
더욱 다재다능하고 효과적인 Ant 자체 개발 옵티마이저 WSAM이 KDD Oral에 채택되었습니다.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-10-10 12:13:09828검색
심층신경망(DNN)의 일반화 능력은 극점의 평탄성과 밀접한 관련이 있으므로, 일반화 능력을 향상시키기 위해 더 평탄한 극점을 찾는 SAM(Sharpness-Aware Minimization) 알고리즘이 등장했습니다. 본 논문에서는 SAM의 손실 함수를 재검토하고 평탄성을 정규화 용어로 사용하여 훈련 극단점의 평탄성을 향상시키는 보다 일반적이고 효과적인 방법인 WSAM을 제안합니다. 다양한 공개 데이터 세트에 대한 실험에서는 원래 최적화 프로그램인 SAM 및 그 변형과 비교하여 WSAM이 대부분의 경우 더 나은 일반화 성능을 달성한다는 것을 보여줍니다. WSAM은 또한 Ant의 내부 디지털 결제, 디지털 금융 및 기타 시나리오에 널리 채택되어 놀라운 결과를 얻었습니다. 이 논문은 KDD '23에 Oral Paper로 승인되었습니다.

- 문서 주소: https://arxiv.org/pdf/2305.15817.pdf
- 코드 주소: https://github.com/int 엘리 젠트 - machine-learning/dlrover/tree/master/atorch/atorch/optimizers
딥 러닝 기술의 발전으로 고도로 매개변수화된 DNN은 CV 및 NLP와 같은 다양한 기계 학습 시나리오에서 뛰어난 결과를 달성했습니다. 성공. 과도하게 매개변수화된 모델은 훈련 데이터에 과적합되는 경향이 있지만 일반적으로 일반화 기능이 뛰어납니다. 일반화의 미스터리는 점점 더 많은 관심을 끌며 딥러닝 분야에서 인기 있는 연구 주제가 되었습니다.
최신 연구에 따르면 일반화 능력은 극점의 평탄성과 밀접한 관련이 있는 것으로 나타났습니다. 즉, 손실 함수의 "풍경"에 평탄한 극단 점이 존재하면 일반화 오류가 더 작아질 수 있습니다. Sharpness-Aware Minimization(SAM)[1]은 더 평탄한 극점을 찾는 기술로 현재 가장 유망한 기술 방향 중 하나로 간주됩니다. SAM 기술은 컴퓨터 비전, 자연어 처리, 2계층 학습 등 다양한 분야에서 널리 사용되며 이러한 분야에서 이전의 최첨단 방법보다 훨씬 뛰어난 성능을 발휘합니다.
더 평평한 최소값을 탐색하기 위해 SAM은 손실 함수를 정의합니다. w에서 L 의 평탄도는 다음과 같습니다.
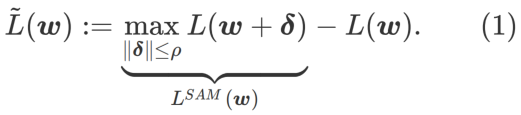
GSAM [2]은 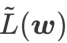 이 극단점에서 헤시안 행렬의 최대 고유값에 대한 근사치라는 것을 증명했습니다. 그
이 극단점에서 헤시안 행렬의 최대 고유값에 대한 근사치라는 것을 증명했습니다. 그 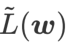 는 정말 평평한(가파른) 효과적인 측정입니다. 그러나
는 정말 평평한(가파른) 효과적인 측정입니다. 그러나 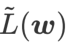 는 최소 지점이 아닌 더 평평한 영역을 찾는 데만 사용할 수 있으며 이로 인해 손실 함수가 손실 값이 여전히 큰 지점으로 수렴될 수 있습니다(주변 영역은 평평하지만). 따라서 SAM은
는 최소 지점이 아닌 더 평평한 영역을 찾는 데만 사용할 수 있으며 이로 인해 손실 함수가 손실 값이 여전히 큰 지점으로 수렴될 수 있습니다(주변 영역은 평평하지만). 따라서 SAM은 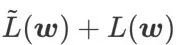 , 즉
, 즉 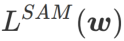 을 손실 함수로 사용합니다. 이는
을 손실 함수로 사용합니다. 이는 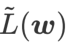 와
와 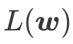 사이에서 더 평평한 표면과 더 작은 손실 값을 찾는 것 사이의 절충안으로 볼 수 있으며, 둘 다 동일한 가중치가 부여됩니다.
사이에서 더 평평한 표면과 더 작은 손실 값을 찾는 것 사이의 절충안으로 볼 수 있으며, 둘 다 동일한 가중치가 부여됩니다.
