
JS를 리버스 엔지니어링하여 글꼴 크롤링을 역전시키고 채용 웹사이트에서 정보를 얻는 방법을 단계별로 가르칩니다.

- Python当打之年앞으로
- 2023-08-09 17:56:531160검색
오늘의 웹사이트
편집자는 다음을 암호화했습니다: aHR0cHM6Ly93d3cuc2hpeGlzZW5nLmNvbS8= 보안상의 이유로 URL을 base64로 인코딩하였으며, base64 디코딩을 통해 URL을 얻을 수 있습니다.
폰트 안티 크롤링
폰트 안티 크롤링: 일반적인 크롤링 방지 기술로, 웹 페이지와 프런트엔드 글꼴 파일을 결합하여 완성된 크롤링 방지 전략입니다. -크롤링 기술은 58.com 및 Autohome입니다. 잠깐만요. 이제 많은 주류 웹사이트나 앱에서도 글꼴 크롤링 방지 기술을 사용하여 자체 웹사이트나 앱에 크롤링 방지 조치를 추가합니다.
폰트 크롤링 방지 원칙: 페이지의 특정 데이터를 사용자 정의 글꼴로 대체합니다. 올바른 디코딩 방법을 사용하지 않으면 올바른 데이터 콘텐츠를 얻을 수 없습니다.
아래와 같이 @font-face를 통해 HTML에서 사용자 정의 글꼴을 사용하세요.

구문 형식은 다음과 같습니다.
@font-face{
font-family:"名字";
src:url('字体文件链接');
url('字体文件链接')format('文件类型')
}Font 파일은 일반적으로 ttf 유형, eot 유형, woff 유형의 파일이 널리 사용되므로 누구나 woff 유형 파일을 일반적으로 접하게 됩니다.
woff 유형 파일을 예로 들면, 그 내용은 무엇이며, 데이터와 코드가 일대일 대응되도록 하려면 어떤 인코딩 방법이 사용됩니까?
채용 웹사이트의 글꼴 파일을 예로 들어 보겠습니다. Baidu 글꼴 컴파일러에 들어가서 아래 그림과 같이 글꼴 파일을 엽니다.

아래 그림과 같이 글꼴을 무작위로 엽니다.
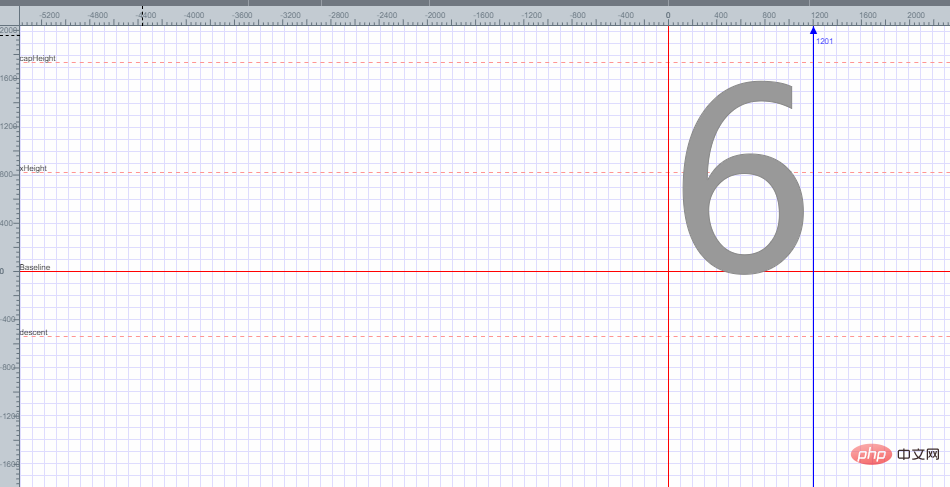
폰트 6은 평면 좌표에 배치되어 있으며, 평면 좌표의 각 지점을 기준으로 글꼴 6의 인코딩이 얻어지는 것을 볼 수 있습니다. 여기서는 글꼴 6의 인코딩을 얻는 방법을 설명하지 않습니다.
글꼴 반등 문제를 해결하는 방법은 무엇입니까?
먼저 매핑 관계를 사전으로 간주할 수 있습니다. 일반적으로 사용되는 방법은 대략 두 가지입니다.
첫 번째: 코드와 문자 집합 간의 해당 관계를 수동으로 추출하여 형식으로 표시합니다. 코드는 다음과 같습니다.
replace_dict={
'0xf7ce':'1',
'0xf324':'2',
'0xf23e':'3',
.......
