
집 >데이터 베이스 >MySQL 튜토리얼 >MySQL의 일반적인 고가용성 아키텍처 배포 솔루션은 무엇입니까?
MySQL의 일반적인 고가용성 아키텍처 배포 솔루션은 무엇입니까?

- 王林앞으로
- 2023-06-03 11:05:552504검색
MySQL의 클러스터 배포 솔루션
머리말
MySQL에서 일반적으로 사용되는 배포 솔루션에 대해 이야기해 보겠습니다.
MySQL 복제
MySQL 복제는 공식적으로 제공되는 마스터-슬레이브 동기화 솔루션으로, 하나의 MySQL 인스턴스를 다른 인스턴스와 동기화하는 데 사용됩니다. 복제는 데이터 보안을 보장하는 중요한 보장을 제공하며 현재 가장 널리 사용되는 MySQL 재해 복구 솔루션입니다. 복제는 두 개 이상의 인스턴스를 사용하여 MySQL 마스터-슬레이브 복제 클러스터를 구축하고 단일 지점 쓰기 및 다중 지점 읽기 서비스를 제공하여 읽기 수평 확장을 달성합니다. MySQL Replication 是官方提供的主从同步方案,用于将一个 MySQL 的实例同步到另一个实例中。Replication 为保证数据安全做了重要的保证,是目前运用最广的 MySQL 容灾方案。Replication 用两个或以上的实例搭建了 MySQL 主从复制集群,提供单点写入,多点读取的服务,实现了读的 scale out。
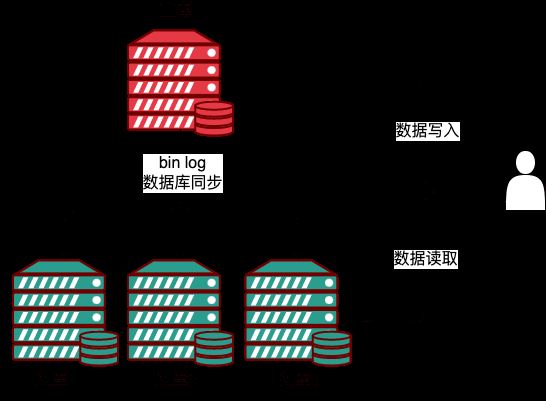
上面的栗子,一个主库(M),三个从库(S),通过 replication,Master 生成 event 的 binlog,然后发给 slave,Slave 将 event 写入 relaylog,然后将其提交到自身数据库中,实现主从数据同步。
对于数据库之上的业务层来说,基于 MySQL 的主从复制集群,单点写入 Master ,在 event 同步到 Slave 后,读逻辑可以从任何一个 Slave 读取数据,以读写分离的方式,大大降低 Master 的运行负载,同时提升了 Slave 的资源利用。
优点:
1、通过读写分离实现横向扩展的能力,写入和更新操作在源服务器上进行,从服务器中进行数据的读取操作,通过增大从服务器的个数,能够极大的增强数据库的读取能力;
2、数据安全,因为副本可以暂停复制过程,所以可以在副本上运行备份服务而不会破坏相应的源数据;
3、方便进行数据分析,可以在写库中创建实时数据,数据的分析操作在从库中进行,不会影响到源数据库的性能;
实现原理
在主从复制中,从库利用主库上的 binlog 进行重播,实现主从同步,复制的过程中蛀主要使用到了 dump thread,I/O thread,sql thread 这三个线程。
IO thread: 在从库执行 start slave 语句时创建,负责连接主库,请求 binlog,接收 binlog 并写入 relay-log;
dump thread:用于主库同步 binlog 给从库,负责响应从 IO thread 的请求。主库会给每个从库的连接创建一个 dump thread,然后同步 binlog 给从库;
sql thread:读取 relay log 执行命令实现从库数据的更新。
来看下复制的流程:
1、主库收到更新命令,执行更新操作,生成 binlog;
2、从库在主从之间建立长连接;
3、主库 dump_thread 从本地读取 binlog 传送刚给从库;
4、从库从主库获取到 binlog 后存储到本地,成为 relay log(中继日志);
5、sql_thread 线程读取 relay log 解析、执行命令更新数据。
不过 MySQL Replication
위의 예에서는 마스터 라이브러리(M)가 1개 있고 슬레이브 라이브러리(S)가 3개 있습니다. 마스터는 이벤트의 binlog를 생성한 후 슬레이브가 이벤트를 Relaylog에 기록하고 전송합니다. 그런 다음 마스터-슬레이브 데이터 동기화를 달성하기 위해 이를 자체 데이터베이스에 제출합니다. 데이터베이스 위의 비즈니스 계층의 경우 MySQL 기반 마스터-슬레이브 복제 클러스터는 이벤트가 슬레이브에 동기화된 후 읽기에서 모든 슬레이브의 데이터를 읽을 수 있습니다. - 분리 방식을 작성하여 마스터의 작업 부하를 크게 줄이고 슬레이브의 리소스 활용도를 향상시킵니다. 장점: 1. 읽기와 쓰기의 분리를 통해 수평 확장이 가능합니다. 쓰기 및 업데이트 작업은 원본 서버에서 수행되고, 데이터 읽기 작업은 서버에서 수행됩니다. 2. 복사본이 복제 프로세스를 일시 중지할 수 있으므로 해당 원본 데이터를 파괴하지 않고 복사본에 대해 백업 서비스를 실행할 수 있으므로 데이터 보안이 크게 향상됩니다. 데이터 분석을 위해 쓰기 데이터베이스에서 실시간 데이터를 생성할 수 있으며, 데이터 분석 작업은 슬레이브 데이터베이스에서 수행되므로 소스 데이터베이스의 성능에 영향을 미치지 않습니다. 구현 원칙마스터-슬레이브 복제에서; , 슬레이브 데이터베이스는 재생을 위해 마스터 데이터베이스의 binlog를 사용합니다. 마스터-슬레이브 동기화를 달성하기 위해
덤프 스레드, I/O 스레드 및 sql 스레드의 세 가지 스레드가 복사 프로세스 중에 주로 사용됩니다. .
IO 스레드: 슬레이브 라이브러리가 start 슬레이브 문을 실행할 때 생성됩니다. 메인 라이브러리에 연결하고, binlog를 요청하고, binlog를 수신하고, 릴레이에 쓰기를 담당합니다. log;
dump thread: 메인 라이브러리의 binlog를 슬레이브 라이브러리로 동기화하는 데 사용되며 IO 스레드의 요청에 응답합니다. 메인 라이브러리는 각 슬레이브 라이브러리 연결에 대해 dump 스레드를 생성한 다음 binlog를 슬레이브 라이브러리에 동기화합니다.
sql 스레드: 릴레이 로그 슬레이브 데이터를 업데이트하는 명령을 실행합니다. <p></p>복제 프로세스를 살펴보겠습니다. <p></p>1. 메인 라이브러리는 업데이트 명령을 수신하고, 업데이트 작업을 수행하며, binlog를 생성합니다. <p></p>2. 슬레이브 라이브러리는 마스터와 슬레이브 사이에 긴 연결을 설정합니다. <p>3. 메인 라이브러리 dump_thread 슬레이브는 binlog를 로컬에서 읽고 슬레이브 라이브러리로 보냅니다. </p>
<p>4. 슬레이브 라이브러리는 메인 라이브러리에서 binlog를 가져와 로컬에 저장하여 <code>relay log가 됩니다.
5.sql_thread 스레드 읽기 릴레이 로그를 가져와 데이터를 업데이트하는 명령을 구문 분석하고 실행합니다.
그러나 MySQL 복제에는 마스터-슬레이브 동기화가 지연된다는 심각한 단점이 있습니다.
마스터와 슬레이브 간에 데이터가 동기화되기 때문에 마스터-슬레이브 동기화 지연이 발생합니다.
🎜마스터-슬레이브 지연은 왜 발생하나요? 🎜🎜1. 슬레이브 데이터베이스 시스템의 성능이 메인 데이터베이스보다 낮습니다. 🎜🎜2. 슬레이브 데이터베이스에 대한 부담이 높습니다. 🎜🎜슬레이브 데이터베이스에 많은 양의 쿼리가 발생할 수 있습니다. 슬레이브 데이터베이스에서 소비되는 CPU 리소스의 양이 줄어들어 슬레이브 데이터베이스의 성능에 영향을 미쳐 마스터-슬레이브 지연이 발생합니다. 🎜🎜3. 대규모 트랜잭션 실행 🎜🎜트랜잭션이 발생하면 마스터 데이터베이스는 트랜잭션이 binlog에 기록될 때까지 기다려야 합니다. 데이터가 슬레이브 데이터베이스로 전송됩니다. 데이터베이스에서 이러한 데이터를 동기화하는 데도 일정 시간이 걸리므로 슬레이브 노드에서 데이터 지연이 발생합니다. 🎜🎜4. 슬레이브 라이브러리의 복제 기능이 좋지 않습니다. 🎜🎜슬레이브 라이브러리의 복제 기능이 마스터 라이브러리의 복제 기능보다 낮을 경우 마스터 라이브러리에 대한 높은 쓰기 압력으로 인해 슬레이브 라이브러리에서 긴 데이터 지연이 발생할 수 있습니다. 🎜🎜어떻게 해결하나요? 🎜🎜1. 다중 스레드 대규모 트랜잭션으로 인한 동시성 시나리오를 방지하기 위해 비즈니스 로직을 최적화합니다. 🎜🎜2. 슬레이브 라이브러리의 시스템 성능을 개선하고 binlog를 작성하는 메인 라이브러리와 binlog를 읽는 슬레이브 라이브러리 간의 효율성 차이를 줄입니다. 3. 네트워크 지연으로 인한 binlog 전송 지연을 방지하기 위해 슬레이브 라이브러리와의 네트워크 연결을 보장합니다. 🎜🎜5. 반동기식 복제에 협력합니다. -sync 반동기식 복제 🎜🎜MySQL에는 세 가지 동기화 모드가 있습니다. 🎜🎜1. 비동기식 복제: MySQL의 기본 복제는 비동기식으로 제출된 트랜잭션을 실행한 후 즉시 결과를 클라이언트에 반환합니다. 클라이언트이며 슬레이브 데이터베이스가 이미 수신하고 처리했는지 여부는 신경 쓰지 않습니다. 문제는 마스터 데이터베이스의 로그가 시간 내에 슬레이브 데이터베이스와 동기화되지 않아 마스터 데이터베이스가 다운되면 장애 조치가 수행되고 슬레이브 데이터베이스에서 마스터가 선택된다는 것입니다. 🎜 불완전할 수 있습니다.2. 완전 동기식 복제: 메인 라이브러리가 트랜잭션을 완료하고 모든 슬레이브 라이브러리도 트랜잭션을 완료할 때까지 기다릴 때 메인 라이브러리가 트랜잭션을 제출하고 데이터를 클라이언트에 반환한다는 의미입니다. 데이터를 반환하기 전에 모든 슬레이브 데이터베이스가 마스터 데이터베이스의 데이터와 동기화될 때까지 기다려야 하기 때문에 마스터-슬레이브 데이터의 일관성은 보장할 수 있지만 데이터베이스의 성능은 필연적으로 영향을 받습니다.
