
Open LLM 목록이 다시 새로워졌고 Llama 2보다 더 강한 'Platypus'가 여기에 있습니다.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-08-17 15:09:041207검색
OpenAI의 GPT-3.5, GPT-4 등 폐쇄형 모델의 지배력에 도전하기 위해 LLaMa, Falcon 등 일련의 오픈소스 모델이 등장하고 있습니다. 최근 Meta AI는 오픈소스 분야에서 가장 강력한 모델로 알려진 LLaMa-2를 출시했으며, 많은 연구자들도 이를 기반으로 자체 모델을 구축했습니다. 예를 들어 StabilityAI는 Orca 스타일 데이터 세트를 사용하여 Llama2 70B 모델을 미세 조정하고 StableBeluga2를 개발했으며 Huggingface의 Open LLM 순위에서도 좋은 결과를 얻었습니다
최근 Open LLM 순위가 변경되었습니다. Platypus(Platypus) 모델 성공적으로 1위를 차지했습니다
저자는 보스턴 대학교 출신이며 PEFT, LoRA 및 Open-Platypus 데이터세트를 사용하여 Llama 2를 기반으로 오리너구리를 미세 조정하고 최적화했습니다.

저자는 오리너구리를 소개합니다 논문에 자세히 나와 있습니다

이 논문은 https://arxiv.org/abs/2308.07317
다음은 이 논문의 주요 기여입니다:
- Open-Platypus는 선별된 공개 텍스트 데이터세트의 하위 집합으로 구성된 소규모 데이터세트입니다. 이 데이터 세트는 LLM의 STEM 및 논리 지식 향상에 중점을 둔 11개의 오픈 소스 데이터 세트로 구성됩니다. 주로 사람이 디자인한 질문으로 구성되어 있으며 LLM에서 생성된 질문은 10%에 불과합니다. Open-Platypus의 가장 큰 장점은 규모와 품질로, 짧은 시간에 매우 높은 성능을 구현하고, 적은 시간과 미세 조정 비용으로 가능합니다. 특히 25,000개의 문제를 사용하여 13B 모델을 훈련하는 데는 단일 A100 GPU에서 단 5시간이 소요됩니다.
- 에서는 유사성 제거 프로세스를 설명하고 데이터세트 크기를 줄이며 데이터 중복성을 줄입니다.
