
인터뷰 기록 : HashMap 핵심지식, 외란함수, 부하율, 확장 연결리스트 분할

- PHPz앞으로
- 2023-05-04 17:52:06871검색
1. 머리말
Doug Lea님의 노력 덕분에 HashMap은 가장 많이 사용되고 인터뷰 대상이 되는 API가 되었습니다.
HashMap은 JDK 1.2에서 처음 등장했으며 기본 구현은 해시 알고리즘을 기반으로 합니다. HashMap은 널 키와 널 값을 허용합니다. 해시 키의 해시 값을 계산할 때 널 키 해시 값은 0입니다. HashMap은 키-값 쌍의 순서를 보장하지 않습니다. 즉, 특정 작업 후에 키-값 쌍의 순서가 변경될 수 있습니다. 또한 HashMap은 스레드로부터 안전하지 않은 클래스이므로 다중 스레드 환경에서 문제를 일으킬 수 있다는 점에 유의해야 합니다.
HashMap은 JDK 1.2에서 처음 등장했습니다. 하위 계층은 여러 세대의 최적화 및 업데이트를 통해 지금까지 더욱 복잡해졌으며 JDK 1.8에서는 다음을 포함합니다. 해시 테이블 구현, 2. 교란 기능, 3. 초기화 용량, 4. 부하 인자, 5. 용량 확장 요소 분할, 6. 연결 리스트 트리 구성, 7. 레드-블랙 트리, 8. 삽입, 9. 검색, 10. Deletion, 11. Traversal, 12. Segment lock 등은 지식 포인트가 많기 때문에, 이번 장에서는 데이터 구조의 활용에 관한 처음 5개 항목에 중점을 두고 설명하겠습니다. .
데이터 구조는 종종 수학과 분리될 수 없습니다. 학습 과정에서 실험적 검증을 위해 해당 소스 코드를 다운로드하는 것이 좋습니다. 이 과정은 약간 머리가 아플 수 있지만 학습하고 나면 이 부분의 지식을 이해할 수 있습니다. 암기하지 않고.
2. 리소스 다운로드
이 장에 포함된 소스 코드와 리소스는 doc 폴더에 있는
100,000 단어 테스트 데이터를 포함하여 doc 폴더에 있습니다.
테스트 소스코드 부분은 인터뷰-04 프로젝트에 있습니다
공개 계정을 팔로우하시면 얻으실 수 있습니다: bugstack Wormhole Stack, 다운로드 답장 {답변 후 얻은 링크를 열어서 다운로드 번호를 찾으세요: 19 }
3. 소스 코드 분석
1. 가장 간단한 HashMap 작성
HashMap을 배우기 전에 먼저 데이터를 저장하는 것이 어떤 데이터 구조인지 이해하는 것이 가장 좋습니다. 여러 버전의 HashMap을 반복한 후에도 언뜻 보면 코드가 여전히 매우 복잡합니다. 예전에는 반바지만 입었지만 이제는 긴 내복과 바람막이도 입는 것처럼요. 그럼 먼저 가장 기본적인 HashMap이 어떤 모습인지, 즉 팬티만 입었을 때 어떤 효과가 있는지 살펴보고 소스코드를 분석해 보겠습니다.
질문: 배열에 저장해야 하는 7개의 문자열 집합이 있지만 각 요소를 검색할 때의 시간 복잡도는 O(1)이 되어야 한다고 가정합니다. 즉, 루프 순회를 통해서는 얻을 수 없고, 배열 ID를 찾아 해당 요소를 직접 얻어야 합니다.
해결 방법: ID로 배열에서 요소를 가져와야 하는 경우 각 문자열에 대해 배열의 위치 ID를 계산해야 합니다. 문자열에서 ID를 얻으려면 어떤 방법을 생각할 수 있나요? 문자열에서 숫자 관련 정보를 얻는 가장 직접적인 방법은 HashCode인데, HashCode의 값 범위가 너무 커서[-2147483648, 2147483647] 바로 사용할 수 없습니다. 그런 다음 HashCode와 배열 길이를 사용하여 AND 연산을 수행하여 배열에 나타날 수 있는 위치를 가져와야 합니다. 동일한 ID를 가진 두 개의 요소가 있는 경우 두 개의 문자열이 이 배열 ID 아래에 저장됩니다.
위 내용은 실제로 문자열을 배열로 해싱하는 기본 아이디어입니다. 다음으로 이 아이디어를 코드로 구현하겠습니다.
