
pytorch + visdom은 간단한 분류 문제를 처리합니다.

- 不言원래의
- 2018-06-04 16:07:163524검색
이 글은 주로 pytorch + visdom이 간단한 분류 문제를 처리하는 방법을 소개합니다. 이제는 모든 사람과 공유합니다. 도움이 필요한 친구들이 참고할 수 있습니다
시스템: win 10 그래픽 카드 : gtx965m cpu: i7-6700HQ
python 3.61pytorch 0.3
패키지 참조
import torch
from torch.autograd import Variable
import torch.nn.functional as F
import numpy as np
import visdom
import time
from torch import nn,optim
데이터 준비
use_gpu = True
ones = np.ones((500,2))
x1 = torch.normal(6*torch.from_numpy(ones),2)
y1 = torch.zeros(500)
x2 = torch.normal(6*torch.from_numpy(ones*[-1,1]),2)
y2 = y1 +1
x3 = torch.normal(-6*torch.from_numpy(ones),2)
y3 = y1 +2
x4 = torch.normal(6*torch.from_numpy(ones*[1,-1]),2)
y4 = y1 +3
x = torch.cat((x1, x2, x3 ,x4), 0).float()
y = torch.cat((y1, y2, y3, y4), ).long()
아래 시각화를 보세요:
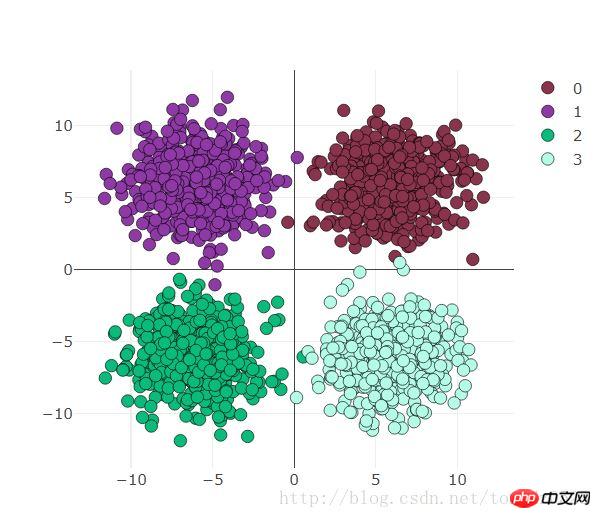 visdom 시각화 준비
visdom 시각화 준비
먼저 관찰해야 할 창을 만듭니다
viz = visdom.Visdom()
colors = np.random.randint(0,255,(4,3)) #颜色随机
#线图用来观察loss 和 accuracy
line = viz.line(X=np.arange(1,10,1), Y=np.arange(1,10,1))
#散点图用来观察分类变化
scatter = viz.scatter(
X=x,
Y=y+1,
opts=dict(
markercolor = colors,
marksize = 5,
legend=["0","1","2","3"]),)
#text 窗口用来显示loss 、accuracy 、时间
text = viz.text("FOR TEST")
#散点图做对比
viz.scatter(
X=x,
Y=y+1,
opts=dict(
markercolor = colors,
marksize = 5,
legend=["0","1","2","3"]
),
)
효과는 다음과 같습니다.
