
LLaMA를 기반으로 하지만 텐서 이름을 변경한 이카이푸의 대형 모델이 논란을 일으켰고, 공식 답변은 여기까지입니다.

- 王林앞으로
- 2023-11-14 21:01:131187검색
얼마 전 오픈 소스 대형 모델 분야에서 컨텍스트 창 크기가 200k를 초과하고 한 번에 400,000자를 처리할 수 있는 "Yi"라는 새로운 모델이 출시되었습니다.
Sinovation Ventures의 이 카이푸 회장 겸 CEO는 대형 모델 회사인 "Zero One Everything"을 설립하고 Yi-6B와 Yi-34B의 두 가지 버전이 포함된 대형 모델을 제작했습니다.
Hugging Face에 따르면 영어 오픈 소스 커뮤니티 플랫폼 및 C-Eval 중국어 평가 목록인 Yi-34B는 출시 당시 여러 SOTA 국제 최고 성능 지표 인정을 획득하여 글로벌 오픈 소스 대형 모델의 "더블 챔피언"이 되었으며 다음과 같은 오픈 소스 경쟁 제품을 물리쳤습니다. LLaMA2 및 Falcon과 같습니다.
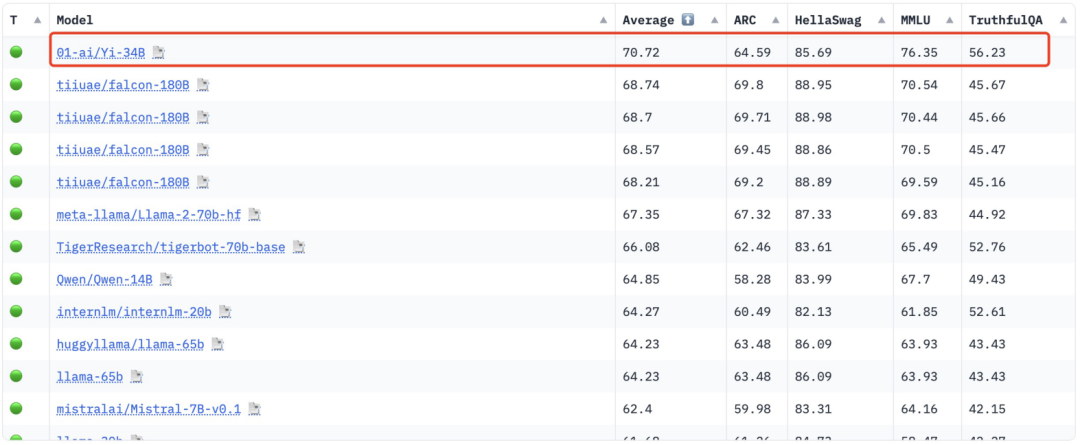
Yi-34B는 당시 국내 모델로는 유일하게 허깅페이스 글로벌 오픈소스 모델 순위 1위를 달성하며 '세계 최강 오픈소스 모델'로 불렸다.
이 모델은 출시 후 많은 국내외 연구자들과 개발자들의 관심을 끌었습니다
그러나 최근 일부 연구자들은 Yi-34B 모델이 기본적으로 LLaMA 아키텍처를 사용하지만 Two Tensor로 이름이 변경되었다는 사실을 발견했습니다.
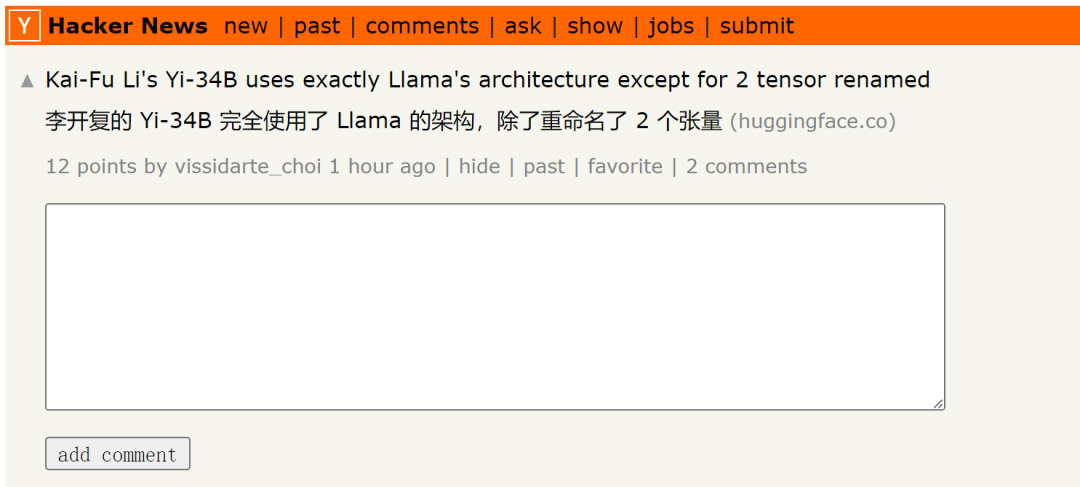
원본 게시물을 보려면 이 링크를 클릭하세요: https://news.ycombinator.com/item?id=38258015
게시물에도 언급됨:
Yi-34B의 코드 실제로는 LLaMA 코드를 리팩토링한 것이지만 실질적인 변경 사항은 없는 것으로 보입니다. 이 모델은 분명히 원본 Apache 버전 2.0 LLaMA 파일을 기반으로 한 편집이지만 LLaMA에 대한 언급은 없습니다.

