
Python Numpy에서 ndarray의 일반적인 작업 예 분석

- PHPz앞으로
- 2023-05-10 16:25:141385검색
Foreword
NumPy(숫자 Python)는 Python용 오픈 소스 수치 컴퓨팅 확장 프로그램입니다. 이 도구는 큰 행렬을 저장하고 처리하는 데 사용할 수 있으며 Python 자체의 중첩 목록 구조(행렬을 나타내는 데에도 사용할 수 있음)보다 훨씬 효율적이며 많은 차원 배열 및 행렬 연산을 지원합니다. 또한 배열 연산을 위한 다수의 수학 함수 라이브러리를 제공합니다.
Numpy는 주로 ndarray를 사용하여 N차원 배열을 처리합니다. Numpy의 대부분의 속성과 메서드는 ndarray를 제공하므로 Numpy에서 ndarray의 일반적인 작업을 마스터하는 것이 매우 필요합니다!
0 Numpy 기본
NumPy의 주요 객체는 동형 다차원 배열입니다. 이는 음이 아닌 정수의 튜플로 인덱싱된 동일한 유형의 요소(일반적으로 숫자) 목록입니다. NumPy 차원에서는 축이라고 합니다.
아래 예에서는 배열에 2개의 축이 있습니다. 첫 번째 축의 길이는 2이고 두 번째 축의 길이는 3입니다.
[[ 1., 0., 0.], [ 0., 1., 2.]]
1 ndarray
1.1의 속성 ndarray
ndarray.ndim의 출력 공통 속성: 배열의 축(차원) 수입니다. Python 세계에서는 차원의 수를 순위라고 합니다.
ndarray.shape : 배열의 크기입니다. 이는 각 차원의 배열 크기를 나타내는 정수의 튜플입니다. n행과 m열로 구성된 행렬의 경우 모양은 (n,m)입니다. 따라서 모양 튜플의 길이는 순위 또는 차원 수 ndim입니다.
ndarray.size : 배열 요소의 총 개수입니다. 이는 모양 요소의 곱과 같습니다.
ndarray.dtype: 배열의 요소 유형을 설명하는 개체입니다. 표준 Python 유형을 사용하여 dtype을 생성하거나 지정할 수 있습니다. 또한 NumPy는 자체 유형을 제공합니다. 예를 들어 numpy.int32, numpy.int16 및 numpy.float64입니다.
ndarray.itemsize : 배열에 있는 각 요소의 바이트 크기입니다. 예를 들어, float64 유형의 요소가 있는 배열의 항목 크기는 8(=64/8)이고, complex32 유형의 배열의 항목 크기는 4(=32/8)입니다. ndarray.dtype.itemsize와 동일합니다.
>>> import numpy as np
>>> a = np.arange(15).reshape(3, 5)
>>> a
array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14]])
>>> a.shape
(3, 5)
>>> a.ndim
2
>>> a.dtype.name
'int64'
>>> a.itemsize
8
>>> a.size
15
>>> type(a)
<type 'numpy.ndarray'>
>>> b = np.array([6, 7, 8])
>>> b
array([6, 7, 8])
>>> type(b)
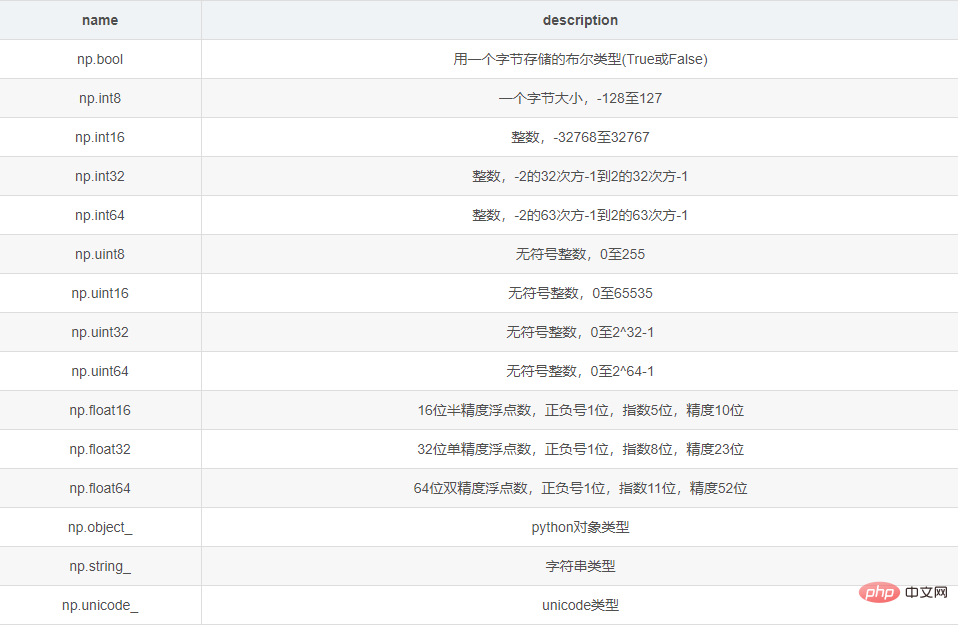
<type 'numpy.ndarray'>2 ndarray의 데이터 유형
동일한 ndarray에는 동일한 유형의 데이터가 저장됩니다. ndarray의 일반적인 데이터 유형은 다음과 같습니다.
