
알파카 패밀리의 대형 모델이 일괄 진화! 32k 컨텍스트는 Tian Yuandong 팀이 제작한 GPT-4와 동일합니다.

- WBOY앞으로
- 2023-06-28 22:06:521751검색
오픈소스 알파카 대형 모델 LLaMA 컨텍스트는 GPT-4와 동일하며 단 한 번의 간단한 변경만 가능합니다!
Meta AI가 방금 제출한 이 논문에서는 LLaMA 컨텍스트 창을 2k에서 32k로 확장한 후 1000단계 미만의 미세 조정 단계가 필요함을 보여줍니다.
사전 훈련에 비해 비용은 미미합니다.

컨텍스트 창을 확장한다는 것은 AI의 "작업 기억" 용량이 증가한다는 것을 의미합니다. 구체적으로 다음과 같은 일이 가능합니다.
- 보다 안정적인 역할극과 같이 더 많은 대화 라운드를 지원하고 망각을 줄입니다. 데이터는 더 긴 문서나 여러 문서를 한 번에 처리하는 등 더 복잡한 작업을 완료할 수 있습니다
- 더 중요한 의미는 LLaMA를 기반으로 하는 모든 대형 알파카 모델 제품군이 이 방법을 저렴한 비용으로 채택하고 집단적으로 발전할 수 있다는 것입니다.
Alpaca는 현재 가장 포괄적인 오픈 소스 기본 모델이며, 상업적으로 이용 가능한 많은 완전 오픈 소스 대형 모델과 수직 산업 모델을 파생했습니다.
 논문의 교신저자인 Tian Yuandong도 이 새로운 발전을 친구들과 신나게 공유했습니다.
논문의 교신저자인 Tian Yuandong도 이 새로운 발전을 친구들과 신나게 공유했습니다.
 RoPE 기반의 모든 대형 모델 사용 가능
RoPE 기반의 모든 대형 모델 사용 가능
새로운 방법은 위치 보간(Position Interpolation)이라고 하며 RoPE(회전 위치 인코딩)를 사용하는 대형 모델에 적합합니다.
RoPE는 이르면 2021년 초 Zhuiyi Technology 팀에서 제안되었으며 현재 대형 모델의 가장 일반적인 위치 인코딩 방법 중 하나가 되었습니다.
 그러나 이 아키텍처에서 컨텍스트 창을 확장하기 위해 외삽법을 직접 사용하면 self-attention 메커니즘이 완전히 파괴됩니다.
그러나 이 아키텍처에서 컨텍스트 창을 확장하기 위해 외삽법을 직접 사용하면 self-attention 메커니즘이 완전히 파괴됩니다.
구체적으로, 사전 훈련된 컨텍스트의 길이를 벗어나는 부분은 모델 당혹감을 훈련되지 않은 모델과 같은 수준으로 치솟게 만듭니다.