1.1 코드 구현
// 初始化一组字符串
List<String> list = new ArrayList<>();
list.add("jlkk");
list.add("lopi");
list.add("小傅哥");
list.add("e4we");
list.add("alpo");
list.add("yhjk");
list.add("plop");
// 定义要存放的数组
String[] tab = new String[8];
// 循环存放
for (String key : list) {
int idx = key.hashCode() & (tab.length - 1);// 计算索引位置
System.out.println(String.format("key值=%s Idx=%d", key, idx));
if (null == tab[idx]) {
tab[idx] = key;
continue;
}
tab[idx] = tab[idx] + "->" + key;
}
// 输出测试结果
System.out.println(JSON.toJSONString(tab));
이 코드는 전체적으로 매우 단순해 보이고 복잡하지 않습니다. 주로 다음 내용을 포함합니다.
여기서 7개가 초기화된 문자열 집합을 초기화합니다.- 문자열을 저장할 배열을 정의하세요. 여기서 길이는 2의 세제곱인 8입니다. 이러한 배열 길이는 해싱을 위한 상위 비트를 제외하고 0111이 모두 1이라는 특성을 갖게 됩니다.
- 다음 단계는 데이터를 루프에 저장하고 배열에 있는 각 문자열의 위치를 계산하는 것입니다. key.hashCode() & (tab.length - 1).
- 문자열을 배열에 저장하는 과정에서 동일한 요소가 발견되면 연결 목록의 과정을 시뮬레이션하기 위해 연결 작업이 수행됩니다.
- 마지막으로 저장 결과를 출력합니다.
- 테스트 결과
key值=jlkk Idx=2 key值=lopi Idx=4 key值=小傅哥 Idx=7 key值=e4we Idx=5 key值=alpo Idx=2 key值=yhjk Idx=0 key值=plop Idx=5 测试结果:["yhjk",null,"jlkk->alpo",null,"lopi","e4we->plop",null,"小傅哥"]테스트 결과에서 첫 번째 단계는 배열에 있는 각 요소의 Idx를 계산하는 것이며, 반복되는 위치도 있습니다.
- 마지막은 테스트 결과의 출력입니다. 1, 3, 6, 위치가 비어 있고, 2, 5, e4we->plop에 연결된 두 개의 요소가 있습니다.
- 이것은 문자열 요소를 배열로 해싱하고 마지막으로 문자열 요소의 인덱스 ID를 통해 해당 문자열을 얻는 가장 기본적인 요구 사항 중 하나를 달성했습니다. 이것이 HashMap의 가장 기본적인 원리이다. 이를 바탕으로 하면 HashMap의 소스코드 구현을 더 쉽게 이해할 수 있을 것이다.
- 1.2 해시 해시 다이어그램
위의 테스트 결과로 데이터 구조가 잘 이해되지 않으면 다음 해시 다이어그램을 보면 쉽게 이해할 수 있습니다.
 cn 해시 해시 다이어그램
cn 해시 해시 다이어그램
- 这张图就是上面代码实现的全过程,将每一个字符串元素通过Hash计算索引位置,存放到数组中。
- 黄色的索引ID是没有元素存放、绿色的索引ID存放了一个元素、红色的索引ID存放了两个元素。
1.3 这个简单的HashMap有哪些问题
以上我们实现了一个简单的HashMap,或者说还算不上HashMap,只能算做一个散列数据存放的雏形。但这样的一个数据结构放在实际使用中,会有哪些问题呢?