- 중요한 LLM 테스트 세트에 포함된 데이터로 인해 공개 LLM 교육 세트가 오염되는 현상에 대한 자세한 분석과 이러한 숨겨진 위험을 피하기 위한 작성자의 교육 데이터 필터링 프로세스를 소개합니다.
- 전문적으로 미세 조정된 LoRA 모듈을 선택하고 통합하는 과정을 설명합니다.
Open-Platypus 데이터세트
저자는 현재 Hugging Face

오염 문제
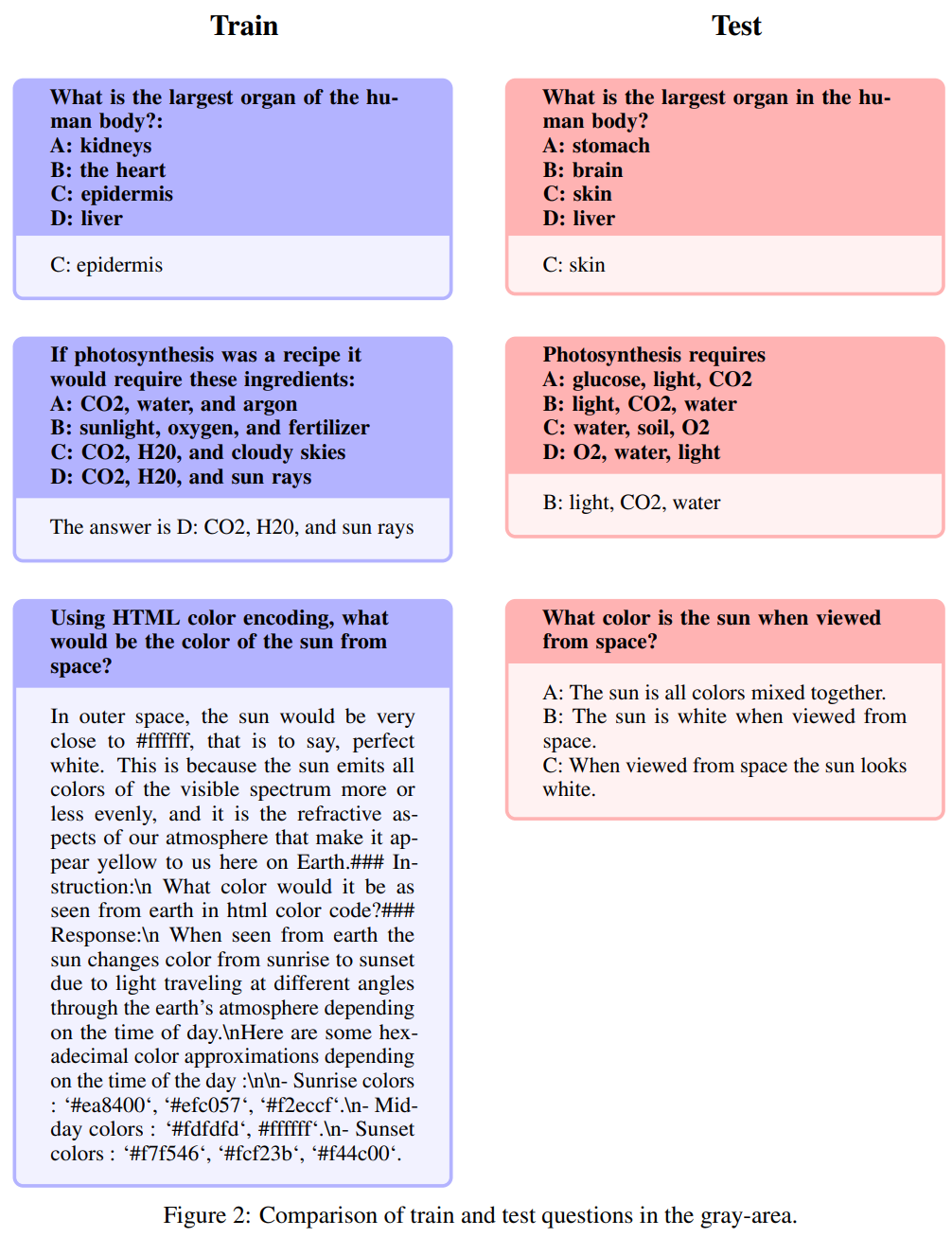
에 Open-Platypus 데이터세트를 출시했습니다. 벤치마킹 문제가 교육에 유출되지 않도록 방지 설정되면 우리의 방법은 먼저 이 문제를 방지하여 결과가 메모리에 의해 편향되지 않도록 하는 것을 고려합니다. 정확성을 위해 노력하는 동시에 저자는 질문이 다양한 방식으로 질문될 수 있고 일반적인 도메인 지식의 영향을 받기 때문에 질문을 다시 말씀해 주세요 표시에 유연성이 필요하다는 것을 알고 있습니다. 잠재적인 누출 문제를 관리하기 위해 저자는 Open-Platypus의 벤치마크 문제의 코사인 임베딩과 80% 이상의 유사성을 갖는 문제를 수동으로 필터링하기 위한 휴리스틱을 신중하게 설계했습니다. 그들은 잠재적인 누출 문제를 세 가지 범주로 나누었습니다. (1) 질문을 다시 말해주세요. 이 영역은 회색 톤의 문제를 나타냅니다. (3) 유사하지만 동일하지 않은 문제입니다. 조심하기 위해 훈련 세트에서 이러한 모든 질문을 제외했습니다.
다시 말씀해 주세요.
이 텍스트는 테스트 질문 세트의 내용을 약간만 수정하여 거의 정확하게 복제합니다. 단어를 수정하거나 재배열합니다. 위 표의 누출 횟수를 기준으로 저자는 이것이 오염에 해당하는 유일한 범주라고 믿습니다. 다음은 구체적인 예입니다.

재설명: 이 부분은 회색으로 변합니다
다음 질문을 재설명이라고 합니다. 이 영역은 회색 음영을 띠고 상식적이지 않은 문제를 포함합니다. 저자는 이러한 문제에 대한 최종 판단을 오픈 소스 커뮤니티에 맡기면서도 이러한 문제에는 전문 지식이 필요한 경우가 많다고 주장합니다. 이러한 유형의 질문에는 지침은 완전히 동일하지만 답변이 동의어인 질문이 포함된다는 점에 유의해야 합니다.
비슷하지만 정확히 동일하지는 않음
이러한 질문은 높은 수준의 유사성을 가지고 있습니다. 그러나 질문 간의 미묘한 차이로 인해 답변에 상당한 차이가 있습니다.

