
툴킷을 사용하여 대규모 모델 추론 성능을 40배 향상

- 王林앞으로
- 2023-11-30 20:26:05935검색
Intel® Extension for Transformer란 무엇입니까?
Intel® Extension for Transformers[1]는 Intel® 아키텍처 플랫폼, 특히 4세대 Intel® Xeon® 확장 가능 프로세서(코드명 Sapphire Rapids[2)를 기반으로 할 수 있는 Intel에서 출시한 혁신적인 툴킷입니다. ], SPR)은 Transformer 기반 LLM(대형 언어 모델)을 크게 가속화합니다. 주요 기능은 다음과 같습니다.
- Hugging Face Transformers API[3]를 확장하고 Intel® Neural Compressor[4]를 활용하여 사용자에게 원활한 모델 압축 환경을 제공합니다.
- 낮은 비트 양자화 커널 사용 제공( NeurIPS 2023: CPU에서 효율적인 LLM 추론[5]을 구현하는 LLM 추론 런타임은 Falcon, LLaMA, MPT, Llama2, BLOOM, OPT, ChatGLM2, GPT-J-6B, Baichuan-13B-Base, Baichuan2-13B-Base를 지원합니다. , Qwen-7B, Qwen-14B 및 Dolly-v2-3B와 같은 일반적인 LLM [6]
- 고급 압축 감지 런타임 [7] (NeurIPS 2022: CPU 및 QuaLA-MiniLM의 빠른 증류: 양자화된 길이 자동 적응 MiniLM; NeurIPS 2021: 한 번 정리하고 잊어버리세요: 사전 훈련된 언어 모델을 희박/ 정리합니다.
이 기사에서는 LLM 추론 런타임 ("LLM 런타임"이라고 함) 과 Transformer 기반 API를 사용하여 Intel® Xeon® 확장 가능한 프로세서에서 보다 효율적인 LLM을 구현하는 방법에 중점을 둘 것입니다. 채팅 시나리오에서 LLM의 적용 문제를 처리합니다.
LLM 런타임(LLM 런타임)
인텔® Extension for Transformers에서 제공하는 LLM 런타임[8]은 가볍지만 효율적인 LLM 추론 런타임으로, GGML[9]에서 영감을 얻었으며 llama.cpp[와 호환됩니다. 10]은 호환되며 다음과 같은 기능을 가지고 있습니다.
- 커널은 Intel® Xeon® CPU(예: AMX, VNNI)와 AVX512F 및 AVX2 명령어 세트에 내장된 다양한 AI 가속 기술에 맞게 최적화되었습니다. 다양한 세부사항(채널별 또는 그룹별), 다양한 그룹 크기(예: 32/128)와 같은 더 많은 수량화 옵션을 제공합니다.
- 더 나은 KV 캐시 액세스 및 메모리 할당 전략이 있습니다.
- 텐서 병렬화 기능으로 분산이 용이합니다. 다중 채널 시스템에서의 추론.
- LLM 런타임의 단순화된 아키텍처 다이어그램은 다음과 같습니다.
