
Apple, 'AI 건축가' GAUDI 개발: 텍스트를 기반으로 초현실적인 3D 장면 생성!

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-05-02 15:46:071615검색
요즘에는 새로운 텍스트 생성 이미지 모델이 가끔씩 출시되는데, 각각의 모델은 항상 모두를 놀라게 합니다. 이 분야는 이미 하늘에 닿았습니다. 그러나 OpenAI의 DALL-E 2나 Google의 Imagen과 같은 AI 시스템은 2차원 이미지만 생성할 수 있습니다. 텍스트도 3차원 장면으로 변환할 수 있다면 시각적 경험은 두 배가 됩니다. 이제 Apple의 AI 팀은 3D 장면 생성을 위한 최신 신경 아키텍처인 GAUDI를 출시했습니다.

복잡하고 사실적인 3D 장면 배포, 모바일 카메라의 몰입형 렌더링을 캡처하고 텍스트 프롬프트를 기반으로 3D 장면을 만들 수 있습니다! 모델명은 스페인의 유명한 건축가 안토니 가우디(Antoni Gaudi)의 이름을 따서 명명되었습니다.

논문 주소: https://arxiv.org/pdf/2207.13751.pdf
1 NeRFs를 기반으로 한 3D 렌더링
컴퓨터 그래픽과 인공 지능을 결합한 신경 렌더링이 만들어졌습니다. 2D 이미지에서 3D 모델을 생성하는 다양한 시스템. 예를 들어, Nvidia가 최근 개발한 3D MoMa는 한 시간 안에 100장 미만의 사진으로 3D 모델을 만들 수 있습니다. Google은 또한 NeRF(Neural Radiation Fields)를 사용하여 2D 위성 및 스트리트 뷰 이미지를 Google 지도의 3D 장면으로 결합하여 몰입형 뷰를 구현합니다. Google의 HumanNeRF는 동영상에서 3D 인체를 렌더링할 수도 있습니다.
현재 NeRF는 다양한 카메라 관점에서 렌더링할 수 있는 3D 모델 및 3D 장면을 위한 신경 저장 매체로 주로 사용됩니다. NeRF는 이미 가상 현실 경험에도 사용되기 시작했습니다.
그렇다면 다양한 카메라 각도에서 이미지를 사실적으로 렌더링하는 강력한 기능을 갖춘 NeRF를 생성 AI에 사용할 수 있을까요? 물론 3D 장면을 생성하려고 시도한 연구팀이 있습니다. 예를 들어 Google은 작년에 처음으로 NeRF의 3D 뷰 생성 기능과 OpenAI의 CLIP 평가 기능을 결합한 AI 시스템을 출시했습니다. 이미지 콘텐츠를 생성하고 최종적으로 NeRF 매칭 텍스트 설명을 생성하는 기능을 달성합니다. ㅋㅋㅋ 어려움. 가장 큰 어려움은 카메라 위치에 큰 제한이 있다는 것입니다. 단일 개체의 경우 가능한 모든 카메라 위치를 돔에 매핑할 수 있지만 3D 장면에서는 카메라 위치가 개체의 영향을 받습니다. 벽 등 장애물 제한. 장면 생성 시 이러한 요소를 고려하지 않으면 3D 장면을 생성하기가 어렵습니다.
2 카메라 포즈는 3D 형상 및 장면의 모양과 분리되어 카메라의 예상 위치를 예측하고 출력이 3D 장면 아키텍처에 유효한 위치인지 확인할 수 있습니다. 
캡션: 디코더 모델 아키텍처
장면에 대한
장면 디코더는 3D 캔버스인 3차원 평면의 표현을 예측할 수 있습니다.
그런 다음 Radiation Field Decoder는 이 캔버스의 볼륨 렌더링 방정식을 사용하여 후속 이미지를 그립니다.
GAUDI의 3D 생성은 두 단계로 구성됩니다. 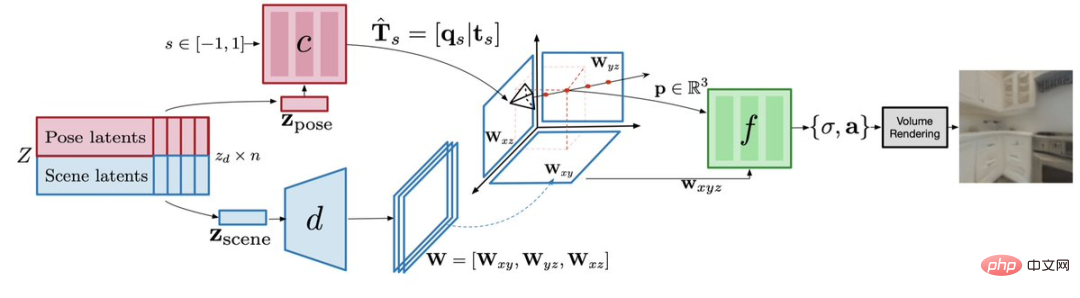
하나는 잠재 및 네트워크 매개변수의 최적화입니다. 3D 방사선장과 수천 개의 궤적에 대한 해당 카메라 포즈를 인코딩하는 잠재 표현을 학습합니다. 단일 객체와 달리 장면에 따라 효과적인 카메라 포즈가 달라지므로 각 장면마다 유효한 카메라 포즈를 인코딩해야 합니다.
두 번째는 확산 모델을 사용하여 잠재 표현에 대한 생성 모델을 학습함으로써 조건 추론 작업과 무조건 추론 작업 모두에서 잘 모델링할 수 있다는 것입니다. 전자는 텍스트나 이미지 프롬프트를 기반으로 3D 장면을 생성하는 반면, 후자는 카메라 궤적을 기반으로 3D 장면을 생성합니다.
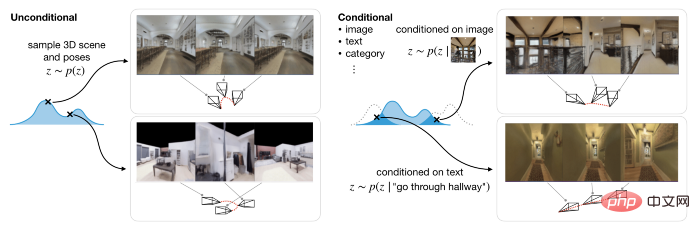
3D 실내 장면을 통해 GAUDI는 새로운 카메라 움직임을 생성할 수 있습니다. 아래의 일부 예에서와 같이 텍스트 설명에는 장면 및 탐색 경로에 대한 정보가 포함됩니다. 여기서 연구팀은 사전 훈련된 RoBERTa 기반 텍스트 인코더를 채택하고 중간 표현을 사용하여 확산 모델을 조정했습니다. 생성된 효과는 다음과 같습니다. 텍스트 프롬프트: Walk into the kitchen