3 ndarray의 모양과 데이터 유형을 수정합니다
3.1 ndarray
## ndarray reshape操作 array_a = np.array([[1, 2, 3], [4, 5, 6]]) print(array_a, array_a.shape) array_a_1 = array_a.reshape((3, 2)) print(array_a_1, array_a_1.shape) # note: reshape不能改变ndarray中元素的个数,例如reshape之前为(2,3),reshape之后为(3,2)/(1,6)... ## ndarray转置 array_a_2 = array_a.T print(array_a_2, array_a_2.shape) ## ndarray ravel操作:将ndarray展平 a.ravel() # returns the array, flattened array([ 1, 2, 3, 4, 5, 6 ]) 输出: [[1 2 3] [4 5 6]] (2, 3) [[1 2] [3 4] [5 6]] (3, 2) [[1 4] [2 5] [3 6]] (3, 2)
모양 보기 및 수정 3.2 ndarray
astype(dtype[, order, casting, subok, copy]) 데이터 유형 보기 및 수정: ndarray에서 데이터 유형을 수정합니다. 수정해야 하는 데이터 유형을 전달하고 다른 키워드 매개변수는 무시할 수 있습니다.
array_a = np.array([[1, 2, 3], [4, 5, 6]]) print(array_a, array_a.dtype) array_a_1 = array_a.astype(np.int64) print(array_a_1, array_a_1.dtype) 输出: [[1 2 3] [4 5 6]] int32 [[1 2 3] [4 5 6]] int64
4 ndarray 배열 생성
NumPy는 주로 np.array() 함수를 통해 ndarray 배열을 생성합니다. np.array()函数来创建ndarray数组。
>>> import numpy as np >>> a = np.array([2,3,4]) >>> a array([2, 3, 4]) >>> a.dtype dtype('int64') >>> b = np.array([1.2, 3.5, 5.1]) >>> b.dtype dtype('float64')
也可以在创建时显式指定数组的类型:
>>> c = np.array( [ [1,2], [3,4] ], dtype=complex )
>>> c
array([[ 1.+0.j, 2.+0.j],
[ 3.+0.j, 4.+0.j]])也可以通过使用np.random.random函数来创建随机的ndarray数组。
>>> a = np.random.random((2,3))
>>> a
array([[ 0.18626021, 0.34556073, 0.39676747],
[ 0.53881673, 0.41919451, 0.6852195 ]])通常,数组的元素最初是未知的,但它的大小是已知的。因此,NumPy提供了几个函数来创建具有初始占位符内容的数组。这就减少了数组增长的必要,因为数组增长的操作花费很大。
函数zeros创建一个由0组成的数组,函数 ones创建一个完整的数组,函数empty 创建一个数组,其初始内容是随机的,取决于内存的状态。默认情况下,创建的数组的dtype是 float64 类型的。
>>> np.zeros( (3,4) )
array([[ 0., 0., 0., 0.],
[ 0., 0., 0., 0.],
[ 0., 0., 0., 0.]])
