
一篇文章把 Go 中的内存分配扒得干干净净
- Go语言进阶学习앞으로
- 2023-07-25 13:57:091391검색
오늘은 Go의 메모리 관리에 대한 몇 가지 공통 지식을 공유하겠습니다.
# 1. 메모리 할당의 세 가지 주요 구성 요소
Go 메모리 할당 프로세스는 주로 세 가지 주요 구성 요소에 의해 관리됩니다. 위에서 아래까지의 수준은 다음과 같습니다.
mheap
Go 프로그램이 시작되면 먼저 운영 체제에서 대규모 메모리 블록을 적용하고 이를 mheap 구조의 전역 관리에 넘겨줍니다.
구체적으로 관리하는 방법은? mheap은 이 큰 메모리 조각을 서로 다른 사양의 작은 메모리 블록으로 나누는데, 이를 mspan이라고 합니다. 사양의 크기에 따라 약 70가지 유형의 mspan이 있으며 분할은 충족하기에 충분합니다. 다양한 객체 메모리 배포의 필요성.
그러니까 이런 mspan 사양이 크고 작은게 섞여서 관리하기 힘들겠죠?
그래서 다음 단계의 구성 요소인 mcentral이 있습니다.
mcentral
Go 프로그램을 시작하면 많은 mcentral이 초기화되며, 각 mcentral은 mspan의 특정 사양을 관리하는 역할만 담당합니다.
mheap을 기반으로 mspan의 세련된 관리를 구현하는 mcentral과 동일합니다.
하지만 mcentral은 Go 프로그램에서 전역적으로 표시되므로 코루틴이 메모리를 적용하기 위해 mcentral에 올 때마다 잠가야 합니다.
각 코루틴이 메모리를 적용하기 위해 mcentral에 오면 잦은 잠금 및 해제로 인한 오버헤드가 매우 클 것으로 예상할 수 있습니다.
따라서 이 압력을 완화하려면 mcentral의 보조 프록시가 필요합니다
mcache
Go 프로그램에서 각 스레드M은 프로세서에 바인딩됩니다P, 단일 시간 단위로 하나의 다중 처리 실행만 수행할 수 있습니다고루틴, 각P가 바인딩됩니다. 하나는 mcache의 로컬 캐시. M会绑定给一个处理器P,在单一粒度的时间里只能做多处理运行一个goroutine,每个P都会绑定一个叫 mcache 的本地缓存。