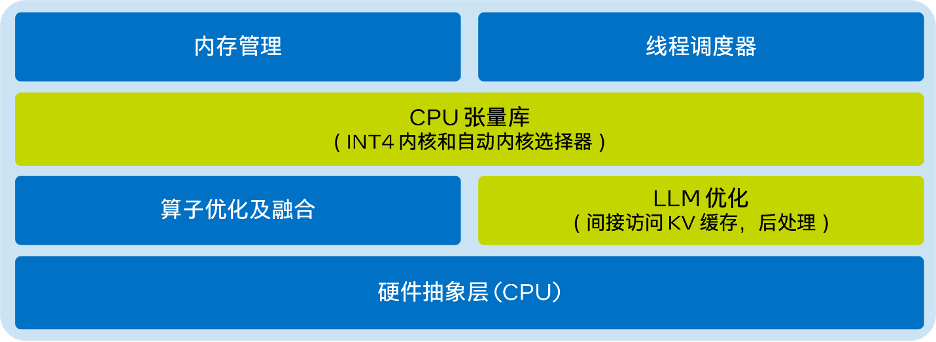 다시 작성해야 하는 내용은 다음과 같습니다. △그림 1. Transformers용 Intel® Extension의 LLM 런타임의 단순화된 아키텍처 다이어그램
다시 작성해야 하는 내용은 다음과 같습니다. △그림 1. Transformers용 Intel® Extension의 LLM 런타임의 단순화된 아키텍처 다이어그램
Transformer 기반 사용 CPU에 구현된 API LLM Efficient Inference
9줄 미만의 코드로 CPU에서 더 나은 LLM 추론 성능을 얻을 수 있습니다. 사용자는 정량화 및 추론을 위해 Transformer와 유사한 API를 쉽게 활성화할 수 있습니다. 'load_in_4bit'를 true로 설정하고 HuggingFace URL 또는 로컬 경로에서 모델을 가져오기만 하면 됩니다. 가중치 전용 INT4 양자화를 활성화하는 예제 코드는 다음과 같습니다.
from transformers import AutoTokenizer, TextStreamerfrom intel_extension_for_transformers.transformers import AutoModelForCausalLMmodel_name = "Intel/neural-chat-7b-v3-1” prompt = "Once upon a time, there existed a little girl,"tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)inputs = tokenizer(prompt, return_tensors="pt").input_idsstreamer = TextStreamer(tokenizer)model = AutoModelForCausalLM.from_pretrained(model_name, load_in_4bit=True)outputs = model.generate(inputs, streamer=streamer, max_new_tokens=300)
기본 설정은 가중치를 4비트로 저장하고 계산을 8비트로 수행합니다. 그러나 다양한 계산 데이터 유형(dtype)과 가중치 데이터 유형 조합도 지원하며 사용자는 필요에 따라 설정을 수정할 수 있습니다. 이 기능을 사용하는 방법에 대한 샘플 코드는 다음과 같습니다.
