코드를 사용하여 정확도를 잃지 않고 추론 속도가 기준보다 10배 더 빨랐습니다!
모든 벤치마크는 A100-80GB에서 실행되었으며 전력은 330W로 제한됩니다.
- Torch.compile: PyTorch 모델 컴파일러인 PyTorch 2.0에는 한 줄의 코드로 기존 모델을 컴파일할 수 있는 torch.compile()이라는 새로운 함수가 추가되었습니다. 모델
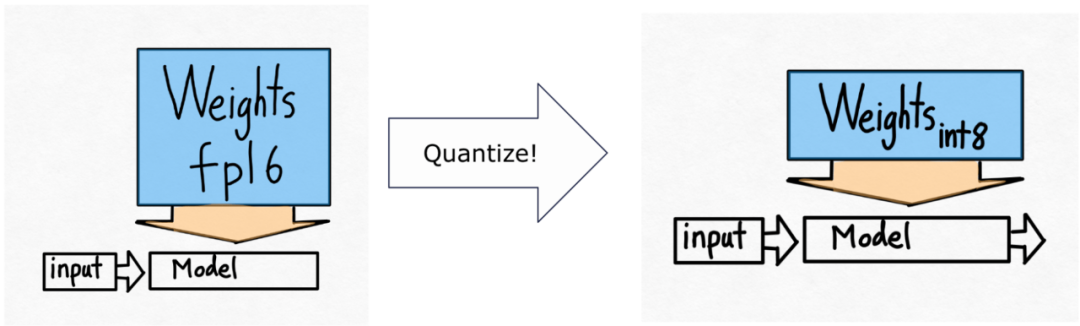
- GPU 양자화: 계산 정확도를 줄여 모델을 가속화합니다.
- 예측 디코딩: 모델의 큰 "목표" 출력을 예측하기 위해 작은 "초안" 모델을 사용하는 대규모 모델 추론 가속 방법.
- Tensor 병렬: 여러 장치에서 모델을 실행하여 모델 추론을 가속화합니다.
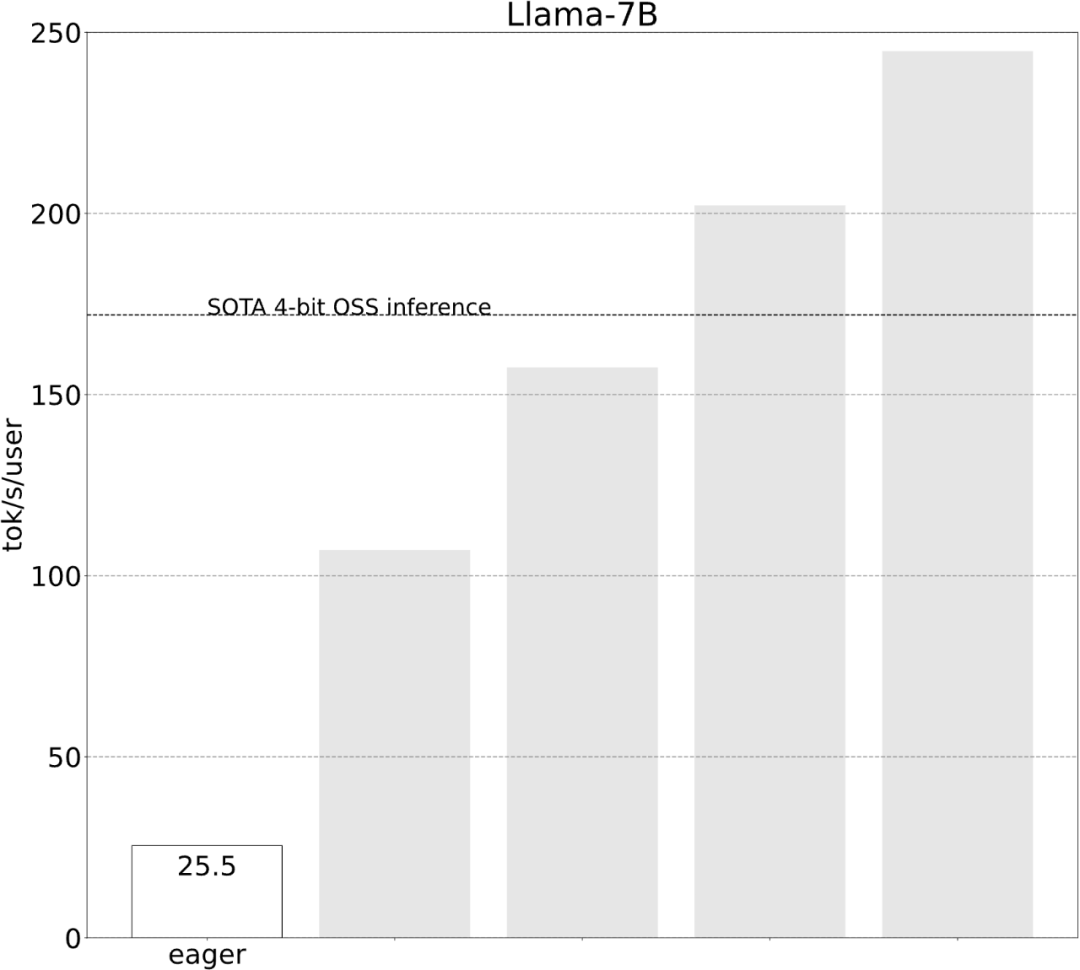