텍스트 프롬프트: Go upstairs

텍스트 프롬프트: 복도를 따라 걷기

또한 사전 훈련된 ResNet-18을 이미지 인코더로 사용하여 GAUDI는 주어진 이미지의 방사선장을 샘플링할 수 있습니다. 임의의 시점에서 관찰하여 이미지 큐에서 3D 장면을 만듭니다. 이미지 팁:

3D 장면 생성:

이미지 팁:

3D 장면 생성:

네 가지 데이터에 대한 연구자들의 실험이 진행됩니다. 실내 스캐닝 데이터 세트 ARKitScences를 포함한 ARKitScences 데이터 세트에 대해 GAUDI가 학습된 뷰를 재구성하고 기존 방법의 품질과 일치할 수 있음을 보여줍니다. 수천 개의 실내 장면에 대해 수십만 개의 이미지로 3D 장면을 제작하는 거대한 작업에서도 GAUDI는 모드 붕괴나 방향 문제를 겪지 않았습니다.
GAUDI는 많은 컴퓨터 비전 작업에 영향을 미칠 뿐만 아니라 3D 장면 생성 기능은 모델 기반 강화 학습 및 계획, SLAM, 3D 콘텐츠 제작과 같은 연구 분야에도 도움이 될 것입니다.
현재 GAUDI에서 생성한 영상의 품질은 높지 않으며 많은 유물을 볼 수 있습니다. 하지만 이 시스템은 3D 객체와 장면을 렌더링하기 위한 Apple의 현재 AI 시스템의 좋은 시작이자 기반이 될 수 있습니다. GAUDI는 디지털 위치 생성을 위해 Apple의 XR 헤드셋에도 적용될 것이라고 합니다. 기대하셔도 좋습니다~
위 내용은 Apple, 'AI 건축가' GAUDI 개발: 텍스트를 기반으로 초현실적인 3D 장면 생성!의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!