当需要进行内存分配时,当前运行的goroutine会从mcache中查找可用的mspan。从本地mcache
goroutine은 사용 가능한 <code style="font-size: 상속;line-height: 상속;overflow-wrap: break-word;padding: mcache에서 2px 4px 찾기 ;경계 반경: 4px;여백-오른쪽: 2px;여백-왼쪽: 2px;색상: rgb(226, 36, 70);배경: rgb(248, 248, 248);">mspan. 로컬mcache는 메모리 할당 시 잠금을 요구하지 않습니다. 이 할당 전략이 더 효율적입니다. mspan 공급망
mcache의 mspan 수가 항상 충분하지는 않습니다. 공급이 수요를 초과하면 mcache는 mcentral에서 더 많은 mspan을 다시 신청합니다. 마찬가지로 mcentral의 mspan 수가 충분하지 않으면 mcache가 다시 mspan을 신청합니다. 또한 우수한 mheap에서 mspan을 신청할 것입니다. 더 극단적으로 말하면, mheap의 mspan이 프로그램의 메모리 요청을 충족할 수 없는 경우 어떻게 해야 합니까? 그렇다면 다른 방법은 없습니다. mheap은 운영체제의 큰 형님에게 뻔뻔하게 적용할 수 밖에 없습니다.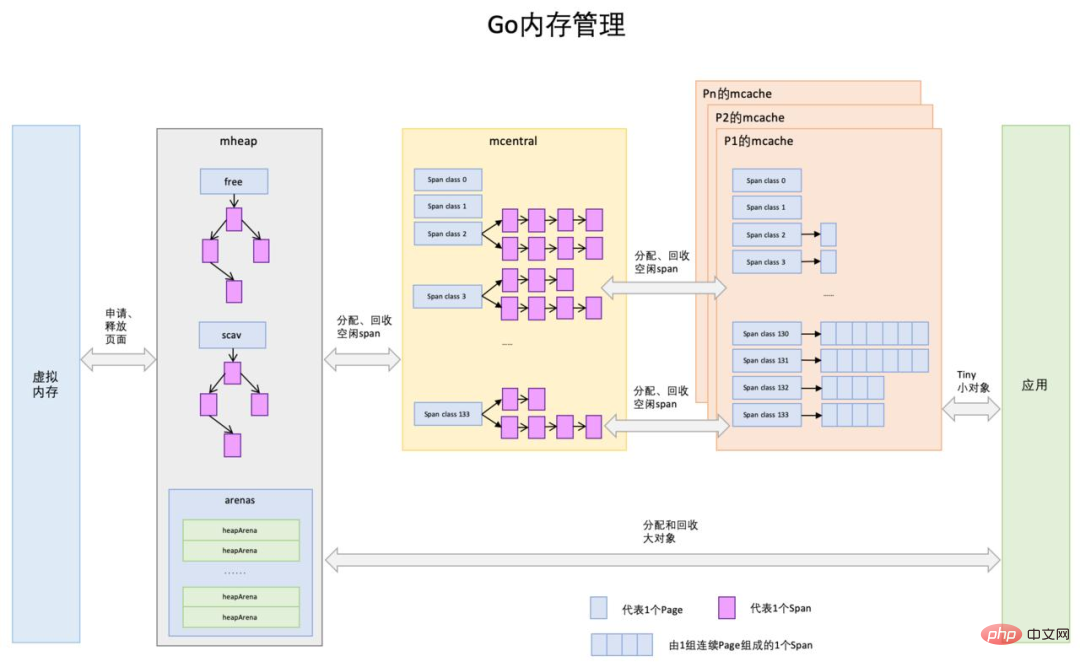
위 공급 프로세스는 메모리 블록이 64KB 미만인 시나리오에만 적용 가능합니다. 그 이유는 Go가 작업자 스레드의 로컬 캐시를 사용하여 해당 메모리 페이지 수(각 페이지 크기는 8KB)를 할당할 수 없기 때문입니다. 프로그램. mcache和全局中心缓存 mcentral 上管理超过 64KB 的内存分配,所以对于那些超过 64KB 的内存申请,会直接从堆上(mheap
# 2. 힙 메모리와 스택 메모리란 무엇인가요?
다양한 메모리 관리(할당 및 재활용) 방법에 따라 메모리는힙 메모리와 스택 메모리로 나눌 수 있습니다.
그럼 차이점은 무엇인가요?힙 메모리: 메모리 할당자와 가비지 수집기는 재활용을 담당합니다.
스택 메모리: 컴파일러에 의해 자동으로 할당 및 해제됩니다.
