
Python에서 PyPDF2 모듈을 사용하여 PDF 문서를 분할하는 방법

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-05-09 15:34:081428검색
PyPDF2 모듈 설치
# 이 모듈은 대소문자를 엄격하게 구분하며, y는 소문자, 나머지는 대문자입니다.
pip3 install PyPDF2
설치가 완료된 후 로컬에 이 프로젝트용으로 특별히 폴더를 만듭니다. 하드디스크, 여기 있어요 현재 저장 경로는 F:PythonPyPDF2 입니다. F 드라이브에는 Python 폴더가 있고, 그 안에 이 모듈의 이름을 딴 폴더를 생성하여 별도로 저장하고 다른 프로젝트와 구분합니다.
파일 생성 및 PDF 문서 준비
연습을 위해 비교적 큰 PDF 문서를 찾았습니다. Django 공식 웹사이트에서 그의 문서를 다운로드했습니다. 이 문서는 1900페이지가 넘으니 확실히 충분합니다. 필요하다면 공식 홈페이지에 가서 다운로드하거나, 내 공식 계정에 'pdf'라고 직접 답장해 다운로드 링크를 받은 후 PDFCF.py 프로젝트 파일을 생성하세요.
작성 시작
프로그램은 두 줄로 시작합니다. 첫 번째 문장은 이 파일의 실행 프로그램을 지정한다는 의미입니다. 이건 아직 나오지는 않았지만, 프로그램을 일괄적으로 빠르게 실행하는 방법을 알면 그 기능도 알 수 있을 테니 여기서는 자세히 설명하지 않겠습니다.
#! python# PDFCF.py - pdf文件拆分程序
문서 분할 아이디어
몇 부분으로 분할되는지는 고정되어 있지 않지만, 각 부분이 몇 페이지로 구성되어 있는지는 고정되어 있으며, 분할된 부분 수를 동적으로 계산합니다. 이제 분할 아이디어가 가능해졌습니다. 그러면 다음 단계는 계산 공식을 나열하는 것입니다.
拆分的份数= 文档总页数 / 拆份每个pdf组成的页数
예:
총 35페이지로 구성된 PDF 문서를 분할하고 10페이지마다 새 문서를 구성하려는 경우 분할할 수 있는 부분 수에 대한 계산 공식은 다음과 같습니다.
3.5 = 35 / 10
이때 다들 주목하고 계시는게 나머지가 0.5라면 무슨 뜻일까요? 이 예를 사용하면 3개로 분할한 후 5페이지가 남는다는 의미입니다. 이 경우 남은 부분이 무엇이든 1씩 앞으로 이동해야 전체 분할이 완료됩니다. 처음 3개 문서 각 문서는 10페이지로 구성되며, 네 번째 문서는 마지막 5페이지로 구성됩니다. 분할 가능한 경우 결과는 바로 분할 사본 수입니다.
Python 분할 계산 공식:
if 35 % 10: # 判断是否有余数 35 // 10 + 1 # 取余数整数部分加1else: 0 # 能整除则直接返回0 # 将这个循环写到一行4 = 35 // 10 + 1 if 35 % 10 else 0
구체적으로 분할하는 방법은 무엇인가요?
35페이지 문서 분할을 예로 들어보겠습니다.
범위(35)에서 num에 대한 데이터의 각 페이지를 반복하고, 각 페이지의 데이터를 가져온 다음 분할 페이지를 지정합니다. 숫자 범위 분할:
첫 번째 문서는 0~10이며, 10은 제외됩니다.
두 번째 문서는 10~20이며, 20은 제외됩니다.
세 번째 문서는 20~30입니다. , 30 제외
네 번째 문서는 35를 제외하고 30~35입니다
매번 첫 번째 숫자를 순회하는 패턴은 문서의 페이지 수에 어느 숫자를 곱한 것입니다. 당신이 속한 사람은 그것을 얻을 수 있습니다. 두 번째 숫자에는 패턴이 없다는 것을 알았습니다. 실제로 자세히 관찰하면 패턴이 있습니다. 분할 수를 정렬하면 이 예는 1-4입니다. 각 문서가 구성되는 페이지 수입니다(페이지 수는 10으로 고정됩니다).
하지만 처음으로 순회할 때는 0부터 시작하므로 num을 사용할 수 없게 됩니다. 그런 다음 이를 변환하고 범위(1,35)에서 처음부터 순회합니다. (1-1)--10*1, 10을 포함하지 않음
두 번째 문서는 10*(2-1)-10*2, 20을 포함하지 않음의 특성입니다.
세 번째 문서는 10*(3-1)-10*3, 30은 제외- 네 번째 문서는 10(4-1)-35
- 특정 순회 코드
-
for num in range(1,35+1): pass for i in range(10 * (num-1), 10 * num if num != 4 else 35): pass
참고: num = 4(마지막 문서 정렬 번호)로 순회할 때 총 페이지 수 35만 반환하면 여기서 순회가 끝납니다. 여기서 총 페이지 수가 35+1이 아닌 35인 이유는 무엇입니까? 이번에는 0부터 순회하기 때문에 페이지 번호는 0부터 시작하므로 1을 더할 필요가 없습니다.
완전한 분할 프로그램:
import PyPDF2참고: 저는 개인적으로 위의 분할 아이디어가 약간 복잡하다고 생각합니다. Python 목록의 가장자리 다듬기 및 단계 크기 개념을 철저히 이해하고 있다면 그렇게 할 수 없습니다. 복잡하다고 생각하지 마세요. 전체 페이지 번호의 큰 목록을 생성한 다음 슬라이싱 방법을 사용하여 이 목록을 여러 개의 작은 목록으로 분할하면 됩니다. 그런 다음 각 분할에 대한 PDF 페이지 번호의 범위가 첫 번째입니다. 숫자-각 작은 목록의 마지막 숫자 숫자 +1, 참고용으로 목록 방법을 사용하여 구현한 코드도 게시했습니다.
PDF를 분할하는 목록 분할 방법:
#! python
사용 방법?
프로젝트 폴더 내에서 Shift 키를 누른 채 마우스 오른쪽 버튼을 클릭하고 여기에서 명령 창을 열도록 선택한 다음 PDFCF.py를 입력하고 Enter 키를 누른 다음 필요에 따라 n 값을 변경하세요. 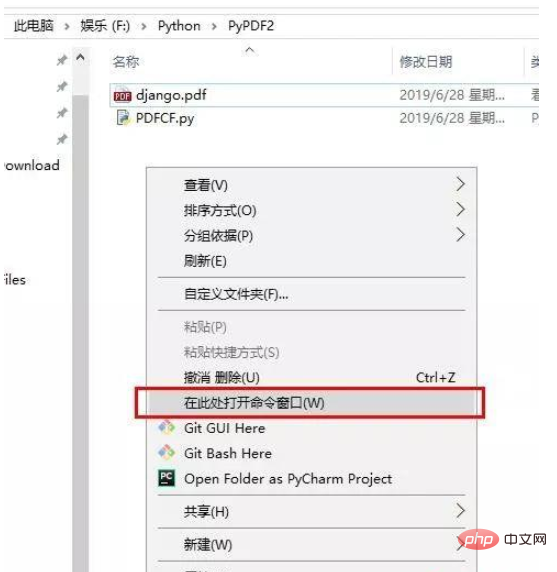

위 내용은 Python에서 PyPDF2 모듈을 사용하여 PDF 문서를 분할하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!