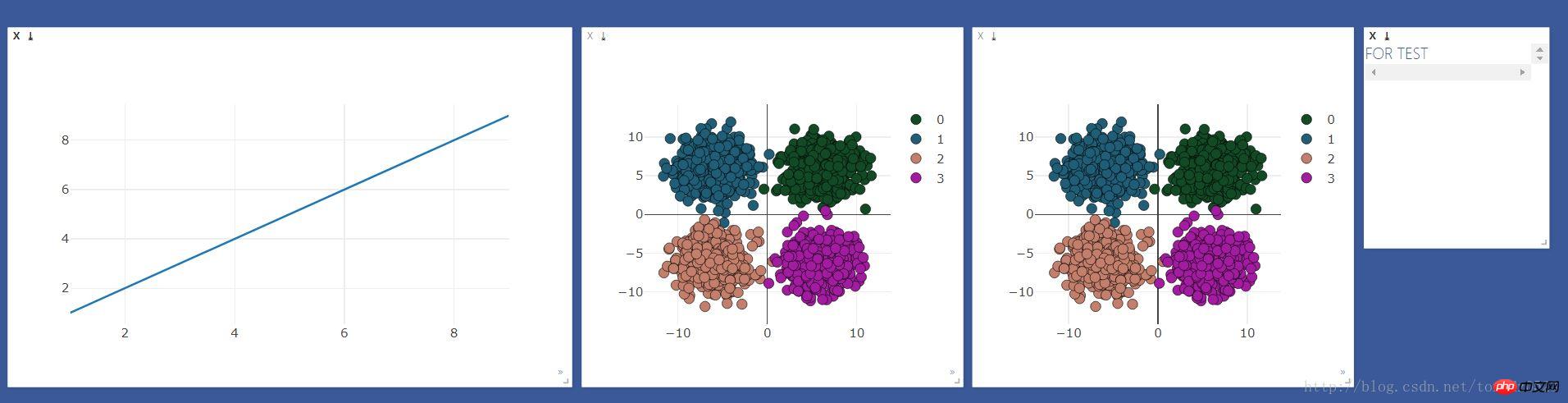 로지스틱 회귀 처리
로지스틱 회귀 처리
입력 2, 출력 4
logstic = nn.Sequential( nn.Linear(2,4) )
Gpu 또는 CPU 선택:
if use_gpu:
gpu_status = torch.cuda.is_available()
if gpu_status:
logstic = logstic.cuda()
# net = net.cuda()
print("###############使用gpu##############")
else : print("###############使用cpu##############")
else:
gpu_status = False
print("###############使用cpu##############")
최적화 및 손실 기능:
loss_f = nn.CrossEntropyLoss() optimizer_l = optim.SGD(logstic.parameters(), lr=0.001)
2000회 훈련:
start_time = time.time()
time_point, loss_point, accuracy_point = [], [], []
for t in range(2000):
if gpu_status:
train_x = Variable(x).cuda()
train_y = Variable(y).cuda()
else:
train_x = Variable(x)
train_y = Variable(y)
# out = net(train_x)
out_l = logstic(train_x)
loss = loss_f(out_l,train_y)
