
'ChatGPT Nemesis' 업그레이드: 교사는 전체 학급의 숙제를 테스트에 제출할 수 있습니다! 중국 작가: 무료로 사용 가능

- 王林앞으로
- 2023-05-04 19:25:041138검색
"ChatGPT Nemesis"가 업그레이드되었습니다!
그렇습니다. 중국 형제 Edward Tian이 만든 GPTZero입니다. 몇 초만 지나면 텍스트가 인간이 쓴 것인지 AI가 쓴 것인지 알 수 있습니다.

약 한 달 후, 그 사람이 출시한 버전은 GPTZeroX라고 불리며 다음과 같이 말했습니다.
이것은 교육자를 위해 특별히 제작된 AI 모델입니다.
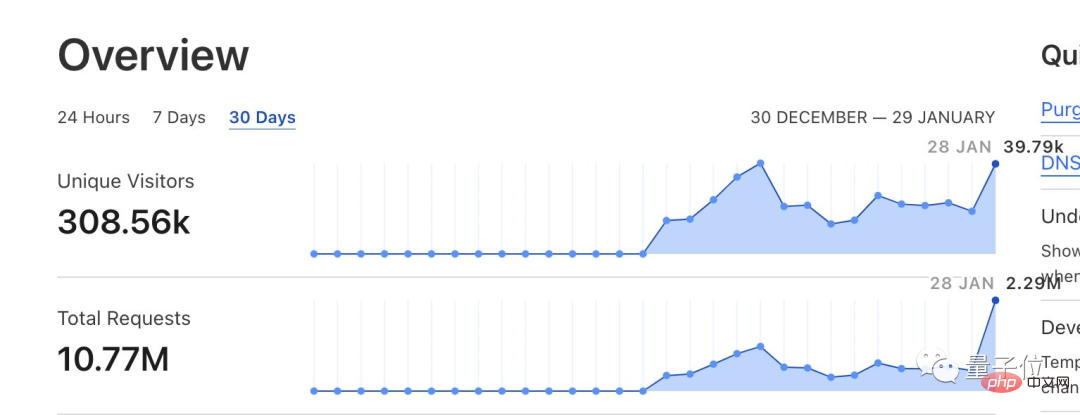
해당 소식이 나오자마자 하루 만에 방문수 40만 건, 서비스 요청 건수 220만 건을 기록할 정도로 많은 네티즌들의 유입을 불러일으켰습니다.
이번에 이 "ChatGPT Nemesis"는 어떤 새로운 기능을 가져오나요?
혼합 쓰기도 테스트할 수 있으며 Word 및 기타 형식도 지원합니다.
업그레이드의 주요 특징은 GPTZeroX가 "인간 + AI"가 혼합된 텍스트 콘텐츠를 감지할 수 있다는 것입니다.
예를 들어, 먼저 인간이 작성한 뉴스를 테스트에 던집니다.