- 这里所有的元素存放都需要获取一个索引位置,而如果元素的位置不够散列碰撞严重,那么就失去了散列表存放的意义,没有达到预期的性能。
- 在获取索引ID的计算公式中,需要数组长度是2的幂次方,那么怎么进行初始化这个数组大小。
- 数组越小碰撞的越大,数组越大碰撞的越小,时间与空间如何取舍。
- 目前存放7个元素,已经有两个位置都存放了2个字符串,那么链表越来越长怎么优化。
- 随着元素的不断添加,数组长度不足扩容时,怎么把原有的元素,拆分到新的位置上去。
以上这些问题可以归纳为;扰动函数、初始化容量、负载因子、扩容方法以及链表和红黑树转换的使用等。接下来我们会逐个问题进行分析。
2. 扰动函数
在HashMap存放元素时候有这样一段代码来处理哈希值,这是java 8的散列值扰动函数,用于优化散列效果;
static final int hash(Object key){
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
2.1 为什么使用扰动函数
理论上来说字符串的hashCode是一个int类型值,那可以直接作为数组下标了,且不会出现碰撞。但是这个hashCode的取值范围是[-2147483648, 2147483647],有将近40亿的长度,谁也不能把数组初始化得这么大,内存也是放不下的。
我们默认初始化的Map大小是16个长度 DEFAULT_INITIAL_CAPACITY = 1
那么,hashMap源码这里不只是直接获取哈希值,还进行了一次扰动计算,(h = key.hashCode()) ^ (h >>> 16)。把哈希值右移16位,也就正好是自己长度的一半,之后与原哈希值做异或运算,这样就混合了原哈希值中的高位和低位,增大了随机性。计算方式如下图;

bugstack.cn 扰动函数
- 说白了,使用扰动函数就是为了增加随机性,让数据元素更加均衡的散列,减少碰撞。
2.2 实验验证扰动函数
从上面的分析可以看出,扰动函数使用了哈希值的高半区和低半区做异或,混合原始哈希码的高位和低位,以此来加大低位区的随机性。
但看不到实验数据的话,这终究是一段理论,具体这段哈希值真的被增加了随机性没有,并不知道。所以这里我们要做一个实验,这个实验是这样做;
- 选取10万个单词词库
- 定义128位长度的数组格子
- 分别计算在扰动和不扰动下,10万单词的下标分配到128个格子的数量
- 统计各个格子数量,生成波动曲线。如果扰动函数下的波动曲线相对更平稳,那么证明扰动函数有效果。
扰动函数对比方法
public class Disturb {
public static int disturbHashIdx(String key, int size){
return (size - 1) & (key.hashCode() ^ (key.hashCode() >>> 16));
}
public static int hashIdx(String key, int size){
return (size - 1) & key.hashCode();
}
}
- disturbHashIdx扰动函数下,下标值计算
- hashIdx非扰动函数下,下标值计算
单元测试
// 10万单词已经初始化到words中
@Test
public void test_disturb(){
Map<Integer, Integer> map = new HashMap<>(16);
for (String word : words) {
// 使用扰动函数
int idx = Disturb.disturbHashIdx(word, 128);
// 不使用扰动函数
// int idx = Disturb.hashIdx(word, 128);
if (map.containsKey(idx)) {
Integer integer = map.get(idx);
map.put(idx, ++integer);
} else {
map.put(idx, 1);
}
}
System.out.println(map.values());
}
以上分别统计两种函数下的下标值分配,最终将统计结果放到excel中生成图表。
以上的两张图,分别是没有使用扰动函数和使用扰动函数的,下标分配。实验数据;
- 10万个不重复的单词
- 128个格子,相当于128长度的数组
未使用扰动函数

bugstack.cn 未使用扰动函数
使用扰动函数

bugstack.cn 使用扰动函数
- 从这两种的对比图可以看出来,在使用了扰动函数后,数据分配的更加均匀了。
- 数据分配均匀,也就是散列的效果更好,减少了hash的碰撞,让数据存放和获取的效率更佳。
3. 初始化容量和负载因子
接下来我们讨论下一个问题,从我们模仿HashMap的例子中以及HashMap默认的初始化大小里,都可以知道,散列数组需要一个2的幂次方的长度,因为只有2的幂次方在减1的时候,才会出现01111这样的值。
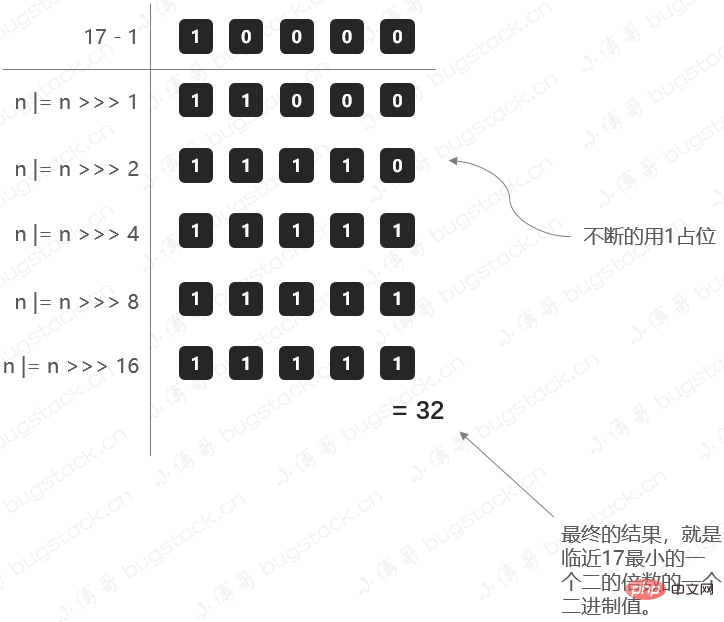
那么这里就有一个问题,我们在初始化HashMap的时候,如果传一个17个的值new HashMap(17);,它会怎么处理呢?
