
컴퓨팅 성능 제한을 우회하기 위해 단일 GPU로 LLM을 미세 조정하는 방법은 무엇입니까? 이것은 'Gradient Accumulation' 알고리즘에 대한 튜토리얼입니다.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-05-22 20:25:041102검색
대형 모델이 뜨거운 트렌드가 되면서 GPU는 귀한 상품이 되었습니다. 개별 개발자는 물론이고 많은 회사의 보유 자금도 충분하지 않을 수 있습니다. 컴퓨팅 성능을 사용하여 모델을 보다 효율적으로 훈련할 수 있는 방법이 있습니까?
최근 블로그에서 Sebastian Raschka는 GPU 메모리가 제한되어 있을 때 하드웨어 제한을 우회하여 더 큰 배치 크기를 사용하여 모델을 훈련할 수 있는 "그라디언트 누적" 방법을 소개했습니다.

이전에 Sebastian Raschka는 다중 GPU 훈련 전략을 사용하여 모델 가중치를 분배하는 모델 또는 텐서 샤딩과 같은 메커니즘을 포함하여 대규모 언어 모델의 미세 조정을 가속화하는 기사도 공유했습니다. GPU 메모리 제한을 해결하기 위해 다양한 장치에서 계산합니다.
분류를 위한 BLOOM 모델 미세 조정
텍스트 분류와 같은 다운스트림 작업을 처리하기 위해 최근 사전 훈련된 대규모 언어 모델을 채택하는 데 관심이 있다고 가정해 보겠습니다. 그런 다음 GPT-3의 오픈 소스 대체 BLOOM 모델, 특히 "단지" 5억 6천만 개의 매개변수가 있는 BLOOM 버전을 사용하도록 선택할 수 있습니다. 이는 문제 없이 기존 GPU의 RAM에 맞아야 합니다(Google Colab 무료 버전에는 15GB RAM).
일단 시작하면 문제에 봉착할 가능성이 높습니다. 훈련이나 미세 조정 중에 기억력이 급격히 증가합니다. 이 모델을 훈련하는 유일한 방법은 배치 크기 1을 사용하는 것입니다.

배치 크기 1(배치 크기=1)을 사용하여 대상 분류 작업을 위해 BLOOM을 미세 조정하는 코드는 다음과 같습니다. GitHub 프로젝트 페이지(
https://github.com/rasbt/gradient-accumulation-blog/blob/main/src/1_batchsize-1.py
)에서 전체 코드를 다운로드할 수도 있습니다. 이것을 사용하십시오. 코드는 Google Colab에 직접 복사하여 붙여넣지만, 함께 제공되는 local_dataset_utilities.py 파일도 일부 데이터세트 유틸리티를 가져온 동일한 폴더에 끌어서 놓아야 합니다.
<code># pip install torch lightning matplotlib pandas torchmetrics watermark transformers datasets -Uimport osimport os.path as opimport timefrom datasets import load_datasetfrom lightning import Fabricimport torchfrom torch.utils.data import DataLoaderimport torchmetricsfrom transformers import AutoTokenizerfrom transformers import AutoModelForSequenceClassificationfrom watermark import watermarkfrom local_dataset_utilities import download_dataset, load_dataset_into_to_dataframe, partition_datasetfrom local_dataset_utilities import IMDBDatasetdef tokenize_text (batch):return tokenizer (batch ["text"], truncatinotallow=True, padding=True, max_length=1024)def train (num_epochs, model, optimizer, train_loader, val_loader, fabric):for epoch in range (num_epochs):train_acc = torchmetrics.Accuracy (task="multiclass", num_classes=2).to (fabric.device)for batch_idx, batch in enumerate (train_loader):model.train ()### FORWARD AND BACK PROPoutputs = model (batch ["input_ids"],attention_mask=batch ["attention_mask"],labels=batch ["label"]) fabric.backward (outputs ["loss"])### UPDATE MODEL PARAMETERSoptimizer.step ()optimizer.zero_grad ()### LOGGINGif not batch_idx % 300:print (f"Epoch: {epoch+1:04d}/{num_epochs:04d}"f"| Batch {batch_idx:04d}/{len (train_loader):04d}"f"| Loss: {outputs ['loss']:.4f}")model.eval ()with torch.no_grad ():predicted_labels = torch.argmax (outputs ["logits"], 1)train_acc.update (predicted_labels, batch ["label"])### MORE LOGGINGmodel.eval ()with torch.no_grad ():val_acc = torchmetrics.Accuracy (task="multiclass", num_classes=2).to (fabric.device)for batch in val_loader:outputs = model (batch ["input_ids"],attention_mask=batch ["attention_mask"],labels=batch ["label"])predicted_labels = torch.argmax (outputs ["logits"], 1)val_acc.update (predicted_labels, batch ["label"])print (f"Epoch: {epoch+1:04d}/{num_epochs:04d}"f"| Train acc.: {train_acc.compute ()*100:.2f}%"f"| Val acc.: {val_acc.compute ()*100:.2f}%")train_acc.reset (), val_acc.reset ()if __name__ == "__main__":print (watermark (packages="torch,lightning,transformers", pythnotallow=True))print ("Torch CUDA available?", torch.cuda.is_available ())device = "cuda" if torch.cuda.is_available () else "cpu"torch.manual_seed (123)# torch.use_deterministic_algorithms (True)############################# 1 Loading the Dataset##########################download_dataset ()df = load_dataset_into_to_dataframe ()if not (op.exists ("train.csv") and op.exists ("val.csv") and op.exists ("test.csv")):partition_dataset (df)imdb_dataset = load_dataset ("csv",data_files={"train": "train.csv","validation": "val.csv","test": "test.csv",},)############################################ 2 Tokenization and Numericalization#########################################tokenizer = AutoTokenizer.from_pretrained ("bigscience/bloom-560m", max_length=1024)print ("Tokenizer input max length:", tokenizer.model_max_length, flush=True)print ("Tokenizer vocabulary size:", tokenizer.vocab_size, flush=True)print ("Tokenizing ...", flush=True)imdb_tokenized = imdb_dataset.map (tokenize_text, batched=True, batch_size=None)del imdb_datasetimdb_tokenized.set_format ("torch", columns=["input_ids", "attention_mask", "label"])os.environ ["TOKENIZERS_PARALLELISM"] = "false"############################################ 3 Set Up DataLoaders#########################################train_dataset = IMDBDataset (imdb_tokenized, partition_key="train")val_dataset = IMDBDataset (imdb_tokenized, partition_key="validation")test_dataset = IMDBDataset (imdb_tokenized, partition_key="test")train_loader = DataLoader (dataset=train_dataset,batch_size=1,shuffle=True,num_workers=4,drop_last=True,)val_loader = DataLoader (dataset=val_dataset,batch_size=1,num_workers=4,drop_last=True,)test_loader = DataLoader (dataset=test_dataset,batch_size=1,num_workers=2,drop_last=True,)############################################ 4 Initializing the Model#########################################fabric = Fabric (accelerator="cuda", devices=1, precisinotallow="16-mixed")fabric.launch ()model = AutoModelForSequenceClassification.from_pretrained ("bigscience/bloom-560m", num_labels=2)optimizer = torch.optim.Adam (model.parameters (), lr=5e-5)model, optimizer = fabric.setup (model, optimizer)train_loader, val_loader, test_loader = fabric.setup_dataloaders (train_loader, val_loader, test_loader)############################################ 5 Finetuning#########################################start = time.time ()train (num_epochs=1,model=model,optimizer=optimizer,train_loader=train_loader,val_loader=val_loader,fabric=fabric,)end = time.time ()elapsed = end-startprint (f"Time elapsed {elapsed/60:.2f} min")with torch.no_grad ():model.eval ()test_acc = torchmetrics.Accuracy (task="multiclass", num_classes=2).to (fabric.device)for batch in test_loader:outputs = model (batch ["input_ids"],attention_mask=batch ["attention_mask"],labels=batch ["label"])predicted_labels = torch.argmax (outputs ["logits"], 1)test_acc.update (predicted_labels, batch ["label"])print (f"Test accuracy {test_acc.compute ()*100:.2f}%")</code>
저자는 개발자가 이 코드를 다른 하드웨어에서 실행할 때 GPU 수와 다중 GPU 훈련 전략을 유연하게 변경할 수 있기 때문에 Lightning Fabric을 사용했습니다. 또한 간단히 정밀도 플래그를 조정하여 혼합 정밀도 훈련을 활성화할 수도 있습니다. 이 경우 혼합 정밀도 훈련을 통해 훈련 속도를 3배 높이고 메모리 요구 사항을 약 25% 줄일 수 있습니다.
