
Python의 urllib 라이브러리와 요청 라이브러리 간의 차이점을 살펴보세요.
- Go语言进阶学习앞으로
- 2023-07-25 15:16:501978검색
1. 소개
Python 크롤러를 사용할 때 사용되는 기본 라이브러리는 요청 라이브러리와 Python에 내장된 urllib 라이브러리를 사용하는 것이 일반적입니다. 요청은 다시 캡슐화된 urllib의 확장입니다.
그 차이점은 무엇인가요?
다음은 사용상의 주요 차이점을 이해할 수 있도록 사례를 통해 자세히 설명합니다.
2.urllib 라이브러리
소개: urllib 라이브러리의 응답 개체는 먼저 http 및 요청 개체를 생성한 다음 이를 reques.urlopen에 로드하여 http 요청을 완료합니다.
반환되는 것은 http, response 객체인데 실제로는 html 속성입니다. .read().decode()를 사용하여 디코딩하고 str 문자열 형식으로 변환하면 한자가 표시될 수 있습니다.
예:
from urllib import request
#请求头
headers = {
"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36'
}
wd = {"wd": "中国"}
url = "http://www.baidu.com/s?"
req = request.Request(url, headers=headers)
response = request.urlopen(req)
print(type(response))
print(response)
res = response.read().decode()
print(type(res))
print(res)실행 결과:
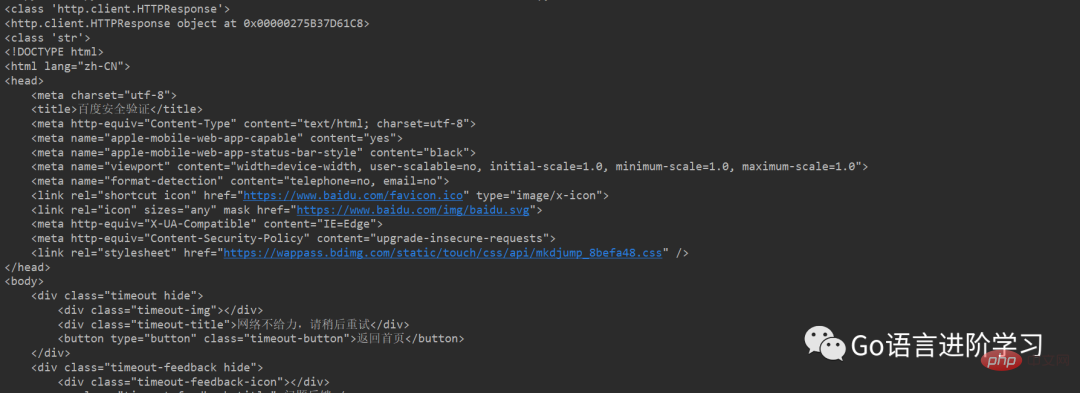
참고:
일반적으로 웹페이지를 크롤링할 때 http 요청을 구성할 때 몇 가지를 추가해야 합니다. Useragent, 쿠키 등과 같은 추가 정보를 제공하거나 프록시 서버를 추가합니다. 종종 이는 필요한 크롤링 방지 메커니즘입니다.
三、requests库
简介:requests库调用是requests.get方法传入url和参数,返回的对象是Response对象,打印出来是显示响应状态码。
通过.text 方法可以返回是unicode 型的数据,一般是在网页的header中定义的编码形式,而content返回的是bytes,二级制型的数据,还有 .json方法也可以返回json字符串。
如果想要提取文本就用text,但是如果你想要提取图片、文件等二进制文件,就要用content,当然decode之后,中文字符也会正常显示。
requests的优势:Python爬虫时,更建议用requests库。因为requests比urllib更为便捷,requests可以直接构造get,post请求并发起,而urllib.request只能先构造get,post请求,再发起。
例:
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Linux; U; Android 8.1.0; zh-cn; BLA-AL00 Build/HUAWEIBLA-AL00) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/57.0.2987.132 MQQBrowser/8.9 Mobile Safari/537.36"
}
wd = {"wd": "中国"}
url = "http://www.baidu.com/s?"
response = requests.get(url, params=wd, headers=headers)
data = response.text
data2 = response.content
print(response)
print(type(response))
print(data)
print(type(data))
print(data2)
print(type(data2))
print(data2.decode())
print(type(data2.decode()))运行结果 (可以直接获取整网页的信息,打印控制台):
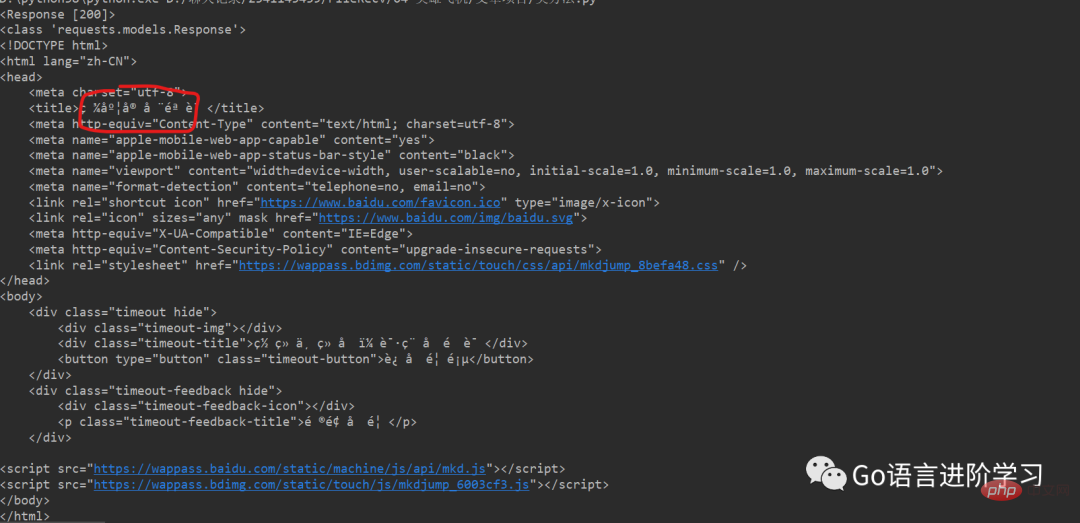
四、总结
1. 本文基于Python基础,主要介绍了urllib库和requests库的区别。
2. 在使用urllib内的request模块时,返回体获取有效信息和请求体的拼接需要decode和encode后再进行装载。进行http请求时需先构造get或者post请求再进行调用,header等头文件也需先进行构造。
3. requests是对urllib的进一步封装,因此在使用上显得更加的便捷,建议在实际应用当中尽量使用requests。
4. 希望能给一些对爬虫感兴趣,有一个具体的概念。方法只是一种工具,试着去爬一爬会更容易上手,网络也会有很多的坑,做爬虫更需要大量的经验来应付复杂的网络情况。
5. 希望大家一起探讨学习, 一起进步。
위 내용은 Python의 urllib 라이브러리와 요청 라이브러리 간의 차이점을 살펴보세요.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!