이 기사에서는 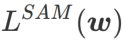 의 구성을 다시 생각하고
의 구성을 다시 생각하고 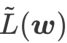 를 정규화 용어로 취급합니다. 우리는 WSAM(Weighted Sharpness-Aware Minimization)이라는 보다 일반적이고 효과적인 알고리즘을 개발했습니다. 이 알고리즘의 손실 함수는 정규화 항으로 가중 평탄성 항
를 정규화 용어로 취급합니다. 우리는 WSAM(Weighted Sharpness-Aware Minimization)이라는 보다 일반적이고 효과적인 알고리즘을 개발했습니다. 이 알고리즘의 손실 함수는 정규화 항으로 가중 평탄성 항 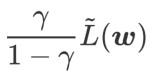 을 추가합니다. 여기서 하이퍼파라미터
을 추가합니다. 여기서 하이퍼파라미터 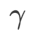 가 가중치를 제어합니다. 방법 소개 장에서
가 가중치를 제어합니다. 방법 소개 장에서 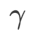 를 사용하여 손실 함수를 안내하여 더 평평하거나 더 작은 극단점을 찾는 방법을 시연했습니다. 우리의 주요 기여는 다음과 같이 요약될 수 있습니다.
를 사용하여 손실 함수를 안내하여 더 평평하거나 더 작은 극단점을 찾는 방법을 시연했습니다. 우리의 주요 기여는 다음과 같이 요약될 수 있습니다.
- 평탄성을 정규화 용어로 취급하고 다양한 작업 간에 서로 다른 가중치를 부여하는 WSAM을 제안합니다. 우리는 현재 단계의 평탄성을 정확하게 반영하는 것을 목표로 업데이트 공식에서 정규화 항을 처리하는 "가중치 분리" 기술을 제안합니다. SGDM 및 Adam과 같이 기본 최적화 프로그램이 SGD가 아닌 경우 WSAM은 형식이 SAM과 크게 다릅니다. 절제 실험에서는 이 기술이 대부분의 경우 성능을 향상시키는 것으로 나타났습니다.
- 공개 데이터 세트의 일반적인 작업에 대한 WSAM의 효율성을 검증했습니다. 실험 결과에 따르면 SAM 및 그 변형과 비교하여 WSAM은 대부분의 상황에서 일반화 성능이 더 우수합니다.
사전 지식
SAM은 식(1)으로 정의된 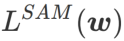 의 미니맥스 최적화 문제를 해결하기 위한 기술입니다.
의 미니맥스 최적화 문제를 해결하기 위한 기술입니다.
먼저 SAM은 w 주위의 1차 Taylor 확장을 사용하여 내부 계층의 최대화 문제를 근사화합니다. 즉, ,
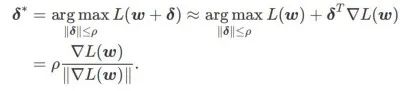
두 번째, SAM은 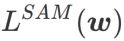 의 대략적인 기울기를 취하여 w를 업데이트합니다. 즉,
의 대략적인 기울기를 취하여 w를 업데이트합니다. 즉,
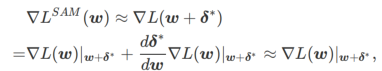
두 번째 근사치는 계산 속도를 높이는 것입니다. 다른 그래디언트 기반 최적화 프로그램(기본 최적화 프로그램이라고 함)은 SAM의 일반 프레임워크에 통합될 수 있습니다. 자세한 내용은 알고리즘 1을 참조하세요. 알고리즘 1에서  및
및  을 변경하면 SGD, SGDM 및 Adam과 같은 다양한 기본 최적화 프로그램을 얻을 수 있습니다. 탭 1을 참조하세요. 기본 최적화 프로그램이 SGD인 경우 알고리즘 1은 SAM 문서[1]의 원래 SAM으로 대체됩니다.
을 변경하면 SGD, SGDM 및 Adam과 같은 다양한 기본 최적화 프로그램을 얻을 수 있습니다. 탭 1을 참조하세요. 기본 최적화 프로그램이 SGD인 경우 알고리즘 1은 SAM 문서[1]의 원래 SAM으로 대체됩니다.


방법 소개
WSAM의 설계 세부 사항
여기에서는 정규 손실과 평탄성 항으로 구성된 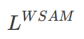 의 형식적 정의를 제공합니다. 공식 (1)에서
의 형식적 정의를 제공합니다. 공식 (1)에서
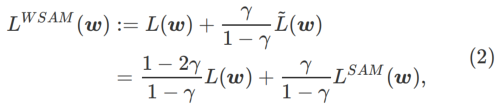
그 중에 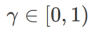 .
. 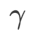 =0일 때
=0일 때 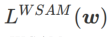 는 일반 손실로 변질됩니다.
는 일반 손실로 변질됩니다. 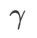 =1/2일 때
=1/2일 때 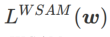 는
는 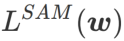
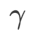 >1/2일 때 가 평탄성에 더 주의를 기울입니다. SAM과 마찬가지로 손실 값이 작은 것보다 곡률이 작은 점을 더 쉽게 찾을 수 있으며 그 반대도 마찬가지입니다.