위에 표시된 메인 코드는 main 함수에서 실행됩니다(if __name__ == "__main__" context). 단일 GPU만 사용하더라도 다중 GPU 훈련을 수행하려면 PyTorch 실행 환경을 사용하는 것이 좋습니다. . 그런 다음 if __name__ == "__main__"에 포함된 다음 세 가지 코드 부분이 데이터 로드를 담당합니다.
# 1 데이터 세트 로드
# 2 토큰화 및 수치화
# 3 data Loader
섹션 4는 모델 초기화이고, 섹션 5 미세 조정에서는 열차 함수가 호출되기 시작합니다. train (...) 함수에서는 표준 PyTorch 루프가 구현됩니다. 핵심 훈련 루프의 주석이 달린 버전은 다음과 같습니다:
배치 크기 1(배치 크기=1)의 문제는 다음을 기반으로 모델을 훈련할 때 아래와 같이 그라데이션 업데이트가 매우 혼란스럽고 어려워진다는 것입니다. 변동 훈련 손실 및 열악한 테스트 세트 성능에서 볼 수 있는 것:
<code>...torch : 2.0.0lightning : 2.0.0transformers: 4.27.2Torch CUDA available? True...Epoch: 0001/0001 | Batch 23700/35000 | Loss: 0.0969Epoch: 0001/0001 | Batch 24000/35000 | Loss: 1.9902Epoch: 0001/0001 | Batch 24300/35000 | Loss: 0.0395Epoch: 0001/0001 | Batch 24600/35000 | Loss: 0.2546Epoch: 0001/0001 | Batch 24900/35000 | Loss: 0.1128Epoch: 0001/0001 | Batch 25200/35000 | Loss: 0.2661Epoch: 0001/0001 | Batch 25500/35000 | Loss: 0.0044Epoch: 0001/0001 | Batch 25800/35000 | Loss: 0.0067Epoch: 0001/0001 | Batch 26100/35000 | Loss: 0.0468Epoch: 0001/0001 | Batch 26400/35000 | Loss: 1.7139Epoch: 0001/0001 | Batch 26700/35000 | Loss: 0.9570Epoch: 0001/0001 | Batch 27000/35000 | Loss: 0.1857Epoch: 0001/0001 | Batch 27300/35000 | Loss: 0.0090Epoch: 0001/0001 | Batch 27600/35000 | Loss: 0.9790Epoch: 0001/0001 | Batch 27900/35000 | Loss: 0.0503Epoch: 0001/0001 | Batch 28200/35000 | Loss: 0.2625Epoch: 0001/0001 | Batch 28500/35000 | Loss: 0.1010Epoch: 0001/0001 | Batch 28800/35000 | Loss: 0.0035Epoch: 0001/0001 | Batch 29100/35000 | Loss: 0.0009Epoch: 0001/0001 | Batch 29400/35000 | Loss: 0.0234Epoch: 0001/0001 | Batch 29700/35000 | Loss: 0.8394Epoch: 0001/0001 | Batch 30000/35000 | Loss: 0.9497Epoch: 0001/0001 | Batch 30300/35000 | Loss: 0.1437Epoch: 0001/0001 | Batch 30600/35000 | Loss: 0.1317Epoch: 0001/0001 | Batch 30900/35000 | Loss: 0.0112Epoch: 0001/0001 | Batch 31200/35000 | Loss: 0.0073Epoch: 0001/0001 | Batch 31500/35000 | Loss: 0.7393Epoch: 0001/0001 | Batch 31800/35000 | Loss: 0.0512Epoch: 0001/0001 | Batch 32100/35000 | Loss: 0.1337Epoch: 0001/0001 | Batch 32400/35000 | Loss: 1.1875Epoch: 0001/0001 | Batch 32700/35000 | Loss: 0.2727Epoch: 0001/0001 | Batch 33000/35000 | Loss: 0.1545Epoch: 0001/0001 | Batch 33300/35000 | Loss: 0.0022Epoch: 0001/0001 | Batch 33600/35000 | Loss: 0.2681Epoch: 0001/0001 | Batch 33900/35000 | Loss: 0.2467Epoch: 0001/0001 | Batch 34200/35000 | Loss: 0.0620Epoch: 0001/0001 | Batch 34500/35000 | Loss: 2.5039Epoch: 0001/0001 | Batch 34800/35000 | Loss: 0.0131Epoch: 0001/0001 | Train acc.: 75.11% | Val acc.: 78.62%Time elapsed 69.97 minTest accuracy 78.53%</code>
텐서 샤딩에 사용할 수 있는 GPU가 많지 않기 때문에 배치 크기가 더 큰 모델을 훈련하려면 어떻게 해야 합니까?
한 가지 솔루션은 앞서 언급한 훈련 루프를 수정하는 데 사용할 수 있는 그래디언트 누적입니다.
什么是梯度积累?
梯度累积是一种在训练期间虚拟增加批大小(batch size)的方法,当可用的 GPU 内存不足以容纳所需的批大小时,这非常有用。在梯度累积中,梯度是针对较小的批次计算的,并在多次迭代中累积(通常是求和或平均),而不是在每一批次之后更新模型权重。一旦累积梯度达到目标「虚拟」批大小,模型权重就会使用累积梯度进行更新。
参考下面更新的 PyTorch 训练循环:
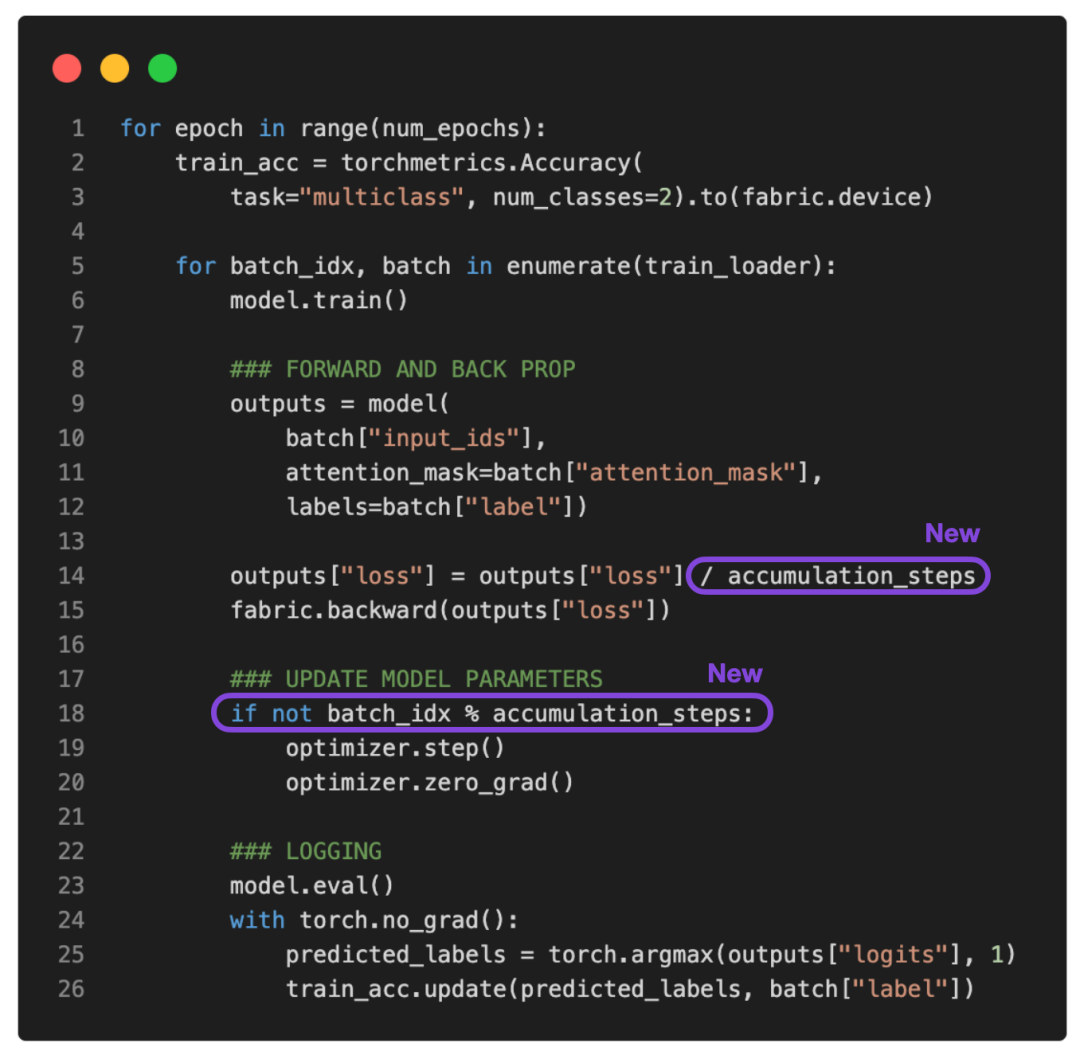
如果将 accumulation_steps 设置为 2,那么 zero_grad () 和 optimizer.step () 将只会每隔一秒调用一次。因此,使用 accumulation_steps=2 运行修改后的训练循环与将批大小(batch size)加倍具有相同的效果。
