
딥러닝 과학 연구에서 코드와 실험을 효율적으로 관리하는 방법은 무엇일까요?

- PHPz앞으로
- 2023-10-23 11:21:011491검색
답변 1
저자: Ye Xiaofei
링크: https://www.zhihu.com/question/269707221/answer/2281374258
북미 메르세데스-벤츠에 착륙했을 때 일정 기간이 있었습니다. 다양한 구조와 매개변수를 테스트하기 위해 일주일에 100개 이상의 다양한 모델을 훈련할 수 있습니다 이러한 이유로 회사의 선배들의 관행과 내 생각을 결합하여 일련의 효율적인 코드 실험 관리 방법을 요약했습니다. 이제 프로젝트가 성공적으로 구현되는 데 도움이 되었습니다.
Yaml 파일을 사용하여 훈련 매개변수 구성
많은 오픈 소스 저장소가 입력 인수 구문 분석을 사용하여 많은 훈련 및 모델 관련 매개변수를 전송하는 것을 좋아한다는 것을 알고 있는데 이는 실제로 매우 비효율적입니다. 한편으로는 학습할 때마다 수많은 매개변수를 수동으로 입력해야 하는 번거로움이 따르며, 기본값을 직접 변경한 후 코드로 이동하여 변경한다면 시간이 많이 낭비될 것입니다. 여기에서는 Yaml 파일을 직접 사용하여 모든 모델 및 교육 관련 매개 변수를 제어하고 Yaml 이름을 모델 이름 및 타임스탬프와 연결하는 것이 좋습니다. 이는 다음과 같이 유명한 3D 포인트 클라우드 감지 라이브러리 OpenPCDet이 수행하는 작업입니다. 이 링크. github.com/open-mmlab/OpenPCDet/blob/master/tools/cfgs/kitti_models/pointrcnn.yaml
아래 그림과 같이 위에 제공된 링크에서 yaml 파일의 일부를 잘라냈습니다. 이 구성은 파일 커버 여기에는 포인트 클라우드 전처리 방법, 분류 유형, 백본의 다양한 매개변수, 최적화 및 손실 선택이 포함됩니다(그림에는 표시되지 않음, 자세한 내용은 위 링크를 참조하세요). 즉,
기본적으로 모델에 영향을 미칠 수 있는 모든 요소가 이 파일에 포함되어 있으며코드에서는 간단한 yaml.load()만 사용하면 dict에서 이러한 모든 매개변수를 읽을 수 있습니다. 더 중요한 것은 이 구성 파일을 체크포인트와 동일한 폴더에 저장할 수 있으므로 중단점 교육, 미세 조정 또는 직접 테스트에 직접 사용할 수 있다는 것입니다. 결과를 테스트에 사용하는 것도 매우 편리합니다. 해당 매개변수.
 코드 모듈화는 매우 중요합니다
코드 모듈화는 매우 중요합니다
일부 연구자들은 손실 함수와 모델을 함께 작성하는 등 코드를 작성할 때 전체 시스템을 과도하게 결합하는 것을 좋아하는데, 이로 인해 전체 시스템이 영향을 받는 경우가 많습니다. 특정 작은 부분을 변경하면 후속 인터페이스도 완전히 변경되므로 코드를 잘 모듈화하면 많은 시간을 절약할 수 있습니다. 일반적인 딥러닝 코드는 기본적으로 I/O 모듈, 전처리 모듈, 시각화 모듈, 모델 본체(대형 모델에 하위 모델이 포함된 경우 새 클래스를 추가해야 함) 등 여러 개의 큰 블록(pytorch를 예로 들어)으로 나눌 수 있습니다. , 손실 함수, 후처리 및 교육 또는 테스트 스크립트에 연결됩니다. 코드 모듈화의 또 다른 이점은 쉽게 읽을 수 있도록 yaml에서 매개변수의 다양한 측면을 정의할 수 있다는 것입니다. 또한 importlib 라이브러리는 많은 성숙한 코드에서 사용됩니다. 이를 통해 코드 학습 중에 사용할 모델이나 하위 모델을 결정할 수 없지만 yaml에서 직접 정의할 수 있습니다.