프로그램이 실행될 때 여러 개의 스택 메모리가 있을 수 있지만 확실히 힙 메모리는 하나만 있습니다. 각 스택 메모리는 스레드나 코루틴에 의해 독립적으로 점유되므로 스택에서 메모리를 할당할 때 잠금이 필요하지 않으며 스택 메모리는 함수 종료 후 자동으로 재활용되며 성능은 힙 메모리보다 높습니다. 그리고 힙 메모리는 어떻습니까? 여러 스레드나 코루틴이 동시에 힙에서 메모리를 신청할 수 있으므로 힙에서 메모리를 신청하려면 충돌을 피하기 위해 잠금이 필요하며, 힙 메모리는 함수가 끝난 후 GC(가비지 수집)의 개입이 필요합니다. GC 작업 수가 늘어나면 프로그램 성능이 심각하게 저하됩니다.# 3. 이스케이프 분석의 필요성
프로그램 성능을 향상시키기 위해서는 힙에 대한 메모리 할당을 최소화해야 하며, 이는 GC에 대한 부담을 줄일 수 있음을 알 수 있습니다. 변수가 힙에 메모리를 할당할지 스택에 메모리를 할당할지 결정하는 데 있어 전임자들이 몇 가지 규칙을 요약했지만 코딩할 때 이 문제에 항상 주의를 기울이는 것은 프로그래머의 몫이며 프로그래머에 대한 요구 사항이 상당히 높습니다. 다행스럽게도 Go 컴파일러는 탈출 분석 기능도 제공합니다. 탈출 분석을 사용하면 프로그래머가 힙에 할당한 모든 변수를 직접 감지할 수 있습니다(이 현상을 탈출이라고 합니다). 다음 명령어를 실행하는 방법이 있습니다go build -gcflags '-m -l' demo.go # 或者再加个 -m 查看更详细信息 go build -gcflags '-m -m -l' demo.go
# 메모리 할당 위치 규칙
이스케이프 분석 도구를 사용하면 실제로 어떤 변수가 힙에 할당되는지 수동으로 확인할 수 있습니다.
그럼 이 규칙은 무엇인가요?
요약하면 크게 4가지 상황이 나옵니다.
변수의 사용 범위에 따라
변수 유형이 결정되는지 여부에 따라
점유 크기에 따라 변수의
에 따라 변수의 길이가 결정되는 걸까요? 다음은 하나씩 분석하고 검증해 보겠습니다
변수의 사용 범위에 따라
예를 들어, 아래 예func foo() int {
v := 1024
return v
}
func main() {
m := foo()
fmt.Println(m)
}
에서는 go build -gcflags '-m -l' 데모.go 이스케이프 분석 결과를 보려면 -m은 이스케이프 분석 정보를 인쇄하는 것입니다. -l은 인라인 최적화를 비활성화합니다. 분석 결과, v 변수에 대한 이스케이프 명령은 보이지 않아 이스케이프되지 않고 스택에 할당되었음을 알 수 있습니다. $ go build -gcflags '-m -l' demo.go # command-line-arguments ./demo.go:12:13: ... argument does not escape ./demo.go:12:13: m escapes to heap그리고 변수를 함수 범위 밖에서 사용해야 하는 경우, 여전히 스택에 할당되어 있으면 함수가 반환될 때 변수가 가리키는 메모리 공간이 재활용되어 프로그램이 필연적으로 오류를 보고하므로 이러한 종류의 변수는 힙에만 할당될 수 있습니다.
go build -gcflags '-m -l' demo.go 来查看逃逸分析的结果,其中 -m 是打印逃逸分析的信息,-l 则是禁止内联优化。
从分析的结果我们并没有看到任何关于 v 变量的逃逸说明,说明其并没有逃逸,它是分配在栈上的。
func foo() *int {
v := 1024
return &v
}
func main() {
m := foo()
fmt.Println(*m) // 1024
}而如果该变量还需要在函数范围之外使用,如果还在栈上分配,那么当函数返回的时候,该变量指向的内存空间就会被回收,程序势必会报错,因此对于这种变量只能在堆上分配。
比如下边这个例子,返回的是指针
$ go build -gcflags '-m -l' demo.go # command-line-arguments ./demo.go:6:2: moved to heap: v ./demo.go:12:13: ... argument does not escape ./demo.go:12:14: *m escapes to heap
从逃逸分析的结果中可以看到 moved to heap: v예를 들어 다음 예에서는 포인터를 반환합니다
func foo() []int {
a := []int{1,2,3}
return a
}
func main() {
b := foo()
fmt.Println(b)
}🎜 탈출 분석 결과에서 확인할 수 있습니다힙으로 이동: v, v 변수는 힙에서 할당된 메모리입니다. , 위의 시나리오에는 분명한 차이점이 있습니다. 🎜$ go build -gcflags '-m -l' demo.go # command-line-arguments ./demo.go:6:2: moved to heap: v ./demo.go:12:13: ... argument does not escape ./demo.go:12:14: *m escapes to heap
