
하나의 기사에서 모든 SOTA 생성 모델을 읽어보세요. 9개 카테고리의 21개 모델에 대한 전체 리뷰입니다!

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-05-02 15:43:072229검색
지난 2년 동안 AI 업계에서는 대규모 생성 모델 출시가 급증했으며, 특히 Stable Diffusion의 오픈소스와 ChatGPT의 오픈 인터페이스가 업계의 열기를 더욱 자극한 이후 더욱 그렇습니다. 생성 모델의 경우.
하지만 생성 모델의 종류가 많고 출시 속도가 매우 빠릅니다. 조심하지 않으면 sota를 놓칠 수도 있습니다
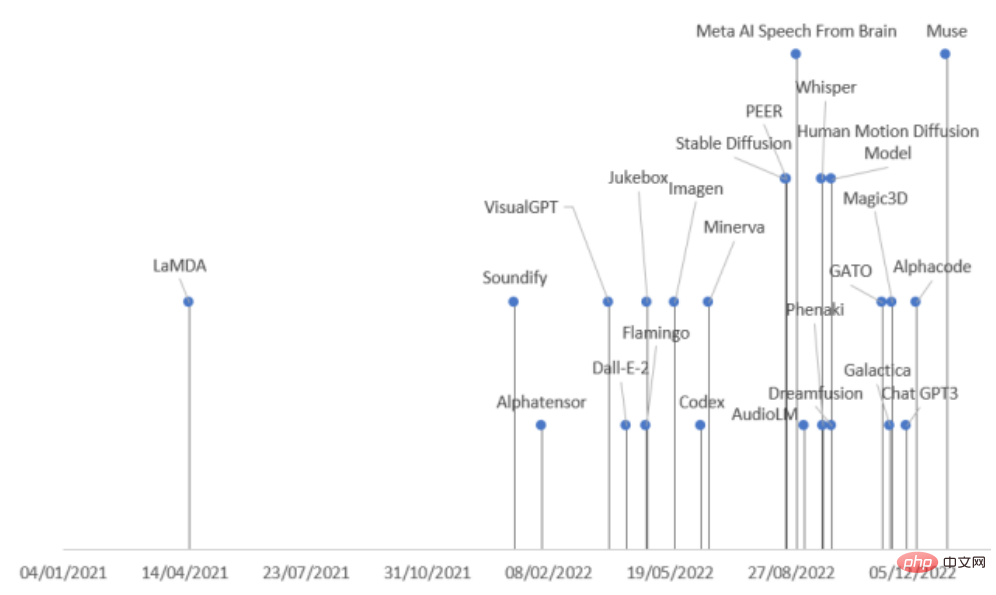
최근 스페인 Pontifical University of Comillas의 연구원들이 종합적인 검토를 실시했습니다. 다양한 분야의 AI 최신 진전은 생성 모델을 작업 모드와 분야에 따라 9가지 카테고리로 나누고, 2022년에 출시된 생성 모델 21개를 요약해 생성 모델의 개발 맥락을 한 번에 이해할 수 있게 해준다!