Tensorboard, tqdm
저는 기본적으로 매번 이 두 라이브러리를 사용합니다. Tensorboard는 훈련의 손실 곡선 변화를 매우 잘 추적할 수 있으므로 모델이 여전히 수렴되고 과적합되는지 여부를 더 쉽게 판단할 수 있습니다. 이미지 관련 작업을 수행하는 경우 시각화 결과를 모델에 적용할 수도 있습니다. 모델이 어떻게 작동하는지 기본적으로 확인하기 위해 텐서보드의 수렴 상태를 살펴봐야 하는 경우가 많습니다. Tqdm을 사용하면 학습 진행 상황을 직관적으로 추적하여 더 쉽게 수행할 수 있습니다. 조기 중지 .Github을 최대한 활용하세요여러 사람과 공동 개발을 하든, 단독 프로젝트를 진행하든 Github(회사에서는 비트버킷을 어느 정도 사용할 수 있음)를 사용하여 코드를 기록하는 것이 좋습니다. 자세한 내용은 제 답변을 참조하세요. 대학원생으로서 어떤 과학 연구 도구가 유용하다고 생각하시나요?https://www.zhihu.com/question/484596211/answer/2163122684
실험 결과 기록
답변 2
저자: Jason 링크: https://www.zhihu.com/question/269707221/answer/470576066
Git 관리 코드는 딥러닝이나 과학적 연구와 관련이 없습니다. 코드를 작성해야 합니다. 버전 관리 도구를 사용하세요. 개인적으로 GitHub를 사용할지 말지는 선택의 문제라고 생각합니다. 결국 회사의 모든 코드를 외부 Git에 연결하는 것은 불가능합니다.
반면에 수천 가지 버전을 테스트한 후에는 어떤 모델에 어떤 매개변수가 있는지 알 수 없을 것입니다. 좋은 습관이 매우 효과적입니다. 또한, 이전 버전의 구성 파일 호출을 용이하게 하기 위해 새로 추가된 매개변수에 대해 기본값을 제공하십시오.
2. 서로 다른 모델을 분리해 보세요
같은 프로젝트에서 좋은 재사용성은 매우 좋은 프로그래밍 습관이지만, 빠르게 발전하는 DL 코딩에서는 프로젝트가 작업 중심이라고 가정합니다. 예, 때로는 그럴 수도 있습니다. 방해가 되므로 재사용 가능한 일부 기능을 추출해 보십시오. 모델 구조와 관련하여 서로 다른 모델을 서로 다른 파일로 분리해 보십시오. 그러면 향후 업데이트가 더 편리해집니다. 그렇지 않으면 겉보기에 아름다워 보이는 디자인도 몇 달 후에는 쓸모 없게 될 것입니다.
3. 어느 정도 안정성을 유지하면서 프레임워크의 새 버전을 정기적으로 후속 조치합니다.
프로젝트 시작부터 끝까지 프레임워크가 여러 버전으로 업데이트되는 경우가 종종 있습니다. 새 버전에는 군침이 도는 기능이 있지만 안타깝게도 일부 API가 변경되었습니다. 따라서 프로젝트 내에서 프레임워크 버전을 안정적으로 유지하려고 노력할 수 있습니다. 프로젝트를 시작하기 전에 다양한 버전의 장단점을 고려해보세요.
또한, 다양한 프레임워크에 대해 관용적인 마음을 가지세요.
4. 훈련 세션에는 시간이 오래 걸립니다. 코딩 후 맹목적으로 실험을 시작하지 마세요. 개인적인 경험에 따르면 작은 데이터와 더 많은 로그를 실험하려면 디버그 모드를 제공하는 것이 좋습니다.
5. 언제든지 돌아가서 다시 시작해야 할 수 있으므로 모델 업데이트 성능의 변경 사항을 기록하세요.