除了返回指针之外,还有其他的几种情况也可归为一类:
第一种情况:返回任意引用型的变量:Slice 和 Map
func foo() []int {
a := []int{1,2,3}
return a
}
func main() {
b := foo()
fmt.Println(b)
}逃逸分析结果
$ go build -gcflags '-m -l' demo.go # command-line-arguments ./demo.go:6:12: []int literal escapes to heap ./demo.go:12:13: ... argument does not escape ./demo.go:12:13: b escapes to heap
第二种情况:在闭包函数中使用外部变量
func Increase() func() int {
n := 0
return func() int {
n++
return n
}
}
func main() {
in := Increase()
fmt.Println(in()) // 1
fmt.Println(in()) // 2
}逃逸分析结果
$ go build -gcflags '-m -l' demo.go # command-line-arguments ./demo.go:6:2: moved to heap: n ./demo.go:7:9: func literal escapes to heap ./demo.go:15:13: ... argument does not escape ./demo.go:15:16: in() escapes to heap
根据变量类型是否确定
在上边例子中,也许你发现了,所有编译输出的最后一行中都是 m escapes to heap 。
奇怪了,为什么 m 会逃逸到堆上?
其实就是因为我们调用了 fmt.Println() 函数,它的定义如下
func Println(a ...interface{}) (n int, err error) {
return Fprintln(os.Stdout, a...)
}可见其接收的参数类型是 interface{} ,对于这种编译期不能确定其参数的具体类型,编译器会将其分配于堆上。
根据变量的占用大小
最开始的时候,就介绍到,以 64KB 为分界线,我们将内存块分为 小内存块 和 大内存块。
小内存块走常规的 mspan 供应链申请,而大内存块则需要直接向 mheap,在堆区申请。
以下的例子来说明
func foo() {
nums1 := make([]int, 8191) // < 64KB
for i := 0; i < 8191; i++ {
nums1[i] = i
}
}
func bar() {
nums2 := make([]int, 8192) // = 64KB
for i := 0; i < 8192; i++ {
nums2[i] = i
}
}给 -gcflags 多加个 -m 可以看到更详细的逃逸分析的结果
$ go build -gcflags '-m -l' demo.go # command-line-arguments ./demo.go:5:15: make([]int, 8191) does not escape ./demo.go:12:15: make([]int, 8192) escapes to heap
那为什么是 64 KB 呢?
我只能说是试出来的 (8191刚好不逃逸,8192刚好逃逸),网上有很多文章千篇一律的说和 ulimit -a 中的 stack size 有关,但经过了解这个值表示的是系统栈的最大限制是 8192 KB,刚好是 8M。
$ ulimit -a -t: cpu time (seconds) unlimited -f: file size (blocks) unlimited -d: data seg size (kbytes) unlimited -s: stack size (kbytes) 8192
我个人实在无法理解这个 8192 (8M) 和 64 KB 是如何对应上的,如果有朋友知道,还请指教一下。
根据变量长度是否确定
由于逃逸分析是在编译期就运行的,而不是在运行时运行的。因此避免有一些不定长的变量可能会很大,而在栈上分配内存失败,Go 会选择把这些变量统一在堆上申请内存,这是一种可以理解的保险的做法。
func foo() {
length := 10
arr := make([]int, 0 ,length) // 由于容量是变量,因此不确定,因此在堆上申请
}
func bar() {
arr := make([]int, 0 ,10) // 由于容量是常量,因此是确定的,因此在栈上申请
}위 내용은 一篇文章把 Go 中的内存分配扒得干干净净의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!