3.1 寻找2的幂次方最小值
在HashMap的初始化中,有这样一段方法;
public HashMap(int initialCapacity, float loadFactor){
...
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
- 阈值threshold,通过方法tableSizeFor进行计算,是根据初始化来计算的。
- 这个方法也就是要寻找比初始值大的,最小的那个2进制数值。比如传了17,我应该找到的是32(2的4次幂是16
计算阈值大小的方法;
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
- MAXIMUM_CAPACITY = 1
- 乍一看可能有点晕怎么都在向右移位1、2、4、8、16,这主要是为了把二进制的各个位置都填上1,当二进制的各个位置都是1以后,就是一个标准的2的幂次方减1了,最后把结果加1再返回即可。
那这里我们把17这样一个初始化计算阈值的过程,用图展示出来,方便理解;
bugstack.cn 计算阈值
3.2 负载因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
负载因子是做什么的?
负载因子,可以理解成一辆车可承重重量超过某个阈值时,把货放到新的车上。
那么在HashMap中,负载因子决定了数据量多少了以后进行扩容。这里要提到上面做的HashMap例子,我们准备了7个元素,但是最后还有3个位置空余,2个位置存放了2个元素。 所以可能即使你数据比数组容量大时也是不一定能正正好好的把数组占满的,而是在某些小标位置出现了大量的碰撞,只能在同一个位置用链表存放,那么这样就失去了Map数组的性能。
所以,要选择一个合理的大小下进行扩容,默认值0.75就是说当阈值容量占了3/4时赶紧扩容,减少Hash碰撞。
同时0.75是一个默认构造值,在创建HashMap也可以调整,比如你希望用更多的空间换取时间,可以把负载因子调的更小一些,减少碰撞。
4. 扩容元素拆分
为什么扩容,因为数组长度不足了。那扩容最直接的问题,就是需要把元素拆分到新的数组中。拆分元素的过程中,原jdk1.7中会需要重新计算哈希值,但是到jdk1.8中已经进行优化,不再需要重新计算,提升了拆分的性能,设计的还是非常巧妙的。
4.1 测试数据
@Test
public void test_hashMap(){
List<String> list = new ArrayList<>();
list.add("jlkk");
list.add("lopi");
list.add("jmdw");
list.add("e4we");
list.add("io98");
list.add("nmhg");
list.add("vfg6");
list.add("gfrt");
list.add("alpo");
list.add("vfbh");
list.add("bnhj");
list.add("zuio");
list.add("iu8e");
list.add("yhjk");
list.add("plop");
list.add("dd0p");
for (String key : list) {
int hash = key.hashCode() ^ (key.hashCode() >>> 16);
System.out.println("字符串:" + key + " tIdx(16):" + ((16 - 1) & hash) + " tBit值:" + Integer.toBinaryString(hash) + " - " + Integer.toBinaryString(hash & 16) + " ttIdx(32):" + ((
System.out.println(Integer.toBinaryString(key.hashCode()) +" "+ Integer.toBinaryString(hash) + " " + Integer.toBinaryString((32 - 1) & hash));
}
}
测试结果
字符串:jlkkIdx(16):3Bit值:1100011101001000010011 - 10000 Idx(32):19 1100011101001000100010 1100011101001000010011 10011 字符串:lopiIdx(16):14Bit值:1100101100011010001110 - 0 Idx(32):14 1100101100011010111100 1100101100011010001110 1110 字符串:jmdwIdx(16):7Bit值:1100011101010100100111 - 0 Idx(32):7 1100011101010100010110 1100011101010100100111 111 字符串:e4weIdx(16):3Bit值:1011101011101101010011 - 10000 Idx(32):19 1011101011101101111101 1011101011101101010011 10011 字符串:io98Idx(16):4Bit值:1100010110001011110100 - 10000 Idx(32):20 1100010110001011000101 1100010110001011110100 10100 字符串:nmhgIdx(16):13Bit值:1100111010011011001101 - 0 Idx(32):13 1100111010011011111110 