>>> np.ones( (2,3,4), dtype=np.int16 ) # dtype can also be specified
array([[[ 1, 1, 1, 1],
[ 1, 1, 1, 1],
[ 1, 1, 1, 1]],
[[ 1, 1, 1, 1],
[ 1, 1, 1, 1],
[ 1, 1, 1, 1]]], dtype=int16)
>>> np.empty( (2,3) ) # uninitialized, output may vary
array([[ 3.73603959e-262, 6.02658058e-154, 6.55490914e-260],
[ 5.30498948e-313, 3.14673309e-307, 1.00000000e+000]])为了创建数字组成的数组,NumPy提供了一个类似于range的函数,该函数返回数组而不是列表。
>>> np.arange( 10, 30, 5 ) array([10, 15, 20, 25]) >>> np.arange( 0, 2, 0.3 ) # it accepts float arguments array([ 0. , 0.3, 0.6, 0.9, 1.2, 1.5, 1.8])
5 ndarray数组的常见运算
与许多矩阵语言不同,乘积运算符*在NumPy数组中按元素进行运算。矩阵乘积可以使用@运算符(在python> = 3.5中)或dot函数或方法执行:
>>> A = np.array( [[1,1],
... [0,1]] )
>>> B = np.array( [[2,0],
... [3,4]] )
>>> A * B # elementwise product
array([[2, 0],
[0, 4]])
>>> A @ B # matrix product
array([[5, 4],
[3, 4]])
>>> A.dot(B) # another matrix product
array([[5, 4],
[3, 4]])某些操作(例如+=和 *=)会更直接更改被操作的矩阵数组而不会创建新矩阵数组。
>>> a = np.ones((2,3), dtype=int)
>>> b = np.random.random((2,3))
>>> a *= 3
>>> a
array([[3, 3, 3],
[3, 3, 3]])
>>> b += a
>>> b
array([[ 3.417022 , 3.72032449, 3.00011437],
[ 3.30233257, 3.14675589, 3.09233859]])
>>> a += b # b is not automatically converted to integer type
Traceback (most recent call last):
...
TypeError: Cannot cast ufunc add output from dtype('float64') to dtype('int64') with casting rule 'same_kind'当使用不同类型的数组进行操作时,结果数组的类型对应于更一般或更精确的数组(称为向上转换的行为)。
>>> a = np.ones(3, dtype=np.int32)
>>> b = np.linspace(0,pi,3)
>>> b.dtype.name
'float64'
>>> c = a+b
>>> c
array([ 1. , 2.57079633, 4.14159265])
>>> c.dtype.name
'float64'
>>> d = np.exp(c*1j)
>>> d
array([ 0.54030231+0.84147098j, -0.84147098+0.54030231j,
-0.54030231-0.84147098j])
>>> d.dtype.name
'complex128'许多一元操作,例如计算数组中所有元素的总和,都是作为ndarray
>>> a = np.random.random((2,3))
>>> a
array([[ 0.18626021, 0.34556073, 0.39676747],
[ 0.53881673, 0.41919451, 0.6852195 ]])
>>> a.sum()
2.5718191614547998
>>> a.min()
0.1862602113776709
>>> a.max()
0.6852195003967595
생성할 때 배열 유형을 명시적으로 지정할 수도 있습니다.
>>> b = np.arange(12).reshape(3,4)
>>> b
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
>>>
>>> b.sum(axis=0) # 计算每一列的和
array([12, 15, 18, 21])
>>>
>>> b.min(axis=1) # 计算每一行的和
array([0, 4, 8])
>>>
>>> b.cumsum(axis=1) # cumulative sum along each row
array([[ 0, 1, 3, 6],
[ 4, 9, 15, 22],
[ 8, 17, 27, 38]])
解释:以第一行为例,0=0,1=1+0,3=2+1+0,6=3+2+1+0 np.random.random 함수를 사용하여 임의의 ndarray 배열을 생성할 수도 있습니다. >>> a = np.arange(10)**3
>>> a
array([ 0, 1, 8, 27, 64, 125, 216, 343, 512, 729])
>>> a[2]
8
>>> a[2:5]
array([ 8, 27, 64])
>>> a[:6:2] = -1000 # 等价于 a[0:6:2] = -1000; 从0到6的位置, 每隔一个设置为-1000
>>> a
array([-1000, 1, -1000, 27, -1000, 125, fan 216, 343, 512, 729])
>>> a[ : :-1] # 将a反转
array([ 729, 512, 343, 216, 125, -1000, 27, -1000, 1, -1000])
일반적으로 배열의 요소는 처음에는 알 수 없지만 크기는 알려져 있습니다. 따라서 NumPy는 초기 자리 표시자 내용으로 배열을 생성하는 여러 기능을 제공합니다. 이렇게 하면 비용이 많이 드는 작업인 어레이 확장의 필요성이 줄어듭니다. zeros 함수는 0으로 구성된 배열을 만들고, ones 함수는 완전한 배열을 만들고, empty 함수는 초기 내용이 포함된 배열을 만듭니다. 메모리 상태에 따라 무작위입니다.
