
Python에서 의사결정 트리를 구축하는 방법

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-05-13 11:22:052526검색
결정 트리
결정 트리는 오늘날 사용할 수 있는 가장 강력한 지도 학습 방법의 필수적인 부분입니다. 의사결정 트리는 기본적으로 각 노드가 일부 특성 변수를 기반으로 관찰 세트를 분할하는 이진 트리의 순서도입니다.
의사결정 트리의 목표는 그룹의 모든 요소가 동일한 범주에 속하도록 데이터를 그룹으로 나누는 것입니다. 의사결정 트리는 연속 목표 변수를 근사화하는 데에도 사용할 수 있습니다. 이 경우 트리는 각 그룹의 평균 제곱 오차가 가장 작도록 분할됩니다.
의사결정 트리의 중요한 속성은 쉽게 해석할 수 있다는 것입니다. 의사결정 트리가 수행하는 작업을 이해하기 위해 기계 학습 기술에 전혀 익숙할 필요는 없습니다. 의사결정나무 다이어그램은 해석하기 쉽습니다.
장단점
의사결정 트리 방법의 장점은 다음과 같습니다.
의사결정 트리는 이해 가능한 규칙을 생성할 수 있습니다.
결정 트리는 많은 계산을 요구하지 않고 분류를 수행합니다.
의사결정 트리는 연속형 변수와 범주형 변수를 모두 처리할 수 있습니다.
결정 트리는 어떤 필드가 가장 중요한지 명확하게 표시합니다.
의사결정 트리 방법의 단점은 다음과 같습니다.
의사결정 트리는 연속적인 속성 값을 예측하는 것이 목표인 추정 작업에는 적합하지 않습니다.
결정 트리는 클래스가 많고 훈련 샘플이 적은 경우 분류 문제에서 오류가 발생하기 쉽습니다.
의사결정 트리 교육에는 계산 비용이 많이 들 수 있습니다. 의사결정 트리를 생성하는 프로세스는 계산적으로 매우 비용이 많이 듭니다. 각 노드에서 각 후보 분할 필드를 정렬하여 최상의 분할을 찾아야 합니다. 일부 알고리즘에서는 필드 조합을 사용하여 최상의 가중치 조합을 검색해야 합니다. 또한 가지치기 알고리즘은 많은 후보 하위 트리를 형성하고 비교해야 하기 때문에 비용이 많이 들 수 있습니다.
Python 결정 트리
Python은 데이터 과학자를 위한 강력한 기계 학습 패키지와 도구를 제공하는 범용 프로그래밍 언어입니다. 이 기사에서는 Python에서 가장 유명한 기계 학습 패키지인 scikit-learn을 사용하여 의사결정 트리 모델을 구축하겠습니다. scikit-learn에서 제공하는 "DecisionTreeClassifier" 알고리즘을 사용하여 모델을 생성한 다음 "plot_tree" 함수를 사용하여 모델을 시각화하겠습니다.
1단계: 패키지 가져오기
모델을 구축하는 데 사용하는 주요 소프트웨어 패키지는 pandas, scikit learn 및 NumPy입니다. 코드에 따라 Python에서 필요한 패키지를 가져옵니다.
import pandas as pd # 数据处理 import numpy as np # 使用数组 import matplotlib.pyplot as plt # 可视化 from matplotlib import rcParams # 图大小 from termcolor import colored as cl # 文本自定义 from sklearn.tree import DecisionTreeClassifier as dtc # 树算法 from sklearn.model_selection import train_test_split # 拆分数据 from sklearn.metrics import accuracy_score # 模型准确度 from sklearn.tree import plot_tree # 树图 rcParams['figure.figsize'] = (25, 20)
모델을 구축하는 데 필요한 모든 패키지를 가져온 후에는 데이터를 가져와서 EDA를 수행할 차례입니다.