3; 반동기 복제: 완전 동기화와 완전 비동기 동기화 유형 사이에 있습니다. 메인 라이브러리는 릴레이 로그 파일을 수신하고 쓰기 위해 적어도 하나의 슬레이브 라이브러리를 기다려야 합니다. 라이브러리는 모든 슬레이브 라이브러리가 기본 라이브러리에 ACK를 반환할 때까지 기다릴 필요가 없습니다. 메인 라이브러리는 트랜잭션이 완료되었음을 나타내는 ACK를 수신하고 데이터를 클라이언트에 반환합니다. Relay Log 文件即可,主库不需要等待所有从库给主库返回 ACK。主库收到 ACK ,标识这个事务完成,返回数据给客户端。
MySQL 中默认的复制是异步的,所以主库和从库的同步会存在一定的延迟,更重要的是异步复制还可能引起数据的丢失。全同步复制的性能又太差了,所以从 MySQL 5.5 开始,MySQL 以插件的形式支持 semi-sync 半同步复制。
半同步复制潜在的问题
在传统的半同步复制中,主库写数据到 binlog,并且执行 commit 提交事务后,会一直等待一个从库的 ACK。从库会在写入 Relay Log 后,将数据落盘,然后回复给主库 ACK,主库收到这个 ACK 才能给客户端事务完成的确认。
这样会存在问题就是,主库已经将该事务的 commit 存储到了引擎层,应用已经可以看到数据的变化了,只是在等待从库的返回,如果此时主库宕机,可能从库还没有写入 Relay Log,就会发生主从库数据不一致。
为了解决这个问题,MySQL 5.7 引入了增强半同步复制。主库写入数据到 binlog 后,就开始等待从库的应答 ACK,直到至少一个从库写入 Relay Log 后,并将数据落盘,然后返回给主库 ACK,通知主库可以进行 commit 操作,然后主库再将事务提交到事务引擎,应用此时才能看到数据的变化。
不过看下来增强半同步复制,在同步给从库之后,因为自己的数据还没有提交,然后宕机了,主库中也是会存在数据的丢失,不过应该想到的是,这时候主库宕机了,是会重新在从库中选主的,这样新选出的主库数据是没有发生丢失的。
MySQL Group Replication
MySQL Group Replication 组复制,又称为 MGR。是 Oracle MySQL 于 2016 年 12 月发布 MySQL 5.7.17 推出的一个全新高可用和高扩展的解决方案。
引入复制组主要是为了解决传统异步复制和半同步复制可能产生数据不一致的问题。
MGR 由若干个节点共同组成一个复制组,一个事务的提交,必须经过组内大多数节点 (N / 2 + 1) 决议并通过,才能得以提交。
当客户端发起一个更新事务时,该事务先在本地执行,执行完成之后就要发起对事务的提交操作。需要在实际提交之前,将所产生的复制写集广播给其他成员进行复制。组中的成员只有在接收到事务广播时,才能全部接收或全部不接收,因为事务是原子性广播。如果组中的所有成员收到了该广播消息(事务),那么他们会按照之前发送事务的相同顺序收到该广播消息。因此,所有的组成员都会按照相同的顺序接收事务的写集,并为该事务建立全局顺序。因此,所有的组成员都会按照相同的顺序接收事务的写集,并为该事务建立全局顺序。
在不同组成员并发执行的事务可能存在冲突。冲突是通过检查和比较两个不同并发事务的 write set
MySQL 5.5부터 MySQL은 플러그인 형태로 반동기 반동기 복제를 지원합니다. 반동기 복제의 잠재적인 문제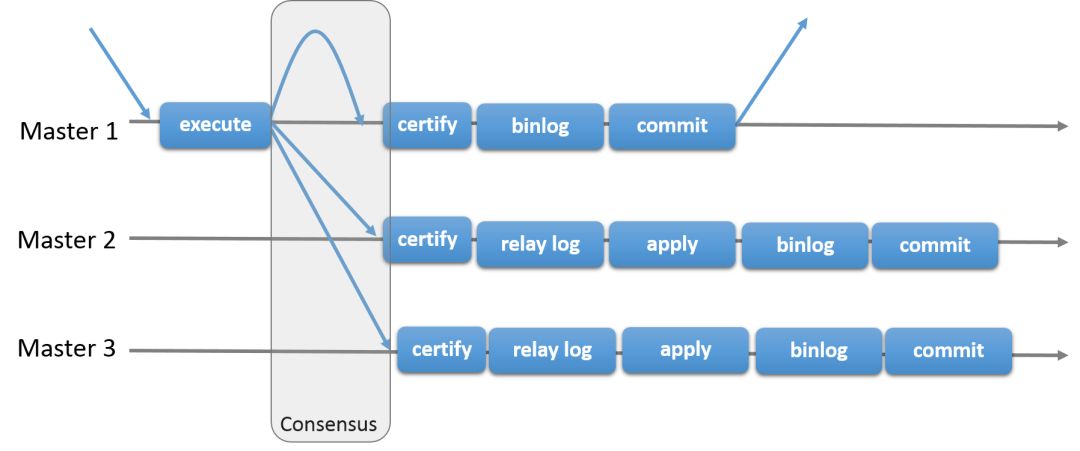 기존 반동기 복제에서 마스터 라이브러리는 binlog에 데이터를 쓰고 커밋을 실행하여 트랜잭션을 커밋합니다. 항상 슬레이브 라이브러리의 ACK를 기다립니다. 슬레이브 라이브러리는
기존 반동기 복제에서 마스터 라이브러리는 binlog에 데이터를 쓰고 커밋을 실행하여 트랜잭션을 커밋합니다. 항상 슬레이브 라이브러리의 ACK를 기다립니다. 슬레이브 라이브러리는 릴레이 로그를 작성한 후 디스크에 데이터를 쓴 다음 ACK로 마스터 라이브러리에 응답합니다. 마스터 라이브러리는 이 ACK를 수신해야만 트랜잭션 완료를 확인할 수 있습니다. 클라이언트.
이 문제는 메인 라이브러리가 이미 엔진 계층에 트랜잭션 커밋을 저장했다는 것입니다. 애플리케이션은 이미 데이터 변경 사항을 볼 수 있으며 메인 라이브러리가 다운된 경우 슬레이브 라이브러리의 반환을 기다리고 있습니다. 이때 슬레이브 라이브러리는 Relay Log가 기록되기 전에 마스터 데이터베이스와 슬레이브 데이터베이스 간의 데이터 불일치가 발생할 수 있습니다.
이 문제를 해결하기 위해 MySQL 5.7에서는 향상된 반동기 복제 기능을 도입했습니다. 마스터 라이브러리는 binlog에 데이터를 쓴 후 하나 이상의 슬레이브 라이브러리가 릴레이 로그를 쓰고 데이터를 디스크에 쓴 다음 반환될 때까지 슬레이브 라이브러리의 응답 ACK를 기다리기 시작합니다. 마스터 라이브러리에 대한 ACK를 통해 메인 라이브러리가 커밋 작업을 수행한 다음 메인 라이브러리가 트랜잭션 엔진에 트랜잭션을 제출해야만 애플리케이션이 데이터 변경 사항을 볼 수 있습니다.