'0xfe43':'n',
}
for key in replace_dict:
数据=数据.replace(key,replace_dict[key])먼저 해당 글꼴과 해당 코드에 해당하는 사전을 정의한 후 for 루프를 통해 데이터를 하나씩 교체합니다.
참고: 이 방법은 주로 글꼴 매핑이 거의 없는 데이터에 적합합니다.
두 번째 방법: 먼저 웹사이트의 글꼴 파일을 다운로드한 다음 글꼴 파일을 XML 파일로 변환하고 내부에서 글꼴 매핑 관계의 코드를 찾아 디코드 기능을 통해 디코딩한 다음 디코딩된 코드를 사전으로 결합합니다. , 사전 내용을 사용하여 데이터를 하나씩 교체합니다. 코드가 비교적 길기 때문에 여기서는 샘플 코드를 작성하지 않겠습니다. 실제 전투 연습에서는 이 방법에 대해 설명합니다.
알겠습니다. 글꼴 크롤링 방지에 대해 간략하게 설명하겠습니다. 다음으로 공식적으로 채용 웹사이트를 크롤링하겠습니다.
실습
사용자 정의 글꼴 파일 검색
먼저 아래 그림과 같이 채용 웹사이트에 들어가서 개발자 모드를 엽니다.
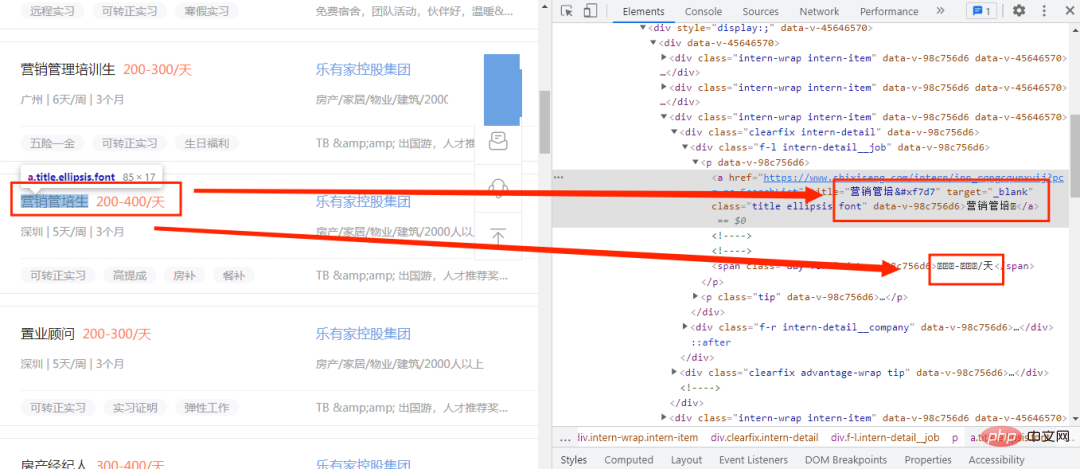
여기서는 코드에 있는 새로운 단어만 정상적으로 작동하지 않고 코드로 대체되는 것을 볼 수 있습니다. 초기에는 사용자 정의 글꼴 파일을 사용한다고 판단됩니다. 이때 글꼴 파일을 찾아야 합니다. 그럼 글꼴 파일은 어디서 찾을 수 있나요? 먼저 아래 그림과 같이 개발자 모드를 열고 네트워크 옵션을 클릭하세요.
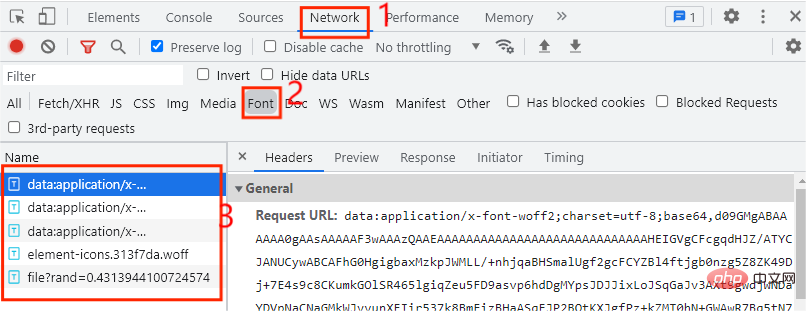
일반적으로 글꼴 파일은 글꼴 탭에 있습니다. 여기에 총 5개의 항목이 있으므로 어느 것이 사용자 정의 글꼴 파일의 항목인지는 다음 페이지를 클릭할 때마다 사용자 정의 글꼴 파일이 한 번씩 실행됩니다. 이때는 다음 페이지만 클릭하면 됩니다. 아래 그림과 같이 웹 페이지에
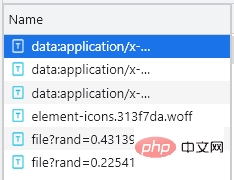
file로 시작하는 추가 항목이 있는 것을 볼 수 있습니다. 이때 해당 파일이 사용자 정의 글꼴 파일임을 처음 확인할 수 있습니다. 다운로드 방법은 매우 간단합니다. 파일로 시작하는 항목의 URL을 복사하여 넣기만 하면 됩니다. 다운로드한 후 아래와 같이 Baidu 글꼴 컴파일러에서 엽니다.

