
Python 일반 함수에서 NumPy를 사용하는 방법

- 王林앞으로
- 2023-05-12 15:07:181015검색
1.txt 파일
(1) 단위 행렬
은 주대각선의 요소가 모두 1이고 나머지 요소는 0인 정사각 행렬입니다.
NumPy에서는 눈 기능을 사용하여 이러한 2차원 배열을 만들 수 있습니다. 행렬의 1개 요소 수를 지정하는 매개변수만 제공하면 됩니다.
예를 들어 3×3의 배열을 생성합니다:
import numpy as np I2 = np.eye(3) print(I2) [[1. 0. 0.] [0. 1. 0.] [0. 0. 1.]]
(2) savetxt 함수를 사용하여 데이터를 파일에 저장합니다. 물론 저장할 파일 이름과 배열을 지정해야 합니다.
np.savetxt('eye.txt', I2)#创建一个eye.txt文件,用于保存I2的数据
2.CSV 파일
CSV(쉼표로 구분된 값) 형식은 일반적으로 데이터베이스 덤프 파일이 CSV 형식이며 파일의 각 필드는 데이터베이스 테이블의 열에 해당합니다. 스프레드시트 소프트웨어(예: Microsoft Excel)는 CSV 파일을 처리할 수 있습니다.
참고: NumPy의 loadtxt 함수는 쉽게 CSV 파일을 읽고, 필드를 자동으로 분할하고, 데이터를 NumPy 배열로 로드할 수 있습니다.
data.csv 데이터 콘텐츠:
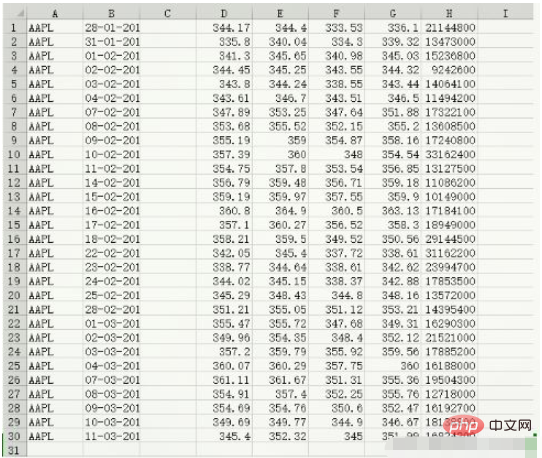
c, v = np.loadtxt('data.csv', delimiter=',', usecols=(6,7), unpack=True) # usecols的参数为一个元组,以获取第7字段至第8字段的数据 # unpack参数设置为True,意思是分拆存储不同列的数据,即分别将收盘价和成交量的数组赋值给变量c和v print(c) [336.1 339.32 345.03 344.32 343.44 346.5 351.88 355.2 358.16 354.54 356.85 359.18 359.9 363.13 358.3 350.56 338.61 342.62 342.88 348.16 353.21 349.31 352.12 359.56 360. 355.36 355.76 352.47 346.67 351.99] print(v) [21144800. 13473000. 15236800. 9242600. 14064100. 11494200. 17322100. 13608500. 17240800. 33162400. 13127500. 11086200. 10149000. 17184100. 18949000. 29144500. 31162200. 23994700. 17853500. 13572000. 14395400. 16290300. 21521000. 17885200. 16188000. 19504300. 12718000. 16192700. 18138800. 16824200.] print(type(c)) print(type(v)) <class 'numpy.ndarray'> <class 'numpy.ndarray'>
3. 거래량 가중 평균 가격 =average() 함수
VWAP 개요: VWAP(거래량 가중 평균 가격)는 금융 자산의 "평균" 가격을 나타내는 매우 중요한 경제 수량입니다.
특정 가격의 거래량이 많을수록 해당 가격의 가중치도 커집니다.
VWAP은 거래량을 가중치로 하여 계산한 가중평균으로, 알고리즘 거래에서 자주 사용됩니다.