MySQL 그룹 복제
🎜MySQL 그룹 복제 그룹 복제(MGR이라고도 함). 2016년 12월 출시된 MySQL 5.7.17과 함께 Oracle MySQL이 출시한 새로운 고가용성, 고확장성 솔루션입니다. 🎜🎜복제 그룹의 도입은 주로 기존 비동기 복제와 반동기 복제에서 발생할 수 있는 데이터 불일치 문제를 해결하기 위한 것입니다. 🎜🎜MGR은 함께 복제 그룹을 형성하는 여러 노드로 구성됩니다. 트랜잭션 제출은 (N/2 + 1) 그룹의 대다수 노드에 의해 해결되고 승인되어야 합니다. 제출된. 🎜🎜클라이언트가 업데이트 트랜잭션을 시작하면 트랜잭션이 먼저 로컬에서 실행되고 실행이 완료된 후 트랜잭션 커밋 작업이 시작됩니다. 복제된 쓰기 세트 결과는 실제 커밋 전에 복제를 위해 다른 구성원에게 브로드캐스트되어야 합니다. 그룹의 구성원은 트랜잭션 브로드캐스트를 수신할 때 트랜잭션 전체를 수신하거나 전혀 수신하지 못할 수 있습니다. 트랜잭션은 원자 브로드캐스트이기 때문입니다. 그룹의 모든 구성원이 브로드캐스트 메시지(트랜잭션)를 받으면 이전에 전송된 트랜잭션이 전송된 순서와 동일한 순서로 이를 수신합니다. 따라서 모든 그룹 구성원은 트랜잭션의 쓰기 세트를 동일한 순서로 수신하여 트랜잭션의 전역 순서를 설정합니다. 따라서 모든 그룹 구성원은 트랜잭션의 쓰기 세트를 동일한 순서로 수신하여 트랜잭션의 전역 순서를 설정합니다. 🎜🎜다른 그룹의 구성원이 동시에 실행하는 거래는 충돌할 수 있습니다. 서로 다른 두 동시 트랜잭션의 쓰기 세트를 검사하고 비교하여 충돌을 확인합니다. 이 프로세스를 인증이라고 합니다. 인증 중에 충돌 감지는 행 수준에서 수행됩니다. 서로 다른 그룹 구성원에서 실행된 두 개의 동시 트랜잭션이 동일한 데이터 행을 업데이트하면 충돌이 발생합니다. 충돌 인증 감지 메커니즘에 따르면 첫 번째 제출된 트랜잭션이 정상적으로 실행되고 두 번째 제출된 트랜잭션이 트랜잭션이 시작된 원래 그룹 구성원에서 롤백되며 그룹의 다른 구성원이 해당 트랜잭션을 삭제합니다. 두 트랜잭션이 자주 충돌하는 경우 동일한 그룹 구성원에서 두 트랜잭션을 실행하는 것이 가장 좋습니다. 그래야 두 트랜잭션 중 하나에 있기 때문이 아니라 로컬 잠금 관리자의 조정 하에 성공적으로 커밋할 수 있습니다. 여러 그룹 구성원 간의 인증 충돌로 인해 자주 롤백됩니다. 🎜🎜결국 모든 그룹 구성원은 동일한 순서로 동일한 거래 세트를 받습니다. 그룹 내 데이터의 강력한 일관성을 보장하기 위해 그룹 구성원은 동일한 수정 작업을 동일한 순서로 수행해야 합니다. 🎜🎜🎜🎜🎜다음과 같은 특징이 있습니다.🎜🎜1. 분할 브레인 방지: MGR에서는 분할 브레인이 발생하지 않습니다.🎜2. 데이터 일관성 보장: MGR은 매우 우수한 중복 기능을 갖추고 있으며 멤버 중 절반 이상이 다운되지 않는 한 Binlog 이벤트가 최소한 절반 이상 복사되도록 보장할 수 있습니다. 동시에 데이터 손실이 발생하지 않습니다. MGR은 또한 Binlog 이벤트가 회원의 절반 이상에게 전송되지 않는 한 로컬 회원이 거래의 Binlog 이벤트를 Binlog 파일에 쓰지 않도록 하고 트랜잭션을 커밋하여 가동 중지 시간을 보장합니다. 그룹의 온라인 구성원에 존재하지 않는 데이터는 서버에 없습니다. 따라서 다운된 서버가 다시 시작된 후에는 더 이상 그룹에 가입하기 위해 특별한 처리가 필요하지 않습니다. Binlog Event 至少被复制到超过一半的成员上,只要同时宕机的成员不超过半数便不会导致数据丢失。MGR还保证只要 Binlog Event 没有被传输到半数以上的成员,本地成员不会将事务的 Binlog Event 写入 Binlog 文件和提交事务,从而保证宕机的服务器上不会有组内在线成员上不存在的数据。因此,宕机的服务器重启后,不再需要特殊的处理就可以加入组;
3、多节点写入支持:多写模式下支持集群中的所有节点都可以写入。
组复制的应用场景
1、弹性复制:需要非常灵活的复制基础设施的环境,其中MySQL Server的数量必须动态增加或减少,并且在增加或减少Server的过程中,对业务的副作用尽可能少。例如,云数据库服务;
2、高可用分片:分片是实现写扩展的一种流行方法。基于 组复制 实现的高可用分片,其中每个分片都会映射到一个复制组上(逻辑上需要一一对应,但在物理上,一个复制组可以承载多个分片);
3、替代主从复制:在某些情况下,使用一个主库会造成单点争用。在一些场景下,将数据同时写入组中多个成员,能给应用程序带来更好的可扩展性
4、自治系统:可以利用组复制内置的自动故障转移、数据在不同组成员之间的原子广播和最终数据一致性的特性来实现一些运维自动化。
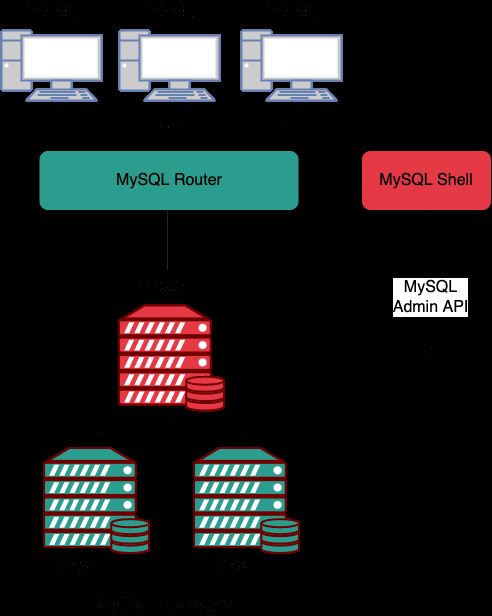
InnoDB Cluster
InnoDB Cluster 是官方提供的高可用方案,是 MySQL 的一种高可用性(HA)解决方案,它通过使用 MySQL Group Replication 来实现数据的自动复制和高可用性,InnoDB Cluster 通常包含下面三个关键组件:
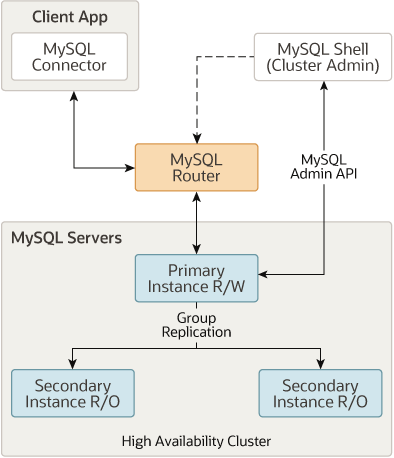
1、MySQL Shell: 它是 MySQL 的高级管理客户端;
2、MySQL Server 和 MGR,使得一组 MySQL 实例能够提供高可用性,对于 MGR,Innodb Cluster 提供了一种更加易于编程的方式来处理 MGR;
3、MySQL Router,一种轻量级中间件,主要进行路由请求,将客户端发送过来的请求路由到不同的 MySQL 服务器节点。
MySQL Server 基于 MySQL Group Replication 构建,提供自动成员管理,容错,自动故障转移动能等。InnoDB Cluster 通常以单主模式运行,一个读写实例和多个只读实例。不过也可以选用多主模式。
优点:
1、高可用性:通过 MySQL Group Replication,InnoDB Cluster 能够实现数据在集群中的自动复制,从而保证数据的可用性;
2、简单易用:InnoDB Cluster 提供了一个简单易用的管理界面,使得管理员可以快速部署和管理集群;
3、全自动故障转移: InnoDB Cluster 能够自动检测和诊断故障,并进行必要的故障转移,使得数据可以继续可用。
缺点:
1、复杂性:InnoDB Cluster 的部署和管理比较复杂,需要对 MySQL 的工作原理有一定的了解;
2、性能影响:由于自动复制和高可用性的要求,InnoDB Cluster 可能对 MySQL 的性能造成一定的影响;
3、限制:InnoDB Cluster 的功能对于一些特殊的应用场景可能不够灵活,需要更多的定制。
InnoDB ClusterSet
MySQL InnoDB ClusterSet 通过将主 InnoDB Cluster 与其在备用位置(例如不同数据中心)的一个或多个副本链接起来,为 InnoDB Cluster 部署提供容灾能力。
InnoDB ClusterSet 使用专用的 ClusterSet 复制通道自动管理从主集群到副本集群的复制。如果主集群由于数据中心损坏或网络连接丢失而变得无法使用,用户可以激活副本集群以恢复服务的可用性。
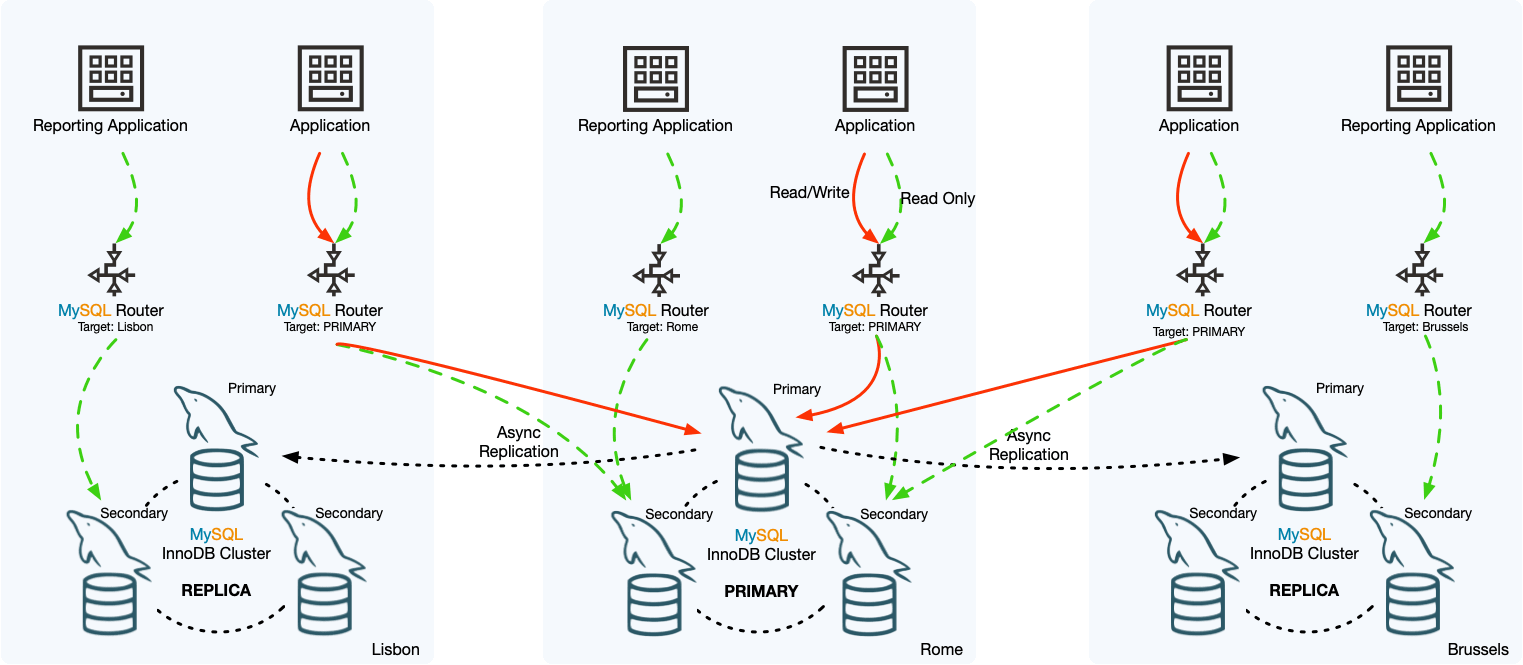
InnoDB ClusterSet 的特点:
1、主集群和副本集群之间的紧急故障转移可以由管理员通过 MySQL Shell
InnoDB 클러스터
