
Apple 코어는 계산 정확도를 저하시키지 않고 대규모 모델을 실행합니다. GPT-4도 사용됩니다.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-09-08 11:25:08848검색
코드 라마가 나오자마자 누군가 정량적 슬리밍을 계속할 것이라고 다들 기대했는데 다행히 로컬에서도 실행이 가능하네요
역시 llama.cpp 작성자인 Georgi Gerganov가 조치를 취했는데, 이번에는 그렇게 했습니다. 루틴을 따르지 마세요:
양자화되지 않음, Code LLama의 34B 코드는 FP16 정밀도로도 Apple 컴퓨터에서 실행될 수 있으며 추론 속도는 초당 20개 토큰을 초과합니다.
 Pictures
Pictures
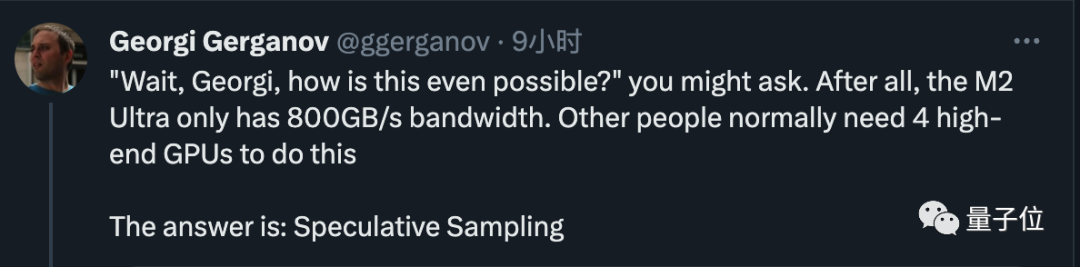
이제 800GB/s 대역폭만 사용하세요. M2 Ultra는 원래 4개의 고급 GPU가 필요한 작업을 완료할 수 있으며 코드 작성 속도도 매우 빠릅니다
그러자 노인이 공개한 비밀은 매우 간단합니다. 바로 추측적 샘플링/디코딩입니다
 Pictures
Pictures
많은 업계 거대 기업의 관심을 불러일으켰습니다
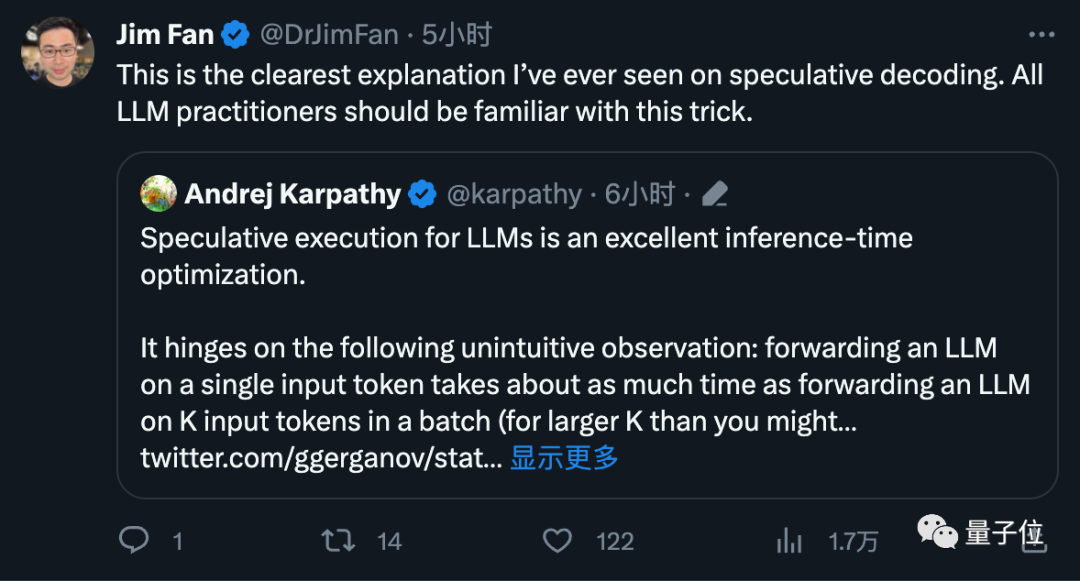
OpenAI 창립 멤버인 Andrej Karpathy는 이것이 매우 뛰어난 추론 시간 최적화라고 평가하고 더 많은 기술적 설명을 제공했습니다.
NVIDIA 과학자인 Fan Linxi도 이것이 대형 모델을 작업하는 모든 사람이 익숙해야 하는 기술이라고 믿습니다.