저작자: OpenMMLab
링크: https://www.zhihu.com/question/269707221/answer/2480772257
출처: Zhihu
저작권은 저작자에게 있습니다. 상업적인 재인쇄의 경우 저자에게 연락하여 승인을 받으시기 바랍니다. 비상업적 재인쇄의 경우 출처를 명시해 주시기 바랍니다.
안녕하세요, 질문자님, 이전 답변에서는 Tensorboard, Weights&Biases, MLFlow, Neptune 및 기타 도구를 사용하여 실험 데이터를 관리하는 것에 대해 언급했습니다. 그러나 실험적인 관리 도구를 위해 점점 더 많은 바퀴가 만들어지면서 도구를 배우는 데 드는 비용이 점점 더 높아지고 있습니다. 어떻게 선택해야 할까요?
MMCV는 모든 환상을 충족시키며 구성 파일을 수정하여 도구를 전환할 수 있습니다.
github.com/open-mmlab/mmcv
Tensorboard는 실험 데이터를 기록합니다.
구성 파일:
log_config = dict( interval=1, hooks=[ dict(type='TextLoggerHook'), dict(type='TensorboardLoggerHook') ])
TensorBoard 데이터 시각화 효과
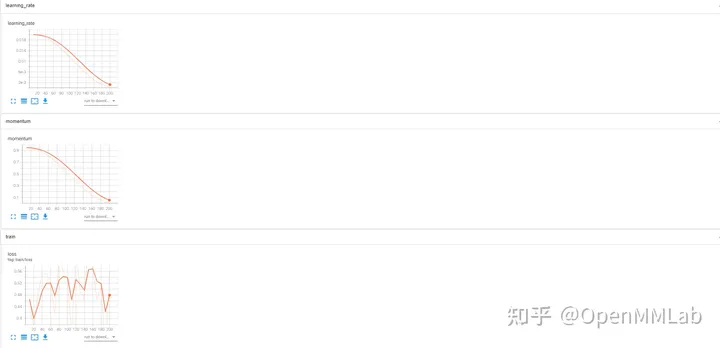
WandB는 실험 데이터를 기록합니다
Config 배급 파일
log_config = dict( interval=1, hooks=[ dict(type='TextLoggerHook'), dict(type='WandbLoggerHook') ])
Wandb 데이터 시각화 효과
(Python API로 wandb에 미리 로그인해야 함)
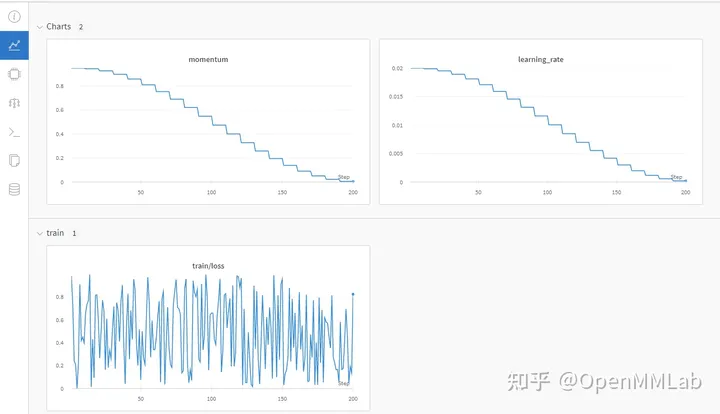
Neptume은 실험 데이터를 기록
구성 파일
log_config = dict( interval=1, hooks=[ dict(type='TextLoggerHook'), dict(type='NeptuneLoggerHook', init_kwargs=dict(project='Your Neptume account/mmcv')) ])
Neptume 시각화 효과