>>> b
array([[ 0, 1, 2, 3],
[10, 11, 12, 13],
[20, 21, 22, 23],
[30, 31, 32, 33],
[40, 41, 42, 43]])
>>> b[2,3]
23
>>> b[0:5, 1] # each row in the second column of b
array([ 1, 11, 21, 31, 41])
>>> b[ : ,1] # equivalent to the previous example
array([ 1, 11, 21, 31, 41])
>>> b[1:3, : ] # each column in the second and third row of b
array([[10, 11, 12, 13],
[20, 21, 22, 23]])
>>> b[-1] # the last row. Equivalent to b[-1,:]
array([40, 41, 42, 43])숫자 배열을 만들기 위해 NumPy는 목록 대신 배열을 반환하는 range와 유사한 함수를 제공합니다.
>>> a = np.floor(10*np.random.random((2,2)))
>>> a
array([[ 8., 8.],
[ 0., 0.]])
>>> b = np.floor(10*np.random.random((2,2)))
>>> b
array([[ 1., 8.],
[ 0., 4.]])
>>> np.vstack((a,b))
array([[ 8., 8.],
[ 0., 0.],
[ 1., 8.],
[ 0., 4.]])
>>> np.hstack((a,b))
array([[ 8., 8., 1., 8.],
[ 0., 0., 0., 4.]])🎜5 ndarray 배열의 일반적인 연산🎜🎜많은 행렬 언어와 달리 곱 연산자 *는 NumPy 배열에서 요소별로 작동합니다. 매트릭스 곱은 @ 연산자(python> = 3.5) 또는 dot 함수나 메서드를 사용하여 수행할 수 있습니다. 🎜>>> from numpy import newaxis
>>> a = np.array([4.,2.])
>>> b = np.array([3.,8.])
>>> np.column_stack((a,b)) # returns a 2D array
array([[ 4., 3.],
[ 2., 8.]])
>>> np.hstack((a,b)) # the result is different
array([ 4., 2., 3., 8.])
>>> a[:,newaxis] # this allows to have a 2D columns vector
array([[ 4.],
[ 2.]])
>>> np.column_stack((a[:,newaxis],b[:,newaxis]))
array([[ 4., 3.],
[ 2., 8.]])
>>> np.hstack((a[:,newaxis],b[:,newaxis])) # the result is the same
array([[ 4., 3.],
[ 2., 8.]])🎜 특정 작업(예: += 및 *=)는 새 행렬 배열을 생성하지 않고도 연산 중인 행렬 배열을 보다 직접적으로 변경합니다. 🎜################### np.hsplit ###################
>>> a = np.floor(10*np.random.random((2,12)))
>>> a
array([[ 9., 5., 6., 3., 6., 8., 0., 7., 9., 7., 2., 7.],
[ 1., 4., 9., 2., 2., 1., 0., 6., 2., 2., 4., 0.]])
>>> np.hsplit(a,3) # Split a into 3
[array([[ 9., 5., 6., 3.],
[ 1., 4., 9., 2.]]), array([[ 6., 8., 0., 7.],
[ 2., 1., 0., 6.]]), array([[ 9., 7., 2., 7.],
[ 2., 2., 4., 0.]])]
>>> np.hsplit(a,(3,4)) # Split a after the third and the fourth column
[array([[ 9., 5., 6.],
[ 1., 4., 9.]]), array([[ 3.],
[ 2.]]), array([[ 6., 8., 0., 7., 9., 7., 2., 7.],
[ 2., 1., 0., 6., 2., 2., 4., 0.]])]
>>> x = np.arange(8.0).reshape(2, 2, 2)
>>> x
array([[[0., 1.],
[2., 3.]],
[[4., 5.],
[6., 7.]]])