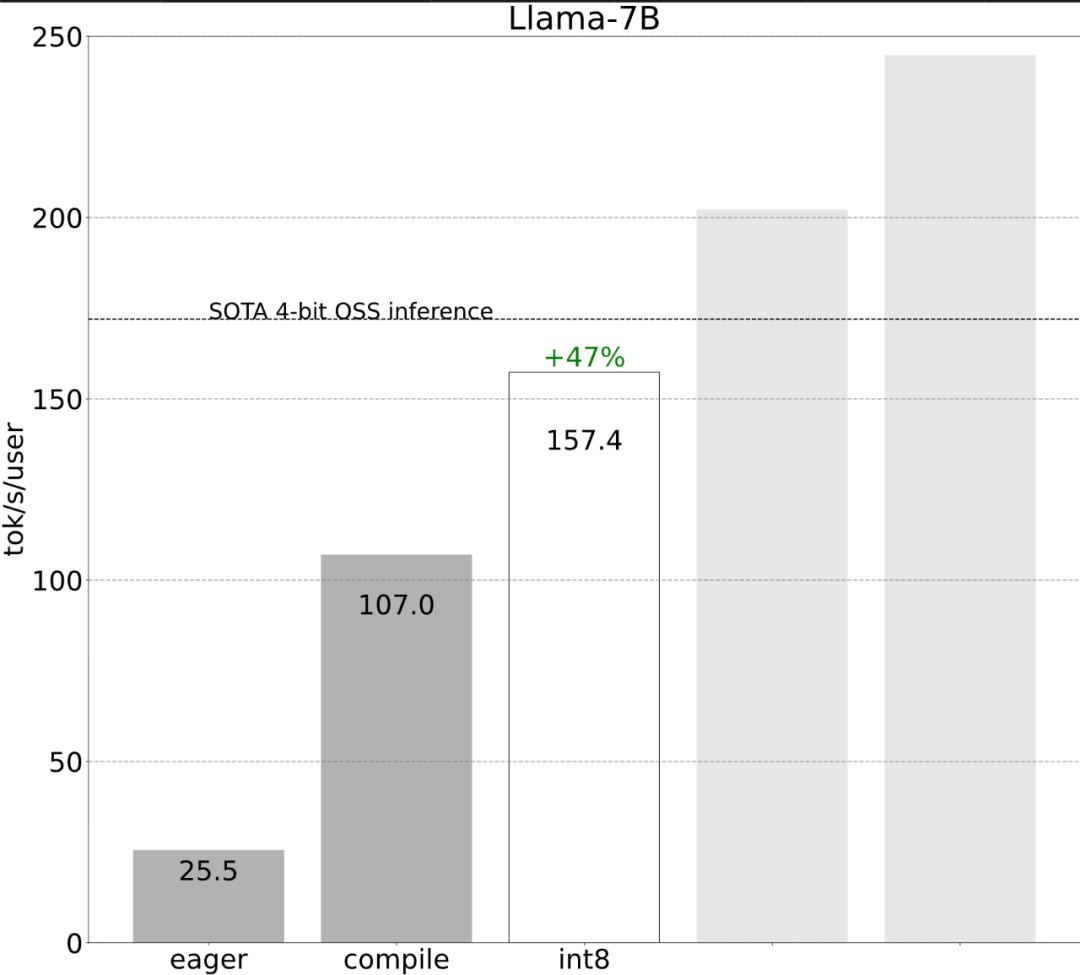
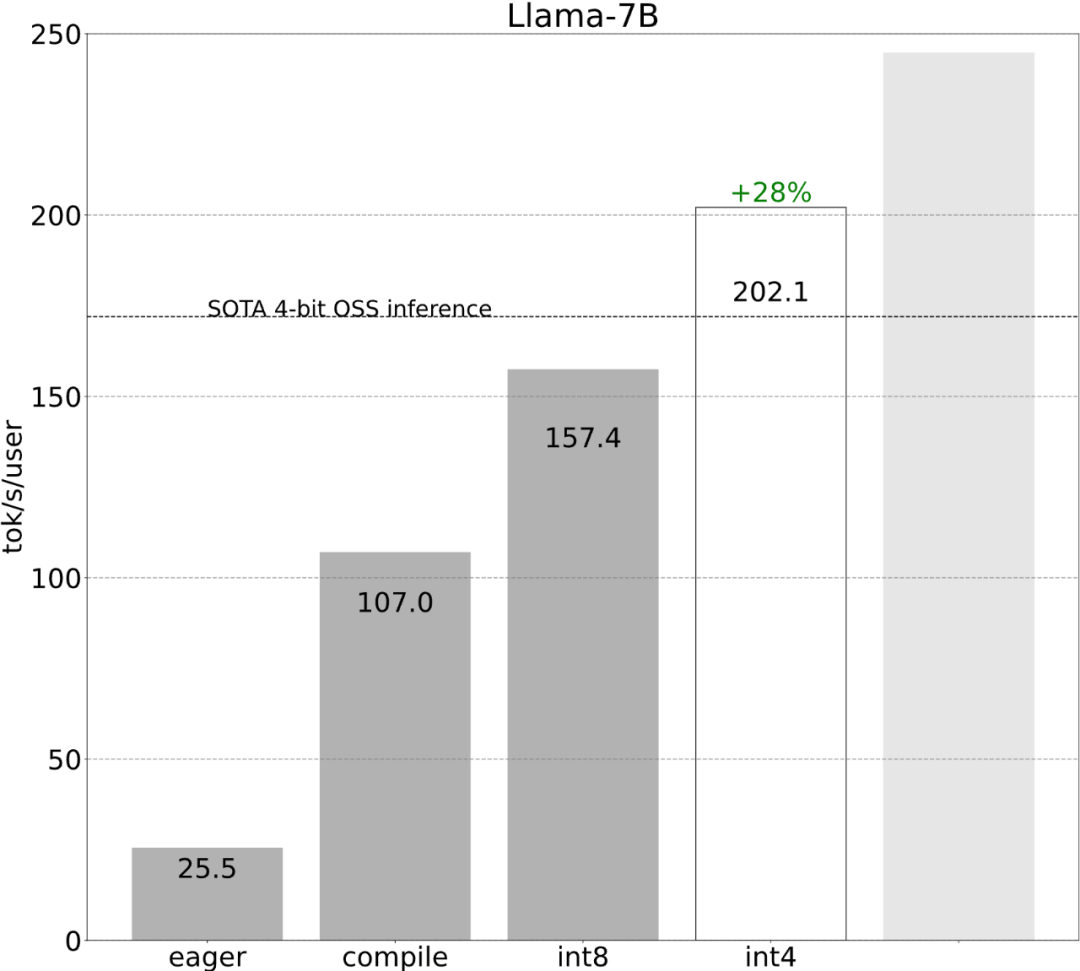
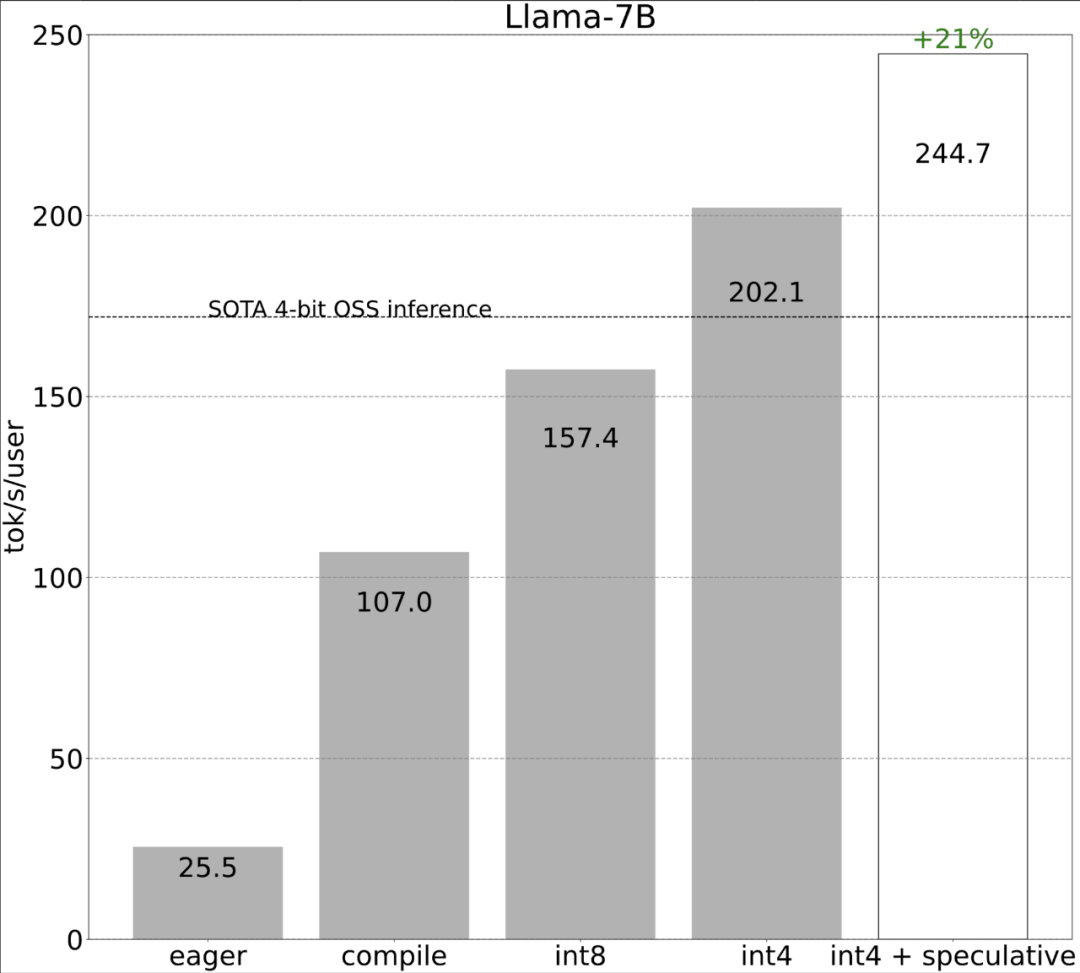
다음으로 각 단계가 어떻게 구현되는지 살펴보겠습니다. 연구에 따르면 최적화 전 대형 모델의 추론 성능은 25.5tok/s로 그다지 좋지 않습니다.
