
직접 만든 기능을 사용하여 모델 성능 향상

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-05-12 16:55:061266검색
원시 데이터에 대해 수작업으로 특성 엔지니어링을 수행함으로써 모델 정확도와 성능을 새로운 수준으로 끌어올려 이전과는 전혀 다른 방식으로 모델을 최적화하고 개선할 수 있습니다.

원시 데이터는 그림이 없는 직소 퍼즐과 같습니다. 하지만 기능 엔지니어링을 통해 조각을 하나로 모을 수 있습니다. 동시에 대량의 데이터를 보유하는 것은 기계 학습 모델을 구축하려는 금융 기관에게도 보물창고입니다. 모든 데이터가 유익한 것은 아니라는 점을 인정하는 것이 중요합니다. 또한, 수동 기능은 수동으로 설계되었으며, 각 작업의 이유를 설명할 수 있어 해석도 용이합니다.
특성 엔지니어링은 단지 최고의 특성을 선택하는 것이 아닙니다. 또한 모델의 일반화 능력을 향상시키기 위해 데이터의 노이즈와 중복성을 줄이는 것도 포함됩니다. 모델이 실제로 유용하려면 보이지 않는 데이터에서 잘 작동해야 하기 때문에 이는 매우 중요합니다.
데이터 세트 설명
이 문서에 설명된 데이터 세트는 고객 데이터의 기밀성을 유지하기 위해 익명화되고 마스크되었습니다. 기능은 다음과 같이 분류할 수 있습니다.
D_* = 拖欠变量 S_* = 支出变量 P_* = 支付变量 B_* = 平衡变量 R_* = 风险变量
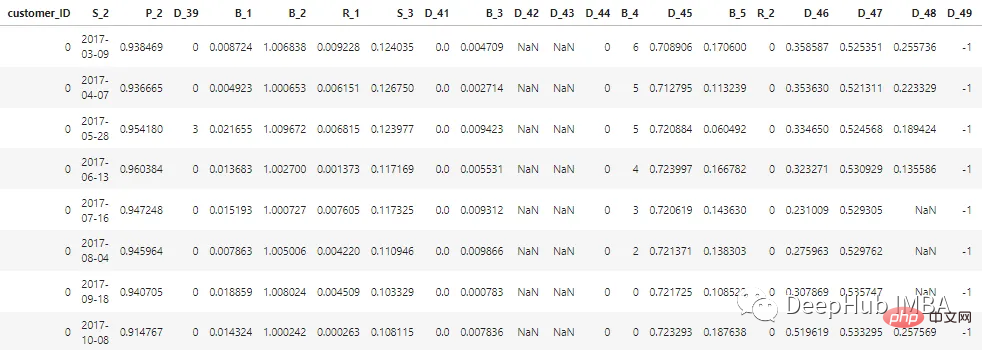
지난 12개월 동안 고객의 상태를 나타내는 총 100개의 정수 기능과 100개의 부동 소수점 기능이 있습니다. 이 데이터 세트에는 1부터 13까지의 고객 보고서에 대한 정보가 포함되어 있습니다. 각 고객의 신용카드 명세서 사이에는 30~180일의 공백이 있을 수 있습니다(예: 고객의 신용카드 명세서가 누락될 수 있음). 각 고객은 고객 ID로 표시됩니다. customer_ID=0인 고객의 처음 5개 레코드의 샘플 데이터는 다음과 같습니다.
700만 개의 customer_ID 중 98%의 레이블이 "0"(좋은 고객, 기본값 없음)이고 2%는 "0"입니다. 레이블은 "1" ”(잘못된 클라이언트, 기본값)입니다.
데이터세트가 크기 때문에 처리 속도를 높이기 위해 cudf를 사용합니다. cudf가 설치되어 있지 않으면 팬더와 동일합니다.
# LOAD LIBRARIES
import pandas as pd, numpy as np # CPU libraries
import cudf # GPU libraries
import matplotlib.pyplot as plt, gc, os
df = cudf.read_parquet('./data.parquet')특성 생성 방법
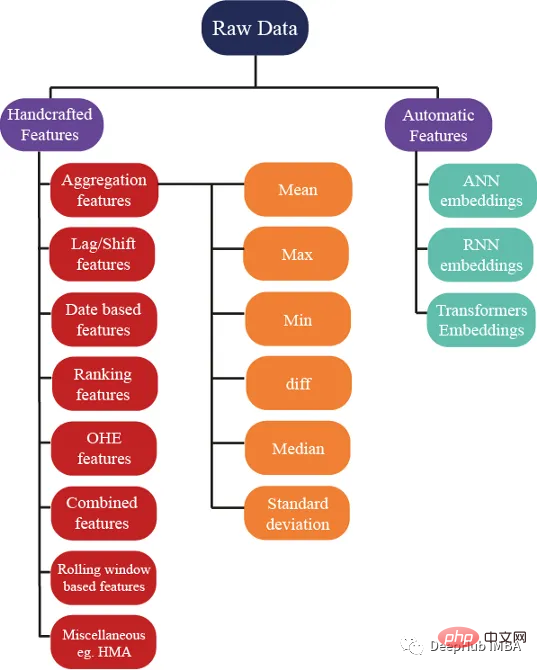
특성 생성에 대한 수백 가지 아이디어가 있지만 우리는 또한 보장합니다. 이러한 특성은 모델의 성능을 향상시키는 데 도움이 되며 아래 이미지는 특성 엔지니어링에 사용되는 몇 가지 기본 방법을 보여줍니다.