GPTZeroX는 단 몇 초 만에 매우 빠르게 답변을 제공합니다.
당신의 텍스트는 전적으로 인간이 쓴 것일 가능성이 높습니다.
당신의 텍스트는 전적으로 사람이 쓴 것일 가능성이 높습니다.
다음으로 지금 막 뉴스 뒷면에 ChatGPT가 작성한 텍스트를 던져 혼합 감지를 수행하겠습니다.
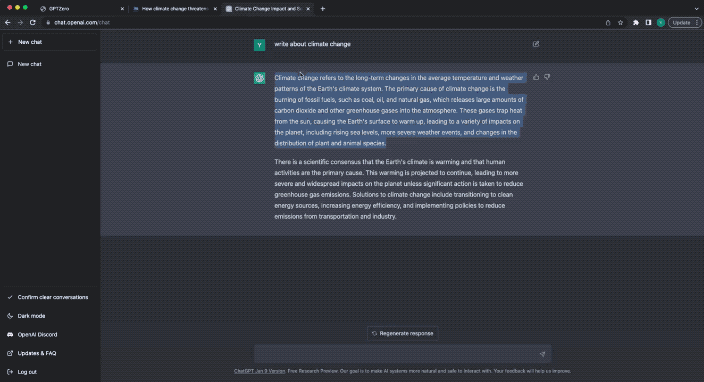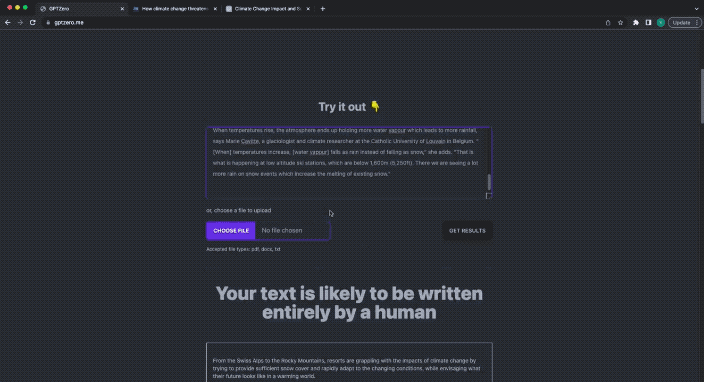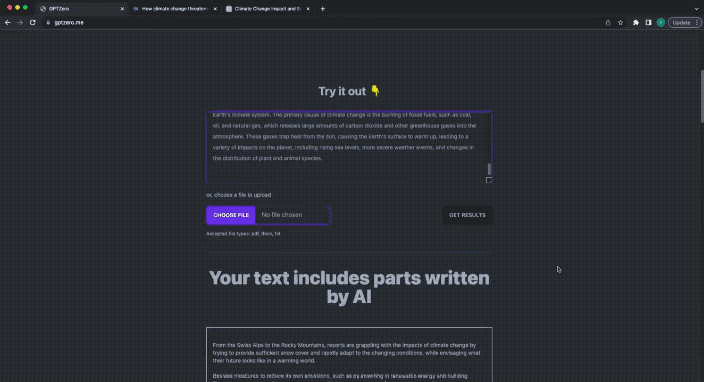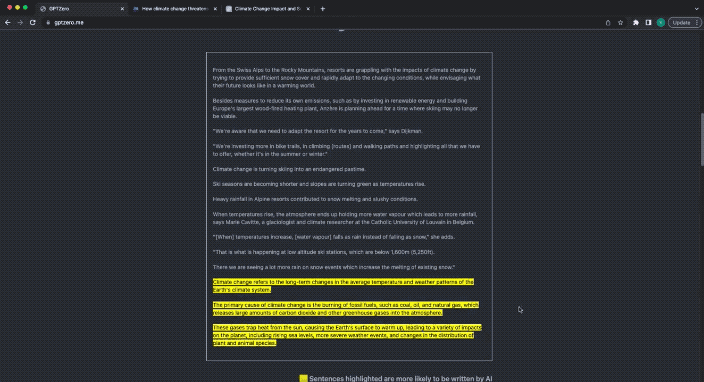
이번 GPTZero의 답변은 다음과 같습니다.
텍스트에는 AI가 작성한 부분이 포함되어 있습니다.
텍스트의 일부는 AI가 작성합니다.
ChatGPT에서 생성된 콘텐츠도 노란색으로 강조 표시됩니다.

형님의 말:
이것은 교육자들이 항상 원했던 핵심 기능입니다.
하지만 선생님이 학생들의 숙제를 확인할 때, 텍스트를 한 문단씩 복사해서 붙여넣는 것은 꽤 지루한 작업입니다.
그 이후로 이 사람은 또 다른 새로운 기능, 즉 파일을 일괄적으로 가져오고 Word, PDF, TXT 및 기타 형식을 지원하는 기능을 신중하게 출시했습니다.
그리고 웹사이트에서는 이 기능을 소개할 때 이렇게 설명하고 있어요

:

게다가 서비스 충돌을 방지하기 위해 그 분이 Python API도 만들어주셨는데, 일종의 스트레스 테스트.

마지막으로 동생이 신중하게 말했습니다.
이 웹사이트는 개별 교사와 교육자에게 무료로 제공될 것을 약속합니다!
어떻게 하나요?
주로 "당황", 즉 텍스트의 "당황"을 해당 콘텐츠를 작성자가 누구인지 확인하는 지표로 사용합니다.
NLP 분야의 친구들은 이 지표가 언어 모델의 품질을 평가하는 데 사용된다는 것을 모두 알고 있습니다.
여기서 GPTZero에 테스트 콘텐츠를 제공할 때마다 다음과 같이 계산됩니다.
1. 총 텍스트 혼란
이 값이 높을수록 사람이 작성한 가능성이 높아집니다.

