
이 오픈소스 프로젝트 덕분에 AI Stefanie Sun의 커버가 히트를 쳤습니다! Guangxi Laobiao가 제작에 앞장섰고, 시작하기 위한 가이드가 공개되었습니다.

- 王林앞으로
- 2023-05-12 14:07:061066검색
AI 스테파니 선은 어떻게 그렇게 많은 곡을 그렇게 빨리 커버했을까요?
핵심은 오픈 소스 프로젝트에 있습니다.
최근 이런 AI 커버 열풍이 불고 있는데, AI 스테파니 선이 노래를 부르는 일이 많아졌을 뿐만 아니라, AI 가수의 영역도 넓어지고, 프로듀싱 튜토리얼까지 속속 등장하고 있다. 또 다른.
그리고 주요 튜토리얼을 살펴보면 핵심 비밀이 so-vits-svc라는 오픈 소스 프로젝트에 있다는 것을 알게 될 것입니다.
음색 교체 방법을 제공하는 프로젝트입니다. 올해 3월에 출시되었습니다.
기여 멤버 대부분은 중국 출신이어야 하며, 기여도가 가장 높은 사람은 Arknights를 플레이하는 광시 출신 베테랑입니다.
이제 프로젝트 업데이트는 중단되었지만 별 수는 계속 늘어나 현재 8.4k에 도달했습니다.
그렇다면 이러한 트렌드를 폭발시킬 수 있는 기술은 무엇입니까?
함께 보시죠.
오픈 소스 프로젝트 덕분입니다
이 프로젝트의 이름은 SoftVC VITS Singing Voice Conversion(Singing Voice Conversion)입니다.
SoftVC 컨텐츠 인코더를 사용하여 소스 오디오의 음성 특징을 추출한 후 중간에 텍스트로 변환하지 않고 벡터를 VITS에 직접 입력하여 음높이와 억양을 유지하는 음색 변환 알고리즘을 제공합니다.
또한 보코더가 NSF HiFiGAN으로 변경되어 소리 끊김 문제를 해결할 수 있습니다.
다음 단계로 나누어집니다.
- 사전 학습 모델
- 데이터 세트 준비
- 사전 처리
- Training
- Inference
그 중 사전 학습 모델 단계는 다음 중 하나입니다. 핵심은 프로젝트 자체가 모든 음색에 대한 오디오 훈련 모델을 제공하지 않기 때문입니다. 따라서 새로운 AI 가수를 만들고 싶다면 모델을 직접 훈련해야 합니다.
모델 사전 학습의 첫 번째 단계는 음악이 없는 순수한 인간의 목소리인 Dry Voice를 준비하는 것입니다.
많은 블로거들이 사용하는 도구는 UVR_v5.5.0입니다.
Twitter 블로거 @Guizang은 처리하기 전에 사운드 형식을 WAV 형식으로 변환하는 것이 가장 좋다고 말했습니다. So-VITS-SVC 4.0은 후속 처리를 용이하게 하기 위해 이 형식만 인식하기 때문입니다.
더 나은 결과를 원한다면 매번 다른 설정으로 배경음을 두 번 처리해야 하며, 이렇게 하면 드라이 사운드의 품질을 극대화할 수 있습니다.
처리된 오디오를 얻은 후 몇 가지 전처리 작업을 수행해야 합니다.
예를 들어 오디오가 너무 길면 비디오 메모리가 초과되기 쉬우므로 오디오를 슬라이싱하는 데 5~15초 이상 소요되는 것이 좋습니다.
그런 다음 44100Hz 및 모노로 리샘플링하고 자동으로 데이터 세트를 훈련 세트와 검증 세트로 나누어 구성 파일을 생성합니다. Hubert와 f0를 재생성합니다.
이제 훈련과 추론을 시작할 수 있습니다.
GitHub 프로젝트 페이지에서 특정 단계를 확인할 수 있습니다(가이드 끝).