vwap = np.average(c,weights=v) print('成交量加权平均价格vwap =', vwap) 成交量加权平均价格vwap = 350.5895493532009
4. 산술 평균 함수 = 평균() 함수
NumPy의 평균 함수는 배열 요소의 산술 평균을 계산할 수 있습니다
print('c数组中元素的算数平均值为: {}'.format(np.mean(c)))
c数组中元素的算数平均值为: 351.03766666666675. 시간 가중 평균 가격
TWAP 개요:
In 경제학에서 TWAP(Time-Weighted Average Price)는 "평균" 가격을 나타내는 또 다른 지표입니다. 이제 VWAP를 계산했으니 TWAP도 계산해 보겠습니다. 사실 TWAP는 단지 변형일 뿐이므로 최근 가격이 더 중요하므로 최근 가격에 더 높은 가중치를 주어야 한다는 것입니다. 가장 간단한 방법은 arange 함수를 사용하여 0부터 시작하여 순차적으로 증가하는 일련의 자연수를 만드는 것입니다. 자연수의 수는 종가의 수입니다. 물론 이것이 반드시 TWAP를 계산하는 올바른 방법은 아닙니다.
t = np.arange(len(c)) print('时间加权平均价格twap=', np.average(c, weights=t)) 时间加权平均价格twap= 352.4283218390804
6. 최대값 및 최소값
h, l = np.loadtxt('data.csv', delimiter=',', usecols=(4,5), unpack=True)
print('h数据为: \n{}'.format(h))
print('-'*10)
print('l数据为: \n{}'.format(l))
h数据为:
[344.4 340.04 345.65 345.25 344.24 346.7 353.25 355.52 359. 360.
357.8 359.48 359.97 364.9 360.27 359.5 345.4 344.64 345.15 348.43
355.05 355.72 354.35 359.79 360.29 361.67 357.4 354.76 349.77 352.32]
----------
l数据为:
[333.53 334.3 340.98 343.55 338.55 343.51 347.64 352.15 354.87 348.
353.54 356.71 357.55 360.5 356.52 349.52 337.72 338.61 338.37 344.8
351.12 347.68 348.4 355.92 357.75 351.31 352.25 350.6 344.9 345. ]
print('h数据的最大值为: {}'.format(np.max(h)))
print('l数据的最小值为: {}'.format(np.min(l)))
h数据的最大值为: 364.9
l数据的最小值为: 333.53
NumPy中有一个ptp函数可以计算数组的取值范围
该函数返回的是数组元素的最大值和最小值之间的差值
也就是说,返回值等于max(array) - min(array)
print('h数据的最大值-最小值的差值为: \n{}'.format(np.ptp(h)))
print('l数据的最大值-最小值的差值为: \n{}'.format(np.ptp(l)))
h数据的最大值-最小值的差值为:
24.859999999999957
l数据的最大值-最小值的差值为:
26.9700000000000277. 통계 분석
중앙값: 일부 임계값을 사용하여 이상값을 제거할 수 있지만 실제로는 더 좋은 방법이 있습니다. 바로 중앙값입니다.
변수 값을 크기순으로 배열하여 시퀀스를 형성하세요. 시퀀스 중간에 있는 숫자가 중앙값입니다.
예를 들어 1, 2, 3, 4, 5의 5개 값이 있는 경우 중앙값은 가운데 숫자 3입니다.
m = np.loadtxt('data.csv', delimiter=',', usecols=(6,), unpack=True)
print('m数据中的中位数为: {}'.format(np.median(m)))
m数据中的中位数为: 352.055
# 数组排序后,查找中位数
sorted_m = np.msort(m)
print('m数据排序: \n{}'.format(sorted_m))
N = len(c)
print('m数据中的中位数为: {}'.format((sorted_m[N//2]+sorted_m[(N-1)//2])/2))
m数据排序:
[336.1 338.61 339.32 342.62 342.88 343.44 344.32 345.03 346.5 346.67
348.16 349.31 350.56 351.88 351.99 352.12 352.47 353.21 354.54 355.2
355.36 355.76 356.85 358.16 358.3 359.18 359.56 359.9 360. 363.13]
m数据中的中位数为: 352.055
方差:
方差是指各个数据与所有数据算术平均数的离差平方和除以数据个数所得到的值。
print('variance =', np.var(m))
variance = 50.126517888888884
var_hand = np.mean((m-m.mean())**2)
print('var =', var_hand)
var = 50.126517888888884참고: 표본 분산과 모집단 분산 간의 계산 차이입니다. 모집단 분산은 편차 제곱의 합을 데이터 수로 나눈 값이고, 표본 분산은 편차 제곱의 합을 표본 데이터 수 - 1로 나눈 값입니다. 여기서 표본 데이터 수 - 1(즉, n- 1) 자유도라고 한다. 이러한 차이가 발생하는 이유는 표본 분산이 편향되지 않은 추정량임을 보장하기 위한 것입니다.
8. 주식 수익률
학술 문헌에서 종가 분석은 종종 주식 수익률과 로그 수익률을 기반으로 합니다.