🎜InnoDB 클러스터는 MySQL용 고가용성(HA) 솔루션입니다. MySQL 그룹 복제를 사용합니다. > 자동 데이터 복제 및 고가용성을 달성하기 위해 InnoDB 클러스터에는 일반적으로 다음 세 가지 주요 구성 요소가 포함됩니다. 🎜🎜🎜🎜1. MySQL Shell: MySQL End의 고급 관리 클라이언트입니다. 🎜🎜2, MySQL Server 및 MGR, MySQL 인스턴스 그룹을 활성화하여 MGR의 경우 Innodb Cluster MGR을 처리하는 보다 프로그래밍 가능한 방법을 제공합니다. 🎜🎜3. 주로 요청을 라우팅하고 클라이언트에서 보내는 경량 미들웨어입니다. 요청은 다른 MySQL 서버 노드로 라우팅됩니다. 🎜🎜<code>MySQL 서버는 MySQL 그룹 복제를 기반으로 구축되어 자동 구성원 관리, 내결함성, 자동 장애 조치 기능 등을 제공합니다. InnoDB 클러스터는 일반적으로 하나의 읽기-쓰기 인스턴스와 여러 개의 읽기 전용 인스턴스가 있는 단일 마스터 모드에서 실행됩니다. 그러나 다중 마스터 모드를 선택할 수도 있습니다. 🎜🎜장점: 🎜🎜1. 고가용성: MySQL 그룹 복제를 통해 InnoDB 클러스터는 클러스터의 데이터를 자동으로 복제할 수 있으므로 데이터 가용성이 보장됩니다. 사용하기 쉬움: InnoDB 클러스터는 간단하고 사용하기 쉬운 관리 인터페이스를 제공하여 관리자가 클러스터를 신속하게 배포하고 관리할 수 있도록 합니다. 🎜🎜3 완전 자동 장애 조치: InnoDB 클러스터는 데이터를 계속 사용할 수 있도록 오류를 자동으로 감지 및 진단하고 필요한 장애 조치를 수행할 수 있습니다. 🎜🎜단점: 🎜🎜1. 복잡성: <code>InnoDB 클러스터의 배포 및 관리는 상대적으로 복잡하며 MySQL의 작동 원리에 대한 특정 이해가 필요합니다. 🎜🎜2. 가용성 요구 사항으로 인해 InnoDB 클러스터는 MySQL의 성능에 특정 영향을 미칠 수 있습니다. 🎜🎜3 제한 사항: InnoDB 클러스터의 기능은 충분히 유연하지 않을 수 있습니다. 일부 특수 애플리케이션 시나리오의 경우 더 많은 사용자 정의가 필요합니다. 🎜InnoDB ClusterSet
🎜MySQL InnoDB ClusterSet 기본 InnoDB 클러스터를 대체 위치(예: 다른 데이터 센터)에 있는 하나 이상의 복제본과 연결 ) InnoDB 클러스터 배포를 위한 재해 복구 기능을 시작하고 제공합니다. 🎜🎜InnoDB ClusterSet는 전용 ClusterSet 복제 채널을 사용하여 마스터 클러스터에서 복제본 클러스터로의 복제를 자동으로 관리합니다. 데이터 센터 손상이나 네트워크 연결 끊김으로 인해 기본 클러스터를 사용할 수 없는 경우 사용자는 복제 클러스터를 활성화하여 서비스 가용성을 복원할 수 있습니다. 🎜🎜🎜 🎜 InnoDB ClusterSet의 기능: 🎜🎜1. 관리자는 AdminAPI를 사용하여 MySQL Shell을 통해 운영할 수 있습니다. 🎜🎜2. 복제본 클러스터 수에는 정의된 제한이 없습니다.3. 비동기 복제 채널은 기본 클러스터에서 복제본 클러스터로 트랜잭션을 복제합니다. clusterset_replication InnoDB ClusterSet 생성 프로세스 중에 ClusterSet이라는 복제 채널이 각 클러스터에 설정됩니다. 클러스터가 복제본인 경우 이 채널을 사용하여 클러스터에서 데이터를 얻습니다. 기본 클러스터를 복사합니다. 기본 그룹 복제 기술은 채널을 관리하고 마스터 클러스터의 마스터 서버(발신자)와 복제본 클러스터의 마스터 서버(수신자) 사이에서 항상 복제가 이루어지도록 보장합니다. clusterset_replication 在 InnoDB ClusterSet 创建过程中,在每个集群上都设置了名为 ClusterSet 的复制通道,当集群是副本时,它使用该通道从主集群复制事务。底层组复制技术管理通道并确保复制始终在主集群的主服务器(作为发送方)和副本集群的主服务器(作为接收方)之间进行;
4、每个 InnoDB ClusterSet 集群,只有主集群能够接收写请求,大多数的读请求流量也会被路由到主集群,不过也可以指定读请求到其他的集群;
InnoDB ClusterSet 的限制:
1、InnoDB ClusterSet 只支持异步复制,不能使用半同步复制,无法避免异步复制的缺陷:数据延迟、数据一致性等;
2、InnoDB Cluster Set只支持单主模式的Cluster实例,不支持多主模式。 即只能包含一个读写主集群, 所有副本集群都是只读的, 不允许具有多个主集群的双活设置,因为在集群发生故障时无法保证数据一致性;
3、已有的 InnoDB Cluster 不能用作 InnoDB ClusterSet 部署中的副本集群。为了创建一个新的 InnoDB 集群,副本集群必须从单个服务器实例启动
4、只支持 MySQL 8.0。
InnoDB ReplicaSet
InnoDB ReplicaSet 是 MySQL 团队在 2020 年推出的一款产品,用来帮助用户快速部署和管理主从复制,在数据库层仍然使用的是主从复制技术。
InnoDB ReplicaSet 由单个主节点和多个辅助节点(传统上称为 MySQL 复制源和副本)组成。
与 InnoDB cluster 类似, MySQL Router 支持针对 InnoDB ReplicaSet 的引导, 这意味着可以自动配置 MySQL Router 以使用 InnoDB ReplicaSet, 而无需手动配置文件. 这使得 InnoDB ReplicaSet 成为一种快速简便的方法, 可以启动和运行 MySQL 复制和 MySQL Router, 非常适合扩展读取, 并在不需要 InnoDB 集群提供高可用性的用例中提供手动故障转移功能。
InnoDB ReplicaSet 的限制:
1、没有自动故障转移,在主节点不可用的情况下,需要使用 AdminAPI 手动触发故障转移,然后才能再次进行任何更改。但是,辅助实例仍可用于读取;
2、由于意外停止或不可用,无法防止部分数据丢失:在意外停止时未完成的事务可能会丢失;
3、在意外退出或不可用后无法防止不一致。如果手动故障转移提升了一个辅助实例,而前一个主实例仍然可用,例如,由于网络分区,裂脑情况可能会导致数据不一致;
4、InnoDB ReplicaSet 不支持多主模式。允许写入所有成员的经典复制拓扑无法保证数据一致性;
5、读取横向扩展是有限的。InnoDB ReplicaSet 基于异步复制,因此无法像 Group Replication 那样调整流量控制;
6、一个 ReplicaSet 最多由一个主实例组成。支持一个或多个辅助。尽管可以添加到 ReplicaSet 的辅助节点的数量没有限制,但是连接到 ReplicaSet 的每个 MySQL Router 都必须监视每个实例。因此,一个 ReplicaSet 中加入的实例越多,监控就越多。
使用 InnoDB ReplicaSets 的主要原因是你有更好的写性能。使用 InnoDB ReplicaSets 的另一个原因是它们允许在不稳定或慢速网络上部署,而 InnoDB Cluster 则不允许。
MMM
MMM(Master-Master replication manager for MySQL)是一套支持双主故障切换和双主日常管理的脚本程序。MMM 使用 Perl 语言开发,主要用来监控和管理 MySQL Master-Master
 2. InnoDB 클러스터 세트는 단일 마스터 모드 클러스터 인스턴스만 지원합니다. 멀티 마스터 모드를 지원하지 않습니다. 즉, 읽기-쓰기 마스터 클러스터는 하나만 포함할 수 있으며, 모든 복제본 클러스터는 읽기 전용입니다. 클러스터가 실패할 경우 데이터 일관성을 보장할 수 없기 때문에 여러 마스터 클러스터를 사용한 활성-활성 설정은 허용되지 않습니다. InnoDB 클러스터는 InnoDB ClusterSet 배포에서 복제 클러스터로 사용할 수 없습니다. 새로운 InnoDB 클러스터를 생성하려면 단일 서버 인스턴스에서 복제본 클러스터를 시작해야 합니다. 4. MySQL 8.0만 지원합니다.