2. 모든 문장의 평균 혼란
문장이 길수록 이 값은 일반적으로 낮습니다.

3. 각 문장의 혼란
은 막대 차트 형식으로 표시됩니다. 각 상자 위에 마우스를 올리면 해당 문장이 무엇인지 확인할 수 있습니다. (테스트 내용이 여기에 있으므로 여기에는 두 개의 블록만 있습니다.) 이번에 입력한 문장은 2문장입니다.)
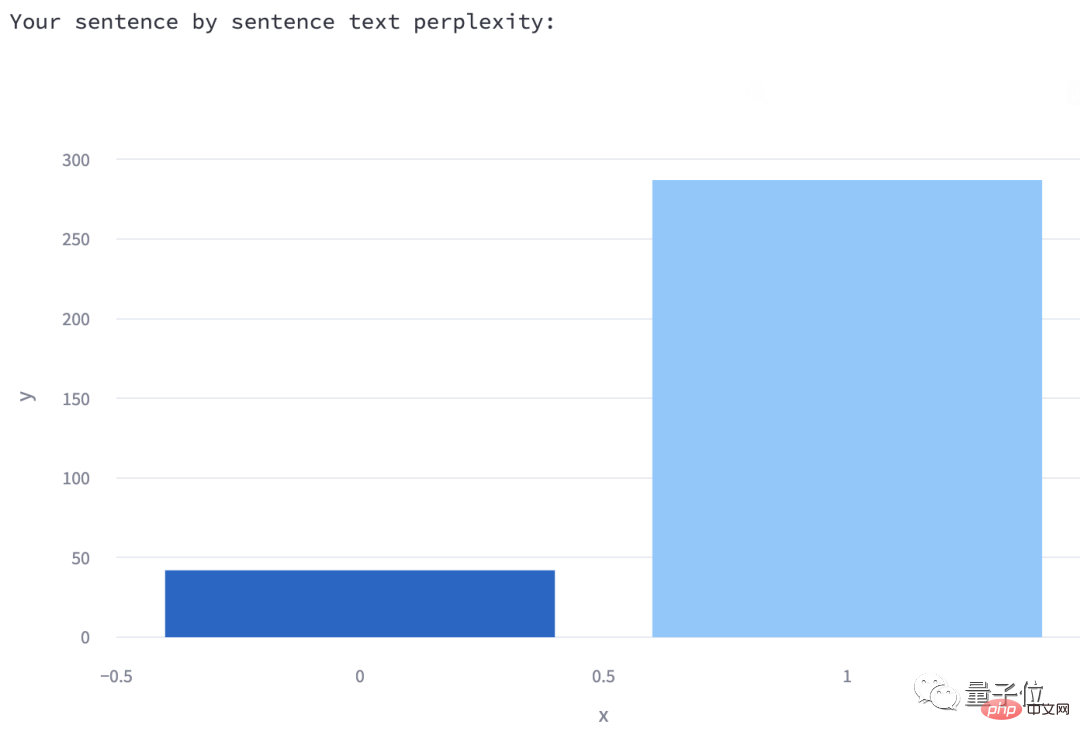
저자는 이러한 막대 차트가 그려지는 이유에 대해서도 설명했습니다.
최신 연구에 따르면 인간이 작성한 일부 문장은 혼동 정도가 낮을 수 있습니다(앞서 언급했듯이 인간의 혼란은 상대적으로 높음), 하지만 계속해서 글을 쓰다 보면 혼란은 최고조에 달할 수밖에 없습니다.
반대로 기계 생성 텍스트의 경우 당혹감이 고르게 분포되어 있으며 항상 낮습니다.
또한 GPTZero는 혼동도가 가장 높은 문장(즉, 가장 인간과 유사한 문장)을 선택합니다.

GPT 채팅 방지 추세가 붐을 일으키고 있습니다
말처럼 , 도덕이 높을수록 악마도 높아진다. ChatGPT가 다양한 무술 기술을 선보이는 가운데, GPTZero처럼 '마법으로 마법을 쓰러뜨리는' 연구와 도구도 속속 등장하고 있다.
예를 들어, 스탠포드 대학교는 최근 학생들이 ChatGPT를 사용하여 논문을 작성하거나 부정 행위를 하는 것을 방지하기 위해 "정찰 방지" 아티팩트인 DetectGPT를 출시했습니다.