특성 집계
집계는 복잡한 데이터를 이해하는 비결입니다. customer_ID(C_ID)나 제품 카테고리 등의 범주형 그룹화 변수나 수치변수의 집합에 대한 요약 통계를 계산함으로써 보이지 않는 패턴과 추세를 발견할 수 있습니다. 평균, 최대값, 최소값, 표준편차, 중앙값 등의 요약 통계를 통해 보다 정확한 예측 모델을 구축하고 고객 데이터, 거래 데이터 또는 기타 수치 데이터에서 의미 있는 통찰력을 추출할 수 있습니다.
이러한 통계 속성은 각 고객에 대해 계산될 수 있습니다.
cat_features = ["B_1","B_2","D_1","D_2","D_10","P_21","D_126","D_3","D_42","R_66","R_68"]
num_features = [col for col in all_cols if col not in cat_features] #all features accept cateforical features.
test_num_agg = df.groupby("customer_ID")[num_features].agg(['mean', 'std', 'min', 'max', 'last','median']) #grouping by customerID
test_num_agg.columns = ['_'.join(x) for x in test_num_agg.columns]평균: 데이터의 중심 경향에 대한 일반적인 감각을 제공할 수 있는 수치 변수의 평균 값입니다. 평균 캡처:
고객이 보유한 평균 은행 잔고.
- 평균 고객 지출입니다.
- 두 신용 명세서 사이의 평균 시간(신용 지불 사이의 시간)입니다.
- 돈을 빌리는 평균 위험.
표준 편차(Std): 평균을 중심으로 데이터 분포를 측정한 값으로, 데이터의 가변성 정도에 대한 통찰력을 제공할 수 있습니다. 잔액의 변동성이 크다는 것은 고객이 지출을 하고 있음을 나타냅니다.
최소값과 최대값은 고객의 부를 포착하고 고객의 지출 및 위험에 대한 정보도 포착합니다.
Median: 데이터의 치우침이 심한 경우에는 평균을 사용하는 것이 더 좋은 생각이 아니므로 중앙값을 사용하면 됩니다. (가운데 값을 사용해도 됩니다.
최신 값이 아마도 가장 중요할 것입니다.
One-Hot Encoding
최소값을 계산하기 때문에 위의 통계 속성을 범주형 변수에 사용하는 것은 현명하지 않습니다. , 최대값 또는 표준 편차는 유용한 정보를 제공하지 않습니다. 그렇다면 어떻게 해야 할까요? 개수 및 고유 수량과 같은 기능을 사용하여 기능을 계산할 수 있으며 최신 값도 사용할 수 있습니다.