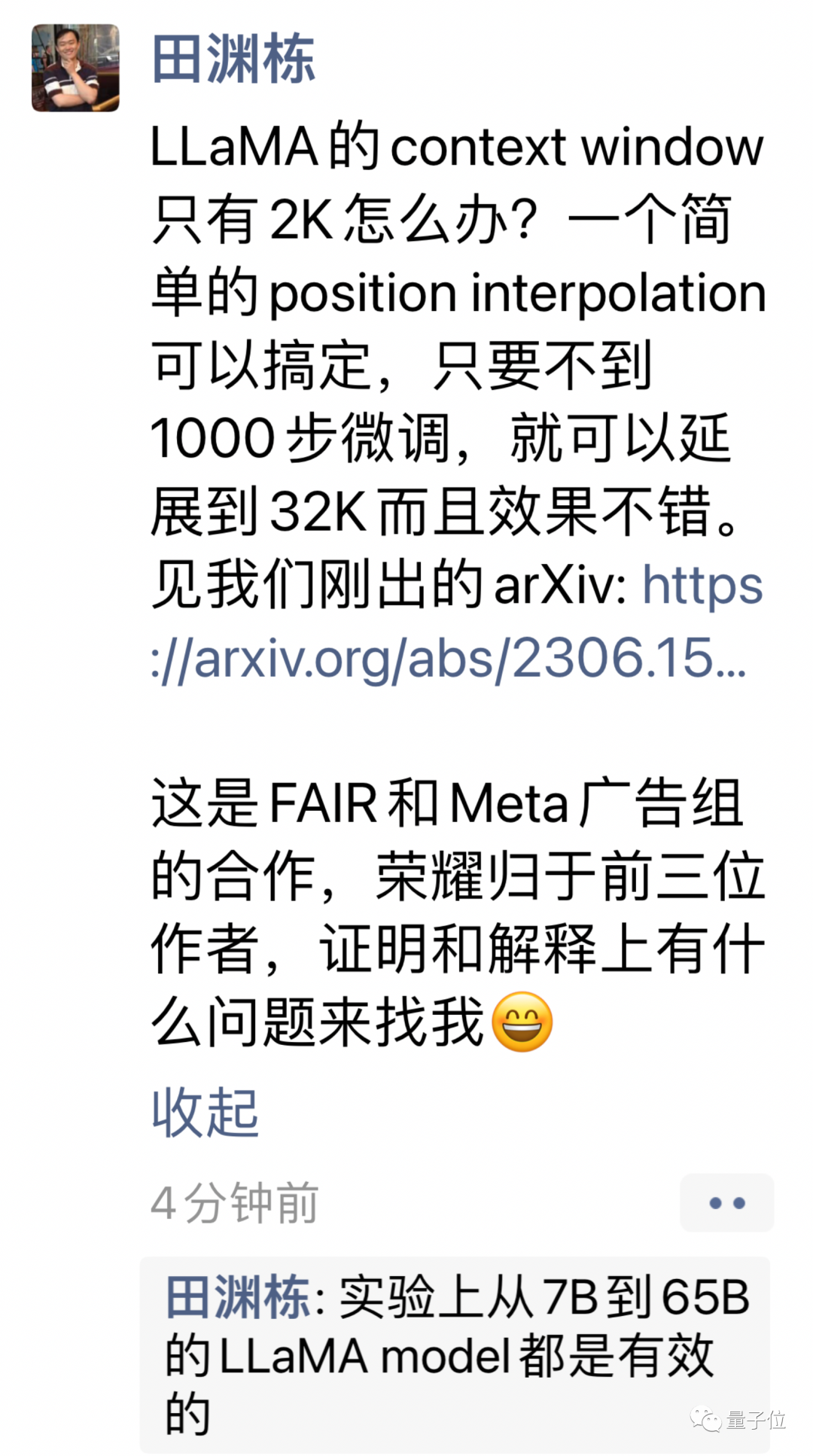
위치 지수를 선형적으로 줄이고 전후 위치 지수와 상대 거리의 범위 정렬을 확장하는 방식으로 새로운 방식이 변경되었습니다.
 둘의 차이를 표현하려면 그림을 사용하는 것이 더 직관적입니다.
둘의 차이를 표현하려면 그림을 사용하는 것이 더 직관적입니다.