단순 수익률은 인접한 두 가격 간의 변화율을 의미하고, 로그 수익률은 모든 가격에 로그를 취한 후 두 가격의 차이를 의미합니다.
우리는 고등학교 때 로그에 대해 배웠습니다. "a"에서 "b"의 로그를 뺀 값은 "a를 b로 나눈 로그"와 같습니다. 따라서 로그 수익률을 사용하여 가격 변화율을 측정할 수도 있습니다.
수익률은 비율이므로, 예를 들어 미국 달러를 미국 달러로 나누면(다른 통화 단위일 수도 있음) 차원이 없습니다.
간단히 말하면, 투자자들이 가장 관심을 두는 것은 수익률의 분산이나 표준편차인데, 이는 투자 위험의 크기를 나타내기 때문입니다.
(1) 먼저 단순수익률을 계산해보겠습니다. NumPy의 diff 함수는 인접한 배열 요소 간의 차이로 구성된 배열을 반환할 수 있습니다. 이는 미분 계산과 다소 유사합니다. 수익률을 계산하려면 전날 가격을 그 차이로 나누어야 합니다. 그러나 여기서 diff에 의해 반환된 배열에는 종가 배열보다 요소가 하나 적다는 점에 유의하세요. return = np.diff(arr)/arr[:-1]
종가 배열의 마지막 값을 제수로 사용하지 않는다는 점에 유의하세요. 다음으로, std 함수를 사용하여 표준 편차를 계산합니다.
print ("Standard deviation =", np.std(returns))(2) 로그 반환은 계산하기가 훨씬 더 간단합니다. 먼저 로그 함수를 사용하여 각 종가의 로그를 얻은 다음 결과에 대해 diff 함수를 사용합니다.
logreturns = np.diff( np.log(c) )
일반적으로 입력 배열에 0과 음수가 포함되어 있지 않은지 확인해야 합니다. 그렇지 않으면 오류 메시지가 표시됩니다. 그러나 이 예에서는 주가가 항상 양수이므로 확인을 생략할 수 있습니다.
(3) 우리는 어느 거래일이 긍정적인 수익을 내는지에 매우 관심이 있을 것입니다.
이전 단계를 완료한 후에는 where 함수만 사용하면 됩니다. where 함수는 지정된 조건에 따라 조건을 만족하는 모든 배열 요소의 인덱스 값을 반환할 수 있습니다.
다음 코드를 입력하세요:
posretindices = np.where(returns > 0) print "Indices with positive returns", posretindices 即可输出该数组中所有正值元素的索引。 Indices with positive returns (array([ 0, 1, 4, 5, 6, 7, 9, 10, 11, 12, 16, 17, 18, 19, 21, 22, 23, 25, 28]),)
(4) 在投资学中,波动率(volatility)是对价格变动的一种度量。历史波动率可以根据历史价格数据计算得出。计算历史波动率(如年波动率或月波动率)时,需要用到对数收益率。年波动率等于对数收益率的标准差除以其均值,再除以交易日倒数的平方根,通常交易日取252天。用std和mean函数来计算
代码如下所示:
annual_volatility = np.std(logreturns)/np.mean(logreturns) annual_volatility = annual_volatility / np.sqrt(1./252.)
(5) sqrt函数中的除法运算。在Python中,整数的除法和浮点数的除法运算机制不同(python3已修改该功能),我们必须使用浮点数才能得到正确的结果。与计算年波动率的方法类似,计算月波动率如下:
annual_volatility * np.sqrt(1./12.)
c = np.loadtxt('data.csv', delimiter=',', usecols=(6,), unpack=True)
returns = np.diff(c)/c[:-1]
print('returns的标准差: {}'.format(np.std(returns)))
logreturns = np.diff(np.log(c))
posretindices = np.where(returns>0)
print('retruns中元素为正数的位置: \n{}'.format(posretindices))
annual_volatility = np.std(logreturns)/np.mean(logreturns)
annual_volatility = annual_volatility/np.sqrt(1/252)
print('每年波动率: {}'.format(annual_volatility))
print('每月波动率:{}'.format(annual_volatility*np.sqrt(1/12)))
returns的标准差: 0.012922134436826306
retruns中元素为正数的位置:
(array([ 0, 1, 4, 5, 6, 7, 9, 10, 11, 12, 16, 17, 18, 19, 21, 22, 23,
25, 28], dtype=int64),)
每年波动率: 129.27478991115132
每月波动率:37.318417377317765위 내용은 Python 일반 함수에서 NumPy를 사용하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!