커스텀 폰트 파일을 찾았으니 어떻게 사용하나요? 이때 먼저 get_fontfile() 메소드를 사용자 정의하여 사용자 정의 글꼴 파일을 처리한 다음 사전을 통해 글꼴 파일의 매핑 관계를 두 단계로 표시합니다.
- 글꼴 파일 다운로드 및 변환
- 글꼴 매핑 관계 디코딩.
우선, 사용자 정의 글꼴 파일 업데이트 빈도가 매우 높습니다. 이때 웹 페이지의 사용자 정의 글꼴 파일을 실시간으로 얻을 수 있습니다. 이전 사용자 정의 글꼴 파일이 사용되지 않아 데이터 수집이 부정확해졌습니다. 먼저 사용자 정의 글꼴 파일의 URL 링크를 관찰하세요:
https://www.xxxxxx.com/interns/iconfonts/file?rand=0.2254193167485603 https://www.xxxxxx.com/interns/iconfonts/file?rand=0.4313944100724574 https://www.xxxxxx.com/interns/iconfonts/file?rand=0.3615862774301839
可以发现自定义字体文件的URL只有rand这个参数发生变化,而且是随机的十六位小于1的浮点数,那么我们只需要构造rand参数即可,主要代码如下所示:
def get_fontfile():
rand=round(random.uniform(0,1),17)
url=f'https://www.xxxxxx.com/interns/iconfonts/file?rand={rand}'
response=requests.get(url,headers=headers).content
with open('file.woff','wb')as f:
f.write(response)
font = TTFont('file.woff')
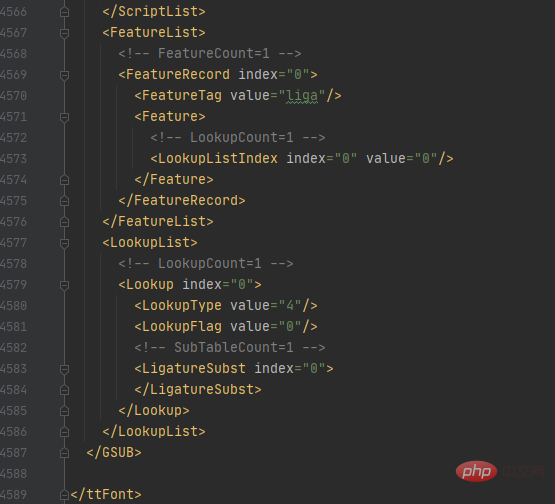
font.saveXML('file.xml')首先通过random.uniform()方法来控制随机数的大小,再通过round()方法控制随机数的位数,这样就可以得到rand的值,再通过.content把URL响应内容转换为二进制并写入file.woff文件中,在通过TTFont()方法获取文件内容,通过saveXML方法把内容保存为xml文件。xml文件内容如下图所示:
字体解码及展现
该字体.xml文件一共有4589行那么多,哪个部分才是字体映射关系的代码部分呢?