>1/2일 때 가 평탄성에 더 주의를 기울입니다. SAM과 마찬가지로 손실 값이 작은 것보다 곡률이 작은 점을 더 쉽게 찾을 수 있으며 그 반대도 마찬가지입니다. 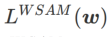
다양한 기본 최적화 프로그램을 포함하는 WSAM의 일반 프레임워크는 서로 다른 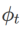 및
및 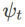 을 선택하여 구현할 수 있습니다. 알고리즘 2를 참조하세요. 예를 들어
을 선택하여 구현할 수 있습니다. 알고리즘 2를 참조하세요. 예를 들어  및
및 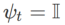 경우 기본 최적화 프로그램이 SGD인 WSAM을 얻습니다. 알고리즘 3을 참조하세요. 여기서는 평탄도 항이 기울기 계산 및 가중치 업데이트를 위한 기본 최적화 프로그램과 통합되지 않고 독립적으로 계산되는 "가중치 분리" 기술을 채택합니다(알고리즘 2의 7행 마지막 항). 이러한 방식으로 정규화의 효과는 추가 정보 없이 현재 단계의 평탄성만 반영합니다. 비교를 위해 알고리즘 4는 "가중치 분리"(Coupled-WSAM이라고 함) 없이 WSAM을 제공합니다. 예를 들어 기본 최적화 프로그램이 SGDM인 경우 Coupled-WSAM의 정규화 용어는 평탄성의 지수 이동 평균입니다. 실험 섹션에서 볼 수 있듯이 "가중치 분리"는 대부분의 경우 일반화 성능을 향상시킬 수 있습니다.
경우 기본 최적화 프로그램이 SGD인 WSAM을 얻습니다. 알고리즘 3을 참조하세요. 여기서는 평탄도 항이 기울기 계산 및 가중치 업데이트를 위한 기본 최적화 프로그램과 통합되지 않고 독립적으로 계산되는 "가중치 분리" 기술을 채택합니다(알고리즘 2의 7행 마지막 항). 이러한 방식으로 정규화의 효과는 추가 정보 없이 현재 단계의 평탄성만 반영합니다. 비교를 위해 알고리즘 4는 "가중치 분리"(Coupled-WSAM이라고 함) 없이 WSAM을 제공합니다. 예를 들어 기본 최적화 프로그램이 SGDM인 경우 Coupled-WSAM의 정규화 용어는 평탄성의 지수 이동 평균입니다. 실험 섹션에서 볼 수 있듯이 "가중치 분리"는 대부분의 경우 일반화 성능을 향상시킬 수 있습니다. 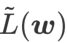



그림 1은 다양한 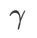 값에 따른 WSAM 업데이트 프로세스를 보여줍니다.
값에 따른 WSAM 업데이트 프로세스를 보여줍니다. 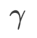 ,
, 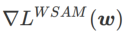 이
이 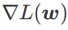 과
과 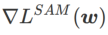 사이에 있을 때
사이에 있을 때 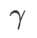 가 증가함에 따라 점차
가 증가함에 따라 점차 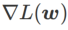 에서 벗어나게 됩니다.
에서 벗어나게 됩니다.

간단한 예
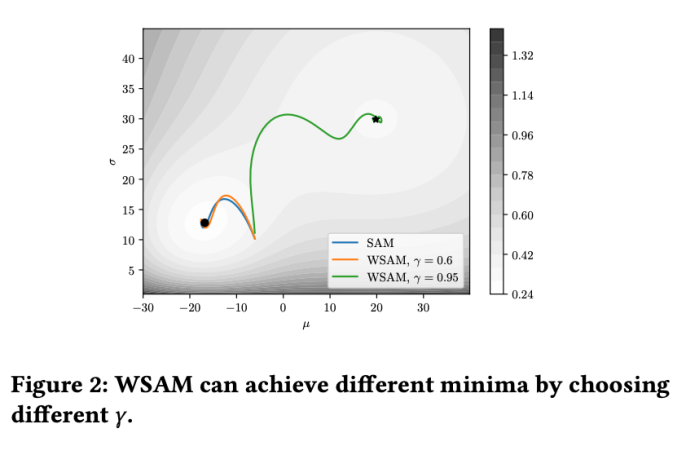
WSAM에서 γ의 효과와 장점을 더 잘 설명하기 위해 2차원의 간단한 예를 설정했습니다. 그림 2에서 보는 바와 같이 손실 함수는 왼쪽 하단에 상대적으로 고르지 않은 극단점(위치: (-16.8, 12.8), 손실 값: 0.28)이 있고, 오른쪽 상단에 평평한 극단점(위치: (19.8, 29.9), 손실 값: 0.36). 손실 함수는 다음과 같이 정의됩니다. 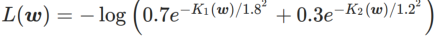 , 여기서
, 여기서 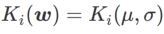 는 일변량 가우스 모델과 두 정규 분포, 즉
는 일변량 가우스 모델과 두 정규 분포, 즉 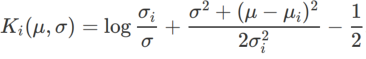 사이의 KL 발산입니다. 여기서
사이의 KL 발산입니다. 여기서 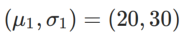 및
및 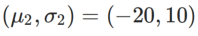 입니다.