 Pictures
Pictures
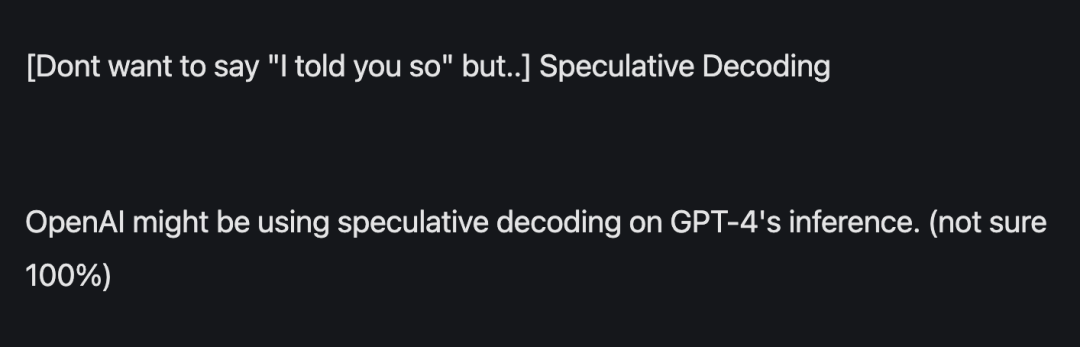
GPT-4도 이 방법을 사용하고 있습니다
추측 샘플링을 사용하는 사람들 로컬에서 대형 모델을 운영하는 사람들에 국한되지 않고 Google, OpenAI와 같은 거대 기업들도 이 기술을 사용하고 있습니다
이전에 유출된 정보에 따르면 GPT-4는 추론 비용을 줄이기 위해 이 방법을 사용합니다. 그런 돈을 태워라.
 Pictures
Pictures
최근 뉴스에 따르면 Google DeepMind가 공동 개발한 차세대 대형 모델 Gemini가 사용될 가능성이 높습니다.
OpenAI의 구체적인 방법은 비밀이지만 Google 팀에서 관련 논문을 발표했으며 해당 논문은 ICML 2023 구두 보고서에 선정되었습니다
 Pictures
Pictures
방법은 간단합니다. 대형 모델과 유사하고 가격이 저렴합니다. 소형 모델의 경우 소형 모델이 먼저 K 토큰을 생성한 후 대형 모델이 판단하도록 합니다.
대형 모델은 승인된 부분을 직접 사용할 수 있고, 승인되지 않은 부분은 대형 모델에 의해 수정될 수 있습니다
원래 연구에서는 T5-XXL 모델을 시연용으로 사용했으며, 생성된 결과는 그대로 유지하면서
 picture
picture
Andjrey Karpathy는 이 방법을 "작은 모델 초안을 먼저 작성하는 것"에 비유합니다.
이 방법의 효율성의 핵심은 대형 모델을 토큰과 토큰 배치에 입력할 때 다음 토큰을 예측하는 데 필요한 시간이 거의 동일하다는 점이라고 설명했습니다.
각 토큰은 이전 토큰에 따라 다릅니다. 토큰이므로 일반적인 상황에서는 동시에 여러 토큰을 샘플링하는 것이 불가능합니다
소형 모델의 능력은 낮지만 실제로 문장을 생성할 때 많은 부분이 매우 간단하고 소형 모델도 해당 작업을 수행할 수 있습니다. 어려운 부분이 있을 때만 대형 모델을 타도록 하세요.
원본 논문에서는 기존의 성숙한 모델이 구조를 변경하거나 재훈련하지 않고도 직접 가속될 수 있다고 지적합니다.
정확도가 감소하지 않는다는 사실에 대한 수학적 주장도 논문의 부록에 나와 있습니다.
 Pictures
Pictures
이제 원리를 이해했으니 이번에는 Georgi Gerganov의 구체적인 설정을 살펴보겠습니다.
그는 초당 약 80개의 토큰을 생성할 수 있는 "드래프트" 모델로 4비트 양자화 7B 모델을 사용합니다.
단독으로 사용할 경우 FP16 정밀도를 갖춘 34B 모델은 초당 10개의 토큰만 생성할 수 있습니다.