Yi 대 LLaMA 코드 비교. 코드 링크 : https://www.diffchecker.com/bJTqkvmQ/
또한, 이번 코드 변경 사항은 Pull Request를 통해 Transformers 프로젝트에 제출되지 않고, 이번 5월에는 외부 코드 형태로 첨부됩니다. 보안 위험이 있거나 프레임워크에서 지원되지 않습니다. HuggingFace 리더보드는 사용자 정의 코드 전략이 없기 때문에 최대 200K의 컨텍스트 창으로 이 모델을 벤치마킹하지도 않습니다.
32K 모델이라고 하는데 4K 모델로 구성되어 있고 RoPE 스케일링 구성도 없고 스케일링 방법에 대한 설명도 없습니다. (참고: Zero One Thousand Things는 이전에 모델 자체가 4K 시퀀스로 훈련되었지만 추론 단계에서는 32K로 확장될 수 있습니다. 현재 미세 조정 데이터에 대한 정보가 없습니다. 또한 의심스러울 정도로 높은 MMLU 점수를 포함하여 벤치마크 재현에 대한 지침도 제공하지 않았습니다.
인공지능 분야에서 한동안 일해본 사람이라면 이 말에 낯설지 않을 것입니다. 이거 허위광고인가요? 라이센스 위반? 실제로 벤치마크에서 부정행위를 한 것일까요? 무슨 상관이야? 우리는 서류를 바꿀 수도 있고, 이 경우에는 벤처 캐피탈 자금을 모두 가져갈 수도 있습니다. 최소한 Yi는 기본 모델이고 성능도 정말 좋기 때문에 기준 이상입니다
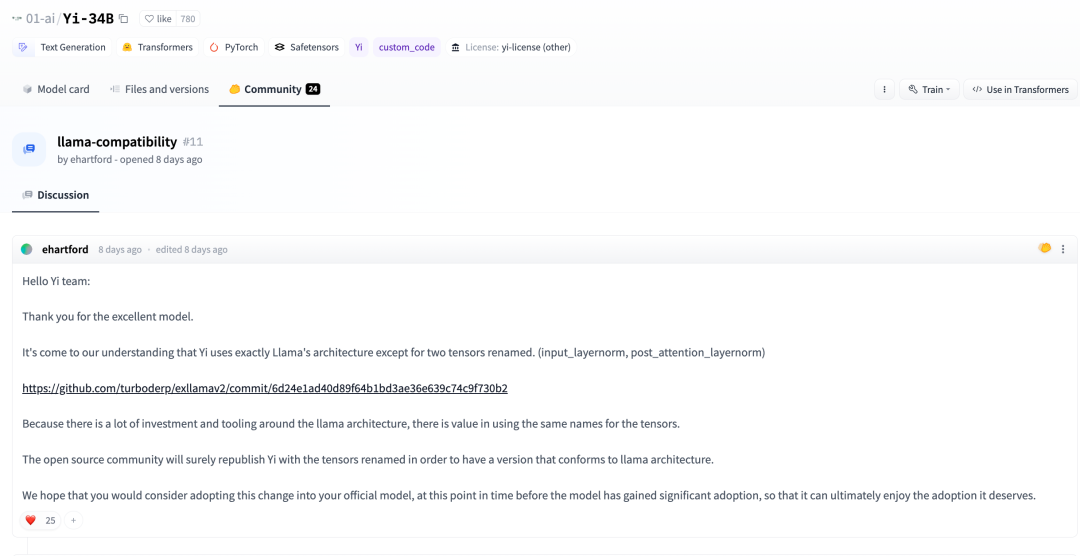
몇일 전 Huggingface 커뮤니티에서 한 개발자도 다음과 같이 지적했습니다.