이 프로젝트는 올해 3월에 시작되었으며 현재 25명의 기여자가 있다는 점을 언급할 가치가 있습니다. 기여하는 사용자의 프로필을 보면 중국 출신이 많을 것입니다.
처음 프로젝트를 시작했을 때는 허점이 많았고 프로그래밍이 필요한 부분도 있었다고 합니다. 하지만 사람들이 거의 매일 업데이트하고 패치를 하면서 지금은 사용의 문턱이 많이 낮아졌다고 합니다.
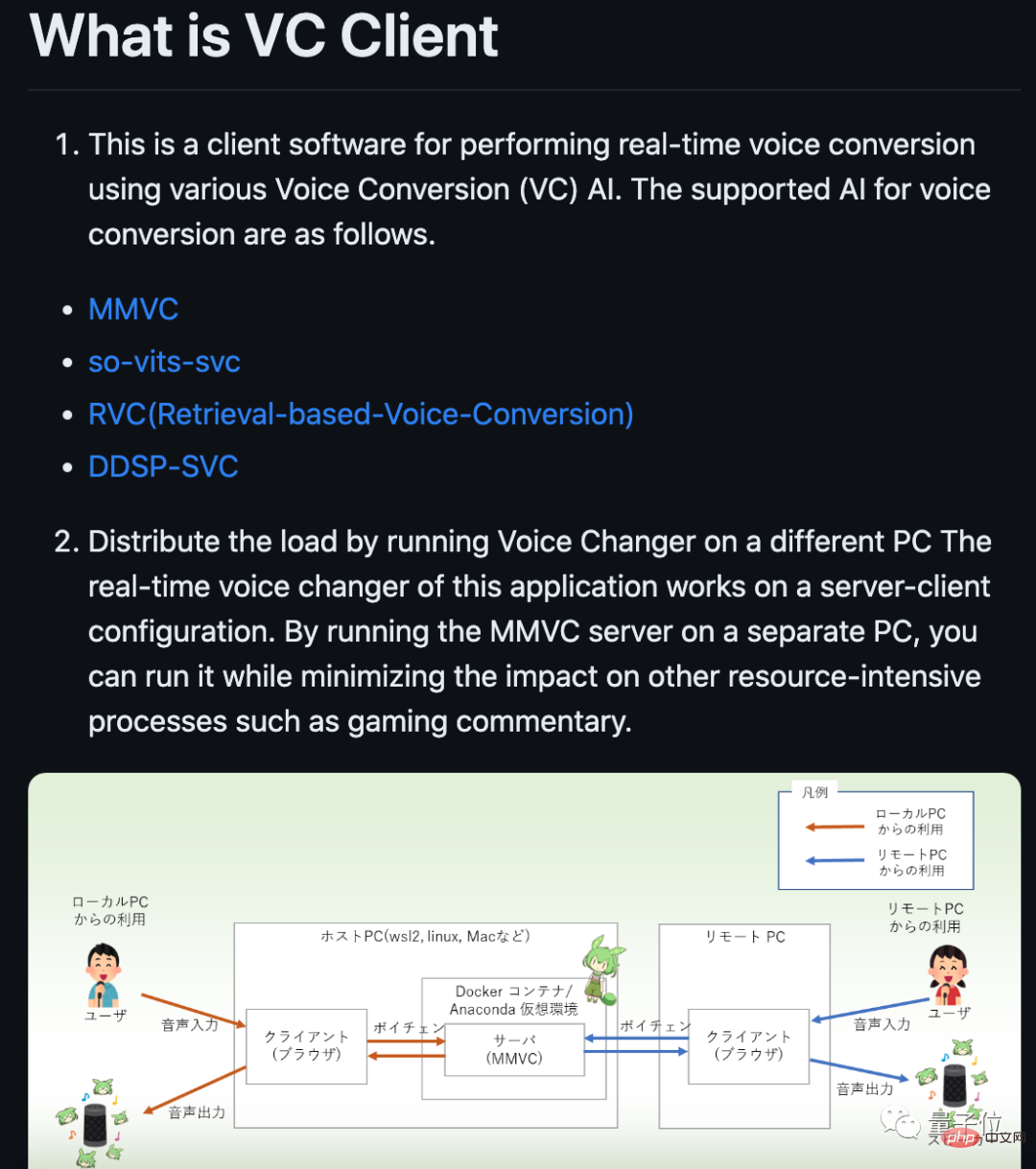
현재 프로젝트 업데이트가 중단되었지만 일부 개발자는 여전히 새로운 브랜치를 만들었습니다. 예를 들어 일부 사람들은 실시간 변환을 지원하는 클라이언트를 만들었습니다.