몇 가지 탐색 끝에 마침내 이유를 발견했습니다. 바로 과도한 CPU 오버헤드였습니다. 그 다음에는 다음과 같은 6단계 최적화 프로세스가 있습니다.
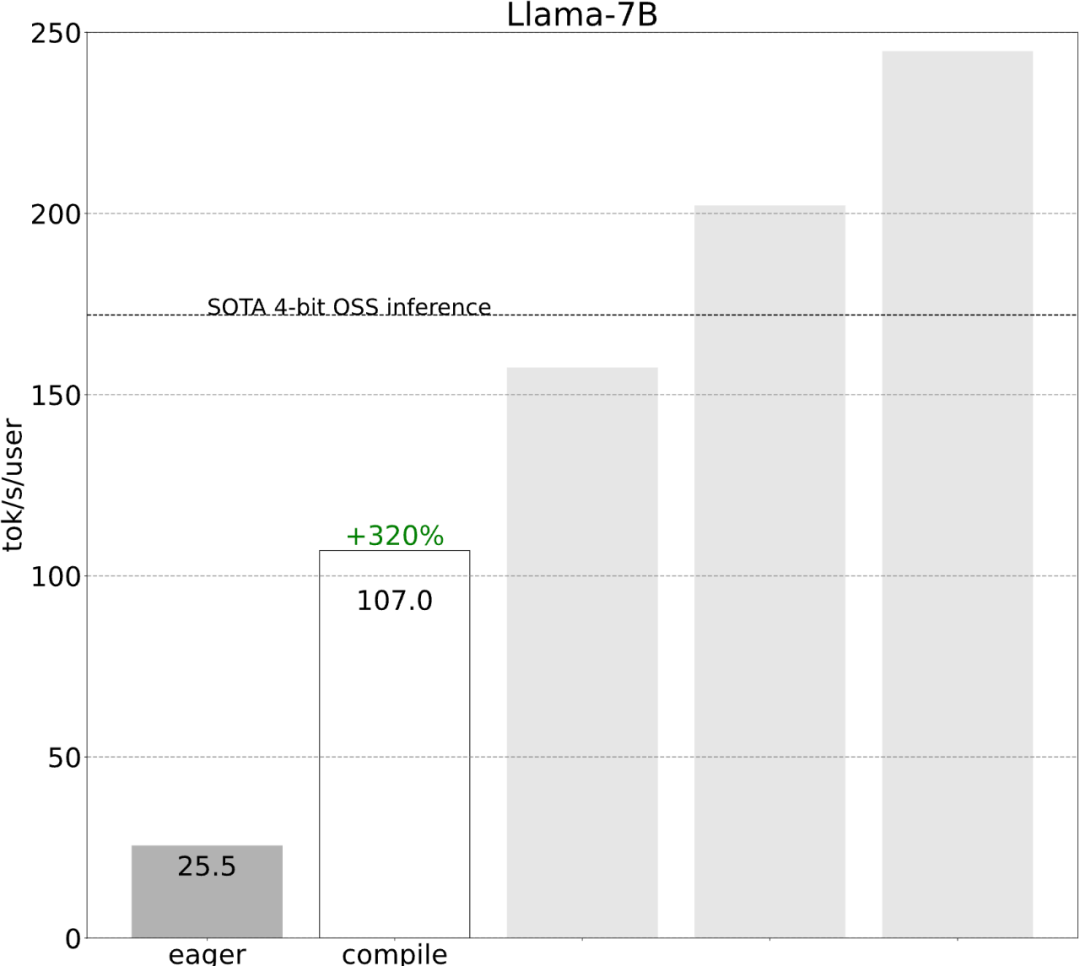
1단계: Torch.compile 및 정적 KV 캐시로 CPU 오버헤드를 줄여 107.0 TOK/S 달성torch.compile을 사용하면 특히 모드에서 더 큰 영역을 단일 컴파일 영역으로 캡처할 수 있습니다. ="reduce-overhead"(아래 코드 참조), 이 함수는 CPU 오버헤드를 줄이는 데 매우 효과적입니다. 또한 이 기사에서는 모델에 "그래프 중단"이 없는지 확인하기 위해 fullgraph=True도 지정합니다. , torch.compile이 컴파일할 수 없는 부분).
