
Java 프로그래머는 처음부터 LangChain(모델 구성 요소)을 배웁니다.

- PHPz앞으로
- 2023-06-03 20:23:491752검색
이전 기사에서는 LangChain에 대한 몇 가지 기본 지식을 소개했습니다. 아직 보지 못한 친구들은 여기를 클릭하여 살펴볼 수 있습니다. 오늘은 LangChain의 첫 번째 매우 중요한 구성 요소 모델인 Model을 소개하겠습니다.
여기에 언급된 모델은 OpenAI와 유사한 언어 모델이 아닌 LangChain의 모델 구성 요소를 의미한다는 점에 유의하세요. LangChain에 모델 구성 요소가 있는 이유는 OpenAI의 언어 모델을 제외하고 업계에 언어 모델이 너무 많기 때문입니다. 회사 OpenAI 외에도 많은 곳이 있습니다.
LangChain에는 LLM 대형 언어 모델, 채팅 모델 및 텍스트 임베딩 모델이라는 세 가지 유형의 모델 구성 요소가 있습니다.
LLM 대형 언어 모델
LLM은 입력 및 출력 모두 문자열만 지원하므로 대부분의 시나리오에서 요구 사항을 충족할 수 있습니다. Colab([https://colab.research.google.com)
예를 들어
다음은 Python 코드를 직접 작성할 수 있으며, 먼저 종속성을 설치한 후 다음 코드를 실행합니다.
pip install openaipip install langchain
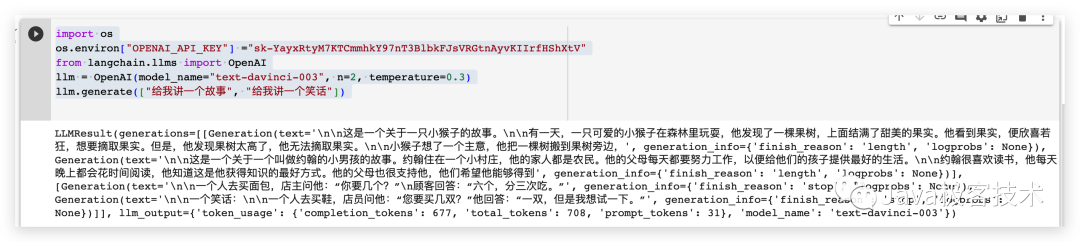
import os# 配置OpenAI 的 API KEYos.environ["OPENAI_API_KEY"] ="sk-xxx"# 从 LangChain 中导入 OpenAI 的模型from langchain.llms import OpenAI# 三个参数分别代表OpenAI 的模型名称,执行的次数和随机性,数值越大越发散llm = OpenAI(model_name="text-davinci-003", n=2, temperature=0.3)llm.generate(["给我讲一个故事", "给我讲一个笑话"])
작업 결과는 다음과 같습니다
Chat 모델 Chat 모델
Chat 모델은 LLM 모델을 기반으로 하지만 LLM 모델 간의 입출력보다 Chat 모델이 더 구조화되어 있습니다. 구성요소, 입력 및 출력 매개변수는 유형이 모두 단순 문자열이 아닌 채팅 모델입니다. 일반적으로 사용되는 채팅 모델 유형에는 다음
- AIMessage가 포함됩니다. 다음 요청 시 이 정보가 LLM으로 다시 전송될 수 있도록 LLM의 응답을 저장하는 데 사용됩니다.
- HumanMessage: "빠른 정렬 방법 구현"과 같이 LLM에 전송되는 프롬프트 메시지
- SystemMessage: LLM 모델의 동작과 목표를 설정합니다. 여기에서 "코딩 전문가 되기" 또는 "json 형식 반환"과 같은 구체적인 지침을 제공할 수 있습니다.
- ChatMessage: ChatMessage는 어떤 형태로든 값을 받을 수 있지만 대부분의 경우 위의 세 가지 유형을 사용해야 합니다.
