
집 >데이터 베이스 >MySQL 튜토리얼 >MySQL이 인덱스 구축 및 인덱스 실패에 적합하지 않은 상황은 무엇입니까?
MySQL이 인덱스 구축 및 인덱스 실패에 적합하지 않은 상황은 무엇입니까?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-06-02 13:28:121915검색
결론
구체적인 사례는 아래에 자세히 설명되어 있습니다.
인덱싱에 적합하지 않은 시나리오:
데이터 용량이 작은 테이블에는 인덱스를 생성하지 않는 것이 좋습니다.
인덱싱에 적합하지 않은 테이블에는 인덱스를 생성하지 않는 것이 좋습니다. 중복 데이터가 많은 필드(: Gender 필드와 유사)
자주 업데이트해야 하는 테이블에는 인덱스를 생성하지 않는 것이 좋습니다
where, group by, order by 이후의 사용되지 않는 필드 색인이 생성되지 않음
중복 색인을 정의하지 마세요
색인 실패 시나리오:
필터 조건이 사용하는 필터 조건은 (!=, )와 같지 않습니다.
필터 조건은 다음과 같습니다. not null
인덱스 필드에 함수나 계산을 사용하세요
공동 인덱스를 사용하는 경우 "최적 왼쪽 접두사 규칙"을 충족해야 합니다. 그렇지 않으면
유형 변환이 유효하지 않습니다.
범위 쿼리를 사용하는 경우 공동 인덱스 부분 필드 무효화(여기서 age >18)
like 필드에서 %로 시작하면 인덱스가 유효하지 않습니다. (여기서 ‘%abc’와 같은 이름)
or를 사용하여 쿼리할 때 앞뒤 또는 비색인 필드가 나타나고, 테이블과 라이브러리의 문자 집합이 일치하지 않게 됩니다. 지식 포인트:
각 테이블에 6개 이상의 인덱스를 사용하는 것은 권장되지 않습니다(공간을 차지하고 테이블 크기가 줄어듭니다)
결국 그렇습니다. 인덱스를 사용할지 옵티마이저를 사용할지 결정
옵티마이저는 데이터 볼륨, 데이터베이스 버전, 데이터 선택 읽기를 기준으로 쿼리 비용을 비교한 후 인덱스를 사용할지 결정합니다
인덱스 생성 시 , 실패를 방지하기 위해 인덱스 끝 부분에 범위 일치가 필요한 필드를 설정합니다. 테이블을 생성할 때 필드를 null이 아닌 값으로 설정하고 xxx에서 값이 없는 레코드를 찾아야 할 때 사용할 수 있습니다. = 기본값, null이 아닌 값을 사용하면 인덱스 오류가 발생합니다
페이지에서 검색할 때 왼쪽 또는 전체 텍스트 퍼지 일치(예: '%abc')를 사용하세요.
더 나은 필터링 필드를 위해 더 많은 데이터를 먼저 필터링할 수 있도록 공동 인덱스
인덱스 시나리오를 생성하는 것은 권장되지 않습니다.
시나리오 1: 데이터가 적은 테이블 데이터가 상대적으로 작을 때는 인덱스의 이점이 분명하지 않습니다. , 데이터베이스의 스토리지 엔진도 매우 빠르기 때문에 테이블 반환 작업을 수행하기 전에 인덱스를 쿼리해야 하는 것과 비교하면 직접 쿼리의 성능이 더 높을 수 있으므로 상대적으로 작은 테이블에 대해서는 인덱스를 생성하지 않는 것이 좋습니다. data
시나리오 2: 예 대량의 반복 데이터가 있는 필드는 성별 필드와 유사합니다. "남성"과 "여성"이라는 두 가지 값만 있으므로 인덱스의 데이터 중 절반은 "입니다. "male"이고 데이터의 절반이 "female"입니다. 그러면 빠른 인덱싱이 불가능합니다. 쿼리 등이 있으므로 중복 데이터가 많은 열에 인덱스를 구축하는 것은 권장되지 않습니다시나리오 3: 자주 업데이트되는 테이블( 업데이트/삭제/삽입)
테이블의 데이터가 업데이트되면 이에 따라 인덱스도 유지 관리되어야 하기 때문입니다. 예, 가까운 시일 내에 테이블을 자주 추가, 삭제, 수정해야 한다면 시간이 걸릴 것입니다. 인덱스를 유지하는 데 시간이 많이 걸립니다. 자주 업데이트 작업이 필요한 경우 인덱스를 삭제하고 업데이트가 완료된 후 인덱스를 다시 작성하는 것은 권장되지 않습니다.