그러나 torch.compile의 축복에도 불구하고 여전히 몇 가지 장애물이 있습니다. 첫 번째 장애물은 kv 캐시입니다. 즉, 사용자가 더 많은 토큰을 생성하면 kv 캐시의 "논리적 길이"가 늘어납니다. 이 문제는 두 가지 이유로 발생합니다. 첫째, 캐시가 커질 때마다 kv 캐시를 재할당(및 복사)하는 데 비용이 많이 들고, 둘째, 이러한 동적 할당으로 인해 오버헤드가 더 어려워집니다. 이 문제를 해결하기 위해 이 문서에서는 정적 KV 캐시를 사용하고 KV 캐시의 크기를 정적으로 할당한 다음 어텐션 메커니즘에서 사용되지 않는 값을 마스크 처리합니다.
두 번째 장애물은 사전 채우기 단계입니다. Transformer를 사용한 텍스트 생성은 2단계 프로세스로 볼 수 있습니다. 1. 전체 프롬프트를 처리하는 사전 채우기 단계 2. 토큰을 디코딩합니다.kv 캐시는 가변 길이로 인해 정적으로 설정되지만 프롬프트, 미리 채우기 단계에는 여전히 더 많은 역동성이 필요합니다. 따라서 이 두 단계를 컴파일하려면 별도의 컴파일 전략을 사용해야 합니다.
이러한 세부 사항은 약간 까다롭지만 구현하기 어렵지 않으며 성능이 크게 향상되었습니다. 이 작업 후 성능은 25tok/s에서 107tok/s로 4배 이상 증가했습니다.
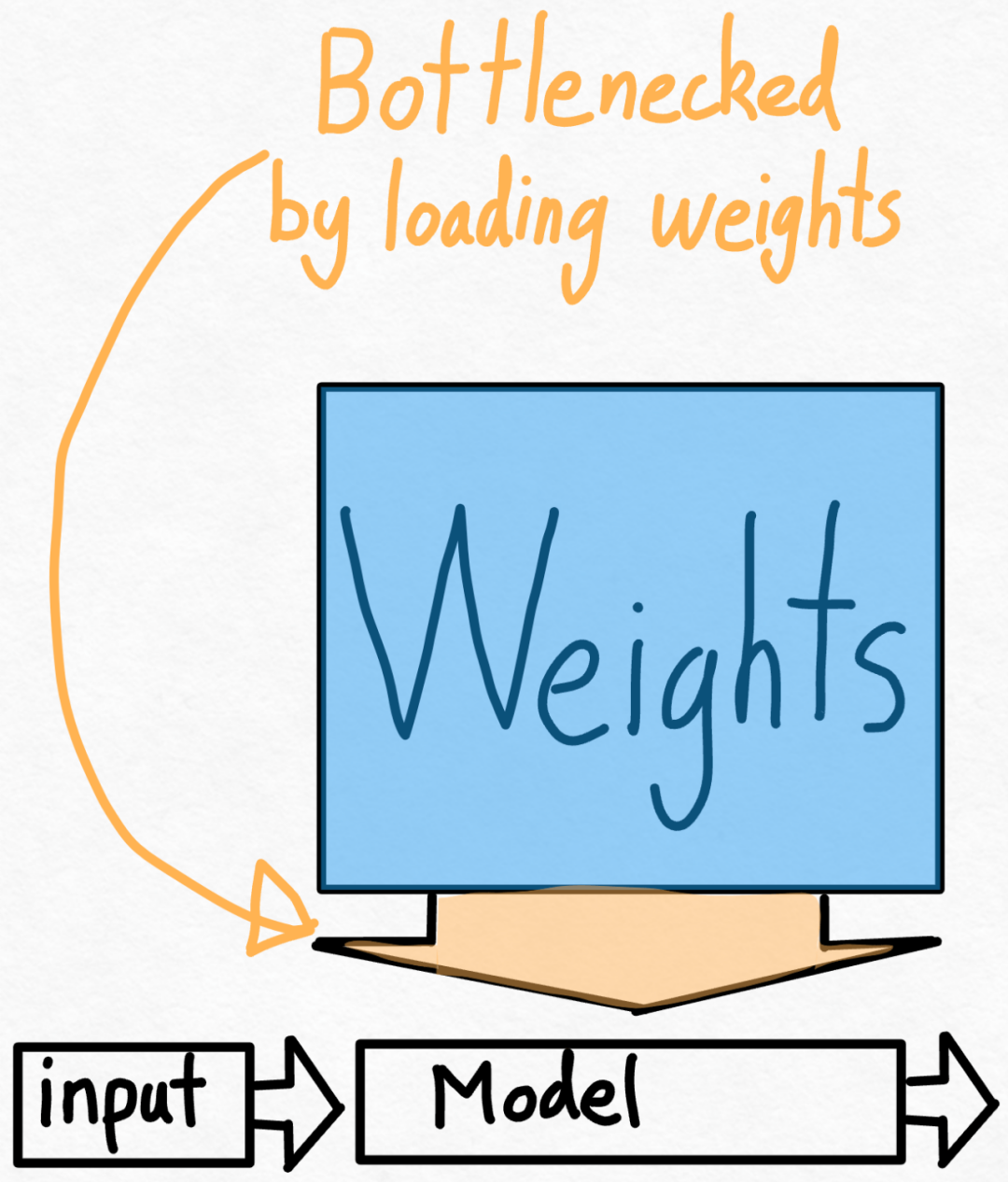
2단계: int8 가중치 양자화를 통해 메모리 대역폭 병목 현상을 완화하고 157.4 tok/s 달성위를 통해 torch.compile, static kv 캐시, 엄청난 가속이 있었지만 PyTorch 팀은 이에 만족하지 않고 최적화를 위한 다른 각도를 찾았습니다. 그들은 생성 AI 훈련을 가속화하는 데 가장 큰 병목 현상이 GPU 전역 메모리에서 레지스터로 가중치를 로드하는 비용이라고 믿습니다. 즉, 각 정방향 패스는 GPU의 모든 매개변수를 "터치"해야 합니다. 그렇다면 이론적으로 모델의 모든 매개변수에 얼마나 빨리 "접근"할 수 있습니까?