from transformers import AutoTokenizer, TextStreamerfrom intel_extension_for_transformers.transformers import AutoModelForCausalLM, WeightOnlyQuantConfigmodel_name = "Intel/neural-chat-7b-v3-1” prompt = "Once upon a time, there existed a little girl,"woq_config = WeightOnlyQuantConfig(compute_dtype="int8", weight_dtype="int4")tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)inputs = tokenizer(prompt, return_tensors="pt").input_idsstreamer = TextStreamer(tokenizer)model = AutoModelForCausalLM.from_pretrained(model_name,quantization_cnotallow=woq_config)outputs = model.generate(inputs, streamer=streamer, max_new_tokens=300)
성능 테스트
지속적인 노력 끝에 위 최적화 체계의 INT4 성능이 크게 향상되었습니다. 이 문서에서는
Intel® GB(16 x 16 GB DDR5 4800 MT/s [4800 MT/s]), BIOS 3A14.TEL2P1, 마이크로코드 0x2b0001b0, CentOS Stream 8이 장착된 시스템에서 llama.cpp와 성능을 비교합니다.추론 성능 테스트 결과는 아래 표와 같습니다. 입력 크기는 32, 출력 크기는 32, 빔은 1
Δ표 1. LLM 런타임 간의 추론 성능 비교 및 llama.cpp (입력 크기=32, 출력 크기 = 32, 빔 = 1) 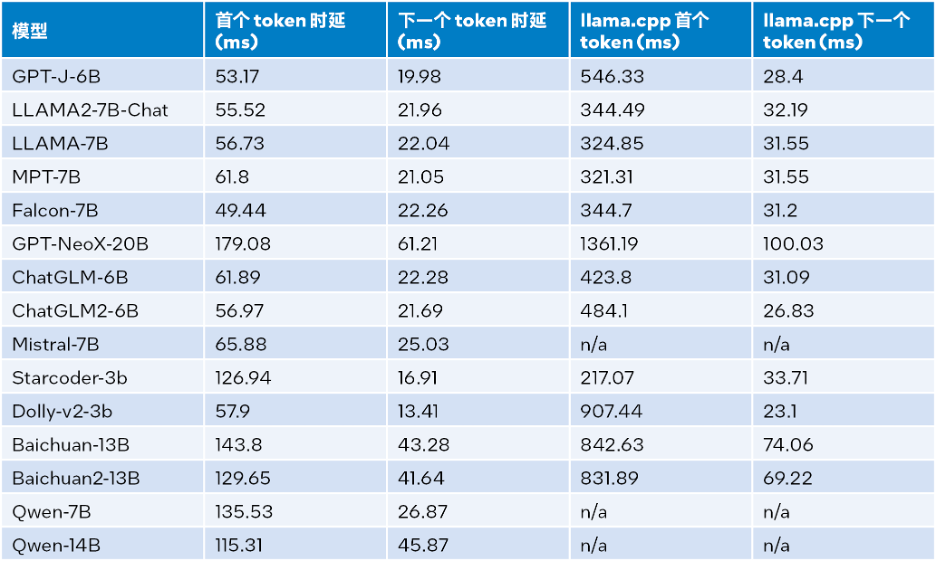
입력 크기가 1024, 출력 크기가 32, 빔이 1일 때의 추론 성능 테스트 결과는 다음 표를 참조하세요. 자세한 내용:
Δ표 2. llama.cpp 추론 성능과 LLM 런타임 비교(입력 크기=1024, 출력 크기=32, 빔=1)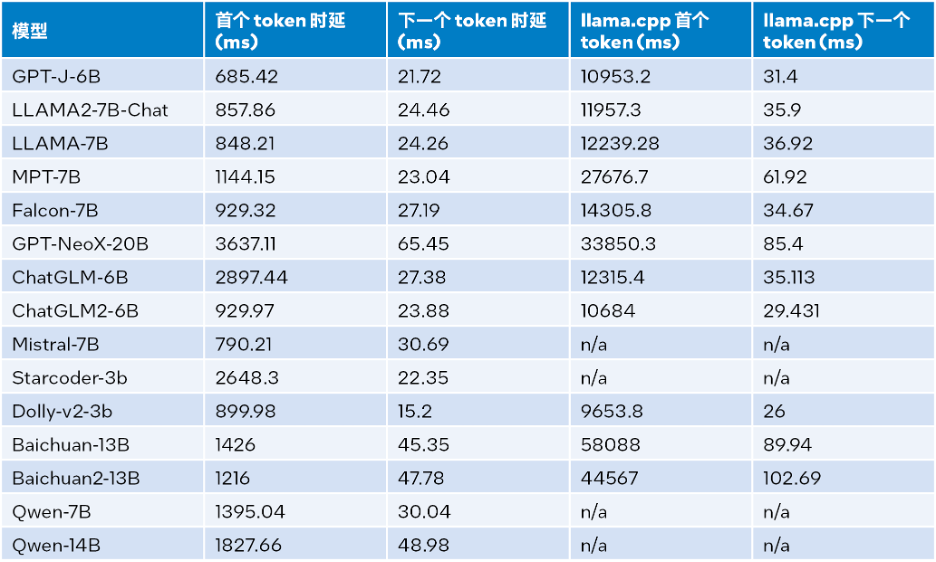
