
생물의학 NLP 도메인을 위한 특정 사전 훈련 모델: PubMedBERT

- 王林앞으로
- 2023-11-27 17:13:461336검색
올해 대규모 언어 모델의 급속한 발전으로 인해 BERT와 같은 모델이 이제 "소형" 모델이라고 불리게 되었습니다. Kaggle의 LLM 과학 시험 대회에서 deberta를 사용하는 플레이어가 4위를 차지했는데, 이는 훌륭한 결과입니다. 따라서 특정 도메인이나 요구 사항에서 최상의 솔루션으로 대규모 언어 모델이 반드시 필요한 것은 아니며 작은 모델도 그 자리를 차지합니다. 그래서 오늘 소개할 것은 ACM의 Microsoft Research가 2022년에 발표한 논문인 PubMedBERT입니다. 이 모델은 도메인별 코퍼스를 사용하여 BERT를 처음부터 사전 학습합니다
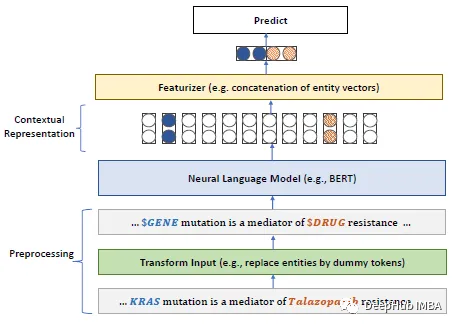
다음은 주요 내용입니다. 논문 요약:
생의학 분야와 같이 레이블이 지정되지 않은 텍스트가 많은 특정 도메인의 경우 언어 모델을 처음부터 사전 훈련하는 것이 일반 도메인 언어 모델을 지속적으로 사전 훈련하는 것보다 더 효과적입니다. 이를 위해 우리는 도메인별 사전 훈련
PubMedBERT
1, 도메인별 사전 훈련
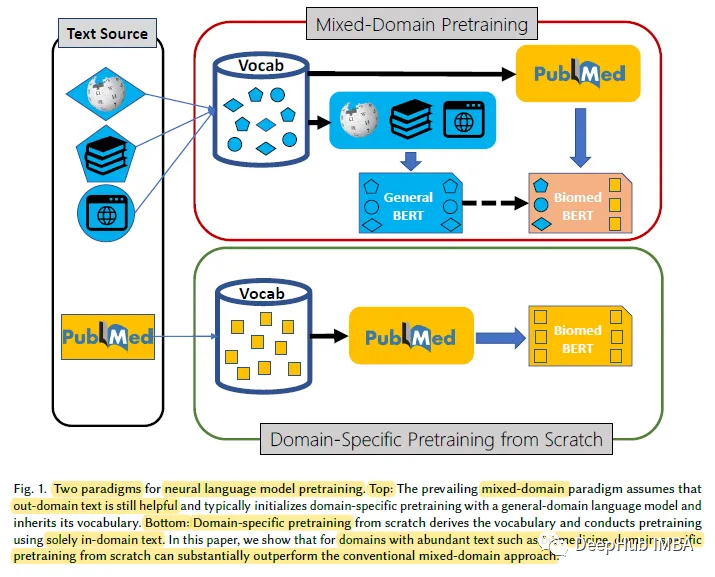
연구에 따르면 도메인을 처음부터 시작하는 것으로 나타났습니다. 특정 사전 훈련은 범용 언어 모델의 연속 사전 훈련보다 훨씬 뛰어난 성능을 보여 혼합 도메인 사전 훈련을 뒷받침하는 일반적인 가정이 항상 적용되는 것은 아님을 보여줍니다.
2. 모델
BERT 모델을 사용하는 경우 MLM(마스크 언어 모델)의 경우 WWM(전체 단어 마스킹)의 요구 사항은 전체 단어를 마스킹해야 한다는 것입니다
3. set
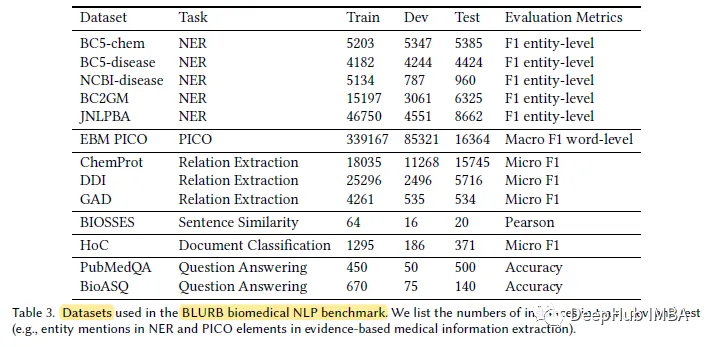
저자에 따르면 BLUE[45]는 생물의학 분야에서 NLP 벤치마크를 만들려는 첫 번째 시도라고 합니다. 하지만 BLUE의 적용 범위는 제한되어 있습니다. pubmed를 기반으로 한 생물의학 응용을 위해 저자는 BLURB(Biomedical Language Understanding and Reasoning Benchmark)를 제안합니다.
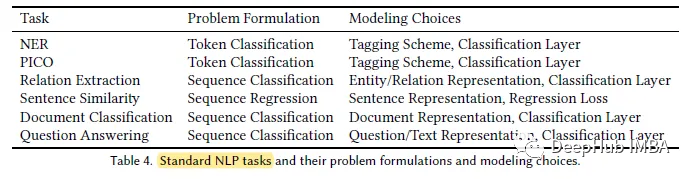
PubMedBERT는 더 큰 도메인별 자료(21GB)를 사용합니다.
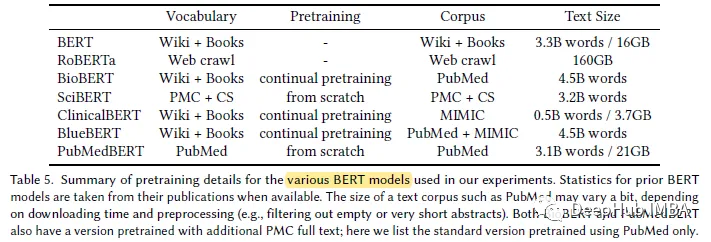
결과 표시
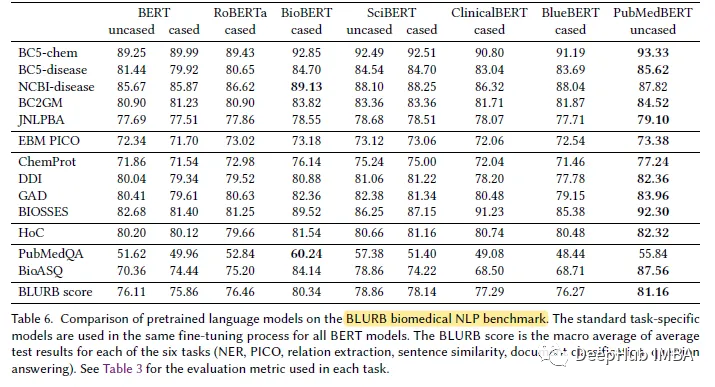
PubMedBERT는 대부분의 생물의학 자연어 처리(NLP) 작업에서 다른 모든 BERT 모델보다 지속적으로 뛰어난 성능을 발휘하며 종종 확실한 이점을 제공합니다.
위 내용은 생물의학 NLP 도메인을 위한 특정 사전 훈련 모델: PubMedBERT의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!