首先我们看回在百度字体编码器的内容,如下图所示:

汉字人对应的代码为f0e2,那么我们就在字体.xml文件中查询人的代码,如下图所示:
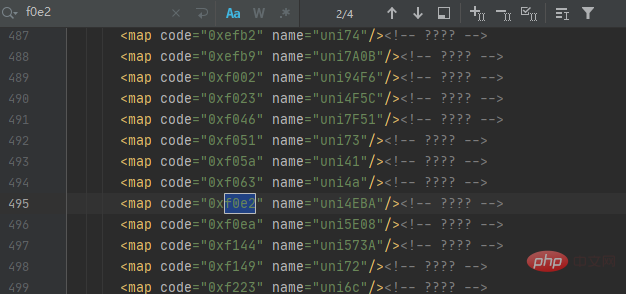
可以发现一共有4个结果,但仔细观察每个结果都相同,这时我们可以根据它们代码规律来获取映射关系,再通过解码来获取对应的数据值,最后以字典的形式展示,主要代码如下所示:
with open('file.xml') as f:
xml = f.read()
keys = re.findall('<map code="(0x.*?)" name="uni.*?"/>', xml)
values = re.findall('<map code="0x.*?" name="uni(.*?)"/>', xml)
for i in range(len(values)):
if len(values[i]) < 4:
values[i] = ('\\u00' + values[i]).encode('utf-8').decode('unicode_escape')
else:
values[i] = ('\\u' + values[i]).encode('utf-8').decode('unicode_escape')
word_dict = dict(zip(keys, values))首先读取file.xml文件内容,找出把代码中的code、name的值并分别设置为keys键,values值,再通过for循环把values的值解码为我们想要的数据,最后通过zip()方法合并为一个元组并通过dict()方法转换为字典数据,运行结果如图所示:

获取招聘数据
在上一步中,我们成功把字体映射关系转换为字典数据了,接下来开始发出网络请求来获取数据,主要代码如下所示:
def get_data(dict,url):
response=requests.get(url,headers=headers).text.replace('&#','0')
for key in dict:
response=response.replace(key,dict[key])
XPATH=parsel.Selector(response)
datas=XPATH.xpath('//*[@id="__layout"]/div/div[2]/div[2]/div[1]/div[1]/div[1]/div')
for i in datas:
data={
'workname':i.xpath('./div[1]/div[1]/p[1]/a/text()').extract_first(),
'link':i.xpath('./div[1]/div[1]/p[1]/a/@href').extract_first(),
'salary':i.xpath('./div[1]/div[1]/p[1]/span/text()').extract_first(),
'place':i.xpath('./div[1]/div[1]/p[2]/span[1]/text()').extract_first(),
'work_time':i.xpath('./div[1]/div[1]/p[2]/span[3]/text()').extract_first()+i.xpath('./div[1]/div[1]/p[2]/span[5]/text()').extract_first(),
'company_name':i.xpath('./div[1]/div[2]/p[1]/a/text()').extract_first(),
'Field_scale':i.xpath('./div[1]/div[2]/p[2]/span[1]/text()').extract_first()+i.xpath('./div[1]/div[2]/p[2]/span[3]/text()').extract_first(),
'advantage': ','.join(i.xpath('./div[2]/div[1]/span/text()').extract()),
'welfare':','.join(i.xpath('./div[2]/div[2]/span/text()').extract())
}
saving_data(list(data.values()))首先自定义方法get_data()并接收字体映射关系的字典数据,再通过for循环将字典内容与数据一一替换,最后通过xpath()来提取我们想要的数据,最后把数据传入我们自定义方法saving_data()中。
保存数据
数据已经获取下来了,接下来将保存数据,主要代码如下所示:
def saving_data(data):
db = pymysql.connect(host=host, user=user, password=passwd, port=port, db='recruit')
cursor = db.cursor()
sql = 'insert into recruit_data(work_name, link, salary, place, work_time,company_name,Field_scale,advantage,welfare) values(%s,%s,%s,%s,%s,%s,%s,%s,%s)'
try:
cursor.execute(sql,data)
db.commit()
except:
db.rollback()
db.close()启动程序
好了,程序已经写得差不多了,接下来将编写代码运行程序,主要代码如下所示:
if __name__ == '__main__':
create_db()
get_fontfile()
for i in range(1,3):
url=f'https://www.xxxxxx.com/interns?page={i}&type=intern&salary=-0&city=%E5%85%A8%E5%9B%BD'
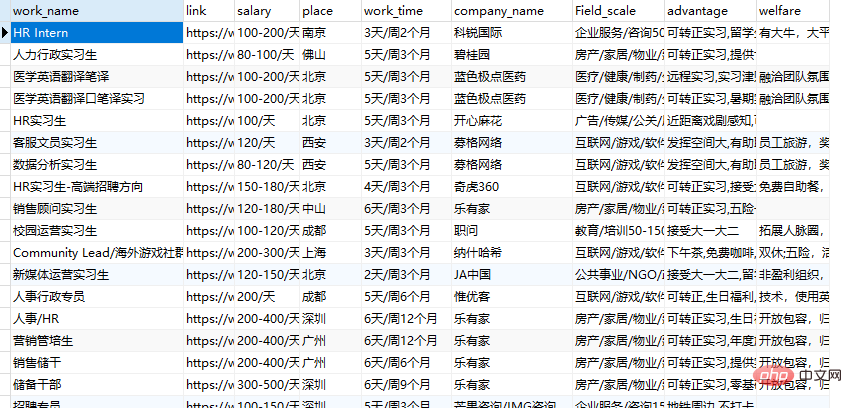
get_data(get_dict(),url)结果展示
위 내용은 JS를 리버스 엔지니어링하여 글꼴 크롤링을 역전시키고 채용 웹사이트에서 정보를 얻는 방법을 단계별로 가르칩니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!