위의 표 2에 따르면: 첫 번째 토큰이든 다음 토큰이든 4세대 Intel® Xeon® 확장 가능 프로세서에서 실행되는 llama.cpp와 비교할 때 LLM 런타임은 지연을 크게 줄일 수 있으며 첫 번째 토큰의 추론 속도를 크게 줄일 수 있습니다. 토큰과 다음 토큰은 각각 최대 40배 [a](Baichuan-13B, 입력은 1024) 및 2.68배 [b](MPT-7B, 입력은 1024)까지 증가합니다. llama.cpp 테스트에서는 기본 코드 베이스 [10]를 사용합니다. 표 1과 표 2의 테스트 결과에 따르면 4세대에서도 실행되는 llama.cpp와 비교할 때
Intel® Xeon®확장 가능한 프로세서인 LLM Runtime은 여러 일반적인 성능을 크게 향상시킬 수 있다는 결론을 내릴 수 있습니다. LLM: 입력 크기가 1024이면 3.58~21.5배의 개선이 달성되고, 입력 크기가 32이면 1.76~3.43배의 개선이 달성됩니다[c]. 정확도 테스트
Intel®Extension for Transformers는 Intel® Neural Compressor에서 SignRound[11], RTN 및 GPTQ[12]와 같은 양자화 방법을 활용하고 Lambada_openai, piqa, winogrande 및 hellaswag 데이터 세트를 사용할 수 있습니다. 검증된 INT4 추론 정확성. 아래 표는 테스트 결과 평균을 FP32 정확도와 비교합니다.
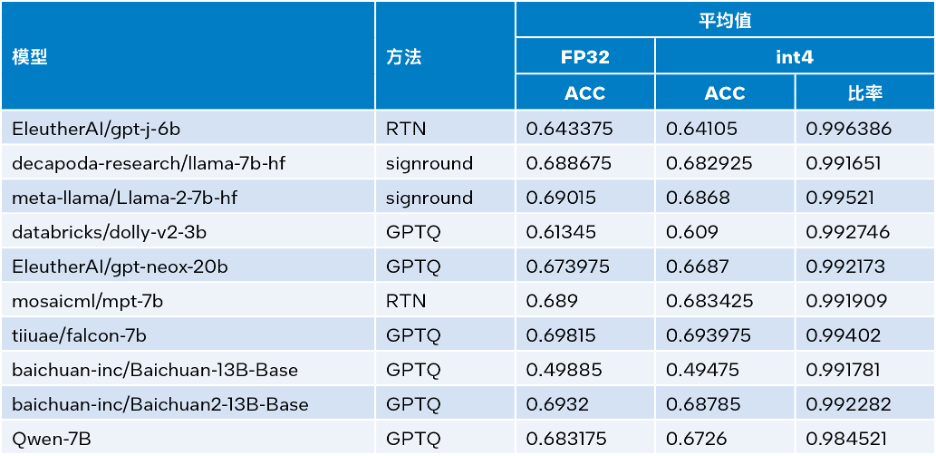 Δ표 3. INT4와 FP32의 정확도 비교
Δ표 3. INT4와 FP32의 정확도 비교
위의 표 3에서 볼 수 있듯이 LLM 런타임을 기반으로 하는 여러 모델에서 수행되는 INT4 추론의 정확도 손실은 매우 작아 거의 무시할 수 있습니다. 우리는 많은 모델을 검증했지만 공간 제한으로 인해 여기에는 일부만 나열되었습니다. 더 많은 정보나 세부 정보를 원하시면 다음 링크를 방문하세요:
https://medium.com/@NeuralCompressor/llm-performance-of-intel-extension-for-transformers-f7d061556176. 더 많은 고급 기능: 더 많은 시나리오에서 LLM의 애플리케이션 요구 사항을 충족합니다.
동시에 LLM 런타임[8]에는 이러한 기능을 갖춘 최초의 제품 중 하나인 듀얼 채널 CPU의 텐서 병렬화 기능도 있습니다. 앞으로는 듀얼 노드가 추가로 지원될 예정입니다.