例如,如果想使用 256 的批大小,但只能将 64 的批大小放入 GPU 内存中,就可以对大小为 64 的四个批执行梯度累积。(处理完所有四个批次后,将获得相当于单个批大小为 256 的累积梯度。)这样能够有效地模拟更大的批大小,而无需更大的 GPU 内存或跨不同设备的张量分片。
虽然梯度累积可以帮助我们训练具有更大批量大小的模型,但它不会减少所需的总计算量。实际上,它有时会导致训练过程略慢一些,因为权重更新的执行频率较低。尽管如此,它却能帮我们解决限制问题,即批大小非常小时导致的更新频繁且混乱。
例如,现在让我们运行上面的代码,批大小为 1,需要 16 个累积步骤(accumulation steps)来模拟批大小等于 16。
输出如下:
<code>...torch : 2.0.0lightning : 2.0.0transformers: 4.27.2Torch CUDA available? True...Epoch: 0001/0001 | Batch 23700/35000 | Loss: 0.0168Epoch: 0001/0001 | Batch 24000/35000 | Loss: 0.0006Epoch: 0001/0001 | Batch 24300/35000 | Loss: 0.0152Epoch: 0001/0001 | Batch 24600/35000 | Loss: 0.0003Epoch: 0001/0001 | Batch 24900/35000 | Loss: 0.0623Epoch: 0001/0001 | Batch 25200/35000 | Loss: 0.0010Epoch: 0001/0001 | Batch 25500/35000 | Loss: 0.0001Epoch: 0001/0001 | Batch 25800/35000 | Loss: 0.0047Epoch: 0001/0001 | Batch 26100/35000 | Loss: 0.0004Epoch: 0001/0001 | Batch 26400/35000 | Loss: 0.1016Epoch: 0001/0001 | Batch 26700/35000 | Loss: 0.0021Epoch: 0001/0001 | Batch 27000/35000 | Loss: 0.0015Epoch: 0001/0001 | Batch 27300/35000 | Loss: 0.0008Epoch: 0001/0001 | Batch 27600/35000 | Loss: 0.0060Epoch: 0001/0001 | Batch 27900/35000 | Loss: 0.0001Epoch: 0001/0001 | Batch 28200/35000 | Loss: 0.0426Epoch: 0001/0001 | Batch 28500/35000 | Loss: 0.0012Epoch: 0001/0001 | Batch 28800/35000 | Loss: 0.0025Epoch: 0001/0001 | Batch 29100/35000 | Loss: 0.0025Epoch: 0001/0001 | Batch 29400/35000 | Loss: 0.0000Epoch: 0001/0001 | Batch 29700/35000 | Loss: 0.0495Epoch: 0001/0001 | Batch 30000/35000 | Loss: 0.0164Epoch: 0001/0001 | Batch 30300/35000 | Loss: 0.0067Epoch: 0001/0001 | Batch 30600/35000 | Loss: 0.0037Epoch: 0001/0001 | Batch 30900/35000 | Loss: 0.0005Epoch: 0001/0001 | Batch 31200/35000 | Loss: 0.0013Epoch: 0001/0001 | Batch 31500/35000 | Loss: 0.0112Epoch: 0001/0001 | Batch 31800/35000 | Loss: 0.0053Epoch: 0001/0001 | Batch 32100/35000 | Loss: 0.0012Epoch: 0001/0001 | Batch 32400/35000 | Loss: 0.1365Epoch: 0001/0001 | Batch 32700/35000 | Loss: 0.0210Epoch: 0001/0001 | Batch 33000/35000 | Loss: 0.0374Epoch: 0001/0001 | Batch 33300/35000 | Loss: 0.0007Epoch: 0001/0001 | Batch 33600/35000 | Loss: 0.0341Epoch: 0001/0001 | Batch 33900/35000 | Loss: 0.0259Epoch: 0001/0001 | Batch 34200/35000 | Loss: 0.0005Epoch: 0001/0001 | Batch 34500/35000 | Loss: 0.4792Epoch: 0001/0001 | Batch 34800/35000 | Loss: 0.0003Epoch: 0001/0001 | Train acc.: 78.67% | Val acc.: 87.28%Time elapsed 51.37 minTest accuracy 87.37%</code>
根据上面的结果,损失的波动比以前小了。此外,测试集性能提升了 10%。由于只迭代了训练集一次,因此每个训练样本只会遇到一次。训练用于 multiple epochs 的模型可以进一步提高预测性能。
你可能还会注意到,这段代码的执行速度也比之前使用的批大小为 1 的代码快。如果使用梯度累积将虚拟批大小增加到 8,仍然会有相同数量的前向传播(forward passes)。然而,由于每八个 epoch 只更新一次模型,因此反向传播(backward passes)会很少,这样可更快地在一个 epoch(训练轮数)内迭代样本。
结论
梯度累积是一种在执行权重更新之前通过累积多个小的批梯度来模拟更大的批大小的技术。该技术在可用内存有限且内存中可容纳批大小较小的情况下提供帮助。
但是,首先请思考一种你可以运行批大小的场景,这意味着可用内存大到足以容纳所需的批大小。在那种情况下,梯度累积可能不是必需的。事实上,运行更大的批大小可能更有效,因为它允许更多的并行性且能减少训练模型所需的权重更新次数。
总之,梯度累积是一种实用的技术,可以用于降低小批大小干扰信息对梯度更新准确性的影响。这是迄今一种简单而有效的技术,可以让我们绕过硬件的限制。
PS:可以让这个运行得更快吗?