시나리오 4: 사용되지 않는 필드(여기서/그룹화 기준) /order by)
where/group by/order by가 아닌 필드에 대해서는 인덱스가 사용되지 않으므로 인덱스를 생성할 필요가 없습니다.
시나리오 5: 중복된 나머지 인덱스를 정의하지 마세요
create index username_password_address on xiao(username,password,address); -- 如果建立了第一个索引,那么就没有必要建立第二个索引 create index username on xiao (username); --第二个索引就是冗余索引,因为第一个已经是先根据username排序的索引 --也就是第二个索引的功能完全可以由第一个索引实现
여기서, 사용자 이름은 첫 번째 공동 인덱스의 첫 번째 필드이기 때문에 사용자 이름을 기준으로 인덱스가 정렬되므로 사용자 이름이 동일할 경우 비밀번호와 주소를 기준으로 정렬되므로 사용자 이름 열만 의 기능으로 사용되는 것을 알 수 있습니다. 즉, 두 번째 인덱스가 중복됨
인덱스 오류 시나리오
시나리오 1: 인덱스된 필드에 대해 작업(함수 등)을 수행하여 인덱스 오류가 발생함
여기서 먼저 age에 대한 인덱스가 생성됩니다. 첫 번째 쿼리에서는 나이 인덱스를 사용했는데, 두 번째 키 값이 null(인덱스 실패)이 나온 이유는 두 번째 쿼리에서 나이를 어디에서 계산했는지, 컴퓨터가 이를 알지 못했기 때문입니다. 가 수행되므로 age+1이 계산되어 1과 비교되고 인덱스가 무효화됩니다. 필드 등에 concat() 함수를 사용하는 것과 유사하게 시나리오 2를 사용하면 인덱스가 무효화됩니다. 같지 않음 (where age != 18)
동등한 연산을 사용하면 인덱스에서 검색할 수 있지만 같지 않으면 모든 데이터를 순회해야 하므로 유효하지 않습니다
explain select * from xiaoyuanhao where age = 18; explain select * from xiaoyuanhao where age != 18; --这里是在age字段上建立了普通索引,第二个查询时候索引失效
시나리오 3: 사용 is not null 인덱스는 유효하지 않습니다
is not null과 동일합니다. is not null을 사용하면 모든 데이터를 순회해야 하며 인덱스는 유효하지 않게 됩니다. 그러나 is null을 사용하면 인덱스를 계속 사용할 수 있습니다.
시나리오 4: 사용 시 조인트 인덱싱 중에 최적의 왼쪽 접두사 규칙을 따르지 않습니다CREATE INDEX age_classid_name ON student(age,classId,NAME); EXPLAIN SELECT * FROM student WHERE classId = 30 AND NAME = 'xiaoyuanhao'; -- 因为没有使用age字段,所以没有准许最佳左前缀原则,索引失效
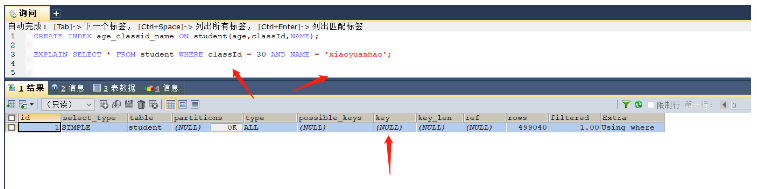
从这里可以看出是没有使用索引的(key = null),因为创建的索引是先按照age进行排序,在age相同的情况下按照classId和name排序,如果在查询的时候需要直接按照classId进行排序查找,那么就无法使用该索引,即索引失效。
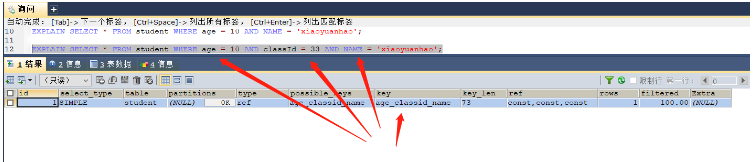
如果需要使用使用索引,那么就一定需要到联合索引的第一个字段age,案例如下
EXPLAIN SELECT * FROM student WHERE age = 10 AND NAME = 'xiaoyuanhao'; EXPLAIN SELECT * FROM student WHERE age = 10 AND classId = 33 AND NAME = 'xiaoyuanhao'; --两者都是使用age字段索引,所以索引有效