그러나 LLM 런타임의 장점은 더 나은 성능과 정확성일 뿐만 아니라 채팅 응용 프로그램 시나리오에서 기능을 향상하고 LLM이 채팅 시나리오에서 발생할 수 있는 다음 응용 프로그램 딜레마를 해결하기 위해 많은 노력을 기울였습니다.
대화는 LLM 추론뿐만 아니라 대화 기록도 유용합니다.
- 제한된 출력 길이: LLM 모델 사전 훈련은 주로 제한된 시퀀스 길이를 기반으로 합니다. 따라서 시퀀스 길이가 사전 훈련 중에 사용된 주의 창 크기를 초과하면 정확도가 감소합니다.
- 비효율성: 디코딩 단계에서 Transformer 기반 LLM은 이전에 생성된 모든 토큰의 키-값 상태(KV)를 저장하므로 과도한 메모리 사용량과 디코딩 지연 시간이 늘어납니다.
- 첫 번째 문제와 관련하여 LLM 런타임의 대화 기능은 더 많은 대화 기록 데이터를 통합하고 더 많은 출력을 생성하여 해결되는데, llama.cpp에서는 아직 처리할 수 있는 장비가 부족합니다.
두 번째 및 세 번째 질문과 관련하여 스트리밍 LLM(Steaming LLM)을
Intel®Extension for Transformers에 통합하여 메모리 사용을 크게 최적화하고 추론 지연 시간을 줄일 수 있습니다. 스트리밍 LLM
기존 KV 캐시 알고리즘과 달리 우리의 방법은
Attention Sink(4개의 초기 토큰)을 결합하여 Attention 계산의 안정성을 향상시키고 롤링 KV 캐시 토큰의 도움으로 최신 상태를 유지합니다. 언어 모델링에 매우 중요합니다. 설계는 매우 유연하며 회전 위치 인코딩 RoPE 및 상대 위치 인코딩 ALiBi를 활용할 수 있는 자동 회귀 언어 모델에 원활하게 통합될 수 있습니다.
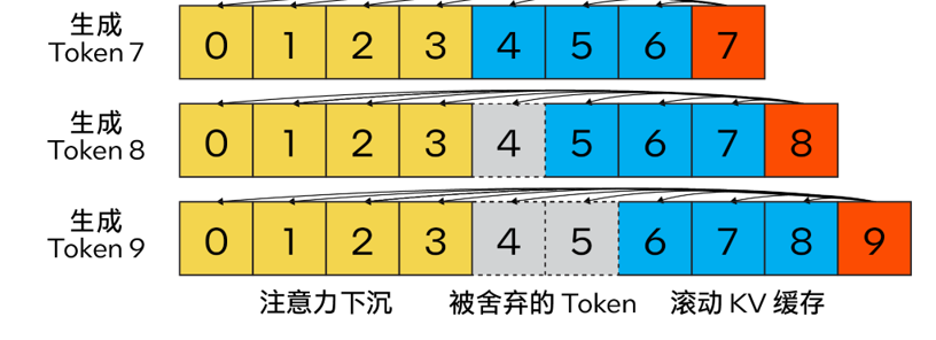 다시 작성해야 하는 콘텐츠는 다음과 같습니다. △ 그림 2. Attention Sinking을 사용하여 효율적인 스트리밍 언어 모델을 구현하는 Steam LLM의 KV 캐시(이미지 출처: [13])
다시 작성해야 하는 콘텐츠는 다음과 같습니다. △ 그림 2. Attention Sinking을 사용하여 효율적인 스트리밍 언어 모델을 구현하는 Steam LLM의 KV 캐시(이미지 출처: [13])
게다가 라마와도 다릅니다. cpp 에서 이 최적화 계획은 스트리밍 LLM 전략을 향상시키기 위해 "n_keep" 및 "n_discard"와 같은 새로운 매개변수도 추가합니다. 사용자는 "n_keep" 매개변수를 사용하여 KV 캐시에 보관할 토큰 수를 지정하고, "n_discard" 매개변수를 사용하여 생성된 토큰 중 삭제할 수를 결정할 수 있습니다. 성능과 정확성의 균형을 높이기 위해 시스템은 기본적으로 KV 캐시에 있는 최신 토큰 번호의 절반을 삭제합니다
동시에 성능을 더욱 향상시키기 위해 스트리밍 LLM도 MHA 융합 모드에 추가했습니다. 모델이 RoPE(회전 위치 인코딩)를 사용하여 위치 임베딩을 구현하는 경우, 이전에 생성되어 폐기되지 않은 토큰에 대한 작업을 수행하지 않도록 기존 K-Cache에 "시프트 작업"만 적용하면 됩니다. 이 방법은 긴 텍스트를 생성할 때 전체 컨텍스트 크기를 최대한 활용할 뿐만 아니라 KV 캐시 컨텍스트가 완전히 채워질 때까지 추가 오버헤드가 발생하지 않습니다.