입니다.
기본 최적화 프로그램으로 모멘텀 0.9의 SGDM을 사용하고 SAM 및 WSAM에 대해 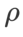 =2로 설정합니다. 초기점(-6, 10)부터 시작하여 학습률 5를 사용하여 150단계로 손실 함수를 최적화합니다. SAM은 손실값은 낮지만 불균일성이 더 큰 극단점으로 수렴하며,
=2로 설정합니다. 초기점(-6, 10)부터 시작하여 학습률 5를 사용하여 150단계로 손실 함수를 최적화합니다. SAM은 손실값은 낮지만 불균일성이 더 큰 극단점으로 수렴하며, 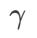 =0.6인 WSAM도 비슷합니다. 그러나
=0.6인 WSAM도 비슷합니다. 그러나 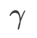 =0.95는 손실 함수를 평탄한 극단점으로 수렴하게 하며, 이는 보다 강력한 평탄성 정규화가 중요한 역할을 함을 나타냅니다.
=0.95는 손실 함수를 평탄한 극단점으로 수렴하게 하며, 이는 보다 강력한 평탄성 정규화가 중요한 역할을 함을 나타냅니다.
Experiments
WSAM의 효율성을 검증하기 위해 다양한 작업에 대한 실험을 진행했습니다.
이미지 분류
우리는 먼저 Cifar10 및 Cifar100 데이터 세트에서 처음부터 훈련 모델에 대한 WSAM의 효과를 연구했습니다. 우리가 선택한 모델에는 ResNet18 및 WideResNet-28-10이 포함됩니다. ResNet18 및 WideResNet-28-10에 대해 각각 사전 정의된 배치 크기 128, 256을 사용하여 Cifar10 및 Cifar100에서 모델을 교육합니다. 여기에 사용된 기본 최적화 프로그램은 모멘텀 0.9의 SGDM입니다. SAM [1]의 설정에 따르면 각 기본 최적화 프로그램은 SAM 클래스 최적화 프로그램보다 두 배의 epoch 횟수를 실행합니다. 우리는 두 모델을 모두 400세대(SAM 클래스 최적화 프로그램의 경우 200세대) 동안 훈련했으며 코사인 스케줄러를 사용하여 학습 속도를 감소시켰습니다. 여기서는 컷아웃 및 AutoAugment와 같은 다른 고급 데이터 증대 방법을 사용하지 않습니다.
두 모델 모두 공동 그리드 검색을 사용하여 기본 최적화 프로그램의 학습률과 가중치 감소 계수를 결정하고 다음 SAM 클래스 최적화 프로그램 실험에서 이를 일정하게 유지합니다. 학습률과 가중치 감쇠 계수의 검색 범위는 각각 {0.05, 0.1} 및 {1e-4, 5e-4, 1e-3}입니다. 모든 SAM 클래스 최적화 프로그램에는 하나의 하이퍼 매개변수 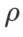 (이웃 크기)가 있으므로 다음으로 SAM 최적화 프로그램에서 가장 좋은
(이웃 크기)가 있으므로 다음으로 SAM 최적화 프로그램에서 가장 좋은 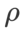 을 검색하고 다른 SAM 클래스 최적화 프로그램에 동일한 값을 사용합니다.
을 검색하고 다른 SAM 클래스 최적화 프로그램에 동일한 값을 사용합니다. 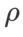 의 검색 범위는 {0.01, 0.02, 0.05, 0.1, 0.2, 0.5}입니다. 마지막으로 다른 SAM 클래스 최적화 프로그램의 고유 하이퍼파라미터를 검색했으며 검색 범위는 해당 원본 기사의 권장 범위에서 나왔습니다. GSAM [2]의 경우 {0.01, 0.02, 0.03, 0.1, 0.2, 0.3} 범위에서 검색합니다. ESAM [3]의 경우 {0.4, 0.5, 0.6} 범위에서
의 검색 범위는 {0.01, 0.02, 0.05, 0.1, 0.2, 0.5}입니다. 마지막으로 다른 SAM 클래스 최적화 프로그램의 고유 하이퍼파라미터를 검색했으며 검색 범위는 해당 원본 기사의 권장 범위에서 나왔습니다. GSAM [2]의 경우 {0.01, 0.02, 0.03, 0.1, 0.2, 0.3} 범위에서 검색합니다. ESAM [3]의 경우 {0.4, 0.5, 0.6} 범위에서  , {0.4, 0.5, 0.6} 범위에서
, {0.4, 0.5, 0.6} 범위에서 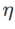 , {0.4, 0.5, 0.6} 범위에서
, {0.4, 0.5, 0.6} 범위에서 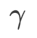 을 검색합니다. . WSAM의 경우 {0.5, 0.6, 0.7, 0.8, 0.82, 0.84, 0.86, 0.88, 0.9, 0.92, 0.94, 0.96} 범위에서
을 검색합니다. . WSAM의 경우 {0.5, 0.6, 0.7, 0.8, 0.82, 0.84, 0.86, 0.88, 0.9, 0.92, 0.94, 0.96} 범위에서 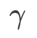 를 검색합니다. 서로 다른 무작위 시드를 사용하여 실험을 5회 반복하고 평균 오차와 표준편차를 계산했습니다. 단일 카드 NVIDIA A100 GPU에 대한 실험을 수행합니다. 각 모델의 최적화 하이퍼파라미터는 표 3에 요약되어 있습니다.
