
3000단어 길이의 기사, Pandas가 Excel 테이블을 아름답게 만들어줍니다!

- Python当打之年앞으로
- 2023-08-10 15:15:111852검색
이 기사에서는 Pandas DataFrame의 숫자를 아름답게 만들고 고급 Pandas 스타일 시각화 옵션을 사용하여 Pandas를 사용하여 데이터를 분석하는 능력을 향상시키는 방법을 보여줍니다.
일반적인 예는 다음과 같습니다.
통화 값을 다룰 때 통화 기호를 사용합니다. 예를 들어 데이터에 25.00이라는 값이 포함된 경우 해당 값이 중국 위안화인지, 미국 달러인지, 영국 파운드인지, 아니면 다른 통화인지 즉시 알 수 없습니다. 퍼센트도 또 다른 유용한 지표입니다. 0.05인가요 아니면 5%인가요? 데이터를 해석하는 방법을 매우 명확하게 하려면 백분율 기호를 사용하십시오. Pandas 스타일에는 출력에 색상이나 기타 시각적 요소를 추가하기 위한 고급 도구도 포함되어 있습니다.
사례 분석
이 기사에서는 가상 데이터를 사용하여 모든 사람에게 설명합니다. 해당 데이터는 가상의 조직에 대한 2018년 매출 데이터입니다.
데이터 세트 링크는 다음과 같습니다.
https://www.aliyundrive.com/s/Tu9zBN2x81c
1. 해당 라이브러리를 가져와 데이터를 읽어옵니다.
import numpy as np import pandas as pd df = pd.read_excel('2018_Sales_Total.xlsx')
효과는 다음과 같습니다. 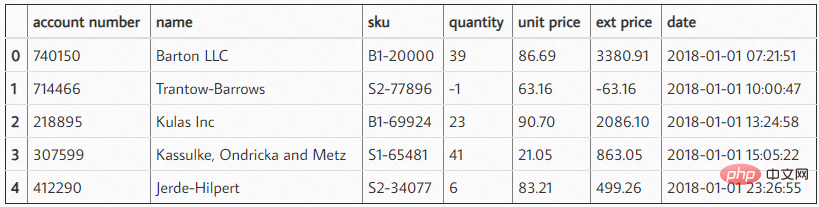 다음 내용을 읽어 보세요. 데이터가 끝나면 고객이 우리에게서 구매한 금액과 평균 구매 금액이 얼마인지 빠르게 요약할 수 있습니다. 단순화를 위해 여기서는 처음 5개의 데이터를 가로채었습니다.
다음 내용을 읽어 보세요. 데이터가 끝나면 고객이 우리에게서 구매한 금액과 평균 구매 금액이 얼마인지 빠르게 요약할 수 있습니다. 단순화를 위해 여기서는 처음 5개의 데이터를 가로채었습니다.
df.groupby('name')['ext price'].agg(['mean', 'sum'])
결과는 다음과 같습니다. 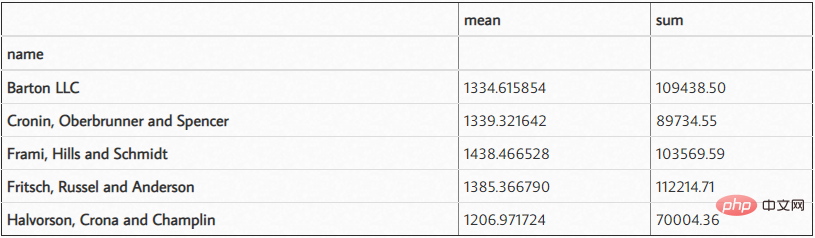
2. 통화 기호 추가
이 데이터를 보면 소수점 이하 6자리와 좀 더 큰 숫자. 게다가 이것이 USD인지 다른 통화인지도 불분명합니다. DataFrame style.format을 사용하여 이 문제를 해결할 수 있습니다.
(df.groupby('name')['ext price']
.agg(['mean', 'sum'])
.style.format('${0:,.2f}'))결과는 다음과 같습니다. 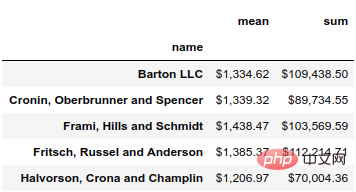 형식 기능을 사용하면 데이터에 대해 Python의 문자열 형식 지정 도구의 모든 기능을 사용할 수 있습니다. 이 경우 ${0:,.2f}를 사용하여 선행 달러 기호를 넣고 쉼표를 추가한 다음 결과를 소수점 이하 두 자리로 반올림합니다.
형식 기능을 사용하면 데이터에 대해 Python의 문자열 형식 지정 도구의 모든 기능을 사용할 수 있습니다. 이 경우 ${0:,.2f}를 사용하여 선행 달러 기호를 넣고 쉼표를 추가한 다음 결과를 소수점 이하 두 자리로 반올림합니다.