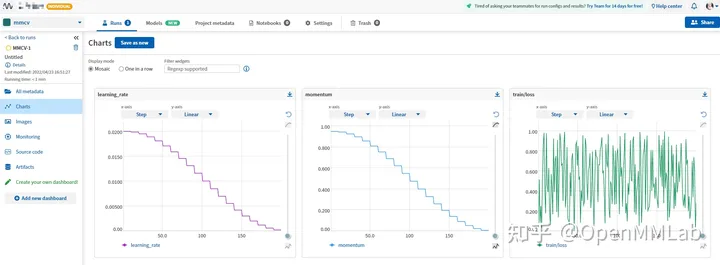
ml 흐름 기록 실험 data
구성 파일
log_config = dict( interval=1, hooks=[ dict(type='TextLoggerHook'), dict(type='MlflowLoggerHook') ])
MLFlow 시각화
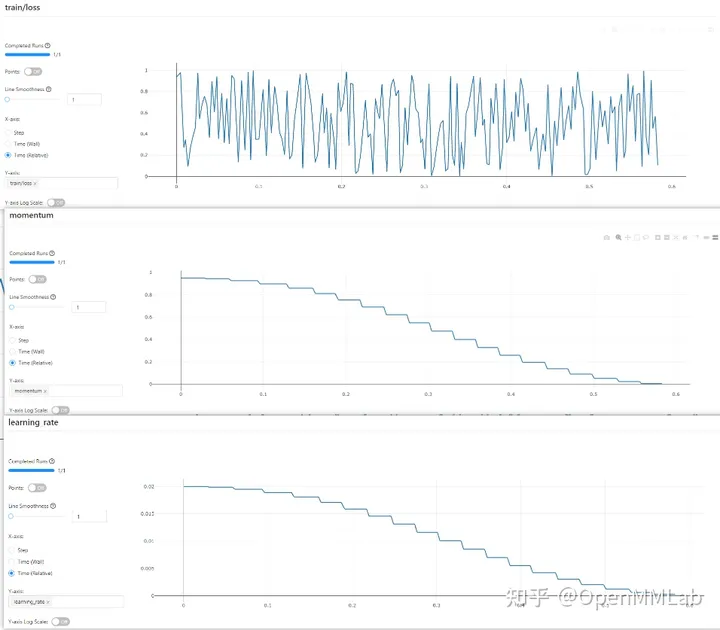
dvclive 실험 데이터 기록
구성 파일
log_config = dict( interval=1, hooks=[ dict(type='TextLoggerHook'), dict(type='DvcliveLoggerHook') ])
생성된 html 파일
위에서는 가장 기본적인 기능만 사용합니다. 다양한 실험 관리 도구의 , 프로필을 추가로 수정하여 더 많은 포즈를 잠금 해제할 수 있습니다.
MMCV를 갖는 것은 모든 실험 관리 도구를 갖는 것과 같습니다. 이전에 tf 소년이었다면 TensorBoard의 고전적인 향수 스타일을 선택할 수 있습니다. 모든 실험 데이터와 실험 환경을 기록하고 싶다면 Wandb(Weights & Biases) 또는 Neptume을 사용해 볼 수도 있습니다. 인터넷에 연결되어 있으면 mlflow를 선택하여 실험 데이터가 로컬에 저장되며 항상 적합한 도구가 있습니다.
또한 MMCV에는 TextLoggerHook이라는 자체 로그 관리 시스템도 있습니다! 장치 환경, 데이터 세트, 모델 초기화 방법, 손실, 메트릭 및 훈련 중에 생성된 기타 정보와 같이 훈련 프로세스 중에 생성된 모든 정보를 로컬 xxx.log 파일에 저장합니다. 도구를 사용하지 않고도 이전 실험 데이터를 검토할 수 있습니다.
아직도 어떤 실험 관리 도구를 사용해야 할지 궁금하신가요? 아직도 다양한 도구의 학습비용이 걱정되시나요? 서둘러 MMCV에 탑승하여 단 몇 줄의 구성 파일만으로 다양한 도구를 손쉽게 경험해 보세요.
github.com/open-mmlab/mmcv
위 내용은 딥러닝 과학 연구에서 코드와 실험을 효율적으로 관리하는 방법은 무엇일까요?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!