“shift operation”依赖于旋转的交换性和关联性,或复数乘法。例如:如果某个token的K-张量初始放置位置为m并且旋转了m×θi for i ∈ [0,d/2),那么当它需要移动到m-1这个位置时,则可以旋转回到(-1)×θi for i ∈ [0,d/2)。这正是每次舍弃n_discard个token的缓存时发生的事情,而此时剩余的每个token都需要“移动”n_discard个位置。下图以“n_keep=4、n_ctx=16、n_discard=1”为例,展示了这一过程。

△图3.Ring-Buffer KV-Cache和Shift-RoPE工作原理
需要注意的是:融合注意力层无需了解上述过程。如果对K-cache和V-cache进行相同的洗牌,注意力层会输出几乎相同的结果(可能存在因浮点误差导致的微小差异)。
您可以使用下面的代码来启动Streaming LLM:
from transformers import AutoTokenizer, TextStreamer from intel_extension_for_transformers.transformers import AutoModelForCausalLM, WeightOnlyQuantConfig model_name = "Intel/neural-chat-7b-v1-1" # Hugging Face model_id or local model woq_config = WeightOnlyQuantConfig(compute_dtype="int8", weight_dtype="int4") prompt = "Once upon a time, a little girl"tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True) inputs = tokenizer(prompt, return_tensors="pt").input_ids streamer = TextStreamer(tokenizer)model = AutoModelForCausalLM.from_pretrained(model_name, quantization_cnotallow=woq_config, trust_remote_code=True) # Recommend n_keep=4 to do attention sinks (four initial tokens) and n_discard=-1 to drop half rencetly tokens when meet length threshold outputs = model.generate(inputs, streamer=streamer, max_new_tokens=300, ctx_size=100, n_keep=4, n_discard=-1)
结论与展望
本文基于上述实践经验,提供了一个在英特尔® 至强® 可扩展处理器上实现高效的低位(INT4)LLM推理的解决方案,并且在一系列常见LLM上验证了其通用性以及展现了其相对于其他基于CPU的开源解决方案的性能优势。未来,我们还将进一步提升CPU张量库和跨节点并行性能。
欢迎您试用英特尔® Extension for Transformers[1],并在英特尔® 平台上更高效地运行LLM推理!也欢迎您向代码仓库(repository)提交修改请求 (pull request)、问题或疑问。期待您的反馈!
特别致谢
在此致谢为此篇文章做出贡献的英特尔公司人工智能资深经理张瀚文及工程师许震中、余振滔、刘振卫、丁艺、王哲、刘宇澄。
[a]根据表2 Baichuan-13B的首个token测试结果计算而得。
[b]根据表2 MPT-7B的下一个token测试结果计算而得。
[c]当输入大小为1024时,整体性能=首个token性能+1023下一个token性能;当输入大小为32时,整体性能=首个token性能+31下一个token性能。
위 내용은 툴킷을 사용하여 대규모 모델 추론 성능을 40배 향상의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!