没问题。可以使用 PyTorch 2.0 中引入的 torch.compile 使其运行得更快。只需要添加一些 model = torch.compile,如下图所示:
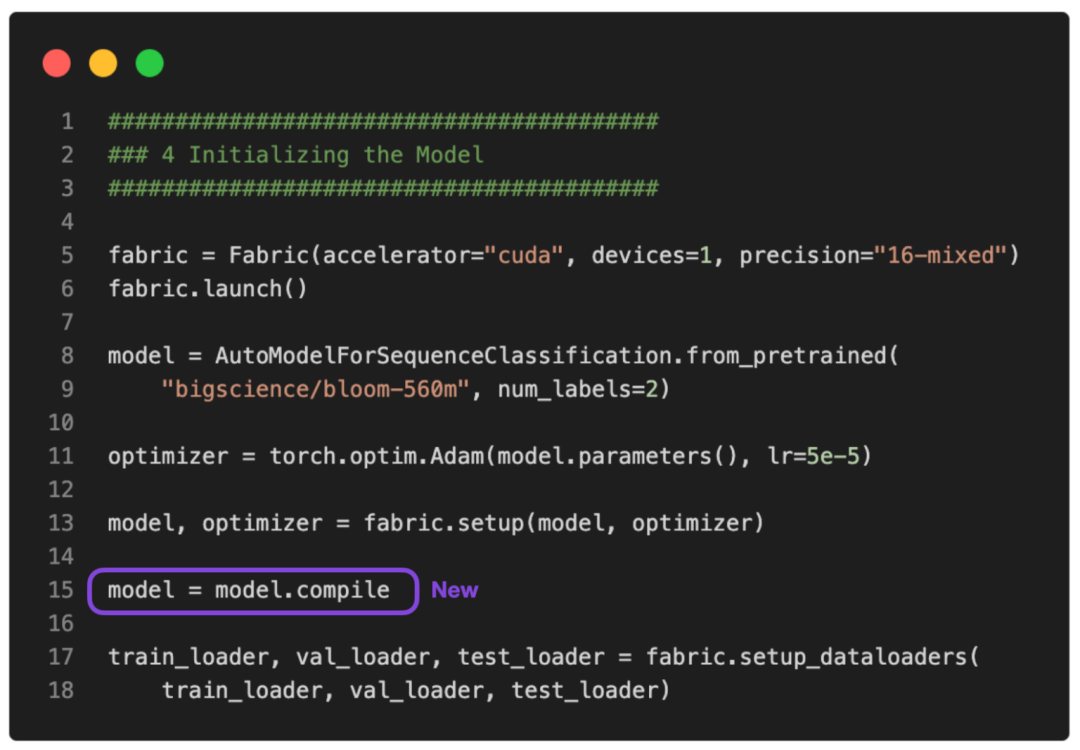
GitHub 上提供了完整的脚本。
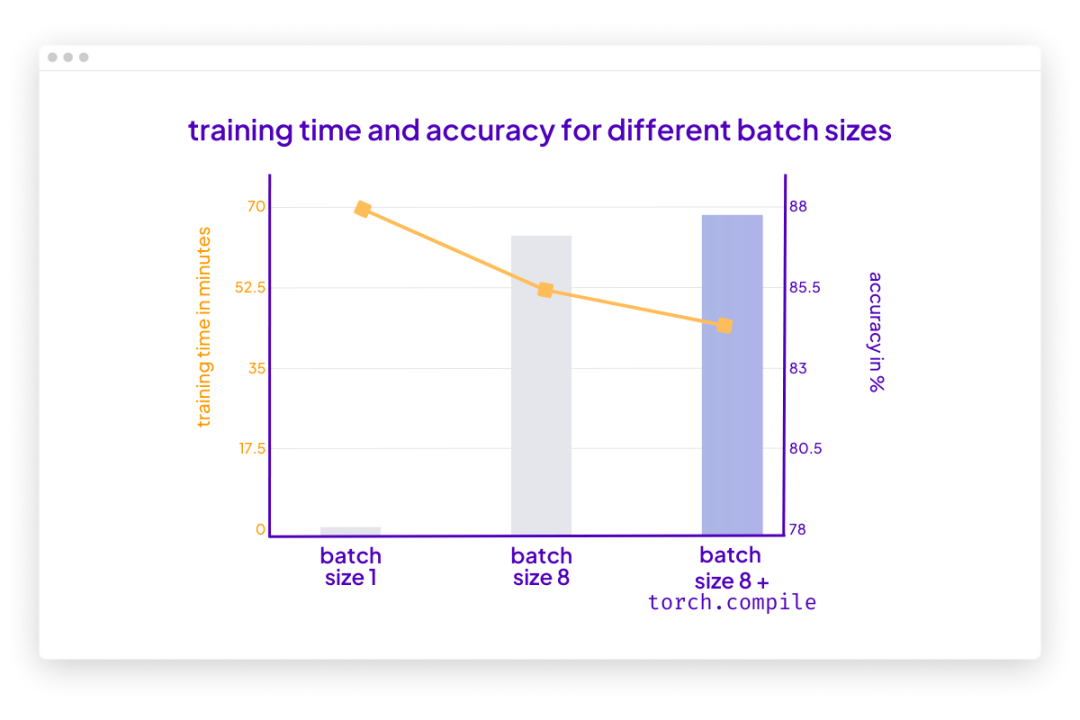
在这种情况下,torch.compile 在不影响建模性能的情况下又减少了十分钟的训练时间:
<code>poch: 0001/0001 | Batch 26400/35000 | Loss: 0.0320Epoch: 0001/0001 | Batch 26700/35000 | Loss: 0.0010Epoch: 0001/0001 | Batch 27000/35000 | Loss: 0.0006Epoch: 0001/0001 | Batch 27300/35000 | Loss: 0.0015Epoch: 0001/0001 | Batch 27600/35000 | Loss: 0.0157Epoch: 0001/0001 | Batch 27900/35000 | Loss: 0.0015Epoch: 0001/0001 | Batch 28200/35000 | Loss: 0.0540Epoch: 0001/0001 | Batch 28500/35000 | Loss: 0.0035Epoch: 0001/0001 | Batch 28800/35000 | Loss: 0.0016Epoch: 0001/0001 | Batch 29100/35000 | Loss: 0.0015Epoch: 0001/0001 | Batch 29400/35000 | Loss: 0.0008Epoch: 0001/0001 | Batch 29700/35000 | Loss: 0.0877Epoch: 0001/0001 | Batch 30000/35000 | Loss: 0.0232Epoch: 0001/0001 | Batch 30300/35000 | Loss: 0.0014Epoch: 0001/0001 | Batch 30600/35000 | Loss: 