이 방법은 별도의 분류기를 훈련하거나 실제 또는 생성된 구절의 데이터 세트를 수집할 필요가 없으며 확률적 곡률을 기반으로 하는 제로샷 방법입니다.
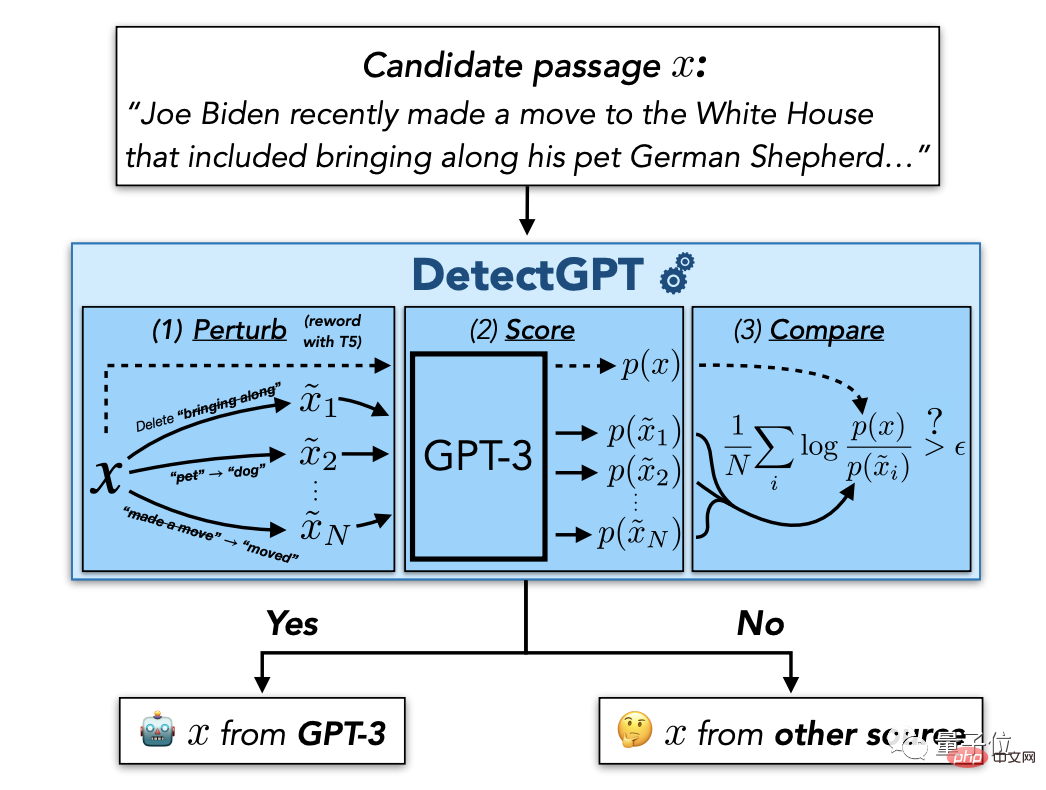
또한 OpenAI 자체도 Harvard 및 기타 대학과 협력하여 감지기인 GPT-2 출력 감지기를 만들었습니다.

저자들은 AI가 'AI 언어'와 '인간 음성'의 차이를 이해할 수 있도록 'GPT-2 생성 콘텐츠'와 WebText(특별히 외국 포스트 바인 Reddit에서 스크랩한) 데이터 세트를 공개했습니다.
이후 이 데이터 세트를 사용하여 RoBERTa 모델을 미세 조정하고 AI 검출기를 얻었습니다. 인간의 음성은 항상 True로 인식되고, AI가 생성한 콘텐츠는 항상 Fake로 인식됩니다.
(RoBERTa는 BERT의 개선된 버전입니다. 원래 BERT는 13GB 크기의 데이터 세트를 사용했지만 RoBERTa는 6,300만 개의 영어 뉴스 항목이 포함된 160GB 데이터 세트를 사용했습니다.)
… 세계를 향해 나아가는 동시에 "anti-ChatGPT" 연구의 발전도 촉진합니다.
참조 링크: [1] https://twitter.com/edward_the6/status/1619874139954905090[2] https://arxiv.org/abs/2301.11305
위 내용은 'ChatGPT Nemesis' 업그레이드: 교사는 전체 학급의 숙제를 테스트에 제출할 수 있습니다! 중국 작가: 무료로 사용 가능의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!