추측 샘플링 방법을 사용한 후 원본 논문의 데이터와 일치하는 2배 가속 효과를 얻었습니다
 그림
그림
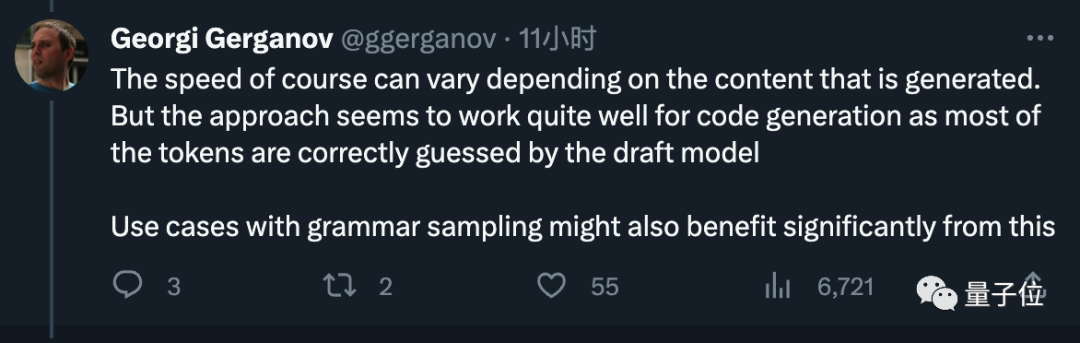
생성된 콘텐츠에 따라 속도가 달라질 수 있지만 코드 생성에는 매우 효과적이며 초안 모델은 대부분의 토큰을 정확하게 추측할 수 있다고 덧붙였습니다.
 Pictures
Pictures
마지막으로 앞으로 모델을 출시할 때 작은 초안 모델도 메타가 직접 포함하자고 제안해 모두의 호평을 받았다.
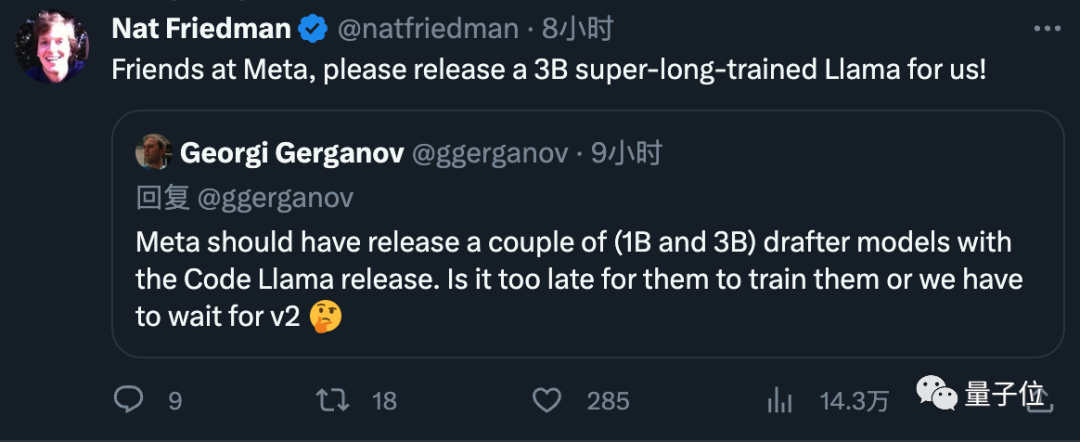 Pictures
Pictures
작가가 사업을 시작했습니다
Georgi Gerganov는 올해 3월에 1세대 LlaMA를 C++로 포팅했습니다. 그의 오픈소스 프로젝트 llama.cpp는 40,000개에 가까운 별을 받았습니다
 pictures
pictures
처음에는 이것을 부업으로만 다루었지만, 뜨거운 호응에 힘입어 6월에
새로운 회사 ggml을 시작한다고 발표했습니다. ai는 엣지 디바이스에서 AI를 실행하는 데 전념하고 있습니다. 회사의 주력 제품은 llama.cpp
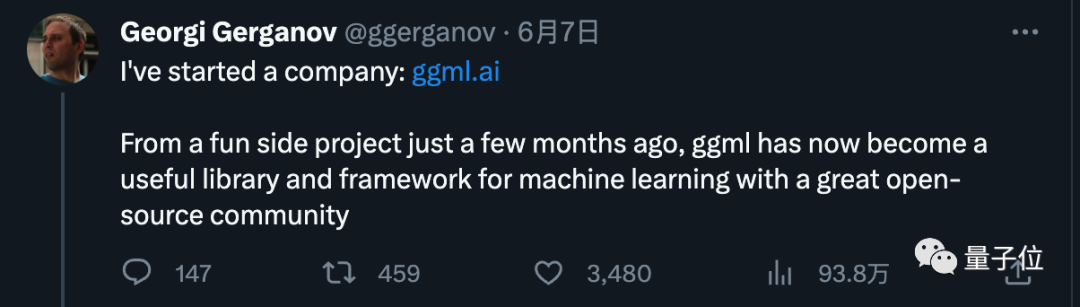 Picture
Picture
뒤에 있는 C 언어 기계 학습 프레임워크입니다. 스타트업 초기에는 전 GitHub CEO Nat Friedman과 Y Combinator 파트너 Daniel Gross로부터 사전 시드 자금을 성공적으로 확보했습니다. 투자
LlaMA2 출시 이후에도 그는 매우 적극적이었습니다. 가장 무자비한 것은 대형 모델을 브라우저에 직접 넣는 것이었습니다.