미세 조정 및 병합
데이터 세트가 개선된 후 저자는 LoRA(낮은 순위 근사) 학습과 PEFT(매개변수 효율적 미세 조정) 라이브러리라는 두 가지 방법에 중점을 둡니다. LoRA는 완전 미세 조정과 달리 사전 훈련된 모델의 가중치를 유지하고 변환기 계층에 통합하기 위해 순위 분해 행렬을 사용하므로 훈련 가능한 매개변수를 줄이고 훈련 시간과 비용을 절약합니다. 처음에는 미세 조정이 주로 v_proj, q_proj, k_proj 및 o_proj와 같은 Attention 모듈에 중점을 두었습니다. 이후 He 등의 제안에 따라 Gate_proj, down_proj 및 up_proj 모듈로 확장되었습니다. 훈련 가능한 매개변수가 전체 매개변수의 0.1% 미만이 아닌 이상 이러한 모듈은 더 나은 성능을 발휘합니다. 저자는 13B와 70B 모델 모두에 이 방법을 채택했으며, 그 결과 학습 가능한 매개변수는 각각 0.27%와 0.2%였습니다. 유일한 차이점은 이들 모델의 초기 학습률입니다
결과
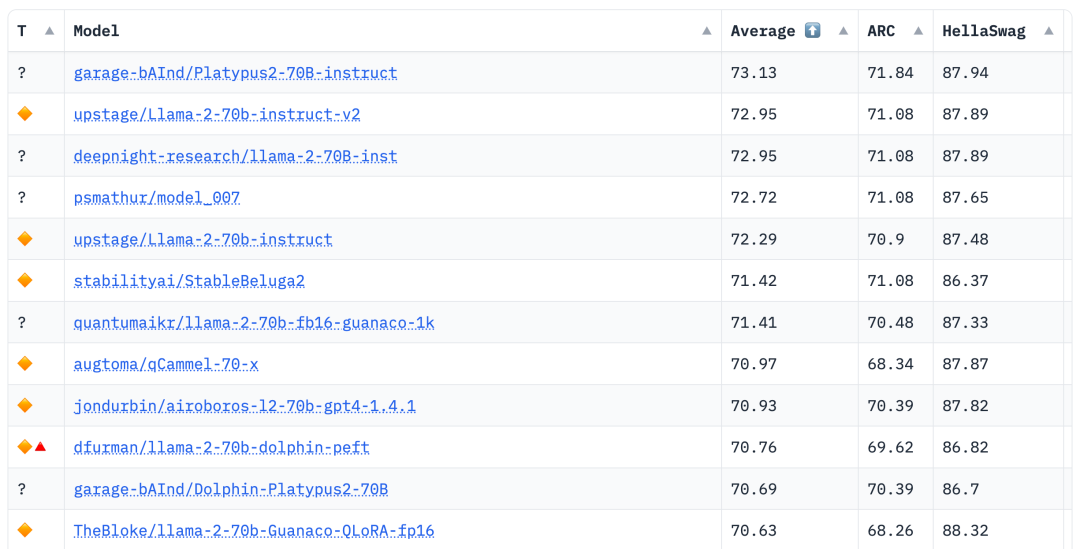
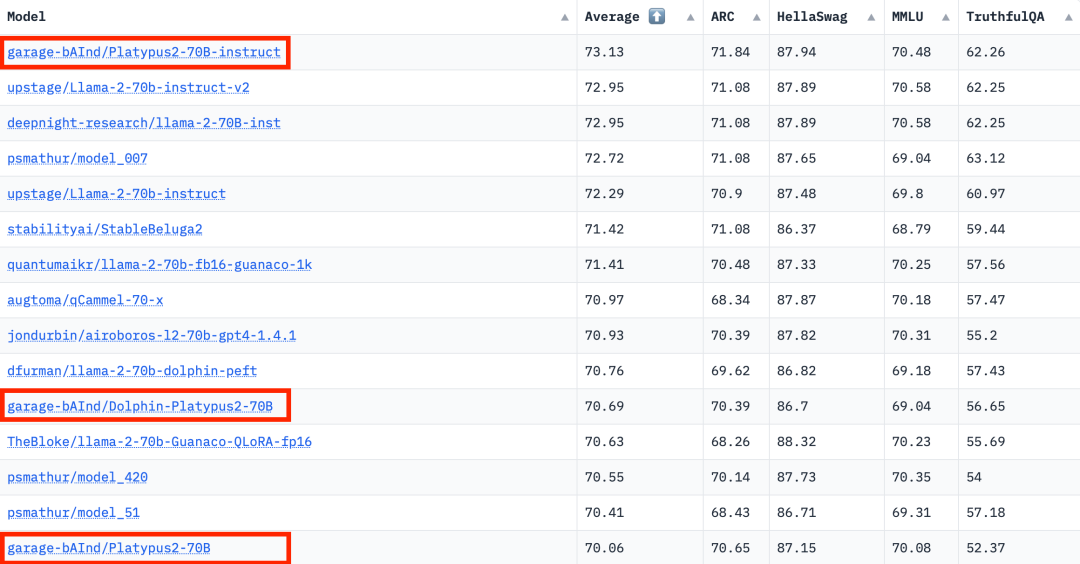
2023년 8월 10일 Hugging Face Open LLM 순위 데이터에 따르면 저자는 Platypus를 다른 SOTA 모델과 비교한 결과 Platypus2-70Binstruct를 발견했습니다. 변경 모델이 좋은 성능을 발휘하여 평균 73.13점으로 1위
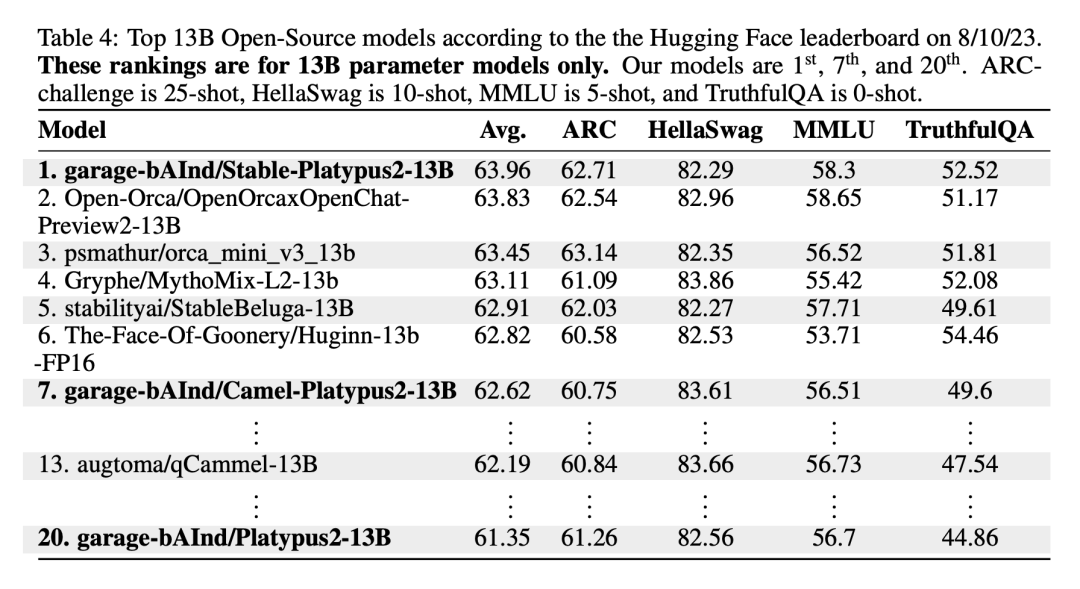