를 검색합니다. 서로 다른 무작위 시드를 사용하여 실험을 5회 반복하고 평균 오차와 표준편차를 계산했습니다. 단일 카드 NVIDIA A100 GPU에 대한 실험을 수행합니다. 각 모델의 최적화 하이퍼파라미터는 표 3에 요약되어 있습니다.
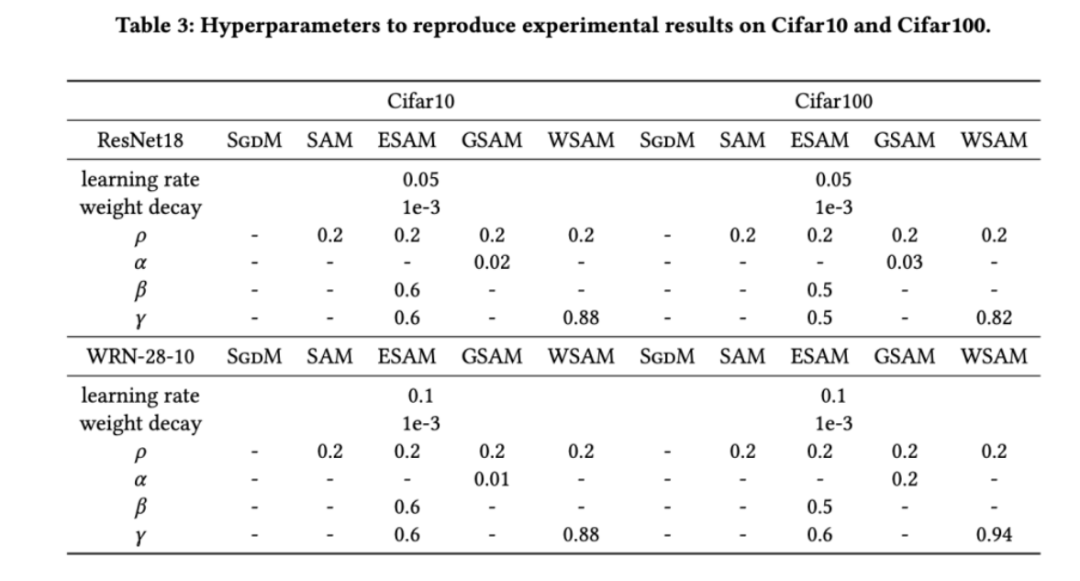
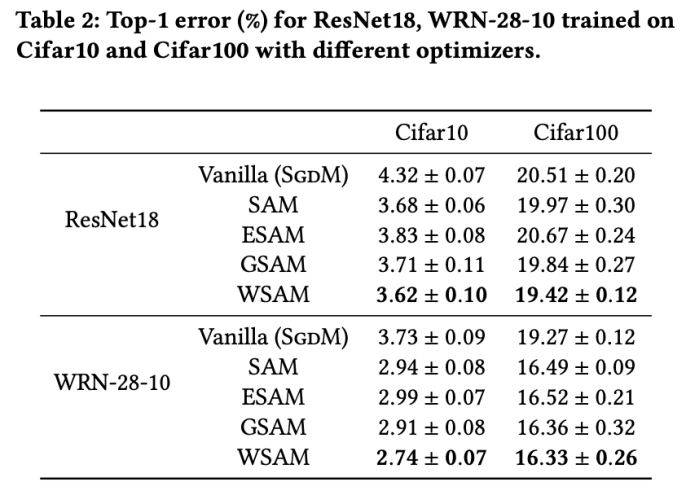
Tab.2는 다양한 최적화 프로그램에서 Cifar10 및 Cifar100의 테스트 세트에 대한 ResNet18, WRN-28-10의 상위 1 오류율을 제공합니다. 기본 최적화 프로그램과 비교하여 SAM 클래스 최적화 프로그램은 성능을 크게 향상시키는 동시에 다른 SAM 클래스 최적화 프로그램보다 훨씬 뛰어납니다.