예를 들어 소수점 이하 0자리로 반올림하려면 형식을 ${0:,.0f}로 변경할 수 있습니다.
(df.groupby('name')['ext price']
.agg(['mean', 'sum'])
.style.format('${0:,.0f}'))결과는 다음과 같습니다.
3. 백분율 추가
월별 총 매출을 보려면 그룹화를 사용하여 월별로 요약하고 월별 점유율을 계산할 수 있습니다. 연간 총 매출 비율입니다.
monthly_sales = df.groupby([pd.Grouper(key='date', freq='M')])['ext price'].agg(['sum']).reset_index() monthly_sales['pct_of_total'] = monthly_sales['sum'] / df['ext price'].sum()
결과는 다음과 같습니다. 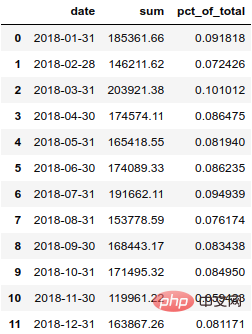 이 백분율을 더 명확하게 표시하려면 백분율로 변환하는 것이 좋습니다.
이 백분율을 더 명확하게 표시하려면 백분율로 변환하는 것이 좋습니다.
format_dict = {'sum':'${0:,.0f}', 'date': '{:%m-%Y}', 'pct_of_total': '{:.2%}'}
monthly_sales.style.format(format_dict).hide_index()结果如下: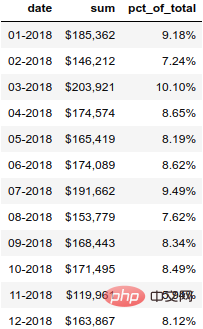
4. 突出显示数字
除了样式化数字,我们还可以设置 DataFrame 中的单元格样式。让我们用绿色突出显示最高的数字,用彩色突出显示最高、最低的数字。
(monthly_sales .style .format(format_dict) .hide_index() .highlight_max(color='lightgreen') .highlight_min(color='#cd4f39'))
结果如下: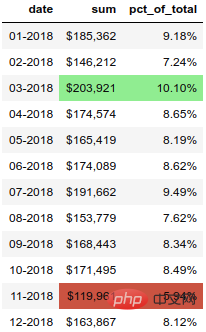
5. 设置渐变色
另一个有用的函数是 background_gradient,它可以突出显示列中的值范围。
(monthly_sales.style .format(format_dict) .background_gradient(subset=['sum'], cmap='BuGn'))
结果如下: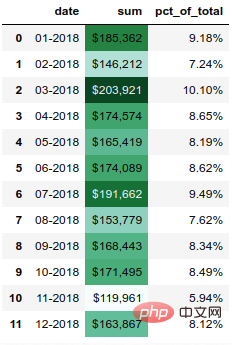
6. 设置数据条
pandas样式功能还支持在列内绘制条形图。
(monthly_sales .style .format(format_dict) .hide_index() .bar(color='#FFA07A', vmin=100_000, subset=['sum'], align='zero') .bar(color='lightgreen', vmin=0, subset=['pct_of_total'], align='zero') .set_caption('2018 Sales Performance'))
结果如下: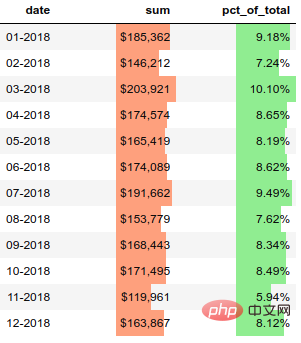
7. 绘制迷你图
我认为这是一个很酷的功能。
import sparklines
def sparkline_str(x):
bins=np.histogram(x)[0]
sl = ''.join(sparklines(bins))
return sl
sparkline_str.__name__ = "sparkline"
df.groupby('name')['quantity', 'ext price'].agg(['mean', sparkline_str])结果如下: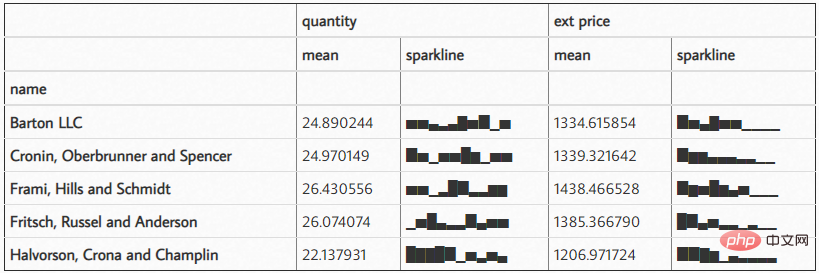
위 내용은 3000단어 길이의 기사, Pandas가 Excel 테이블을 아름답게 만들어줍니다!의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!