논문 링크: https://arxiv.org/abs/2301.04655
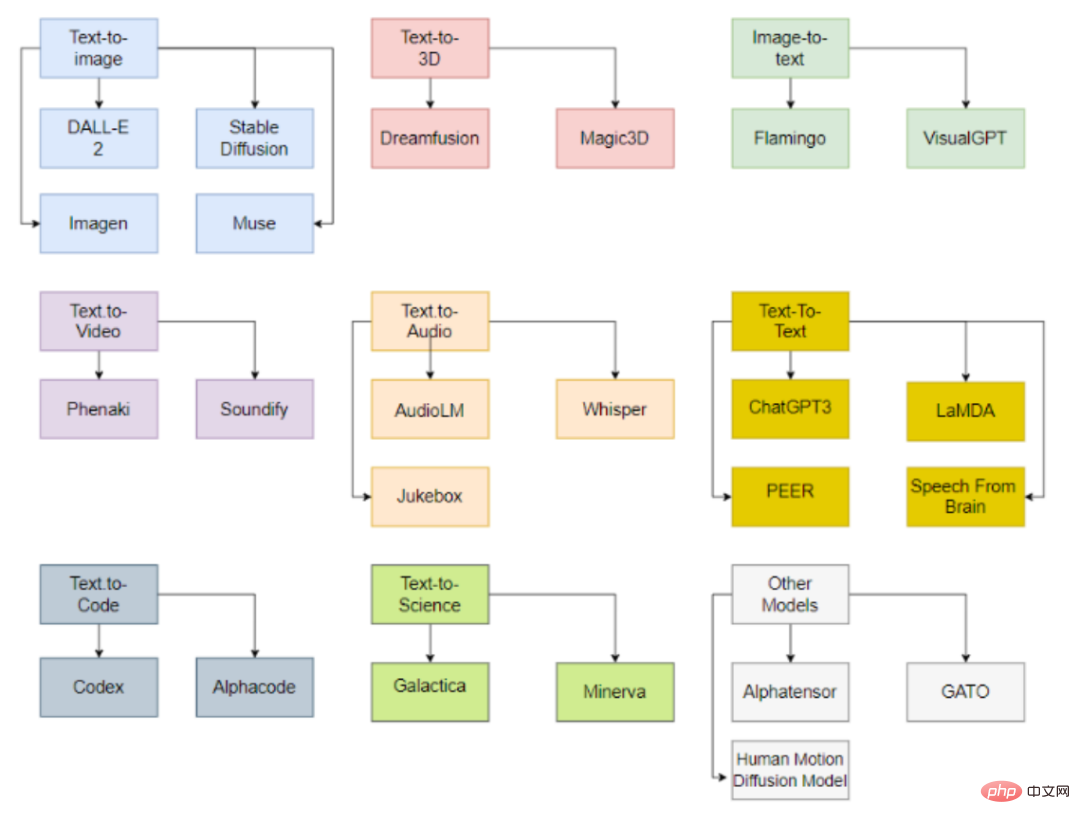
Generative AI classification
모델은 입력 및 출력 데이터 유형에 따라 분류할 수 있으며 현재 주로 9개 범주를 포함합니다.
흥미롭게도 이러한 대규모 공개 모델 뒤에는 6개 조직(OpenAI, Google, DeepMind, Meta, runway, Nvidia)만이 이러한 최첨단 모델 배포에 참여하고 있습니다.
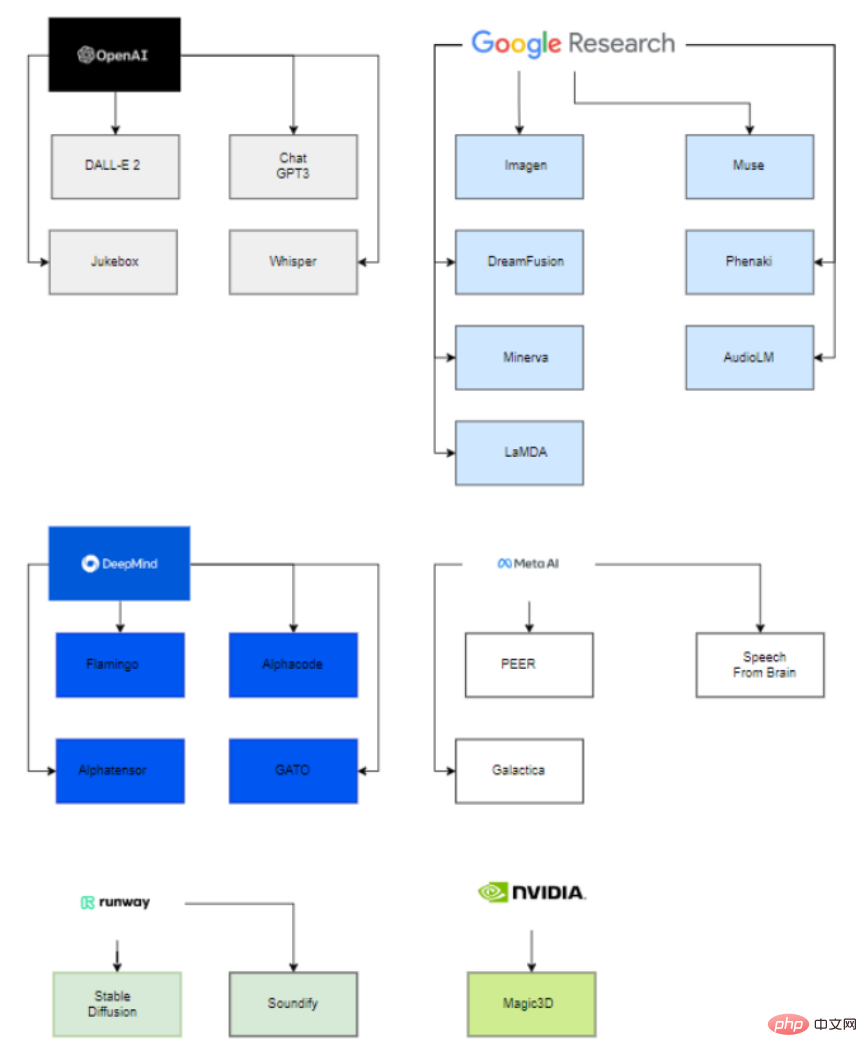
주된 이유는 이러한 모델의 매개변수를 추정할 수 있으려면 매우 큰 컴퓨팅 능력과 데이터 과학 및 데이터 엔지니어링에 대한 고도로 숙련되고 경험이 풍부한 팀이 필요하기 때문입니다.