ImageNet에 대한 추가 교육
Data-Efficient Image Transformers 네트워크 구조를 사용하여 ImageNet 데이터세트에 대한 실험을 추가로 수행합니다. 사전 훈련된 DeiT 기반 체크포인트를 재개한 다음 세 에포크 동안 훈련을 계속합니다. 모델은 배치 크기 256을 사용하여 학습되었으며 기본 최적화 프로그램은 운동량 0.9의 SGDM, 가중치 감소 계수는 1e-4, 학습 속도는 1e-5입니다. 4카드 NVIDIA A100 GPU에서 5회 실행을 반복하고 평균 오류와 표준편차를 계산했습니다
{0.05, 0.1, 0.5, 1.0,⋯ , 6.0}에서 SAM의 가장 좋은 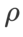 을 검색했습니다. . 최적의
을 검색했습니다. . 최적의 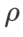 =5.5는 다른 SAM 클래스 최적화 프로그램에서 직접 사용됩니다. 그 후, 우리는 {0.01, 0.02, 0.03, 0.1, 0.2, 0.3}에서 GSAM의 최고
=5.5는 다른 SAM 클래스 최적화 프로그램에서 직접 사용됩니다. 그 후, 우리는 {0.01, 0.02, 0.03, 0.1, 0.2, 0.3}에서 GSAM의 최고  를 검색하고 0.02 단계 크기로 0.80과 0.98 사이에서 WSAM의 최고
를 검색하고 0.02 단계 크기로 0.80과 0.98 사이에서 WSAM의 최고 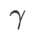 을 검색합니다.
을 검색합니다.
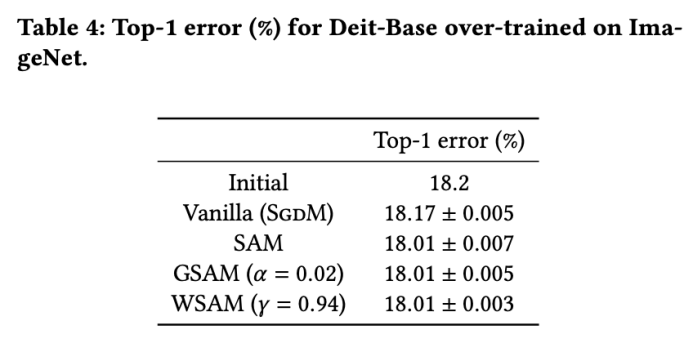
모델의 초기 Top-1 오류율은 18.2%이며, 3개의 추가 Epoch 이후의 오류율은 탭 4에 표시됩니다. 우리는 세 가지 SAM 유사 최적화 프로그램 간에 큰 차이점을 찾지 못했지만 모두 기본 최적화 프로그램보다 성능이 뛰어났으며 이는 더 평탄한 극단점을 찾을 수 있고 더 나은 일반화 기능을 가질 수 있음을 나타냅니다.
레이블 노이즈에 대한 견고성
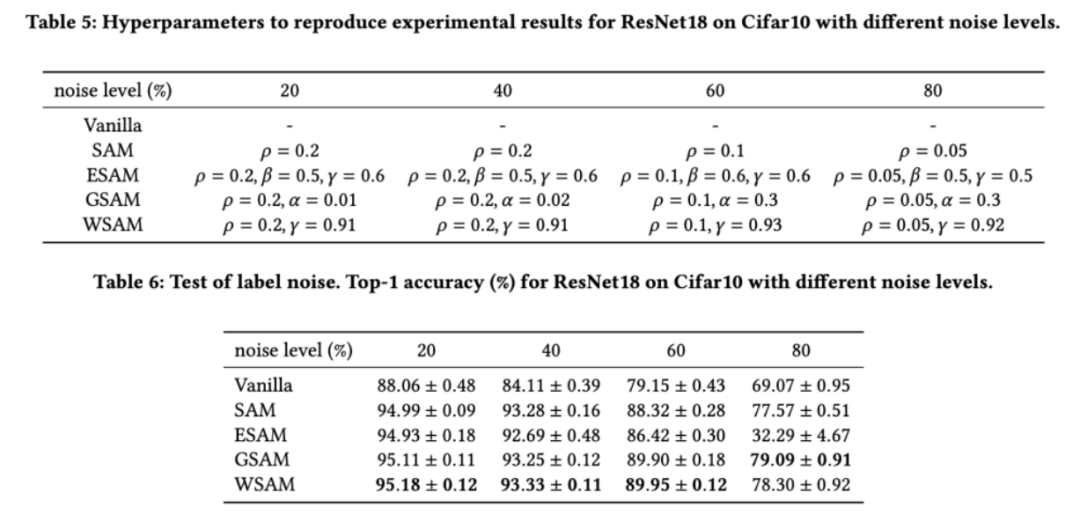
이전 연구 [1, 4, 5]에서 볼 수 있듯이 SAM 클래스 최적화 프로그램은 훈련 세트에 레이블 노이즈가 있을 때 좋은 견고성을 나타냅니다. 여기서는 WSAM의 견고성을 SAM, ESAM 및 GSAM과 비교합니다. Cifar10 데이터 세트에서 ResNet18을 200세대 동안 훈련하고 노이즈 수준이 20%, 40%, 60% 및 80%인 대칭 레이블 노이즈를 주입합니다. 기본 최적화 프로그램으로 모멘텀 0.9, 배치 크기 128, 학습률 0.05, 가중치 감소 계수 1e-3, 코사인 스케줄러를 사용하여 학습률을 감소시키는 SGDM을 사용합니다. 각 라벨 노이즈 수준에 대해 보편적인 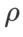 값을 결정하기 위해 {0.01, 0.02, 0.05, 0.1, 0.2, 0.5} 범위 내의 SAM에서 그리드 검색을 수행했습니다. 그런 다음 최적의 일반화 성능을 찾기 위해 다른 최적화 프로그램 관련 하이퍼 매개변수를 개별적으로 검색합니다. 표 5에는 결과를 재현하는 데 필요한 하이퍼파라미터가 나열되어 있습니다. 견고성 테스트 결과는 표 6에 나와 있습니다. WSAM은 일반적으로 SAM, ESAM 및 GSAM보다 견고성이 좋습니다.