2. InnoDB 클러스터 세트는 단일 마스터 모드 클러스터 인스턴스만 지원합니다. 멀티 마스터 모드를 지원하지 않습니다. 즉, 읽기-쓰기 마스터 클러스터는 하나만 포함할 수 있으며, 모든 복제본 클러스터는 읽기 전용입니다. 클러스터가 실패할 경우 데이터 일관성을 보장할 수 없기 때문에 여러 마스터 클러스터를 사용한 활성-활성 설정은 허용되지 않습니다. InnoDB 클러스터는 InnoDB ClusterSet 배포에서 복제 클러스터로 사용할 수 없습니다. 새로운 InnoDB 클러스터를 생성하려면 단일 서버 인스턴스에서 복제본 클러스터를 시작해야 합니다. 4. MySQL 8.0만 지원합니다.
InnoDB ReplicaSet
InnoDB ReplicaSet는 사용자가 마스터-슬레이브 복제를 빠르게 배포하고 관리할 수 있도록 돕기 위해 2020년 MySQL 팀에서 출시한 제품입니다. 여전히 데이터베이스 계층에서 사용됩니다. 마스터-슬레이브 복제 기술입니다.
InnoDB ReplicaSet 는 단일 기본 노드와 여러 보조 노드(전통적으로 MySQL 복제 소스 및 복제본이라고 함)로 구성됩니다. 🎜🎜InnoDB 클러스터와 유사하게 MySQL 라우터는 InnoDB ReplicaSet 부팅을 지원합니다. 즉, MySQL 라우터는 수동 구성 파일 없이 InnoDB ReplicaSet를 사용하도록 자동으로 코드를 구성하면 InnoDB ReplicaSet가 MySQL 복제 및 MySQL 라우터는 InnoDB 클러스터에서 제공하는 고가용성이 필요하지 않은 사용 사례에서 읽기를 확장하고 수동 장애 조치 기능을 제공하는 데 이상적입니다. 🎜🎜🎜 🎜 InnoDB ReplicaSet의 제한 사항: 🎜🎜1. 마스터 노드를 사용할 수 없으면 다시 변경하기 전에 AdminAPI를 사용하여 수동으로 장애 조치를 실행해야 합니다. 그러나 보조 인스턴스는 계속해서 읽을 수 있습니다. 🎜🎜2. 예기치 않은 중지 또는 사용 불가로 인해 부분적인 데이터 손실을 방지할 수 없습니다. 예기치 않게 종료되거나 사용할 수 없게 되면 완료되지 않은 트랜잭션이 손실될 수 있습니다. 불일치를 방지하는 방법. 예를 들어 네트워크 파티션으로 인해 이전 기본 인스턴스를 계속 사용할 수 있는 동안 수동 장애 조치가 보조 인스턴스를 승격하는 경우 분할 브레인 상황으로 인해 데이터 불일치가 발생할 수 있습니다. 🎜🎜4. InnoDB ReplicaSet는 다중 마스터 모드를 지원하지 않습니다. 모든 구성원에 대한 쓰기를 허용하는 기존 복제 토폴로지는 데이터 일관성을 보장할 수 없습니다. 🎜🎜5. 읽기 수평 확장이 제한됩니다. InnoDB ReplicaSet는 비동기 복제를 기반으로 하므로 그룹 복제처럼 흐름 제어를 조정할 수 없습니다. 🎜🎜6 ReplicaSet은 최대 하나의 마스터 인스턴스로 구성됩니다. 하나 이상의 보조 장치를 지원합니다. ReplicaSet에 추가할 수 있는 보조 노드 수에는 제한이 없지만 ReplicaSet에 연결된 각 MySQL 라우터는 각 인스턴스를 모니터링해야 합니다. 따라서 ReplicaSet에 더 많은 인스턴스를 추가할수록 더 많은 모니터링이 필요합니다. 🎜🎜 InnoDB ReplicaSets를 사용하는 주된 이유는 쓰기 성능이 더 좋다는 것입니다. InnoDB ReplicaSets를 사용하는 또 다른 이유는 InnoDB Cluster가 지원하지 않는 불안정하거나 느린 네트워크에서의 배포를 허용한다는 것입니다. 🎜MMM
🎜MMM(MySQL용 Master-Master 복제 관리자)은 듀얼 마스터 장애 조치 및 듀얼 마스터 일일 관리를 지원하는 스크립트 프로그램 세트입니다. MMM은 Perl 언어를 사용하여 개발되었으며 주로MySQL Master-Master(이중 마스터) 복제를 모니터링하고 관리하는 데 사용됩니다. MySQL 마스터-마스터 복제 관리자라고 할 수 있습니다. 🎜🎜이중 마스터 모드, 비즈니스에서는 하나의 마스터 데이터베이스만 동시에 데이터를 쓸 수 있습니다. 다른 활성 및 대기 데이터베이스는 주 서버에 장애가 발생할 경우 활성 및 대기 전환과 장애 조치를 수행합니다. 🎜🎜MMM은 VIP(가상 IP) 메커니즘을 사용하여 클러스터의 고가용성을 보장합니다. 전체 클러스터에서 마스터 노드는 데이터 읽기 및 쓰기 서비스를 제공하기 위해 VIP 주소를 제공하며, 장애가 발생하면 VIP는 원래 마스터 노드에서 다른 노드로 이전되고 다른 노드는 서비스를 제공합니다. 🎜🎜🎜🎜🎜MMM은 데이터 일관성을 완전히 보장할 수 없으므로 데이터 일관성 요구 사항이 그다지 높지 않은 시나리오에 적합합니다. (기본 및 보조 서버의 데이터가 반드시 최신일 필요는 없으므로 슬레이브 데이터베이스보다 최신이 아닐 수도 있습니다. 해결 방법: 반동기화를 활성화합니다.) 🎜MMM의 장점과 단점
장점: 고가용성, 우수한 확장성, 장애 시 자동 전환, 마스터-마스터 동기화의 경우 데이터 일관성을 보장하기 위해 동시에 하나의 데이터베이스 쓰기 작업만 제공됩니다.
단점: 데이터 일관성을 완전히 보장할 수는 없습니다. 실패 가능성을 줄이기 위해 반동기식 복제를 사용하는 것이 좋습니다. 현재 MMM 커뮤니티에는 유지 관리가 부족하고 GTID 기반 복제를 지원하지 않습니다.
적용 가능한 시나리오:
MMM에 적용 가능한 시나리오는 데이터베이스 액세스 규모가 크고 비즈니스 성장이 빠르며 읽기 및 쓰기 분리가 가능한 시나리오입니다.
MHA
MHA라고 하는 MySQL용 고가용성 관리자 및 도구를 마스터하세요. 이는 MySQL 고가용성 환경에서 장애 조치 및 마스터-슬레이브 승격을 위한 탁월한 고가용성 소프트웨어 세트입니다.
이 도구는 메인 라이브러리의 상태를 모니터링하는 데 특별히 사용됩니다. 마스터 노드에 결함이 있는 것으로 확인되면 자동으로 새 데이터로 슬레이브 노드를 승격하여 이 기간 동안 MHA가 새 마스터 노드가 됩니다. 데이터 일관성 문제를 방지하기 위해 다른 슬레이브 노드의 추가 데이터. MHA는 또한 필요에 따라 전환할 수 있는 마스터-슬레이브 노드를 온라인으로 전환하는 기능을 제공합니다. MHA는 데이터 일관성을 최대한 보장하면서 30초 이내에 장애 조치를 구현할 수 있습니다.
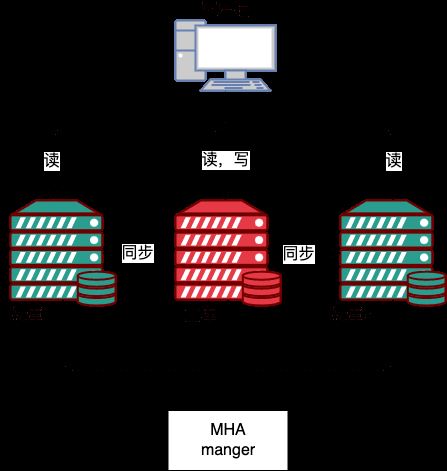
MHA는
MHA Manager(관리 노드)와 MHA Node(데이터 노드)의 두 부분으로 구성됩니다.