2단계: 데이터 및 EDA 가져오기
이 단계에서는 Python에서 제공되는 "Pandas" 패키지를 사용하여 가져오고 EDA를 수행합니다. 우리는 특정 기준에 따라 환자에게 처방되는 약물 데이터 세트를 기반으로 의사결정 트리 모델을 구축할 것입니다. Python을 사용하여 데이터를 가져오겠습니다!
Python 구현:
df = pd.read_csv('drug.csv') df.drop('Unnamed: 0', axis = 1, inplace = True) print(cl(df.head(), attrs = ['bold']))
출력:
Age Sex BP Cholesterol Na_to_K Drug 0 23 F HIGH HIGH 25.355 drugY 1 47 M LOW HIGH 13.093 drugC 2 47 M LOW HIGH 10.114 drugC 3 28 F NORMAL HIGH 7.798 drugX 4 61 F LOW HIGH 18.043 drugY
이제 데이터 세트에 대한 명확한 아이디어를 얻었습니다. 데이터를 가져온 후 "info" 기능을 사용하여 데이터에 대한 몇 가지 기본 정보를 얻습니다. 이 함수가 제공하는 정보에는 항목 수, 인덱스 번호, 열 이름, Null이 아닌 값 개수, 속성 유형 등이 포함됩니다.
Python 구현:
df.info()
출력:
<class> RangeIndex: 200 entries, 0 to 199 Data columns (total 6 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Age 200 non-null int64 1 Sex 200 non-null object 2 BP 200 non-null object 3 Cholesterol 200 non-null object 4 Na_to_K 200 non-null float64 5 Drug 200 non-null object dtypes: float64(1), int64(1), object(4) memory usage: 9.5+ KB</class>
3단계: 데이터 처리
Sex, BP 및 Cholesterol과 같은 속성은 본질적으로 범주형 및 객체 유형임을 알 수 있습니다. 문제는 scikit-learn의 의사결정 트리 알고리즘이 본질적으로 "객체" 유형의 X 변수(기능)를 지원하지 않는다는 것입니다. 따라서 이러한 "객체" 값을 "바이너리" 값으로 변환할 필요가 있습니다. Python을 사용하여
Python 구현:
for i in df.Sex.values: if i == 'M': df.Sex.replace(i, 0, inplace = True) else: df.Sex.replace(i, 1, inplace = True) for i in df.BP.values: if i == 'LOW': df.BP.replace(i, 0, inplace = True) elif i == 'NORMAL': df.BP.replace(i, 1, inplace = True) elif i == 'HIGH': df.BP.replace(i, 2, inplace = True) for i in df.Cholesterol.values: if i == 'LOW': df.Cholesterol.replace(i, 0, inplace = True) else: df.Cholesterol.replace(i, 1, inplace = True) print(cl(df, attrs = ['bold']))
출력:
Age Sex BP Cholesterol Na_to_K Drug 0 23 1 2 1 25.355 drugY 1 47 1 0 1 13.093 drugC 2 47 1 0 1 10.114 drugC 3 28 1 1 1 7.798 drugX 4 61 1 0 1 18.043 drugY .. ... ... .. ... ... ... 195 56 1 0 1 11.567 drugC 196 16 1 0 1 12.006 drugC 197 52 1 1 1 9.894 drugX 198 23 1 1 1 14.020 drugX 199 40 1 0 1 11.349 drugX [200 rows x 6 columns]
범주형 데이터를 나타내기 위해 모든 "객체" 값이 "이진" 값으로 처리되는 것을 관찰할 수 있습니다. 예를 들어 콜레스테롤 속성에서 '낮음'을 나타내는 값은 0으로 처리되고, '높음' 값은 1로 처리됩니다. 이제 데이터로부터 종속변수와 독립변수를 생성할 준비가 되었습니다.
4단계: 데이터 분할
데이터를 올바른 구조로 처리한 후 이제 "X" 변수(독립 변수), "Y" 변수(종속 변수)를 설정합니다. Python으로 구현해 보겠습니다.