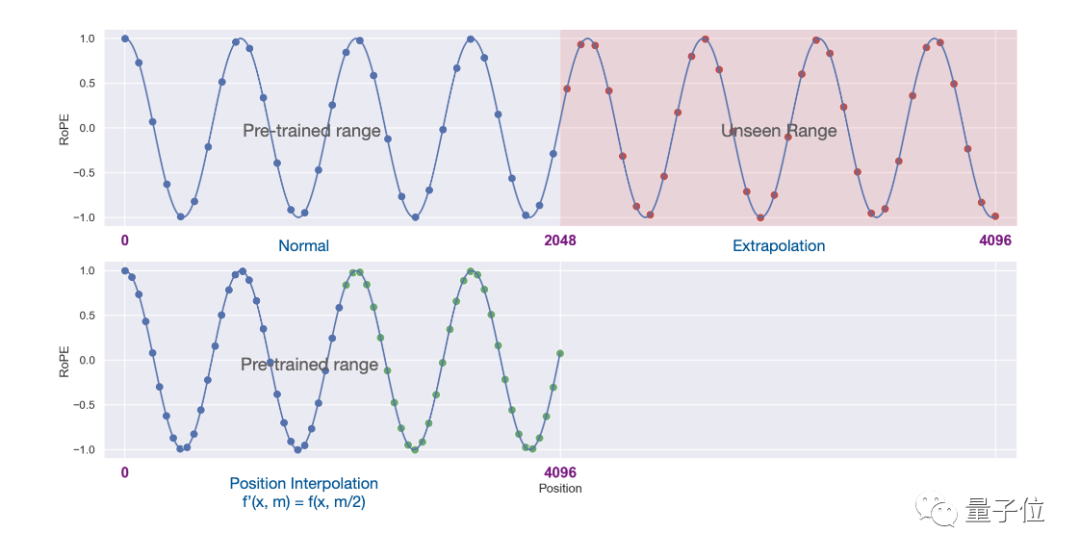 실험 결과, 새로운 방식은 7B부터 65B까지의 LLaMA 대형 모델에 효과적인 것으로 나타났습니다.
실험 결과, 새로운 방식은 7B부터 65B까지의 LLaMA 대형 모델에 효과적인 것으로 나타났습니다.
Long Sequence Language Modeling, Passkey Retrieval, Long Document Summarization에서는 성능이 크게 저하되지 않습니다.
 실험 외에도 새로운 방법에 대한 자세한 증명도 논문의 부록에 나와 있습니다.
실험 외에도 새로운 방법에 대한 자세한 증명도 논문의 부록에 나와 있습니다.
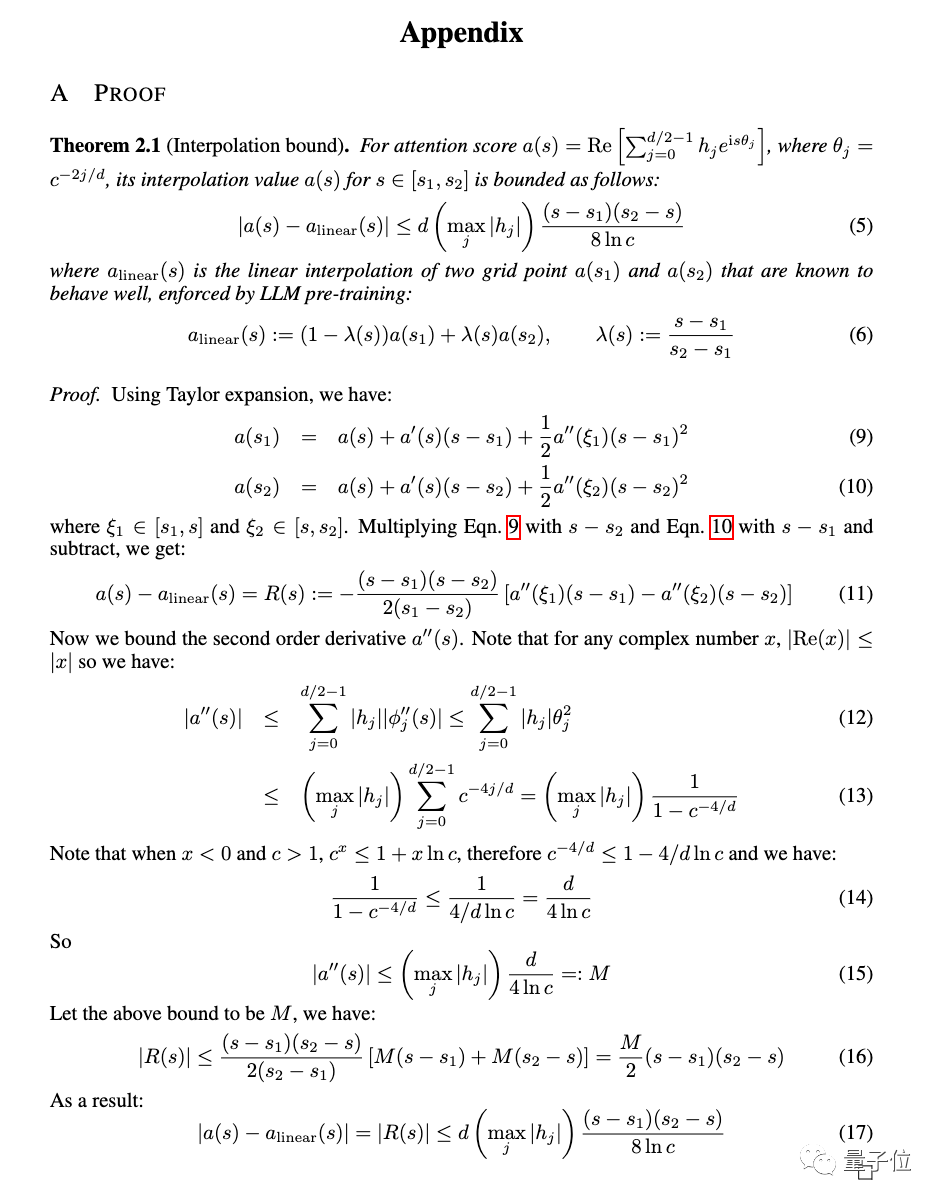 Three More Thing
Three More Thing
컨텍스트 창은 오픈 소스 대형 모델과 상업용 대형 모델 사이의 중요한 간격이었습니다.
예를 들어 OpenAI의 GPT-3.5는 최대 16k를 지원하고 GPT-4는 32k를 지원하며 AnthropicAI의 Claude는 최대 100k를 지원합니다.
동시에 LLaMA, Falcon 등 많은 오픈소스 대형 모델이 여전히 2k에 머물고 있습니다.
이제 Meta AI의 새로운 결과는 이러한 격차를 직접적으로 해소했습니다.
컨텍스트 창을 확장하는 것도 최근 대형 모델 연구의 초점 중 하나입니다. 위치 보간 방법 외에도 업계의 관심을 끌기 위한 많은 시도가 있습니다.
1. 개발자 kaiokendev는 기술 블로그에서 LLaMa 컨텍스트 창을 8k로 확장하는 방법을 탐색했습니다.