################### np.vsplit ###################
>>> np.vsplit(x, 2)
[array([[[0., 1.],
[2., 3.]]]), array([[[4., 5.],
[6., 7.]]])]🎜 다양한 유형의 배열로 작업할 때 결과 배열의 유형은 보다 일반적이거나 정확한 배열에 해당합니다(업캐스팅이라는 동작). 🎜rrreee🎜배열에 있는 모든 요소의 합을 계산하는 것과 같은 많은 단항 연산은 ndarray 클래스의 메서드로 구현됩니다. 🎜rrreee🎜🎜기본적으로 이러한 작업은 모양에 관계없이 배열에서 숫자 목록인 것처럼 작동합니다. 그러나 축 매개변수를 지정하면 배열의 지정된 축을 따라 작업을 적용할 수 있습니다. 🎜🎜rrreee🎜6 ndarray 배열의 인덱싱, 슬라이싱 및 반복 🎜🎜🎜1차원 🎜배열은 인덱싱, 슬라이싱 및 반복 가능 목록은 다른 Python 시퀀스 유형과 같습니다. 🎜rrreee🎜🎜다차원🎜 배열은 축당 하나의 인덱스를 가질 수 있습니다. 이러한 인덱스는 쉼표로 구분된 튜플로 제공됩니다. 🎜>>> b
array([[ 0, 1, 2, 3],
[10, 11, 12, 13],
[20, 21, 22, 23],
[30, 31, 32, 33],
[40, 41, 42, 43]])
>>> b[2,3]
23
>>> b[0:5, 1] # each row in the second column of b
array([ 1, 11, 21, 31, 41])
>>> b[ : ,1] # equivalent to the previous example
array([ 1, 11, 21, 31, 41])
>>> b[1:3, : ] # each column in the second and third row of b
array([[10, 11, 12, 13],
[20, 21, 22, 23]])
>>> b[-1] # the last row. Equivalent to b[-1,:]
array([40, 41, 42, 43])7 ndarray数组的堆叠、拆分
几个数组可以沿不同的轴堆叠在一起,例如:np.vstack()函数和np.hstack()函数
>>> a = np.floor(10*np.random.random((2,2)))
>>> a
array([[ 8., 8.],
[ 0., 0.]])
>>> b = np.floor(10*np.random.random((2,2)))
>>> b
array([[ 1., 8.],
[ 0., 4.]])
>>> np.vstack((a,b))
array([[ 8., 8.],
[ 0., 0.],
[ 1., 8.],
[ 0., 4.]])
>>> np.hstack((a,b))
array([[ 8., 8., 1., 8.],
[ 0., 0., 0., 4.]])column_stack()函数将1D数组作为列堆叠到2D数组中。
>>> from numpy import newaxis
>>> a = np.array([4.,2.])
>>> b = np.array([3.,8.])
>>> np.column_stack((a,b)) # returns a 2D array
array([[ 4., 3.],
[ 2., 8.]])
>>> np.hstack((a,b)) # the result is different
array([ 4., 2., 3., 8.])
>>> a[:,newaxis] # this allows to have a 2D columns vector
array([[ 4.],
[ 2.]])
>>> np.column_stack((a[:,newaxis],b[:,newaxis]))
array([[ 4., 3.],
[ 2., 8.]])
>>> np.hstack((a[:,newaxis],b[:,newaxis])) # the result is the same
array([[ 4., 3.],
[ 2., 8.]])使用hsplit(),可以沿数组的水平轴拆分数组,方法是指定要返回的形状相等的数组的数量,或者指定应该在其之后进行分割的列:
同理,使用vsplit(),可以沿数组的垂直轴拆分数组,方法同上。
################### np.hsplit ###################
>>> a = np.floor(10*np.random.random((2,12)))
>>> a
array([[ 9., 5., 6., 3., 6., 8., 0., 7., 9., 7., 2., 7.],
[ 1., 4., 9., 2., 2., 1., 0., 6., 2., 2., 4., 0.]])
>>> np.hsplit(a,3) # Split a into 3
[array([[ 9., 5., 6., 3.],
[ 1., 4., 9., 2.]]), array([[ 6., 8., 0., 7.],
[ 2., 1., 0., 6.]]), array([[ 9., 7., 2., 7.],
[ 2., 2., 4., 0.]])]
>>> np.hsplit(a,(3,4)) # Split a after the third and the fourth column
[array([[ 9., 5., 6.],
[ 1., 4., 9.]]), array([[ 3.],
[ 2.]]), array([[ 6., 8., 0., 7., 9., 7., 2., 7.],
[ 2., 1., 0., 6., 2., 2., 4., 0.]])]
>>> x = np.arange(8.0).reshape(2, 2, 2)
>>> x
array([[[0., 1.],
[2., 3.]],
[[4., 5.],
[6., 7.]]])
################### np.vsplit ###################
>>> np.vsplit(x, 2)
[array([[[0., 1.],
[2., 3.]]]), array([[[4., 5.],
[6., 7.]]])]위 내용은 Python Numpy에서 ndarray의 일반적인 작업 예 분석의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!