이 프로젝트에 가장 많이 기여한 개발자는 Miuzarte입니다. 프로필 주소로 보면 광시 출신인 것으로 보입니다.
점점 더 많은 사람들이 시작하고 싶어함에 따라 많은 블로거들이 시작하기 더 쉬운 보다 자세한 소비 가이드를 출시했습니다.
Guizang에서 권장하는 방법은 추론(모델 사용) 및 교육을 위해 통합 패키지를 사용하는 것이며, Station B의 Jack-Cui가 Windows (https://www.bilibili.com/)에서 단계별 가이드를 보여주었습니다. 읽기/cv22375562 ).
모델 훈련에는 상대적으로 높은 그래픽 카드가 필요하며, 그래픽 메모리가 6G 미만인 경우 다양한 문제가 발생할 수 있다는 점에 유의하세요.
Jack-Cui는 N 카드 사용을 권장했으며 RTX 2060 S를 사용했으며 모델을 훈련하는 데 약 14시간이 걸렸습니다.
교육 데이터도 중요합니다. 오디오 품질이 높을수록 최종 효과가 더 좋습니다.
여전히 저작권 문제가 걱정됩니다
참고로 so-vits-svc 프로젝트 홈페이지에는 저작권 문제가 강조되어 있습니다.
경고: 데이터 세트의 인증 문제를 직접 해결하시기 바랍니다. 교육을 위해 승인되지 않은 데이터 세트를 사용하여 발생하는 모든 문제와 그에 따른 모든 결과에 대한 책임은 전적으로 귀하에게 있습니다. 생성된 결과에 저장소, 관리자, SVC 개발팀은 아무 관련이 없습니다!

이것은 AI 페인팅이 폭발했을 때와 약간 비슷합니다.
AI가 생성한 콘텐츠의 초기 데이터는 인간의 저작물을 기반으로 하기 때문에 저작권 분쟁이 끊이지 않습니다.
그리고 AI 작품의 인기로 인해 일부 저작권 소유자가 플랫폼에서 동영상을 삭제하는 조치를 취했습니다.
AI 합성곡 'Heart on My Sleeve'가 Tik Tok에서 인기를 끌었던 것으로 파악됩니다. Drake와 Weekend가 부른 버전을 합성한 것입니다.
그런데 드레이크와 위켄드의 음반 회사인 유니버설 뮤직은 해당 영상을 플랫폼에서 삭제하고 잠재적인 위조자들에게 성명을 통해 “우리는 아티스트, 팬, 인간의 창의적 표현의 편에 서야 할까요, 아니면 아티스트 쪽, 팬 쪽, 그리고 인간의 창의적 표현 쪽?” 딥페이크 쪽, 사기 쪽, 아티스트 보상 거부 쪽?
게다가 가수 드레이크도 AI가 만든 커버곡에 불만을 표시했다.
반면에는 이 기술을 받아들이는 사람들도 있습니다.
캐나다 가수 Grimes는 다른 사람들이 자신의 목소리로 노래를 합성하도록 할 의향이 있지만 로열티의 절반을 지불해야 한다고 말했습니다.
GitHub 주소: https://github.com/svc-develop-team/so-vits-svc
위 내용은 이 오픈소스 프로젝트 덕분에 AI Stefanie Sun의 커버가 히트를 쳤습니다! Guangxi Laobiao가 제작에 앞장섰고, 시작하기 위한 가이드가 공개되었습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!