MHA Manager는 독립된 시스템에 배포하여 여러 마스터-슬레이브 클러스터를 관리하거나 슬레이브 노드에 배포할 수 있습니다. MHA 노드는 각 MySQL 서버에서 실행됩니다. MHA 관리자는 클러스터의 마스터 노드를 정기적으로 감지하며, 마스터가 실패하면 자동으로 최신 데이터로 슬레이브를 승격할 수 있습니다. 새 마스터로 이동한 다음 다른 모든 슬레이브를 새 마스터로 리디렉션합니다. MHA Manager 可以单独部署在一台独立的机器上管理多个 master-slave 集群,也可以部署在一台 slave节点上。MHA Node 运行在每台 MySQL 服务器上,MHA Manager 会定时探测集群中的 master 节点,当 master 出现故障时,它可以自动将最新数据的 slave 提升为新的 master,然后将所有其他的 slave 重新指向新的 master。
整个故障转移过程对应用程序完全透明。
在 MHA 自动故障切换过程中,MHA 试图从宕机的主服务器上最大限度的保存二进制日志,最大程度的保证数据的不丢失,但这并不总是可行的。例如,主服务器硬件故障或无法通过 ssh 访问,MHA 没法保存二进制日志,只进行故障转移而丢失了最新的数据。
使用 MySQL 5.5 开始找支持的半同步复制,可以大大降低数据丢失的风险。MHA可以与半同步复制结合起来。如果只有一个 slave 已经收到了最新的二进制日志,MHA 可以将最新的二进制日志应用于其他所有的 slave 服务器上,因此可以保证所有节点的数据一致性。
目前 MHA 主要支持一主多从的架构,要搭建 MHA,要求一个复制集群中必须最少有三台数据库服务器 ,一主二从,即一台 master,一台充当备用 master,另外一台充当从库,因为至少需要三台服务器。
MHA 工作原理总结如下:
1、从宕机崩溃的 master 保存二进制日志事件(binlog events);
2、识别最新更新的 slave;
3、应用差异的中继日志(relay log) 到其他slave;
4、应用从master保存的二进制日志事件(binlog events);
5、提升一个 slave 为新master;
6、使用其他的 slave 连接新的 master 进行复制。
优点:
1、可以支持基于 GTID 的复制模式;
2、MHA 在进行故障转移时更不易产生数据丢失;
3、同一个监控节点可以监控多个集群。
缺点:
1、需要编写脚本或利用第三方工具来实现 Vip 的配置;
2、MHA 启动后只会对主数据库进行监控;
3、需要基于 SSH 免认证配置,存在一定的安全隐患。
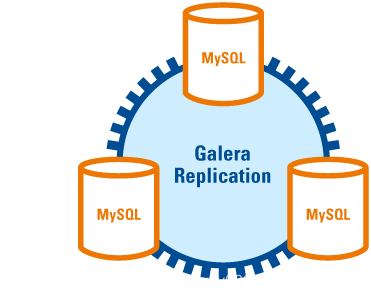
Galera Cluster
Galera Cluster 是由 Codership 开发的MySQL多主集群,包含在 MariaDB 中,同时支持 Percona xtradb、MySQL,是一个易于使用的高可用解决方案,在数据完整性、可扩展性及高性能方面都有可接受的表现。
其本身具有 multi-master 特性,支持多点写入,Galera Cluster
 MHA 자동 장애 조치 프로세스 중에 MHA는 데이터가 최대한 손실되지 않도록 다운된 메인 서버의 바이너리 로그를 최대한 저장하려고 시도하지만 이것이 항상 가능한 것은 아닙니다. 예를 들어, 마스터 서버 하드웨어에 오류가 발생하거나 SSH를 통해 액세스할 수 없는 경우 MHA는 바이너리 로그를 저장할 수 없으며 장애 조치만 수행되고 최신 데이터가 손실됩니다.
MHA 자동 장애 조치 프로세스 중에 MHA는 데이터가 최대한 손실되지 않도록 다운된 메인 서버의 바이너리 로그를 최대한 저장하려고 시도하지만 이것이 항상 가능한 것은 아닙니다. 예를 들어, 마스터 서버 하드웨어에 오류가 발생하거나 SSH를 통해 액세스할 수 없는 경우 MHA는 바이너리 로그를 저장할 수 없으며 장애 조치만 수행되고 최신 데이터가 손실됩니다.
MySQL 5.5를 사용하여 데이터 손실 위험을 크게 줄일 수 있는 지원되는 반동기 복제를 찾아보세요. MHA는 반동기 복제와 결합될 수 있습니다. 하나의 슬레이브만 최신 바이너리 로그를 수신한 경우 MHA는 최신 바이너리 로그를 다른 모든 슬레이브 서버에 적용하여 모든 노드의 데이터 일관성을 보장할 수 있습니다.
현재 MHA는 주로 단일 마스터, 다중 슬레이브 아키텍처를 지원합니다. MHA를 구축하려면 복제 클러스터에 마스터 1개와 슬레이브 2개, 즉 마스터 1개, 백업 마스터 역할을 하는 하나 등 최소 3개의 데이터베이스 서버가 있어야 합니다. , 다른 하나는 3개 이상의 서버가 필요하므로 슬레이브 역할을 합니다.
MHA의 작동 원리는 다음과 같이 요약됩니다.
1. 충돌한 마스터에서 바이너리 로그 이벤트(binlog 이벤트)를 저장합니다.
2. 애플리케이션 차이점을 릴레이합니다.
4. 마스터에서 저장된 바이너리 로그 이벤트를 적용합니다.
5. 슬레이브를 새 마스터로 승격합니다.
6.
🎜장점: 🎜🎜1. GTID 기반 복제 모드를 지원할 수 있습니다. 🎜🎜2. MHA는 장애 조치 중에 데이터 손실이 발생할 가능성이 적습니다. 🎜🎜3. 🎜🎜단점: 🎜🎜1. VIP를 구성하려면 스크립트를 작성하거나 타사 도구를 사용해야 합니다. 🎜🎜2. MHA가 시작된 후에는 기본 데이터베이스만 모니터링됩니다. 🎜🎜3. 필요하며 특정 문제 안전 위험이 있습니다. 🎜🎜Galera Cluster🎜🎜Galera Cluster는 Codership에서 개발한 MySQL 멀티 마스터 클러스터이며 Percona xtradb 및 MySQL도 지원합니다. 사용하기 쉬운 고급 클러스터. 사용 가능한 솔루션은 데이터 무결성, 확장성 및 고성능 측면에서 허용 가능한 성능을 갖습니다. 🎜🎜다중 마스터 특성을 가지며 다중 지점 쓰기를 지원합니다. Galera Cluster의 각 인스턴스는 P2P(Peer-to-Peer), 서로 마스터-슬레이브입니다. 클라이언트가 데이터를 읽고 쓸 때 모든 MySQL 인스턴스를 선택할 수 있습니다. 읽기 작업의 경우 각 인스턴스에서 읽는 데이터는 동일합니다. 쓰기 작업의 경우 데이터가 노드에 기록되면 클러스터는 이를 다른 노드와 동기화합니다. 이 아키텍처는 데이터를 공유하지 않으며 고도로 중복되는 아키텍처입니다. 🎜🎜🎜🎜🎜주요 기능🎜🎜1. 동기식 복제 🎜🎜2. 즉, 모든 노드가 동시에 데이터베이스를 읽고 쓸 수 있습니다. 🎜🎜3. 🎜 🎜4. 새 노드가 추가되면 데이터가 자동으로 복제됩니다. 🎜🎜5. 진정한 병렬 복제, 행 수준 🎜🎜6. 사용자는 클러스터에 직접 연결할 수 있습니다. MySQL. 🎜🎜장점🎜1. 데이터 일관성: 동기식 복제는 모든 노드에서 동일한 선택 쿼리가 실행될 때마다 결과가 동일합니다.
2. 모든 노드의 데이터가 일관됩니다. , 단일 노드 충돌이 발생하지 않습니다. 데이터 손실이나 서비스 중단 없이 복잡하고 시간이 많이 소요되는 장애 조치를 수행할 필요가 없습니다.
3. 성능 개선: 동기식 복제를 통해 클러스터의 모든 노드에서 트랜잭션을 병렬로 실행할 수 있습니다. 따라서 읽기 및 쓰기 성능이 향상됩니다.
5. 읽기 및 쓰기 확장 기능이 모두 있습니다.
원리 분석
동기 복제는 주로 Galera Cluster에서 사용됩니다. 메인 라이브러리의 단일 업데이트 트랜잭션은 메인 라이브러리가 트랜잭션을 커밋할 때 모든 슬레이브 라이브러리에서 동기적으로 업데이트되어야 합니다. 클러스터의 모든 노드 데이터는 일관성을 유지해야 합니다.