1100111010011011001101 1101 字符串:vfg6Idx(16):8Bit值:1101110010111101101000 - 0 Idx(32):8 1101110010111101011111 1101110010111101101000 1000 字符串:gfrtIdx(16):1Bit值:1100000101111101010001 - 10000 Idx(32):17 1100000101111101100001 1100000101111101010001 10001 字符串:alpoIdx(16):7Bit值:1011011011101101000111 - 0 Idx(32):7 1011011011101101101010 1011011011101101000111 111 字符串:vfbhIdx(16):1Bit值:1101110010111011000001 - 0 Idx(32):1 1101110010111011110110 1101110010111011000001 1 字符串:bnhjIdx(16):0Bit值:1011100011011001100000 - 0 Idx(32):0 1011100011011001001110 1011100011011001100000 0 字符串:zuioIdx(16):8Bit值:1110010011100110011000 - 10000 Idx(32):24 1110010011100110100001 1110010011100110011000 11000 字符串:iu8eIdx(16):8Bit值:1100010111100101101000 - 0 Idx(32):8 1100010111100101011001 1100010111100101101000 1000 字符串:yhjkIdx(16):8Bit值:1110001001010010101000 - 0 Idx(32):8 1110001001010010010000 1110001001010010101000 1000 字符串:plopIdx(16):9Bit值:1101001000110011101001 - 0 Idx(32):9 1101001000110011011101 1101001000110011101001 1001 字符串:dd0pIdx(16):14Bit值:1011101111001011101110 - 0 Idx(32):14 1011101111001011000000 1011101111001011101110 1110
- 这里我们随机使用一些字符串计算他们分别在16位长度和32位长度数组下的索引分配情况,看哪些数据被重新路由到了新的地址。
- 同时,这里还可以观察出一个非常重要的信息,原哈希值与扩容新增出来的长度16,进行&运算,如果值等于0,则下标位置不变。如果不为0,那么新的位置则是原来位置上加16。{这个地方需要好好理解下,并看实验数据}
- 这样一来,就不需要在重新计算每一个数组中元素的哈希值了。
4.2 数据迁移

bugstack.cn 数据迁移
- 这张图就是原16位长度数组元素,向32位扩容后数组转移的过程。
- 对31取模保留低5位,对15取模保留低4位,两者的差异就在于第5位是否为1,是的话则需要加上增量,为0的话则不需要改变
- 其中黄色区域元素zuio因计算结果hash & oldCap低位第5位为1,则被迁移到下标位置24。
- 同时还是用重新计算哈希值的方式验证了,确实分配到24的位置,因为这是在二进制计算中补1的过程,所以可以通过上面简化的方式确定哈希值的位置。
那么为什么 e.hash & oldCap == 0 为什么可以判断当前节点是否需要移位, 而不是再次计算hash;
仍然是原始长度为16举例:
old: 10: 0000 1010 15: 0000 1111 &: 0000 1010 new: 10: 0000 1010 31: 0001 1111 &: 0000 1010
从上面的示例可以很轻易的看出, 两次indexFor()的差别只是第二次参与位于比第一次左边有一位从0变为1, 而这个变化的1刚好是oldCap, 那么只需要判断原key的hash这个位上是否为1: 若是1, 则需要移动至oldCap + i的槽位, 若为0, 则不需要移动;
这也是HashMap的长度必须保证是2的幂次方的原因, 正因为这种环环相扣的设计, HashMap.loadFactor的选值是3/4就能理解了, table.length * 3/4可以被优化为((table.length >> 2) > 2) == table.length - (table.length >> 2), JAVA的位运算比乘除的效率更高, 所以取3/4在保证hash冲突小的情况下兼顾了效率;
四、总结
- 如果你能坚持看完这部分内容,并按照文中的例子进行相应的实验验证,那么一定可以学会本章节涉及这五项知识点;1、散列表实现、2、扰动函数、3、初始化容量、4、负载因子、5、扩容元素拆分。
- 对我个人来说以前也知道这部分知识,但是没有验证过,只知道概念如此,正好借着写面试手册专栏,加深学习,用数据验证理论,让知识点可以更加深入的理解。
- 这一章节完事,下一章节继续进行HashMap的其他知识点挖掘,让懂了就是真的懂了。好了,写到这里了,感谢大家的阅读。如果某处没有描述清楚,或者有不理解的点,欢迎与我讨论交流。
위 내용은 인터뷰 기록 : HashMap 핵심지식, 외란함수, 부하율, 확장 연결리스트 분할의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!