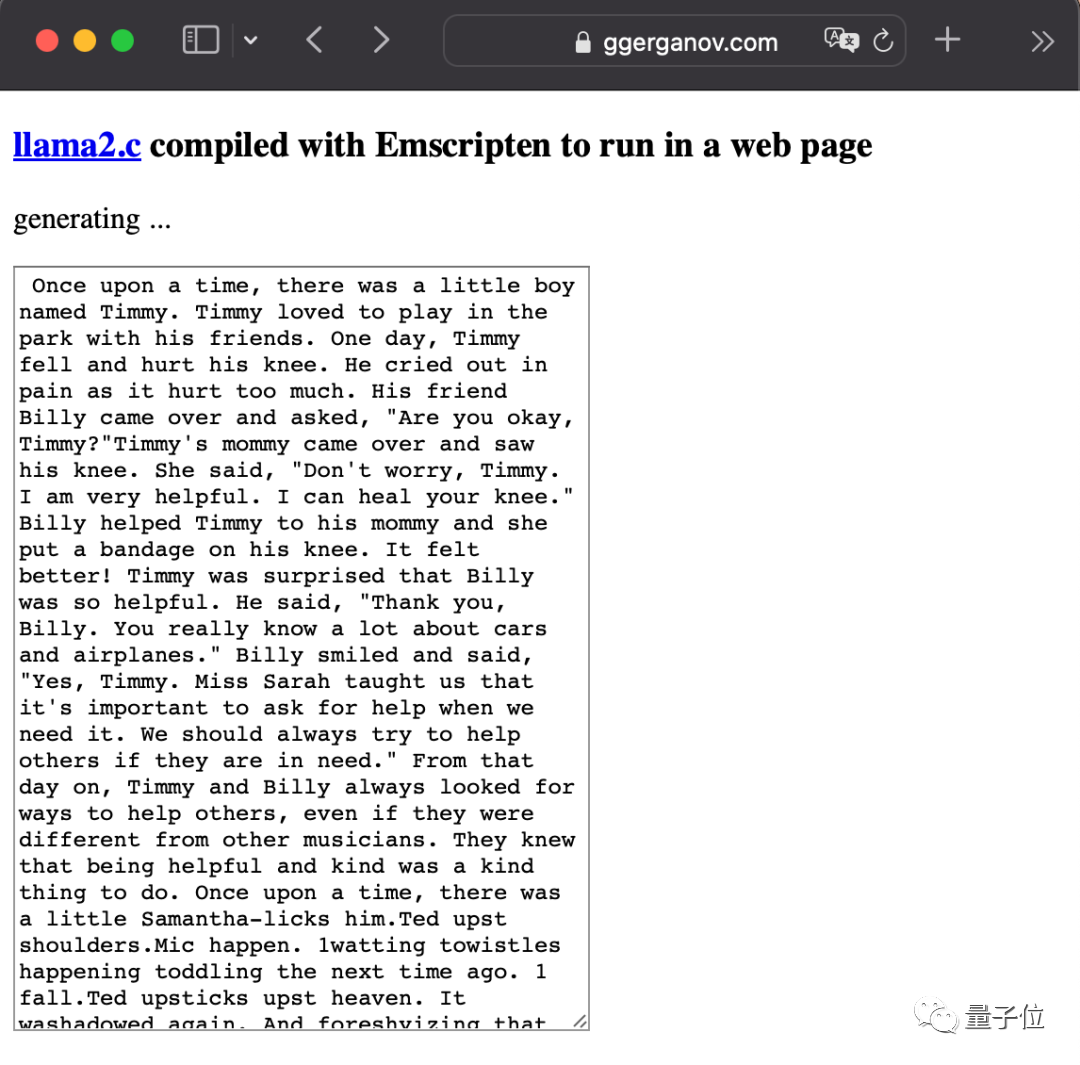 Pictures
Pictures
Google의 추측 샘플링 논문을 확인하세요: https://arxiv.org/abs/2211.17192
참조 링크: [1] https://x.com/ggerganov/status/1697262700165013689 [2 ]https://x.com/karpathy/status/1697318534555336961
위 내용은 Apple 코어는 계산 정확도를 저하시키지 않고 대규모 모델을 실행합니다. GPT-4도 사용됩니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!