비동기 복제에서는 슬레이브 데이터베이스가 데이터 변경 사항을 성공적으로 읽거나 재생하는지 여부에 관계없이 마스터 데이터베이스가 데이터 업데이트를 슬레이브 데이터베이스에 전파한 후 즉시 트랜잭션을 커밋하므로 비동기 복제로 인해 마스터-슬레이브 데이터 동기화에 일시적인 불일치가 발생합니다. Galera Cluster 中主要用到了同步复制,主库中的单个更新事务需要在所有从库中同步更新,当主库提交事务,集群中的所有节点数据保持一致。
异步复制,主库将数据更新传播给从库后立即提交事务,而不论从库是否成功读取或重放数据变化,所以异步复制会存在短暂的,主从数据同步不一致的情况出现。
不过同步复制的缺点也是很明显的,同步复制协议通常使用两阶段提交或分布式锁协调不同节点的操作,也及时说节点越多需要协调的节点也就越多,那么事务冲突和死锁的概率也就会随之增加。
我们知道 MGR 组复制的引入也是为了解决传统异步复制和半同步复制可能产生数据不一致的问题,MGR 中的组复制,基于 Paxos 协议,原则上事务的提交,主要大多数节点 ACK 就可以提交了。
Galera Cluster 中的同步需要同步数据到所有节点,保证所有节点都成功。基于专有通信组系统 GCommon ,所有节点都必须有 ACK。
Galera 复制是一种基于验证的复制,基于验证的复制使用通信和排序技术实现同步复制,通过广播并发事务之间建立的全局总序来协调事务提交。简单的讲就是事务必须以相同的顺序应用于所有实例。
事务现在本地执行,然后发送的其他节点做冲突验证,没有冲突的时候所有节点提交事务,否则在所有节点回滚。
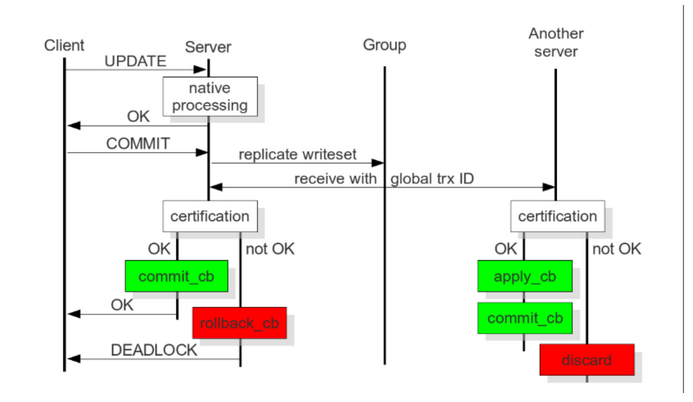
当客户端发出 commit 命令时,在实际提交之前,对数据所做的更改都会收集到一个写集合中,写集合中包含事务信息和所更改行的主键,数据库将写集发送到其它节点。
节点用写集中的主键与当前节点中未完成事务的所有写集的主键比较,确定节点是否可以提交事务,同时满足下面三个条件会被任务存在冲突,验证失败:
1、两个事务来源于不同节点;
2、两个事务包含相同的主键;
3、老事务对新事务不可见,即老事务未提交完成。新老事务的划定依赖于全局事务总序,即 GTID。
每个节点独立进行验证,如果验证失败,该节点将删除写集并回滚原始事务,所有节点都会执行相同的操作。所有节点按照相同顺序接收事务,导致它们都做出相同的结果决定,要么全部成功,要么全部失败。成功后自然就提交了,所有的节点又会重新达到数据一致的状态。节点之间不交换“是否冲突”的信息,各个节点独立异步处理事务。
MySQL Cluster
MySQL Cluster 是一个高度可扩展的,兼容 ACID 事务的实时数据库,基于分布式架构不存在单点故障,MySQL Cluster 支持自动水平扩容,并能做自动的读写负载均衡。
MySQL Cluster 使用了一个叫 NDB 的内存存储引擎来整合多个 MySQL 实例,提供一个统一的服务集群。
NDB是一种采用不共享的Sharding-Nothing架构的内存存储引擎。Sarding-Nothing 指的是每个节点有独立的处理器,磁盘和内存,节点之间没有共享资源完全独立互不干扰,节点之间通过告诉网络组在一起,每个节点相当于是一个小型的数据库,存储部分数据。这种架构的好处是可以利用节点的分布性并行处理数据,调高整体的性能,还有就是有很高的水平扩展性能,只需要增加节点就能增加数据的处理能力。
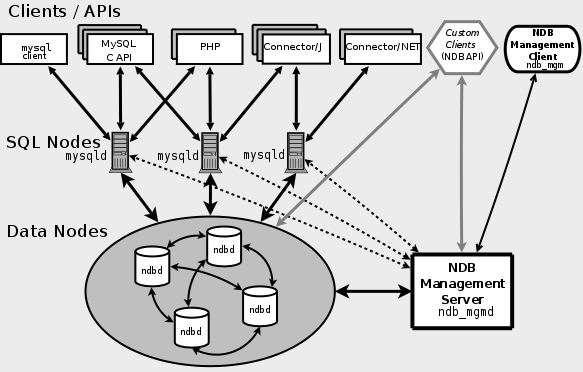
MySql Cluster 中包含三种节点,分别是管理节点(NDB Management Server)、数据节点(Data Nodes)和 SQL查询节点(SQL Nodes) 。
SQL Nodes 是应用程序的接口,像普通的 mysqld 服务一样,接受用户的 SQL 输入,执行并返回结果。Data Nodes 是数据存储节点,NDB Management Server
Galera Cluster의 동기화를 위해서는 모든 노드가 성공하도록 모든 노드에 대한 데이터 동기화가 필요합니다. 독자적인 통신 그룹 시스템 GCommon을 기반으로 모든 노드에는 ACK가 있어야 합니다. 🎜🎜Galera 복제는 일종의 검증 기반 복제입니다. 검증 기반 복제는 통신 및 정렬 기술을 사용하여 동기식 복제를 달성하고 동시 트랜잭션 간에 설정된 전역 총 순서를 브로드캐스팅하여 트랜잭션 제출을 조정합니다. 간단히 말해서 트랜잭션은 모든 인스턴스에 동일한 순서로 적용되어야 합니다. 🎜🎜이제 트랜잭션은 로컬에서 실행된 다음 충돌 확인을 위해 다른 노드로 전송됩니다. 충돌이 없으면 모든 노드가 트랜잭션을 커밋하고 그렇지 않으면 모든 노드에서 롤백됩니다. 🎜🎜🎜 🎜 클라이언트가 커밋 명령을 내리면 실제 커밋 전에 데이터에 대한 변경 사항이 쓰기 세트에 수집되고, 쓰기 세트에는 변경된 행의 기본 키와 트랜잭션 정보가 포함되며, 데이터베이스는 쓰기 세트를 다른 곳으로 보냅니다. 노드. 🎜🎜노드는 쓰기 세트의 기본 키와 현재 노드의 완료되지 않은 모든 트랜잭션 쓰기 세트의 기본 키를 비교하여 다음 세 가지 조건이 동시에 충족되면 노드가 트랜잭션을 제출할 수 있는지 여부를 결정합니다. 작업이 충돌하고 확인이 실패합니다. 🎜🎜1. 두 개의 트랜잭션이 서로 다른 노드에서 발생합니다. 🎜🎜2. 두 트랜잭션에 동일한 기본 키가 포함되어 있습니다. 🎜🎜3. 즉, 이전 거래가 제출되지 않았습니다. 신규 트랜잭션과 기존 트랜잭션의 구분은 글로벌 트랜잭션 전체 순서, 즉 GTID에 따라 달라집니다. 🎜🎜각 노드는 독립적으로 검증을 수행하며, 검증에 실패하면 노드는 쓰기 세트를 삭제하고 원래 트랜잭션을 롤백하며 모든 노드는 동일한 작업을 수행합니다. 모든 노드는 동일한 순서로 트랜잭션을 수신하므로 모두 성공하거나 모두 실패하는 동일한 결과 결정을 내립니다. 성공하면 자연스럽게 제출되고 모든 노드는 다시 일관된 데이터 상태에 도달합니다. 노드 간에 "충돌"에 대한 정보가 교환되지 않으며, 각 노드는 독립적이고 비동기적으로 트랜잭션을 처리합니다. 🎜MySQL 클러스터
🎜MySQL 클러스터는 확장성이 뛰어난 ACID 트랜잭션 호환 실시간 데이터베이스입니다. MySQL 클러스터는 자동 수평 확장을 지원하며 자동 읽기 및 쓰기 로드 밸런싱을 수행할 수 있습니다. 🎜🎜<code>MySQL 클러스터는 NDB라는 인메모리 스토리지 엔진을 사용하여 여러 MySQL 인스턴스를 통합하고 통합 서비스 클러스터를 제공합니다. 🎜🎜NDB는 Sharding-Nothing 아키텍처를 사용하는 메모리 저장 엔진입니다. Sarding-Nothing은 각 노드가 독립적인 프로세서, 디스크 및 메모리를 가지며 노드 간에 공유 리소스가 없으며 완전히 독립적이며 서로 간섭하지 않는다는 것을 의미합니다. 각 노드는 다음과 같습니다. 작은 데이터베이스. 일부 데이터를 저장합니다. 이 아키텍처의 장점은 노드의 분산을 활용하여 데이터를 병렬로 처리하고 전반적인 성능을 향상시킬 수 있다는 것입니다. 또한 노드를 추가하는 것만으로도 데이터 처리 능력이 향상됩니다. 🎜🎜🎜 🎜 MySql 클러스터에는 관리 노드(NDB 관리 서버), 데이터 노드(데이터 노드) 및 SQL 쿼리 노드(SQL 노드)라는 세 가지 유형의 노드가 포함되어 있습니다. 🎜🎜SQL 노드는 일반적인 mysqld 서비스와 마찬가지로 사용자의 SQL 입력을 받아 실행하고 결과를 반환하는 응용 프로그램의 인터페이스입니다. 데이터 노드는 데이터 저장 노드이며 NDB 관리 서버는 클러스터의 각 노드를 관리하는 데 사용됩니다. 🎜데이터 노드는 데이터 파티션과 파티션 복사본을 클러스터에 저장합니다. MySql Cluster가 데이터에 대해 샤딩 작업을 수행하는 방법을 살펴보겠습니다. 먼저 다음 개념을 이해해 보겠습니다.MySql Cluster 是如何对数据进行分片的操作的,首先来了解下下面几个概念
节点组(Node Group): 一组数据节点的集合。节点组的个数=节点数 / 副本数;
比如有集群中 4 个节点,副本数为 2(对应 NoOfReplicas 的设置),那么节点组个数为2。
另外,在可用性方面,数据的副本在组内交叉分配,一个节点组内只有要一台机器可用,就可以保证整个集群的数据完整性,实现服务的整体可用。
分区(Partition):MySql Cluster 是一个分布式的存储系统,数据按照 分区 划分成多份存储在各数据节点中,分区个数由系统自动计算,分区数 = 数据节点数 / LDM 线程数;
副本(Replica):分区数据的备份,有几个分区就有几个副本,为了避免单点,保证 MySql Cluster 集群的高可用,原始数据对应的分区和副本通常会保存在不同的主机上,在一个节点组内进行交叉备份。