따라서 인수된 스타트업과 학계와의 협력을 통해 이러한 회사만이 생성 AI 모델을 성공적으로 배포할 수 있습니다.
스타트업에 참여하는 대기업의 경우 Microsoft는 OpenAI에 10억 달러를 투자하고 모델 개발을 돕는 것으로 볼 수 있습니다. 마찬가지로 Google은 2014년에 Deepmind를 인수했습니다.
대학 측면에서는 VisualGPT가 King Abdullah University of Science and Technology(KAUST), Carnegie Mellon University 및 Nanyang Technological University에서 개발되었으며, Human Motion Diffusion 모델은 이스라엘 Tel Aviv University에서 개발되었습니다.
마찬가지로 Stable Diffusion은 Runway, Stability AI, Soundify는 Runway, Carnegie Mellon University는 Google과 California University에서 개발하는 등 다른 프로젝트도 회사와 대학에서 개발합니다. 버클리 협업.
텍스트-이미지 모델
DALL-E 2
OpenAI에서 개발한 DALL-E 2는 텍스트 설명으로 구성된 프롬프트에서 독창적이고 사실적이며 사실적인 이미지와 예술을 생성할 수 있으며 OpenAI는 이를 모델에 액세스하기 위한 공개 API입니다.
DALL-E 2의 특별한 점은 개념, 속성 및 다양한 스타일을 결합하는 능력입니다. 이 능력은 사전 훈련된 언어-이미지 모델 CLIP 신경망에서 파생되므로 자연어를 사용하여 가장 많은 것을 나타낼 수 있습니다. 관련 텍스트 조각.
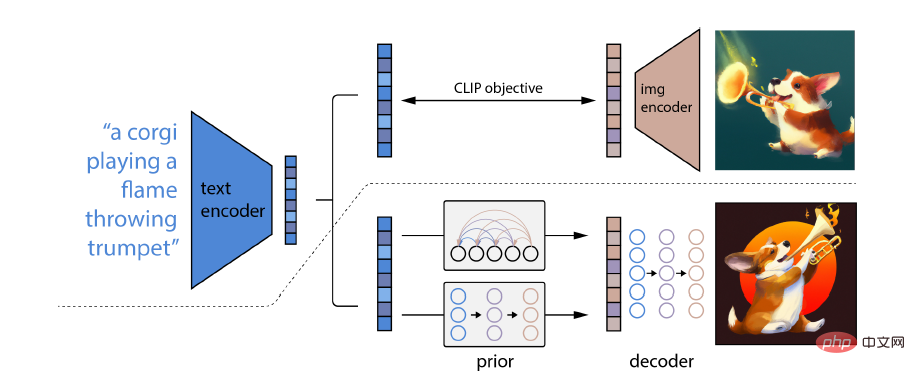
특히 CLIP 임베딩에는 몇 가지 바람직한 특성이 있습니다. 이미지 분포를 안정적으로 변환할 수 있으며 강력한 제로샷 기능이 있으며 미세 조정 후 최첨단 결과를 얻을 수 있습니다.
완전한 이미지 생성 모델을 얻으려면 CLIP 이미지 임베딩 디코더 모듈을 이전 모델과 결합하여 주어진 텍스트 캡션에서 관련 CLIP 이미지 임베딩을 생성합니다.