이를 측정하기 위해 이 기사에서는 MBU(Model Bandwidth Utilization)를 사용하며 계산은 다음과 같이 매우 간단합니다.
예를 들어 7B 매개변수 모델의 경우 각 매개변수는 fp16(2 매개변수당 바이트), 107개 토큰/초를 달성할 수 있습니다. A100-80GB의 이론적인 메모리 대역폭은 2TB/s입니다. 아래 그림과 같이 위의 수식을 특정 값에 대입하면 72%의 MBU를 얻을 수 있습니다! 많은 연구에서 85%를 돌파하는 데 어려움이 있기 때문에 이 결과는 상당히 좋습니다.
하지만 PyTorch 팀도 이 값을 늘리고 싶어합니다. 그들은 모델의 매개변수 수나 GPU의 메모리 대역폭을 변경할 수 없다는 것을 발견했습니다. 그러나 그들은 각 매개변수에 대해 저장된 바이트 수를 변경할 수 있다는 것을 발견했습니다!
그래서 그들은 int8 양자화를 사용할 것입니다.
이것은 양자화된 가중치일 뿐이며 계산 자체는 여전히 bf16에서 수행됩니다. 또한, torch.compile을 사용하면 int8 양자화를 위한 효율적인 코드를 쉽게 생성할 수 있습니다.
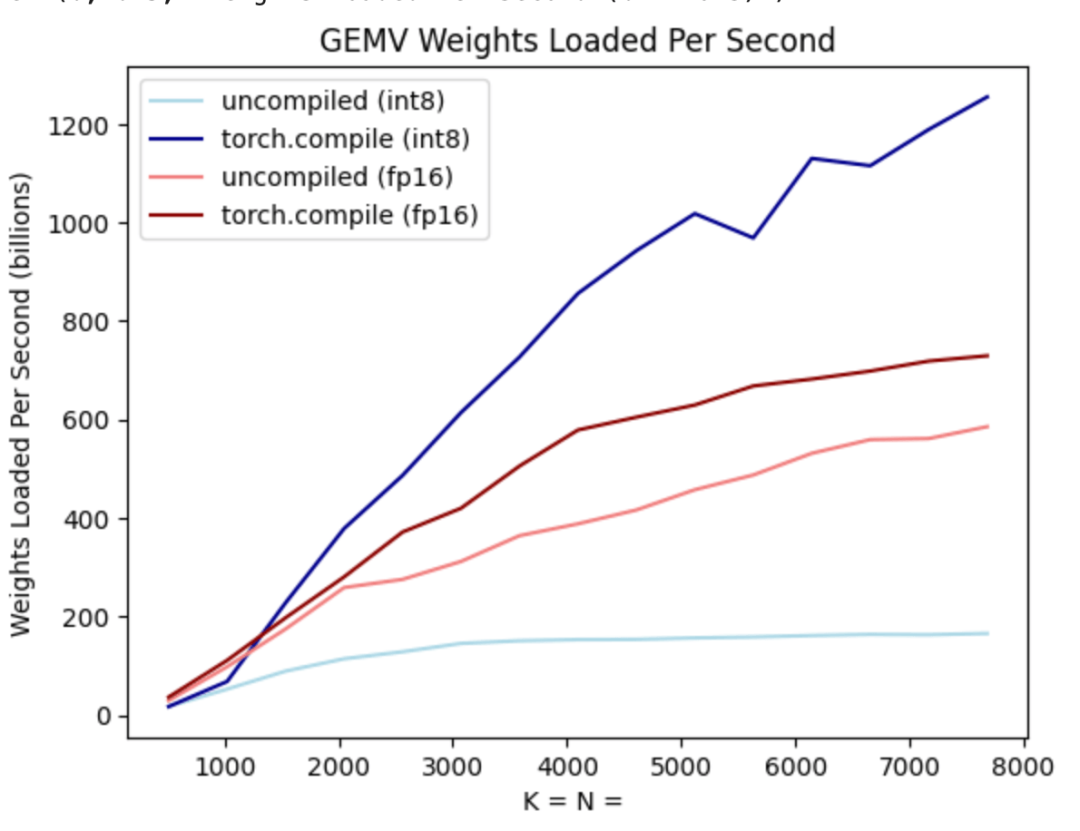
위 그림과 같이 진한 파란색 선(torch.compile + int8)을 보면 torch.compile + int8 가중치 양자화만 사용할 때 성능이 크게 향상되는 것을 알 수 있습니다. Llama-7B 모델에 int8 양자화를 적용하면 성능이 약 50% 향상되어 157.4 토큰/초로 향상됩니다.