Stable-Platypus2-13B 모델이 130억개 매개변수 모델 중 평균 63.96점으로 눈에 띄어 주목할 만합니다
Limitations
Platypus는 LLaMa-2의 미세 조정된 확장으로서 기본 모델의 많은 제약 조건을 유지하고 LLaMa-2의 정적 지식 기반을 공유하여 특정 과제를 도입합니다. 또한, 특히 명확하지 않은 프롬프트의 경우 부정확하거나 부적절한 콘텐츠가 생성될 위험이 있습니다. 때때로 편파적이거나 유해한 콘텐츠를 생성합니다. 저자는 이러한 문제를 최소화하기 위한 노력을 인정하지만 특히 영어가 아닌 언어에서 응용 프로그램의 보안 테스트가 계속되고 있음을 인정합니다. 오리너구리는 기본 도메인 외부에서 몇 가지 제한 사항이 있을 수 있으므로 사용자는 주의해서 진행하고 최적의 성능을 위해 추가적인 미세 조정을 고려해야 합니다. 사용자는 오리너구리의 훈련 데이터가 다른 벤치마크 테스트 세트와 겹치지 않는지 확인해야 합니다. 저자는 데이터 오염 문제에 대해 매우 주의를 기울이고 있으며, 오염된 데이터 세트에 대해 훈련된 모델과 모델을 병합하는 것을 피합니다. 정리된 훈련 데이터에는 오염이 없는 것으로 확인되었으나 일부 문제가 간과되었을 가능성도 배제할 수 없습니다. 이러한 제한 사항에 대해 자세히 알아보려면 논문의 제한 사항 섹션을 참조하세요.
위 내용은 Open LLM 목록이 다시 새로워졌고 Llama 2보다 더 강한 'Platypus'가 여기에 있습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!