다른 모델에는 Imagen, Stable Diffusion, Muse
Text가 포함됩니다. -to-3D 모델
일부 산업에서는 2D 이미지만 생성할 수 있고 자동화가 완료되지 않습니다. 예를 들어 게임 분야에서는 3D 모델을 생성해야 합니다.
Dreamfusion
DreamFusion은 Google Research에서 개발했으며 텍스트-3D 합성을 위해 사전 훈련된 2D 텍스트-이미지 확산 모델을 사용합니다.
Dreamfusion은 CLIP 기법을 2차원 확산 모델의 증류에서 얻은 손실로 대체합니다. 즉, 확산 모델을 일반적인 연속 최적화 문제에서 손실로 사용하여 샘플을 생성할 수 있습니다.

주로 픽셀을 샘플링하는 다른 방법과 비교할 때, DreamFusion은 임의의 각도에서 렌더링되는 이미지를 만드는 데 초점을 맞춘 미분 가능 생성기를 사용합니다.

Magic3D와 같은 다른 모델은 NVIDIA에서 개발합니다.
이미지-텍스트 모델
이미지 생성의 역 버전과 동일한 이미지를 설명하는 텍스트를 얻는 것도 유용합니다.
Flamingo
Deepmind에서 개발한 이 모델은 입력/출력 예제의 몇 가지 프롬프트만으로 개방형 시각적 언어 작업에 대한 퓨샷 학습을 수행할 수 있습니다.
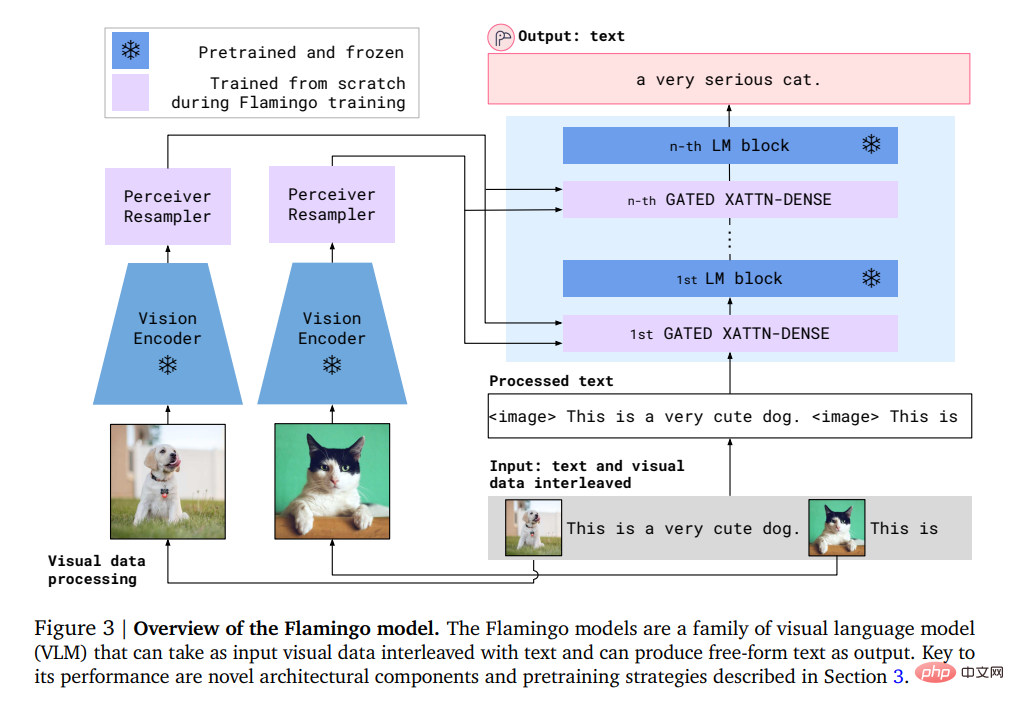
특히 Flamingo의 입력에는 시각적 조건 하에서 자동 회귀 텍스트 생성 모델이 포함되어 있습니다. 이 모델은 이미지나 비디오가 인터리브된 일련의 텍스트 토큰을 수신하고 텍스트를 출력으로 생성할 수 있습니다.
사용자가 모델에 쿼리를 입력하고 사진이나 동영상을 첨부하면 모델이 텍스트 답변으로 답변합니다.