场景五:类型转换导致索引失效
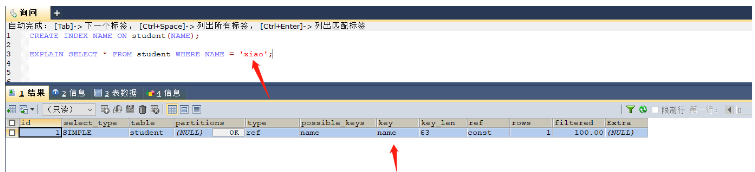
CREATE INDEX NAME ON student(NAME); -- 这里的name字段是varchar类型 EXPLAIN SELECT * FROM student WHERE NAME = 'xiao'; -- 本次查询是可以使用索引的,因为类型都是一致的,都是字符串 EXPLAIN SELECT * FROM student WHERE NAME = 123; -- 本次查询则无法使用索引,因为是将数字类型123转换为字符类型
没有发生类型转换,使用索引key = name
发生了类型转换,无法使用索引kye = null,索引失效
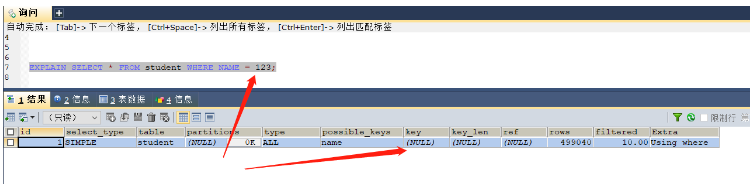
使用索引的时候一定需要保证数据类型是一致的,否则系统就需要进行转换,那么就无法使用索引
场景六:使用范围查询导致联合索引其他字段失效
create index age_classId_name on student (age,classId,name); EXPLAIN SELECT * FROM student WHERE age = 10 AND classId > 20 AND NAME = 'xiaoyuanhao'; -- 这里只能使用age,classId,索引的前两个字段 EXPLAIN SELECT * FROM student WHERE age = 10 AND classId = 20 AND NAME = 'xiaoyuanhao'; -- 这里可以使用完整的索引,因为都是等值连接
在classId字段上使用范围查询,导致name字段失效,有效索引长度为63

使用的都是等值匹配,整个索引皆可用,有效索引长度为73

也就是在对于联合索引来说,如果在使用的时候是等值匹配,那么就可以重复的利用索引,如果不是等值匹配,那么该字段也是可以使用索引的,但是该字段右边的字段就将失效
建议在建立索引的时候将需要范围匹配的字段建立在索引的最后面
场景七:在使用like的时候,如果以%开头导致索引失效
EXPLAIN SELECT * FROM student WHERE NAME LIKE 'abc%'; -- 可以正常使用索引 EXPLAIN SELECT * FROM student WHERE NAME LIKE '%abc'; -- 这里在like中,%在前面无法使用索引
key = name,使用了该索引,索引有效
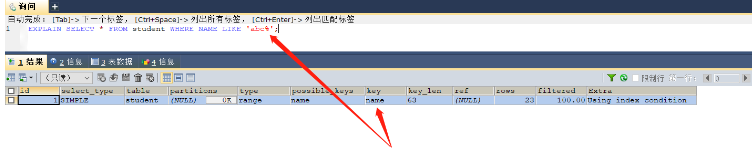
key = null,索引失效

因为建立的索引实际上是按照整个字符串的从第一个开始进行比较排序的,所以在使用like的时候,也只能够重现进行比较,如果使用的是’%abc’,那么查询的就是以abc结尾的数据,无法使用索引
场景八:or前后出现非索引字段,索引失效
-- 该表中只有name字段上的索引 CREATE INDEX NAME ON student(NAME); EXPLAIN SELECT * FROM student WHERE NAME = 'xiao'; -- 这里是可以使用name索引的 EXPLAIN SELECT * FROM student WHERE NAME = 'xiao' OR classId = 1001; -- 这个则无法使用索引,进行的是全表扫描
key = null,无法使用索引,or条件中出现非索引字段
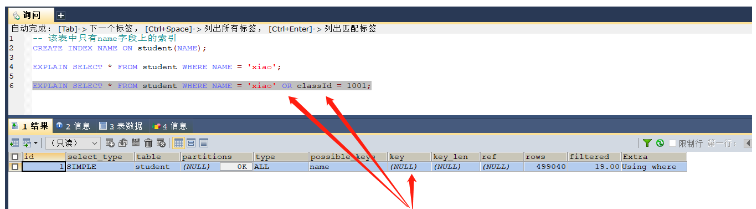
因为如果name不等于’xiao’的时候那么就会继续判断classId是否等于1001,那么实际上还是会进行全表扫描,所以索引失效(也就是进行name判断的时候可以使用索引,但是在判断classId的时候又要全表扫描,那么优化器就直接进行全表扫描),但是如果or前后的字段都有索引了,那么就就会使用索引
위 내용은 MySQL이 인덱스 구축 및 인덱스 실패에 적합하지 않은 상황은 무엇입니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!