0.0032Epoch: 0001/0001 | Batch 30900/35000 | Loss: 0.0004Epoch: 0001/0001 | Batch 31200/35000 | Loss: 0.0062Epoch: 0001/0001 | Batch 31500/35000 | Loss: 0.0032Epoch: 0001/0001 | Batch 31800/35000 | Loss: 0.0066Epoch: 0001/0001 | Batch 32100/35000 | Loss: 0.0017Epoch: 0001/0001 | Batch 32400/35000 | Loss: 0.1485Epoch: 0001/0001 | Batch 32700/35000 | Loss: 0.0324Epoch: 0001/0001 | Batch 33000/35000 | Loss: 0.0155Epoch: 0001/0001 | Batch 33300/35000 | Loss: 0.0007Epoch: 0001/0001 | Batch 33600/35000 | Loss: 0.0049Epoch: 0001/0001 | Batch 33900/35000 | Loss: 0.1170Epoch: 0001/0001 | Batch 34200/35000 | Loss: 0.0002Epoch: 0001/0001 | Batch 34500/35000 | Loss: 0.4201Epoch: 0001/0001 | Batch 34800/35000 | Loss: 0.0018Epoch: 0001/0001 | Train acc.: 78.39% | Val acc.: 86.84%Time elapsed 43.33 minTest accuracy 87.91%</code>
请注意,与之前相比准确率略有提高很可能是由于随机性。
위 내용은 컴퓨팅 성능 제한을 우회하기 위해 단일 GPU로 LLM을 미세 조정하는 방법은 무엇입니까? 이것은 'Gradient Accumulation' 알고리즘에 대한 튜토리얼입니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!