int8 양자화와 같은 기술을 사용한 후에도 팀은 여전히 또 다른 문제에 직면했습니다. 즉, 100개의 토큰을 생성하려면 가중치가 100이어야 합니다. 로드된 이류.
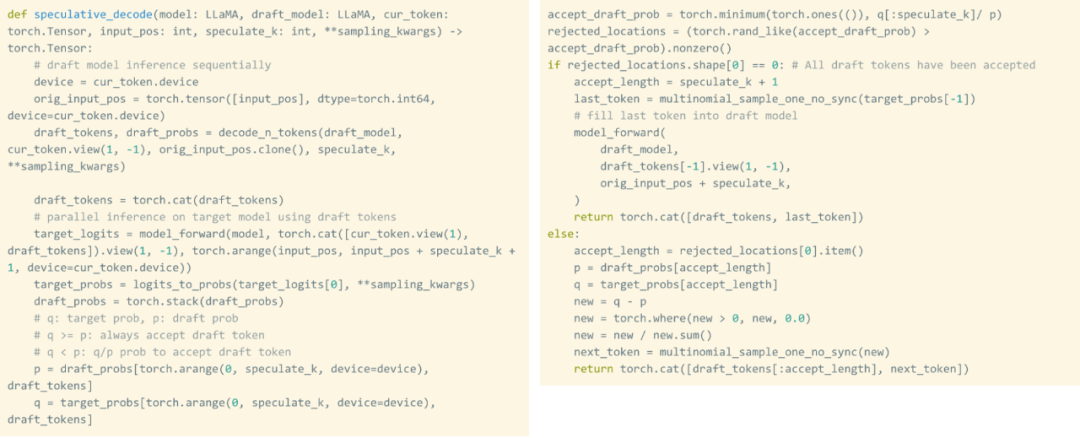
가중치가 양자화되더라도 계속해서 가중치를 로드하는 것은 불가피합니다. 이 문제를 해결하는 방법은 무엇입니까? 추측적 디코딩을 활용하면 이러한 엄격한 직렬 종속성을 깨고 속도를 높일 수 있다는 것이 밝혀졌습니다.
이 연구에서는 초안 모델을 사용하여 8개의 토큰을 생성한 다음 유효성 검사기 모델을 사용하여 이를 병렬로 처리하고 일치하지 않는 토큰을 폐기합니다. 이 프로세스는 직렬 종속성을 깨뜨립니다. 전체 구현에는 약 50줄의 기본 PyTorch 코드가 필요합니다.
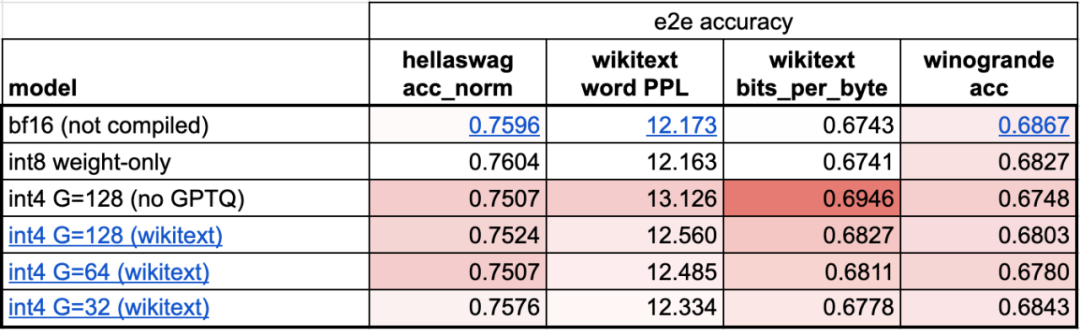
4단계: int4 양자화 및 GPTQ 방법을 사용하여 무게를 추가로 줄여 202.1 tok/s를 달성합니다이 기사에서는 무게가 4비트일 때 모델의 정확도가 시작된다는 것을 발견했습니다. 감소하다.
이 문제를 해결하기 위해 이 기사에서는 두 가지 기술을 사용하여 해결합니다. 첫 번째는 보다 세분화된 배율 인수를 사용하는 것이고, 다른 하나는 보다 고급 양자화 전략을 사용하는 것입니다. 이러한 작업을 결합하면 다음을 얻습니다.