저희가 파악한 바에 따르면, 추가로 Yi는 텐서 외에도 LLaMA 아키텍처를 완전히 채택했습니다. (input_layernorm, post_attention_layernorm)
토론 중에 일부 네티즌들은 다음과 같이 말했습니다. Meta LLaMA의 아키텍처, 코드 라이브러리 및 기타 관련 리소스를 정확하게 사용하려면 LLaMA
 에서 규정한 라이센스 계약을 준수해야 합니다.
에서 규정한 라이센스 계약을 준수해야 합니다.
LLaMA의 오픈 소스 라이센스를 준수하기 위해 개발자는 이름을 다시 변경하고 Huggingface에 다시 게시하기로 결정했습니다.
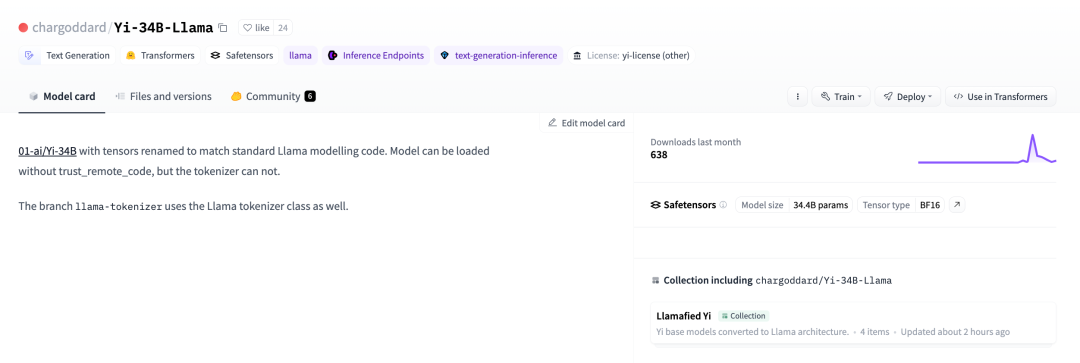 01-ai/Yi-34B, 텐서는 표준 LLaMA 모델과 일치하도록 이름이 변경되었습니다. 암호. 관련 링크: https://huggingface.co/chargoddard/Yi-34B-LLaMA
01-ai/Yi-34B, 텐서는 표준 LLaMA 모델과 일치하도록 이름이 변경되었습니다. 암호. 관련 링크: https://huggingface.co/chargoddard/Yi-34B-LLaMA
이 내용을 보면 Jia Yangqing이 Alibaba를 떠나 사업을 시작했다는 소식이 며칠 전 그의 친구들 사이에서 언급된 것으로 유추할 수 있습니다

이 문제와 관련하여 기계의 심장도 Zero One Thousand Things 표현이 검증되었습니다. Lingyiwu는 다음과 같이 답변했습니다.
GPT는 업계에서 인정받는 성숙한 아키텍처이며 LLaMA는 GPT에 대한 요약을 작성했습니다. Zero One Thousand Things의 대규모 R&D 모델의 구조 설계는 GPT의 성숙한 구조를 기반으로 하며 동시에 업계 최고 수준의 공개 결과를 바탕으로 Zero One Thousand Things 팀이 많은 작업을 수행했습니다. 모델에 대한 이해와 훈련에 대한 기초 중 하나를 처음으로 공개했습니다. 동시에 Zero One Thing은 모델 구조 수준에서 필수적인 혁신을 계속해서 탐구하고 있습니다.
모델 구조는 모델 학습의 일부일 뿐입니다. Yi의 오픈 소스 모델은 데이터 엔지니어링, 훈련 방법, 베이비 시팅(훈련 프로세스 모니터링) 기술, 하이퍼 매개변수 설정, 평가 방법, 평가 지표의 성격에 대한 깊이 있는 이해 및 원리에 대한 깊이 있는 연구와 같은 다른 측면에 중점을 둡니다. 모델 일반화 능력, 업계 최고 수준의 AI 인프라 역량 등 많은 연구개발과 기반 작업이 기본 구조보다 더 큰 역할과 가치를 발휘하는 경우가 많습니다. 대형 모델 사전 훈련 단계의 왜건 1대.
많은 훈련 실험을 수행하는 과정에서 실험 실행의 필요에 따라 코드 이름을 변경했습니다. 우리는 오픈 소스 커뮤니티의 피드백을 매우 중요하게 생각하며 Transformer 생태계에 더 잘 통합되도록 코드를 업데이트했습니다.
커뮤니티의 피드백에 매우 감사하며 오픈 소스 커뮤니티에서 이제 막 시작했으며 작업을 수행할 수 있기를 바랍니다. 모두가 함께 번영하는 커뮤니티를 만들기 위해 노력하겠습니다
위 내용은 LLaMA를 기반으로 하지만 텐서 이름을 변경한 이카이푸의 대형 모델이 논란을 일으켰고, 공식 답변은 여기까지입니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!