Python 구현:
X_var = df[['Sex', 'BP', 'Age', 'Cholesterol', 'Na_to_K']].values # 自变量 y_var = df['Drug'].values # 因变量 print(cl('X variable samples : {}'.format(X_var[:5]), attrs = ['bold'])) print(cl('Y variable samples : {}'.format(y_var[:5]), attrs = ['bold']))
출력:
X variable samples : [[ 1. 2. 23. 1. 25.355] [ 1. 0. 47. 1. 13.093] [ 1. 0. 47. 1. 10.114] [ 1. 1. 28. 1. 7.798] [ 1. 0. 61. 1. 18.043]] Y variable samples : ['drugY' 'drugC' 'drugC' 'drugX' 'drugY']
이제 scikit learn에서 "train_test_split" 알고리즘을 사용하여 데이터를 훈련 세트와 테스트 세트로 분할할 수 있습니다. Y 우리는 변수를 정의했습니다. 파이썬에서 데이터를 분할하려면 코드를 따르세요.
Python 구현:
X_train, X_test, y_train, y_test = train_test_split(X_var, y_var, test_size = 0.2, random_state = 0) print(cl('X_train shape : {}'.format(X_train.shape), attrs = ['bold'], color = 'black')) print(cl('X_test shape : {}'.format(X_test.shape), attrs = ['bold'], color = 'black')) print(cl('y_train shape : {}'.format(y_train.shape), attrs = ['bold'], color = 'black')) print(cl('y_test shape : {}'.format(y_test.shape), attrs = ['bold'], color = 'black'))
출력:
X_train shape : (160, 5) X_test shape : (40, 5) y_train shape : (160,) y_test shape : (40,)
이제 의사 결정 트리 모델을 구축하는 데 필요한 모든 구성 요소가 있습니다. 이제 Python으로 모델을 구축해 보겠습니다.
5단계: 모델 및 예측 구축
scikit-learn 패키지에서 제공하는 "DecisionTreeClassifier" 알고리즘의 도움으로 의사결정 트리를 구축하는 것이 가능합니다. 그런 다음 훈련된 모델을 사용하여 데이터를 예측할 수 있습니다. 마지막으로, "정확도" 평가 지표를 사용하여 예측 결과의 정확도를 계산할 수 있습니다. Python을 사용하여 이 프로세스를 완료해 보겠습니다.
Python 구현:
model = dtc(criterion = 'entropy', max_depth = 4) model.fit(X_train, y_train) pred_model = model.predict(X_test) print(cl('Accuracy of the model is {:.0%}'.format(accuracy_score(y_test, pred_model)), attrs = ['bold']))
출력:
Accuracy of the model is 88%
在代码的第一步中,我们定义了一个名为“model”变量的变量,我们在其中存储DecisionTreeClassifier模型。接下来,我们将使用我们的训练集对模型进行拟合和训练。之后,我们定义了一个变量,称为“pred_model”变量,其中我们将模型预测的所有值存储在数据上。最后,我们计算了我们的预测值与实际值的精度,其准确率为88%。
步骤6:可视化模型
现在我们有了决策树模型,让我们利用python中scikit learn包提供的“plot_tree”函数来可视化它。按照代码从python中的决策树模型生成一个漂亮的树图。
Python实现:
feature_names = df.columns[:5] target_names = df['Drug'].unique().tolist() plot_tree(model, feature_names = feature_names, class_names = target_names, filled = True, rounded = True) plt.savefig('tree_visualization.png')
输出:
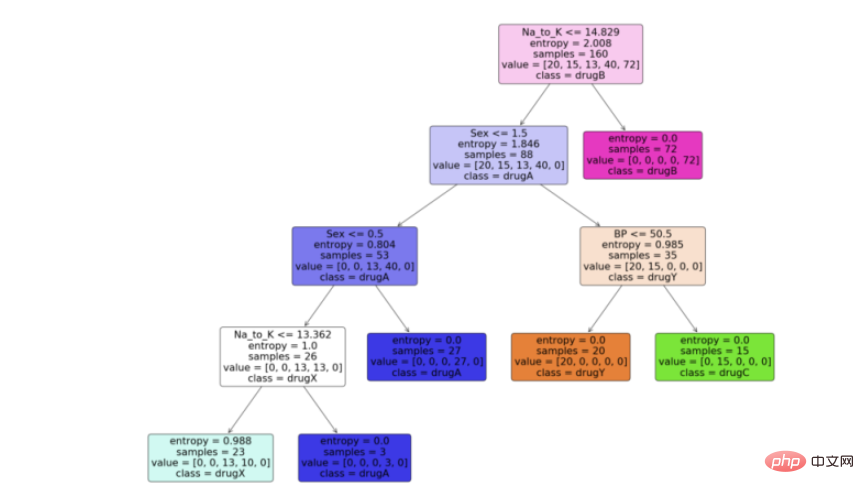
结论
有很多技术和其他算法用于优化决策树和避免过拟合,比如剪枝。虽然决策树通常是不稳定的,这意味着数据的微小变化会导致最优树结构的巨大变化,但其简单性使其成为广泛应用的有力候选。在神经网络流行之前,决策树是机器学习中最先进的算法。其他一些集成模型,比如随机森林模型,比普通决策树模型更强大。