값을 결정하기 위해 {0.01, 0.02, 0.05, 0.1, 0.2, 0.5} 범위 내의 SAM에서 그리드 검색을 수행했습니다. 그런 다음 최적의 일반화 성능을 찾기 위해 다른 최적화 프로그램 관련 하이퍼 매개변수를 개별적으로 검색합니다. 표 5에는 결과를 재현하는 데 필요한 하이퍼파라미터가 나열되어 있습니다. 견고성 테스트 결과는 표 6에 나와 있습니다. WSAM은 일반적으로 SAM, ESAM 및 GSAM보다 견고성이 좋습니다.
탐사 기하학의 영향
SAM과 유사한 최적화 프로그램은 ASAM [4] 및 Fisher SAM [5]과 같은 기술과 결합하여 탐사 지역의 모양을 적응적으로 조정할 수 있습니다. 우리는 적응형 정보 방법과 Fisher 정보 방법을 각각 사용할 때 SAM과 WSAM의 성능을 비교하기 위해 Cifar10에서 WRN-28-10에 대한 실험을 수행하여 탐사 영역의 기하학적 구조가 SAM과 유사한 최적화 프로그램의 일반화 성능에 어떻게 영향을 미치는지 이해합니다.
매개변수 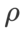 및
및 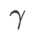 를 제외하고 이미지 분류에서 구성을 재사용했습니다. 이전 연구[4, 5]에 따르면 ASAM과 Fisher SAM의
를 제외하고 이미지 분류에서 구성을 재사용했습니다. 이전 연구[4, 5]에 따르면 ASAM과 Fisher SAM의 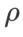 는 일반적으로 더 큽니다. 우리는 {0.1, 0.5, 1.0,…, 6.0}에서 가장 좋은
는 일반적으로 더 큽니다. 우리는 {0.1, 0.5, 1.0,…, 6.0}에서 가장 좋은 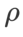 을 검색하며 ASAM과 Fisher SAM에 대한 가장 좋은
을 검색하며 ASAM과 Fisher SAM에 대한 가장 좋은 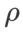 은 모두 5.0입니다. 그 후, 우리는 0.80과 0.94 사이에서 0.02의 단계 크기로 WSAM의 최고
은 모두 5.0입니다. 그 후, 우리는 0.80과 0.94 사이에서 0.02의 단계 크기로 WSAM의 최고 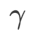 를 검색했으며 두 방법 모두 최고
를 검색했으며 두 방법 모두 최고 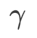 는 0.88이었습니다.
는 0.88이었습니다.
놀랍게도 표 7에서 볼 수 있듯이 기준 WSAM은 여러 후보 간에도 더 나은 일반화를 보여줍니다. 따라서 고정된 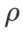 기준선과 함께 WSAM을 사용하는 것이 좋습니다.
기준선과 함께 WSAM을 사용하는 것이 좋습니다.

절제 실험
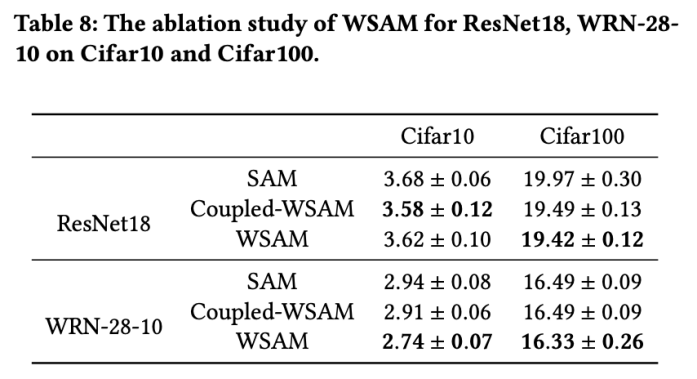
이 섹션에서는 WSAM에서 "무게 분리" 기술의 중요성을 깊이 이해하기 위해 절제 실험을 수행합니다. WSAM의 설계 세부 사항에 설명된 대로 "가중치 분리"(알고리즘 4) Coupled-WSAM이 없는 WSAM 변형을 원래 방법과 비교합니다.