5단계: 모든 것을 결합하면 244.7tok/s를 얻습니다.마지막으로 모든 기술을 결합하여 더 나은 결과를 얻습니다. 성능은 244.7tok입니다. /에스.
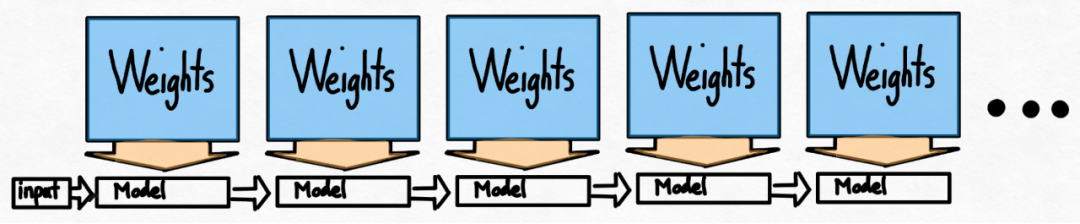
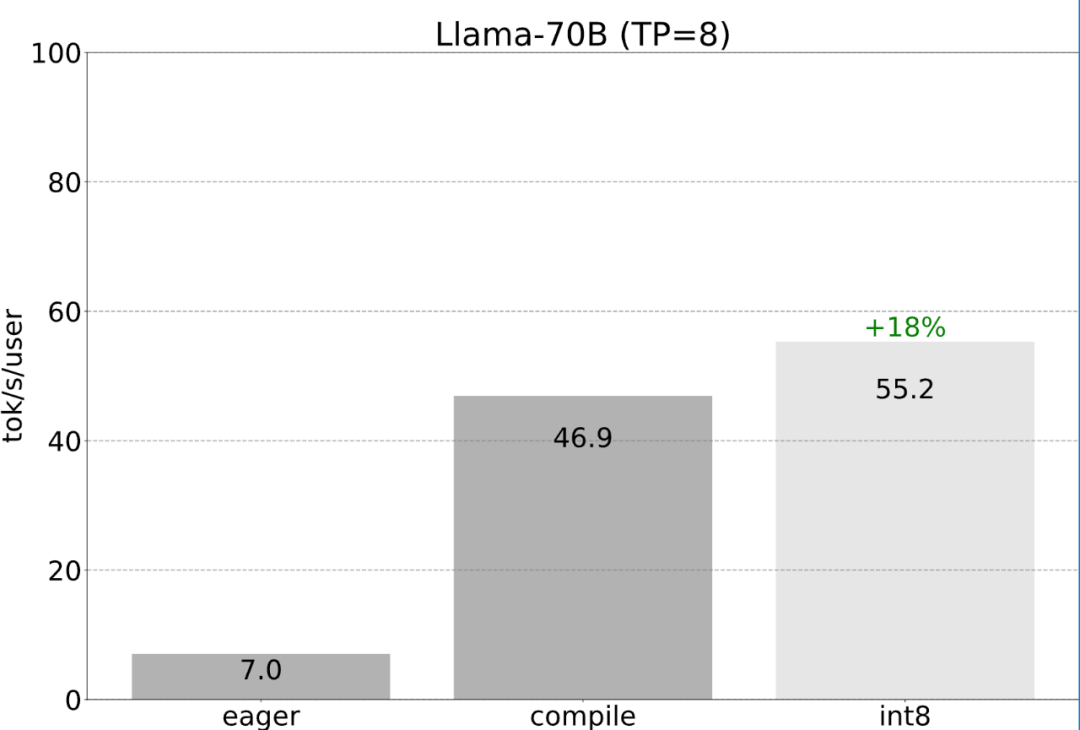
이 문서는 단일 GPU에서 지연 시간을 최소화하는 방법에 관한 것이었습니다. 실제로 여러 GPU를 사용하는 것도 가능하므로 지연 시간이 더욱 향상됩니다. 다행히 PyTorch 팀은 150줄의 코드만 필요하고 모델 변경이 필요하지 않은 텐서 병렬 처리를 위한 하위 수준 도구를 제공합니다.
앞서 언급한 모든 최적화는 텐서 병렬성과 계속 결합될 수 있으며, 이는 Llama-70B 모델에 대해 초당 55토큰의 int8 양자화를 제공합니다.
마지막으로 기사의 주요 내용을 간략하게 요약합니다. Llama-7B에서 이 기사는 "컴파일 + int4 퀀트 + 추측 디코딩" 조합을 사용하여 240+ tok/s를 달성합니다. Llama-70B에서 이 백서에서는 SOTA 성능에 가깝거나 이를 초과하는 약 80 tok/s를 달성하기 위해 텐서 병렬성을 도입했습니다. 원본 링크: https://pytorch.org/blog/accelerating-generative-ai-2/위 내용은 1,000줄 미만의 코드로 PyTorch 팀은 Llama 7B를 10배 더 빠르게 만들었습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!