예를 들어
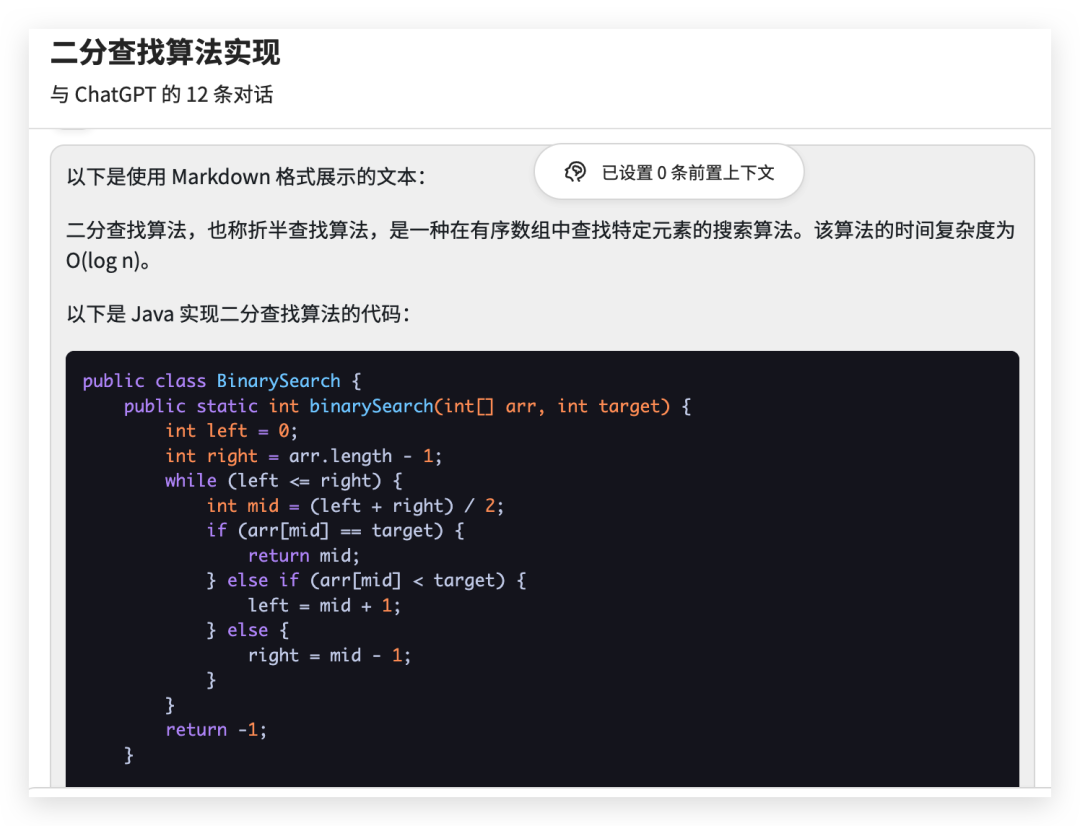
from langchain.chat_models import ChatOpenAIfrom langchain.schema import (AIMessage,HumanMessage,SystemMessage)chat = ChatOpenAI(temperature=0)messages = [SystemMessage(cnotallow="返回的数据markdown 语法进行展示,代码使用代码块包裹"),HumanMessage(cnotallow="用 Java 实现一个二分查找算法")]print(chat(messages))
생성된 콘텐츠 문자열 형식은 다음과 같습니다
이진 검색 알고리즘은 정렬된 배열에서 특정 요소를 찾는 데 사용되는 검색 알고리즘으로 이진 검색 알고리즘이라고도 합니다. 이 알고리즘의 시간 복잡도는 O(log n)입니다. nn다음은 Java에서 이진 검색 알고리즘을 구현하는 코드입니다. nnjavanpublic class BinarySearch {n public static int binarySearch(int[] arr, int target) {n int left = 0;n int right = arr.length - 1;n while (왼쪽
콘텐츠의 콘텐츠를 추출하고 다음과 같은 마크다운 구문을 사용하여 표시합니다
이 모델 구성 요소를 사용하면 일부 문자를 미리 설정한 다음 Q&A를 사용자 정의할 수 있습니다.
프롬프트 템플릿
from langchain.chat_models import ChatOpenAIfrom langchain.prompts import (ChatPromptTemplate,PromptTemplate,SystemMessagePromptTemplate,AIMessagePromptTemplate,HumanMessagePromptTemplate,)from langchain.schema import (AIMessage,HumanMessage,SystemMessage)system_template="你是一个把{input_language}翻译成{output_language}的助手"system_message_prompt = SystemMessagePromptTemplate.from_template(system_template)human_template="{text}"human_message_prompt = HumanMessagePromptTemplate.from_template(human_template)chat_prompt = ChatPromptTemplate.from_messages([system_message_prompt, human_message_prompt])messages = chat_prompt.format_prompt(input_language="英语", output_language="汉语", text="I love programming.")print(messages)chat = ChatOpenAI(temperature=0)print(chat(messages.to_messages()))
output
messages=[SystemMessage(cnotallow='당신은 영어를 중국어로 번역하는 어시스턴트입니다', extra_kwargs={}), HumanMessage(cnotallow='나는 프로그래밍을 좋아합니다.', extra_kwargs = {}, example=False)] cnotallow='저는 프로그래밍을 좋아합니다. 예=거짓, 추가_kwargs={}
文本嵌入模型 Text Embedding Models
文本嵌入模型组件相对比较难理解,这个组件接收的是一个字符串,返回的是一个浮点数的列表。在 NLP 领域中 Embedding 是一个很常用的技术,Embedding 是将高维特征压缩成低维特征的一种方法,常用于自然语言处理任务中,如文本分类、机器翻译、推荐系统等。它将文本中的离散数据如单词、短语、句子等,映射为实数向量,以更好地进行神经网络处理和学习。通过 Embedding,文本数据可以被更好地表示和理解,提高了模型的表现力和泛化能力。
举个栗子
from langchain.embeddings import OpenAIEmbeddingsembeddings = OpenAIEmbeddings()text = "hello world"query_result = embeddings.embed_query(text)doc_result = embeddings.embed_documents([text])print(query_result)print(doc_result)
output
[-0.01491016335785389, 0.0013780705630779266, -0.018519161269068718, -0.031111136078834534, -0.02430146001279354, 0.007488010451197624,0.011340680532157421, 此处省略 .......
总结
今天给大家介绍了一下 LangChain 的模型组件,有了模型组件我们就可以更加方便的跟各种 LLMs 进行交互了。
参考资料
官方文档:https://python.langchain.com/en/latest/modules/models.html
위 내용은 Java 프로그래머는 처음부터 LangChain(모델 구성 요소)을 배웁니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!