cat_features = ["B_1","B_2","D_1","D_2","D_10","P_21","D_126","D_3","D_42","R_66","R_68"]
test_cat_agg = df.groupby("customer_ID")[cat_features].agg(['count', 'last', 'nunique'])
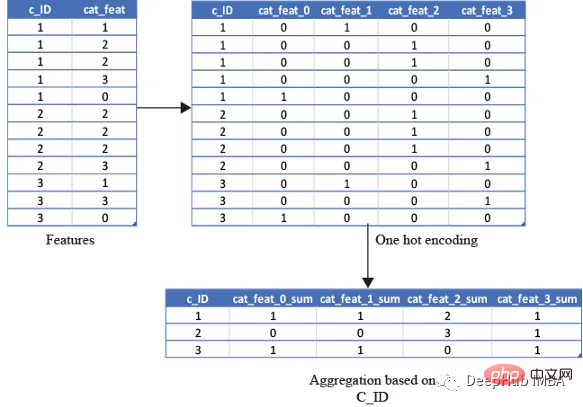
test_cat_agg.columns = ['_'.join(x) for x in test_cat_agg.columns]하지만 이 정보는 그렇지 않습니다. 고객이 특정 카테고리로 분류되는 것을 포착합니다. 따라서 변수를 한 번 핫 인코딩한 다음 평균, 합계 및 마지막으로
평균과 같은 변수를 집계하여 고객이 해당 카테고리에 속하는 총 횟수를 캡처합니다. 단순히 고객이 해당 카테고리
基于排名的特征
在预测客户行为方面,基于排名的特征是非常重要的。通过根据收入或支出等特定属性对客户进行排名,我们可以深入了解他们的财务习惯并更好地管理风险。
使用 cudf 的 rank 函数,我们可以轻松计算这些特征并使用它们来为预测提供信息。例如,可以根据客户的消费模式、债务收入比或信用评分对客户进行排名。然后这些特征可用于预测违约或识别有可能拖欠付款的客户。
基于排名的特征还可用于识别高价值客户、目标营销工作和优化贷款优惠。例如,可以根据客户接受贷款提议的可能性对客户进行排名,然后将排名最高的客户作为目标。
df[feat+'_rank']=df[feat].rank(pct=True, method='min')
PCT用于是否做百分位排名。客户的排名也可以基于分类特征来计算。
df[feat+'_rank']=df.groupby([cat_feat]).rank(pct=True, method='min')
特征组合
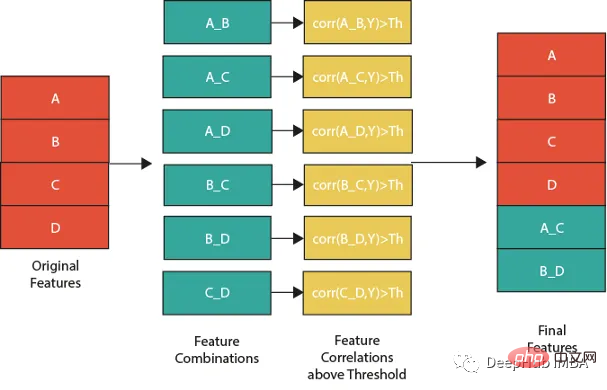
特征组合的一种流行方法是线性或非线性组合。这包括采用两个或多个现有特征,将它们组合在一起创建一个新的复合特征。然后使用这个复合特征来识别单独查看单个特征时可能不可见的模式、趋势和相关性。
例如,假设我们正在分析客户消费习惯的数据集。可以从个人特征开始,比如年龄、收入和地点。但是通过以线性或非线性的方式组合这些特性,可以创建新的复合特性,使我们能够更多地了解客户。可以结合收入和位置来创建一个复合特征,该特征告诉我们某一地区客户的平均支出。
但是并不是所有的特征组合都有用。关键是要确定哪些组合与试图解决的问题最相关,这需要对数据和问题领域有深刻的理解,并仔细分析创建的复合特征和试图预测的目标变量之间的相关性。
下图展示了一个组合特征并将信息用于模型的过程。作为筛选条件,这里只选择那些与目标相关性大于最大值 0.9 的特征。
features=[col for col in train.columns if col not in ['customer_ID',target]+cat_features] for feat1 in features: for feat2 in features: th=max(np.corr(feat1,Y)[0],np.corr(feat1,Y)[0]) #calculate threshold feat3=df[feat1]-df[feat2] #difference feature corr3=np.corr(feat3,Y)[0] if(corr3>max(th,0.9)): #if correlation greater than max(th,0.9) we add it as feature df[feat1+'_'+feat2]=feat3
基于时间/日期的特征
在数据分析方面,基于时间的特征非常重要。通过根据时间属性(例如月份或星期几)对数据进行分组,可以创建强大的特征。这些特征的范围可以从简单的平均值(如收入和支出)到更复杂的属性(如信用评分随时间的变化)。
借助基于时间的特征,还可以识别在孤立地查看数据时可能看不到的模式和趋势。下图演示了如何使用基于时间的特征来创建有用的复合属性。
首先,计算一个月内的值的平均值(可以使用该月的某天或该月的某周等),将获得的DF与原始数据合并,并取各个特征之间的差。
features=[col for col in train.columns if col not in ['customer_ID',target]+cat_features]
month_Agg=df.groupby([month])[features].agg('mean')#grouping based on month feature
month_Agg.columns = ['_month_'.join(x) for x in month_Agg.columns]
month_Agg.reset_index(inplace=True)
df=df.groupby(month_Agg,notallow='month')
for feat in features: #create composite features b taking difference
df[feat+'_'+feat+'_month_mean']=df[feat]-df[feat+'_month_mean']
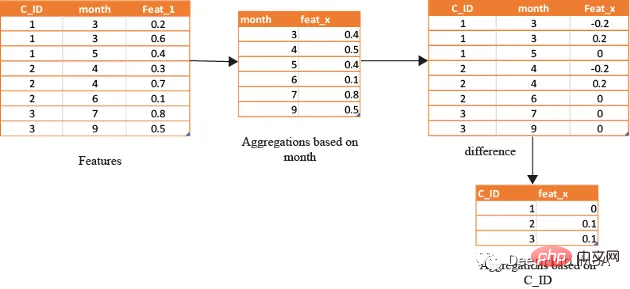
还可以通过使用时间作为分组变量来创建基于排名的特征,如下所示