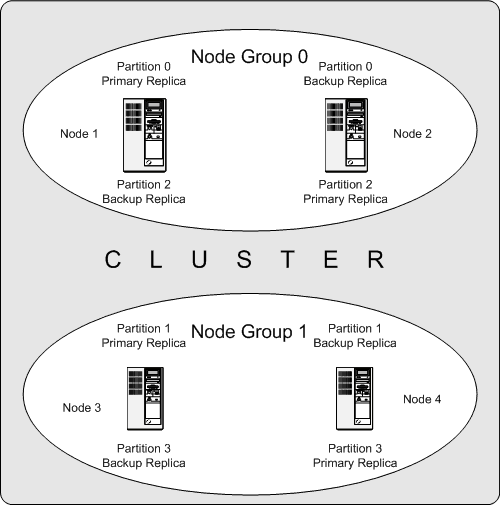
栗如,上面的例子,有四个数据节点(使用ndbd),副本数为2的集群,节点组被分为2组(4/2),数据被分为4个分区,数据分配情况如下:
分区0(Partition 0)保存在节点组 0(Node Group 0)中,分区数据(主副本 — Primary Replica)保存在节点1(node 1) 中,备份数据(备份副本,Backup Replica)保存在节点2(node 2) 中;
分区1(Partition 1)保存在节点组 1(Node Group 1)中,分区数据(主副本 — Primary Replica)保存在节点3(node 3) 中,备份数据(备份副本,Backup Replica)保存在节点4(node 4) 中;
分区2(Partition 2)保存在节点组 0(Node Group 0)中,分区数据(主副本 — Primary Replica)保存在节点2(node 2) 中,备份数据(备份副本,Backup Replica)保存在节点1(node 1) 中;
分区3(Partition 2)保存在节点组 1(Node Group 1)中,分区数据(主副本 — Primary Replica)保存在节点4(node 4) 中,备份数据(备份副本,Backup Replica)保存在节点3(node 3) 中;
这样,对于一张表的一个 Partition 来说,在整个集群有两份数据,并分布在两个独立的 Node 上,实现了数据容灾。同时,每次对一个 Partition 的写操作,都会在两个 Replica 上呈现,如果 Primary Replica 异常,那么 Backup Replica 可以立即提供服务,实现数据的高可用。
mysql cluster 的优点
1、99.999%的高可用性;
2、快速的自动失效切换;
3、灵活的分布式体系结构,没有单点故障;
4、高吞吐量和低延迟;
5、可扩展性强,支持在线扩容。
mysql cluster 的缺点
1、存在很多限制,比如:不支持外键,数据行不能超过8K(不包括BLOB和text中的数据);
2、部署、管理、配置很复杂;
3、占用磁盘空间大,内存大;
4、备份和恢复不方便;
5、重启的时候,数据节点将数据 load 到内存需要很长时间。
MySQL Fabric
MySQL Fabric 会组织多个 MySQL 数据库,将大的数据分散到多个数据库中,即数据分片(Data Shard),同时同一个分片数据库中又是一个主从结构,Fabric 会挑选合适的库作为主库,当主库挂掉的时候,又会重新在从库中选出一个主库。
MySQL Fabric 的特点:
1、高可用;
2、使用数据分片的横向功能。
MySQL Fabric-aware 连接器把从 MySQL Fabric 获取的路由信息存储到缓存中,然后凭借该信息将事务或查询发送给正确的 MySQL 服务器。
同时,每一个分片组,可以又多个一个服务器组成,构成主从结构,当主库挂掉的时候,又会重新在从库中选出一个主库。保证节点的高可用。
HA Group 保证访问指定 HA Group 的数据总是可用的,同时其基础的数据复制是基于 MySQL Replication
노드 수 / 복제본 수; 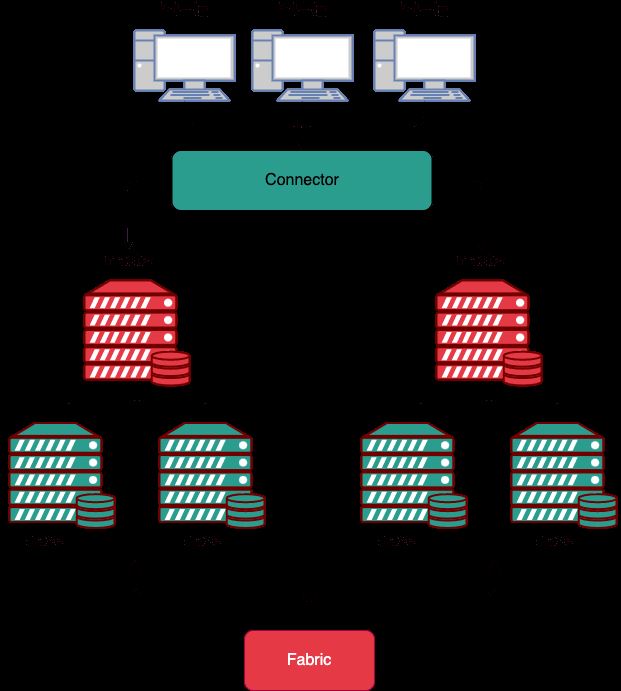 예를 들어 클러스터에 노드가 4개 있고 복제본 수가 2(NoOfReplicas 설정에 해당)인 경우 노드 그룹 수는 2입니다.
예를 들어 클러스터에 노드가 4개 있고 복제본 수가 2(NoOfReplicas 설정에 해당)인 경우 노드 그룹 수는 2입니다.
또한 가용성 측면에서 데이터 복사본은 그룹 내에서 교차 배포됩니다. 전체 클러스터의 데이터 무결성을 보장하고 전반적인 서비스 가용성을 달성하기 위해 노드 그룹에서 하나의 머신만 사용할 수 있습니다.
파티션: MySql 클러스터는 데이터를 파티션에 따라 여러 부분으로 나누어 각 데이터 노드에 저장합니다. 파티션 수는 시스템에서 자동으로 계산됩니다. Number = 데이터 노드 수 / LDM 스레드 수
MySql Cluster 클러스터의 고가용성을 위해 원본 데이터에 해당하는 파티션과 복사본은 일반적으로 다른 호스트에 저장되고 노드 그룹 내에서 교차 백업됩니다. 🎜🎜<img src="/static/imghwm/default1.png" data-src="https://img.php.cn/upload/article/000/465/014/168576156320389.png" class="lazy" alt="MySQL의 일반적인 고가용성 아키텍처 배포 솔루션은 무엇입니까">🎜 🎜 Li Ru, 위의 예에는 4개의 데이터 노드(ndbd 사용), 2개의 복제본이 있는 클러스터, 노드 그룹이 2개의 그룹(4/2)으로 나뉘고 데이터가 4개의 파티션으로 나뉘며 데이터는 배포는 다음과 같습니다. 🎜🎜파티션 0(파티션 0)은 노드 그룹 0(노드 그룹 0)에 저장되고, 파티션 데이터(Primary Replica)는 노드 1(노드 1)에 저장되며, 백업 데이터(Backup Replica) 노드 2(노드 2)에 저장됩니다. 파티션 1(파티션 1)은 노드 그룹 1(노드 그룹 1)에 저장되고, 파티션 데이터(기본 복사본— 기본 복제본)는 노드 3(노드 )에 저장됩니다. 3) 백업 데이터(백업 복제본)는 노드 4(노드 4)에 저장됩니다. 🎜🎜파티션 2(파티션 2)는 노드 그룹 0(노드 그룹 0)에 저장되고, 파티션 데이터(기본 복제본 - 기본 복제본)은 노드 2(노드 2)에 저장되고 백업 데이터(백업 복제본, 백업 복제본)는 노드 1(노드 1)에 저장됩니다. 🎜🎜파티션 3(파티션 2)은 노드에 저장됩니다. 그룹 1(Node Group 1), 파티션 데이터(주 복제본 - Primary Replica)는 노드 4(노드 4)에 저장되고, 백업 데이터(Backup Replica)는 노드 3(노드 3)에 저장됩니다. ); 🎜🎜이런 방식으로 테이블 파티션의 경우 전체 클러스터에 두 개의 데이터 복사본이 있으며 두 개의 독립 노드에 분산되어 데이터 재해 복구가 이루어집니다. 동시에 파티션에 대한 모든 쓰기 작업은 두 개의 복제본에 표시됩니다. <code>기본 복제본이 비정상적인 경우 백업 복제본은 즉시 서비스를 제공하여 높은 데이터 효율성을 달성할 수 있습니다. . 사용 가능. 🎜🎜mysql 클러스터 장점🎜🎜1. 99.999% 고가용성, 🎜🎜2. 빠른 자동 장애 조치, 🎜🎜4. 낮은 대기 시간 🎜🎜5. 강력한 확장성, 온라인 확장 지원. 🎜🎜mysql 클러스터 단점🎜🎜1. 다음과 같은 많은 제한 사항이 있습니다. 외래 키가 지원되지 않으며 데이터 행이 8K를 초과할 수 없습니다(BLOB 및 텍스트의 데이터 제외). 배포, 관리 및 구성이 매우 복잡합니다. 🎜🎜4. 백업 및 복구가 불편합니다. 🎜🎜5. 데이터를 메모리에 로드합니다. 🎜MySQL Fabric
🎜MySQL Fabric은 여러 개의 MySQL 데이터베이스를 정리하고 대용량 데이터를 여러 데이터베이스에 분산시키는 것, 즉 데이터 샤딩(Data Shard), 동시에 동일한 샤드 데이터베이스에 마스터-슬레이브 구조가 있습니다. Fabric은 적절한 라이브러리를 마스터 라이브러리로 선택합니다. 마스터 라이브러리가 실패하면 슬레이브 라이브러리에서 마스터 라이브러리를 다시 선택합니다. 🎜🎜MySQL Fabric 기능: 🎜🎜1. 고가용성 🎜🎜2. 데이터 샤딩을 사용한 수평 기능. 🎜🎜 MySQL Fabric 인식 커넥터는 MySQL Fabric에서 얻은 라우팅 정보를 캐시에 저장한 다음 이 정보를 사용하여 올바른 MySQL 서버에 트랜잭션이나 쿼리를 보냅니다. 🎜🎜동시에 각 샤딩 그룹은 여러 서버로 구성되어 마스터-슬레이브 구조를 형성할 수 있습니다. 마스터 데이터베이스가 중단되면 슬레이브 데이터베이스에서 다시 마스터 데이터베이스가 선택됩니다. 노드 고가용성을 보장합니다. 🎜🎜HA 그룹은 지정된 HA 그룹의 데이터에 대한 액세스가 항상 가능하도록 보장하며 기본 데이터 복제는 MySQL 복제를 기반으로 합니다. . 🎜🎜🎜🎜🎜단점🎜🎜트랜잭션과 쿼리는 동일한 샤드 내에서만 지원됩니다. 트랜잭션에서 업데이트된 데이터는 샤드를 교차할 수 없으며, 쿼리 문에서 반환된 데이터도 샤드를 교차할 수 없습니다. 🎜위 내용은 MySQL의 일반적인 고가용성 아키텍처 배포 솔루션은 무엇입니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!