 2. 데이터 보안 회사 Soveren의 기계 학습 책임자인 Galina Alperovich는 기사에서 컨텍스트 창을 확장하기 위한 6가지 팁을 요약했습니다.
2. 데이터 보안 회사 Soveren의 기계 학습 책임자인 Galina Alperovich는 기사에서 컨텍스트 창을 확장하기 위한 6가지 팁을 요약했습니다.
3. Mila, IBM 및 기타 기관의 팀도 논문에서 Transformer의 위치 인코딩을 완전히 제거하려고 시도했습니다.伴 필요하신 분들은 아래 링크를 클릭하시면 보실 수 있어요~
메타 논문:  Https://www.php.cn/link/0BDF2C1F05365071F0C725D754B96
Https://www.php.cn/link/0BDF2C1F05365071F0C725D754B96
ht TPS:/ /www.php.cn/link/9659078925b57e621eb3f9ef19773ac3
LLM의 100K 컨텍스트 창 뒤에 숨겨진 비밀 소스https://www.php.cn/link/09a630e07af043e4cae879dd60db1cac
None 위치 코딩 페이퍼https:/ /www.php.cn/link/fb6c84779f12283a81d739d8f088fc12
위 내용은 알파카 패밀리의 대형 모델이 일괄 진화! 32k 컨텍스트는 Tian Yuandong 팀이 제작한 GPT-4와 동일합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!