features=[col for col in train.columns if col not in ['customer_ID',target]+cat_features] month_Agg=df.groupby([month])[features].rank(pct=True) #grouping based on month feature month_Agg.columns = ['_month_'.join(x) for x in month_Agg.columns] month_Agg.reset_index(inplace=True) df=pd.concat([df,month_Agg],axis=1) #concat to original dataframe
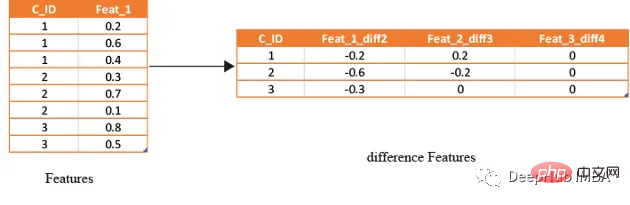
滞后特征
滞后特征是有效预测金融数据的重要工具。这些特征包括计算时间序列中当前值与之前值之间的差值。通过将滞后特征纳入分析,可以更好地理解数据中的模式和趋势,并做出更准确的预测。
如果滞后特征显示客户连续几个月按时支付信用卡账单,可能会预测他们将来不太可能违约。相反,如果延迟特征显示客户一直延迟或错过付款,可能会预测他们更有可能违约。
# difference function calculate the lag difference for numerical features
#between last value and shift last value.
def difference(groups,num_features,shift):
data=(groups[num_features].nth(-1)-groups[num_features].nth(-1*shift)).rename(columns={f: f"{f}_diff{shift}" for f in num_features})
return data
#calculate diff features for last -2nd last, last -3rd last, last- 4th last
def get_difference(data,num_features):
print("diff features...")
groups=data.groupby('customer_ID')
df1=difference(groups,num_features,2).fillna(0)
df2=difference(groups,num_features,3).fillna(0)
df3=difference(groups,num_features,4).fillna(0)
df1=pd.concat([df1,df2,df3],axis=1)
df1.reset_index(inplace=True)
df1.sort_values(by='customer_ID')
del df2,df3
gc.collect()
return df1train_diff = get_difference(df, num_features)
基于滚动窗口的特性
这些特征只是取最后3(4,5,…x)值的平均值,这取决于数据,因为基于时间的最新值携带了关于客户最新状态的信息。
xth=3 #define the window size
df["cumulative"]=df.groupby('customer_ID').sort_values(by=['time'],ascending=False).cumcount()
last_info=df[df["cumulative"]<=xth]
last_info = last_info.groupby("customer_ID")[num_features].agg(['mean', 'std', 'min', 'max', 'last','median']) #grouping by customerID
last_info.columns = ['_'.join(x) for x in last_info.columns]其他的特征提取方法
上面的方法已经创建了足够多的特征来构建一个很棒的模型。但是根据数据的性质,还可以创建更多的特征。例如:可以创建像null计数这样的特征,它可以计算客户当前的总null值,从而帮助捕获基于树的算法无法理解的特征分布。
def calc_nan(df,features):
print("calculating nan_info...")
df_nan = (df[features].mul(0) + 1).fillna(0) #marke non_null values as 1 and null as zero
df_nan['customer_ID'] = df['customer_ID']
nan_sum = df_nan.groupby("customer_ID").sum().sum(axis=1) #total unknown values for a customer
nan_last = df_nan.groupby("customer_ID").last().sum(axis=1)#how many last values that are not known
del df_nan
gc.collect()
return nan_sum,nan_last这里可以不使用平均值,而是使用修正的平均值,如基于时间的加权平均值或 HMA(hull moving average)。
요약
이 기사에서는 현실 세계에서 부도 위험을 예측하는 데 사용되는 가장 일반적으로 손수 만든 기능 전략 중 일부를 제시했습니다. 그러나 기능을 설계하는 데는 항상 새롭고 혁신적인 방법이 있으며, 기능을 수동으로 설정하는 방법은 시간이 많이 걸리고 힘들기 때문에 이후 기사에서 자동 기능 생성을 위한 도구를 사용하는 방법을 소개하겠습니다.
위 내용은 직접 만든 기능을 사용하여 모델 성능 향상의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!