결과는 탭 8에 나와 있습니다. Coupled-WSAM은 대부분의 경우 SAM보다 더 나은 결과를 생성하며 WSAM은 대부분의 경우 결과를 더욱 향상시켜 "가중치 분리" 기술의 효율성을 입증합니다.
극점 분석
여기에서는 WSAM 옵티마이저와 SAM 옵티마이저가 찾은 극점점 간의 차이를 비교하여 WSAM 옵티마이저에 대한 이해를 더욱 깊게 합니다. 극단점의 평탄도(가파름)는 헤세 행렬의 최대 고유값으로 설명할 수 있습니다. 고유값이 클수록 덜 평탄합니다. 이 최대 고유값을 계산하기 위해 Power Iteration 알고리즘을 사용합니다.
Tab.9는 SAM과 WSAM 최적화 프로그램이 찾은 극단점의 차이를 보여줍니다. 바닐라 옵티마이저가 찾은 극단점은 손실 값이 작지만 덜 평탄한 반면, SAM이 찾은 극단점은 손실 값이 크지만 더 평탄하여 일반화 성능이 향상되는 것을 발견했습니다. 흥미롭게도 WSAM이 찾아낸 극한점은 SAM보다 손실값이 훨씬 작을 뿐만 아니라 SAM에 매우 가까운 평탄도를 가지고 있습니다. 이는 WSAM이 극한점을 찾는 과정에서 더 평탄한 영역을 찾으려고 노력하면서 더 작은 손실 값을 보장하는 것을 우선시한다는 것을 보여줍니다.
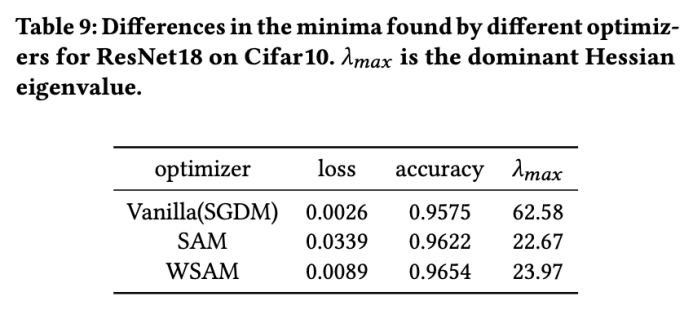
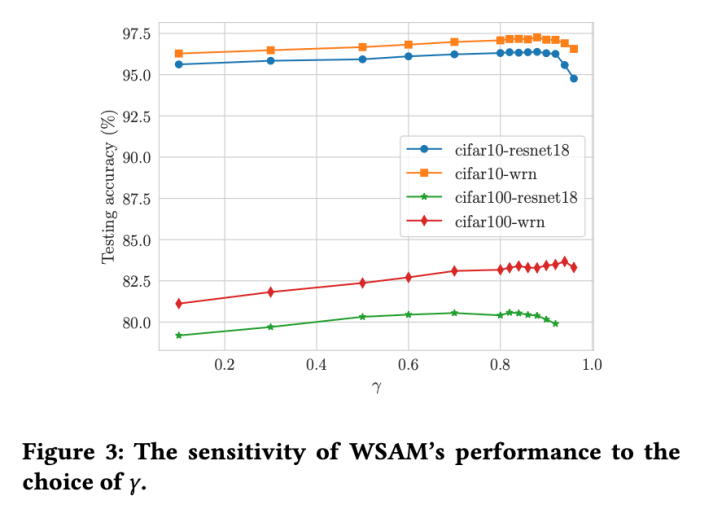
Hyperparameter Sensitivity
SAM과 비교하여 WSAM에는 평탄(가파른) 차수 항의 크기를 조정하기 위한 추가 하이퍼 매개변수 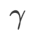 가 있습니다. 여기서는 이 하이퍼 매개변수에 대한 WSAM의 일반화 성능 민감도를 테스트합니다. 우리는 광범위한
가 있습니다. 여기서는 이 하이퍼 매개변수에 대한 WSAM의 일반화 성능 민감도를 테스트합니다. 우리는 광범위한 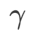 값을 사용하여 Cifar10 및 Cifar100에서 WSAM을 사용하여 ResNet18 및 WRN-28-10 모델을 교육했습니다. 그림 3에서 볼 수 있듯이 결과는 WSAM이 하이퍼파라미터
값을 사용하여 Cifar10 및 Cifar100에서 WSAM을 사용하여 ResNet18 및 WRN-28-10 모델을 교육했습니다. 그림 3에서 볼 수 있듯이 결과는 WSAM이 하이퍼파라미터 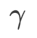 선택에 민감하지 않음을 보여줍니다. 또한 WSAM의 최적 일반화 성능은 거의 항상 0.8에서 0.95 사이라는 것을 발견했습니다.
선택에 민감하지 않음을 보여줍니다. 또한 WSAM의 최적 일반화 성능은 거의 항상 0.8에서 0.95 사이라는 것을 발견했습니다.
위 내용은 더욱 다재다능하고 효과적인 Ant 자체 개발 옵티마이저 WSAM이 KDD Oral에 채택되었습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!