决策树由于其简单性和可解释性而非常强大。决策树和随机森林在用户注册建模、信用评分、故障预测、医疗诊断等领域有着广泛的应用。我为本文提供了完整的代码。
完整代码:
import pandas as pd # 数据处理 import numpy as np # 使用数组 import matplotlib.pyplot as plt # 可视化 from matplotlib import rcParams # 图大小 from termcolor import colored as cl # 文本自定义 from sklearn.tree import DecisionTreeClassifier as dtc # 树算法 from sklearn.model_selection import train_test_split # 拆分数据 from sklearn.metrics import accuracy_score # 模型准确度 from sklearn.tree import plot_tree # 树图 rcParams['figure.figsize'] = (25, 20) df = pd.read_csv('drug.csv') df.drop('Unnamed: 0', axis = 1, inplace = True) print(cl(df.head(), attrs = ['bold'])) df.info() for i in df.Sex.values: if i == 'M': df.Sex.replace(i, 0, inplace = True) else: df.Sex.replace(i, 1, inplace = True) for i in df.BP.values: if i == 'LOW': df.BP.replace(i, 0, inplace = True) elif i == 'NORMAL': df.BP.replace(i, 1, inplace = True) elif i == 'HIGH': df.BP.replace(i, 2, inplace = True) for i in df.Cholesterol.values: if i == 'LOW': df.Cholesterol.replace(i, 0, inplace = True) else: df.Cholesterol.replace(i, 1, inplace = True) print(cl(df, attrs = ['bold'])) X_var = df[['Sex', 'BP', 'Age', 'Cholesterol', 'Na_to_K']].values # 自变量 y_var = df['Drug'].values # 因变量 print(cl('X variable samples : {}'.format(X_var[:5]), attrs = ['bold'])) print(cl('Y variable samples : {}'.format(y_var[:5]), attrs = ['bold'])) X_train, X_test, y_train, y_test = train_test_split(X_var, y_var, test_size = 0.2, random_state = 0) print(cl('X_train shape : {}'.format(X_train.shape), attrs = ['bold'], color = 'red')) print(cl('X_test shape : {}'.format(X_test.shape), attrs = ['bold'], color = 'red')) print(cl('y_train shape : {}'.format(y_train.shape), attrs = ['bold'], color = 'green')) print(cl('y_test shape : {}'.format(y_test.shape), attrs = ['bold'], color = 'green')) model = dtc(criterion = 'entropy', max_depth = 4) model.fit(X_train, y_train) pred_model = model.predict(X_test) print(cl('Accuracy of the model is {:.0%}'.format(accuracy_score(y_test, pred_model)), attrs = ['bold'])) feature_names = df.columns[:5] target_names = df['Drug'].unique().tolist() plot_tree(model, feature_names = feature_names, class_names = target_names, filled = True, rounded = True) plt.savefig('tree_visualization.png')위 내용은 Python에서 의사결정 트리를 구축하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!