optimizer_l.zero_grad()
loss.backward()
optimizer_l.step()
관찰 및 시각화 훈련 결과:
if t % 10 == 0:
prediction = torch.max(F.softmax(out_l, 1), 1)[1]
pred_y = prediction.data
accuracy = sum(pred_y ==train_y.data)/float(2000.0)
loss_point.append(loss.data[0])
accuracy_point.append(accuracy)
time_point.append(time.time()-start_time)
print("[{}/{}] | accuracy : {:.3f} | loss : {:.3f} | time : {:.2f} ".format(t + 1, 2000, accuracy, loss.data[0],
time.time() - start_time))
viz.line(X=np.column_stack((np.array(time_point),np.array(time_point))),
Y=np.column_stack((np.array(loss_point),np.array(accuracy_point))),
win=line,
opts=dict(legend=["loss", "accuracy"]))
#这里的数据如果用gpu跑会出错,要把数据换成cpu的数据 .cpu()即可
viz.scatter(X=train_x.cpu().data, Y=pred_y.cpu()+1, win=scatter,name="add",
opts=dict(markercolor=colors,legend=["0", "1", "2", "3"]))
viz.text("<h3 align='center' style='color:blue'>accuracy : {}</h3><br><h3 align='center' style='color:pink'>"
"loss : {:.4f}</h3><br><h3 align ='center' style='color:green'>time : {:.1f}</h3>"
.format(accuracy,loss.data[0],time.time()-start_time),win =text)
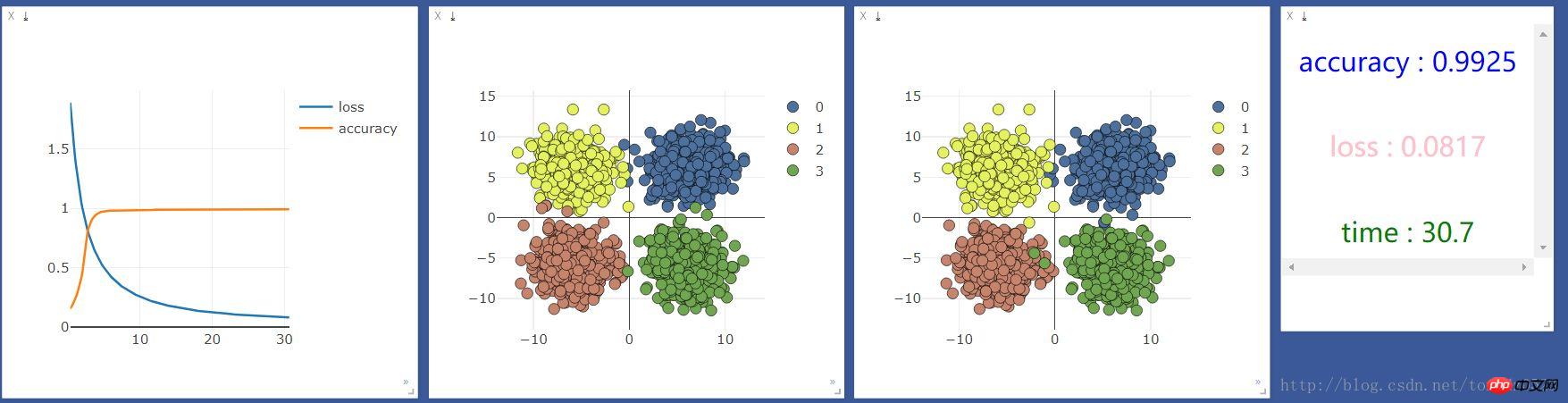
먼저 CPU로 실행했는데 결과는 다음과 같습니다.
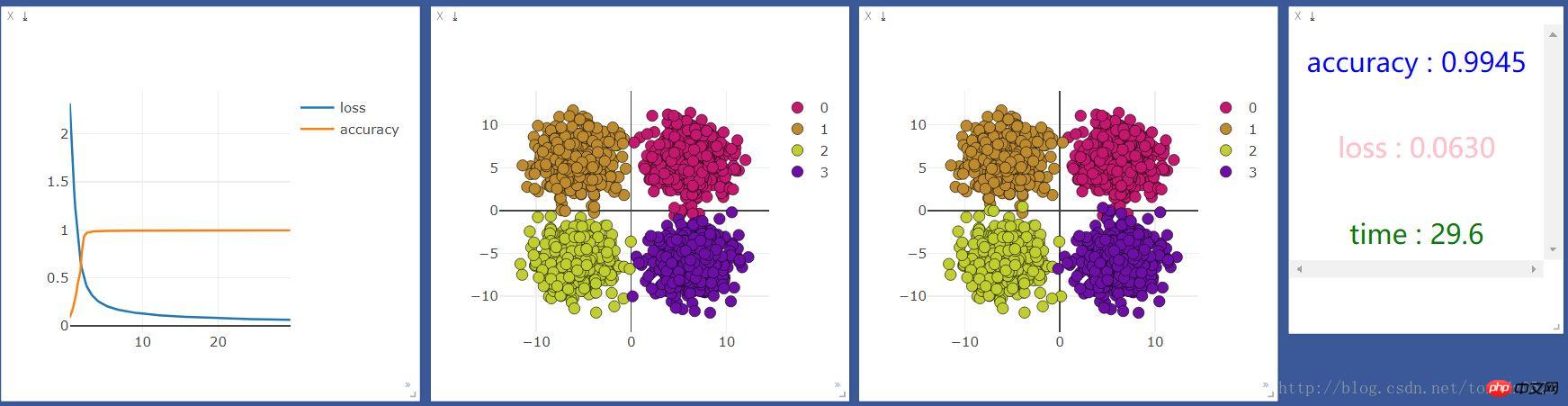
그런 다음 GPU로 실행했는데 결과는 다음과 같습니다.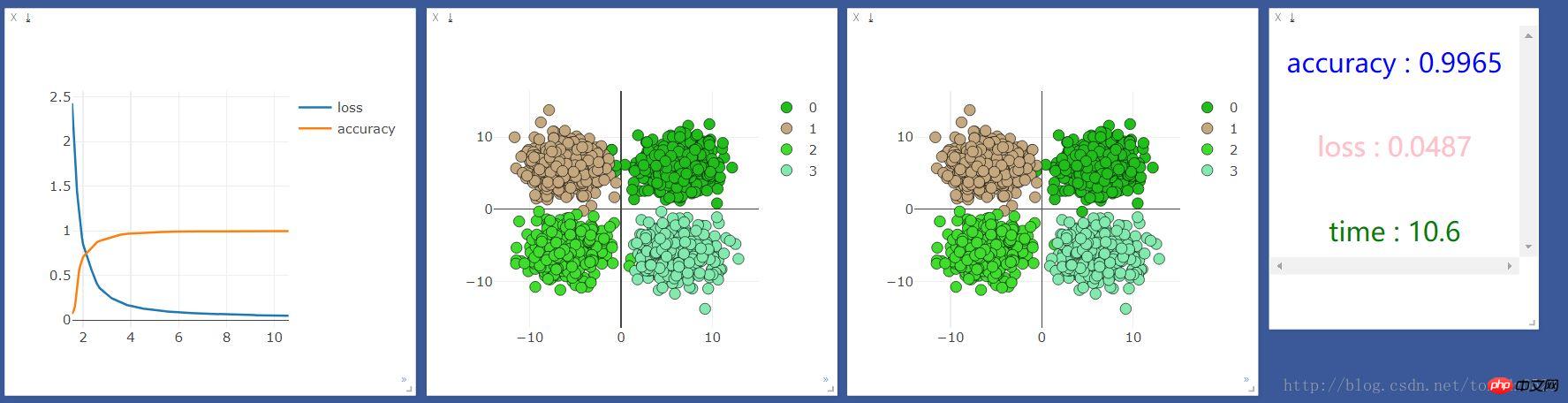

net = nn.Sequential(
nn.Linear(2, 10),
nn.ReLU(), #激活函数
nn.Linear(10, 4)
)
10단위 신경층을 추가하고 효과가 향상되는지 확인:
CPU 사용:GPU 사용: 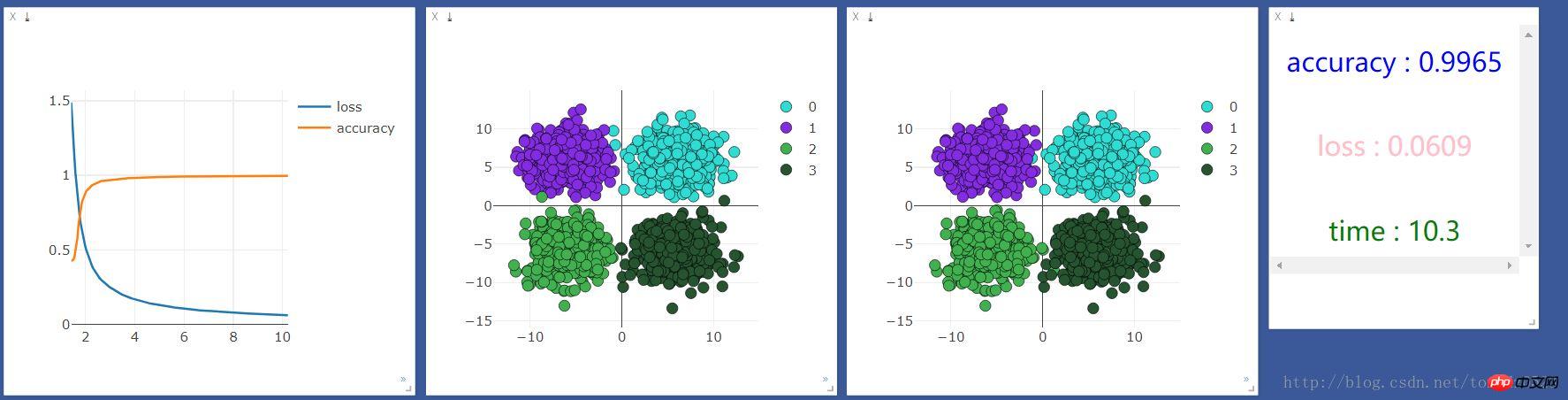
 관련 권장사항:
관련 권장사항:
회귀 및 분류를 구현하기 위해 PyTorch에서 간단한 신경망을 구축하는 예
PyTorch 배치 훈련 및 최적화 프로그램 비교에 대한 자세한 설명
위 내용은 pytorch + visdom은 간단한 분류 문제를 처리합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!