Flamingo 모델은 두 가지 보완 모델, 즉 시각적 장면을 분석하는 시각적 모델과 기본 형태의 추론을 수행하는 대규모 언어 모델을 활용합니다.
VisualGPT
VisualGPT는 사전 훈련된 언어 모델 GPT-2의 지식을 활용할 수 있는 OpenAI에서 개발한 이미지 설명 모델입니다.
다양한 양식 간의 의미적 격차를 해소하기 위해 연구원들은 정류 게이팅 기능을 갖춘 새로운 인코더-디코더 주의 메커니즘을 설계했습니다.

VisualGPT의 가장 큰 장점은 텍스트 모델에 다른 이미지만큼 많은 데이터가 필요하지 않고, 이미지 설명 모델의 데이터 효율성을 향상시킬 수 있으며, 틈새 분야에 적용하거나 희귀한 개체를 설명할 수 있다는 것입니다.
텍스트-비디오 모델
Phenaki
이 모델은 Google Research에서 개발 및 생산되었으며 일련의 텍스트 프롬프트가 제공되면 실제 비디오 합성을 수행할 수 있습니다.
Phenaki는 오픈 도메인 시간 변수 큐에서 비디오를 생성할 수 있는 최초의 모델입니다.
데이터 문제를 해결하기 위해 연구원들은 대규모 이미지-텍스트 쌍 데이터 세트와 더 적은 수의 비디오-텍스트 예제에 대해 공동 교육을 실시했으며 마침내 비디오 데이터 세트를 넘어서는 일반화 기능을 달성했습니다.
주로 이미지-텍스트 데이터세트는 수십억 개의 입력 데이터를 갖는 경향이 있는 반면, 텍스트-비디오 데이터세트는 훨씬 더 작고, 다양한 길이의 비디오를 컴퓨팅하는 것도 어려운 문제입니다.

Phenaki 모델은 C-ViViT 인코더, 트레이닝 트랜스포머, 비디오 생성기의 세 부분으로 구성됩니다.
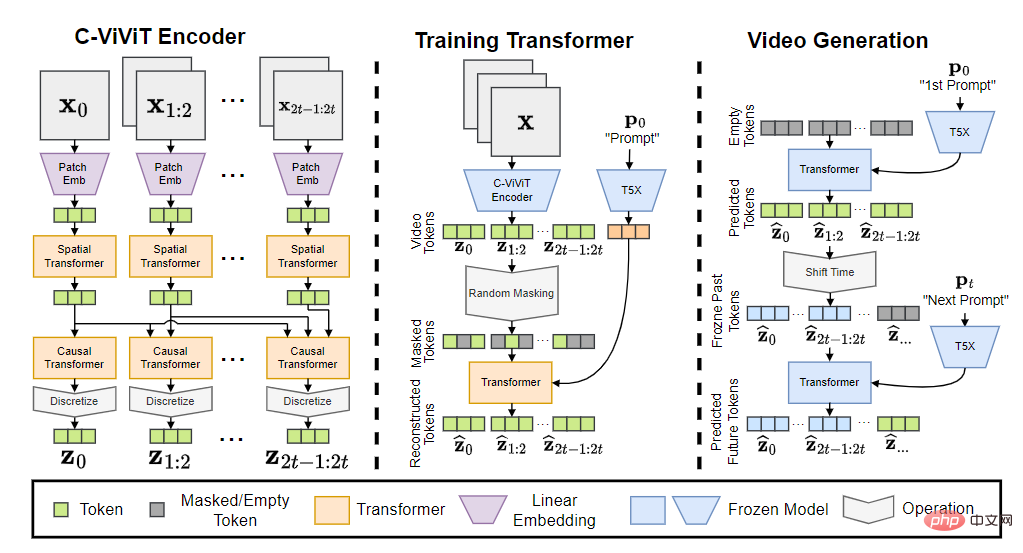
입력 토큰을 임베딩으로 변환한 후 시간 변환기와 공간 변환기를 통과한 다음 활성화 없이 단일 선형 투영을 사용하여 토큰을 픽셀 공간에 다시 매핑합니다.
최종 모델은 오픈 도메인 큐에 따라 시간적 일관성과 다양성을 갖춘 비디오를 생성할 수 있으며 데이터 세트에 존재하지 않는 몇 가지 새로운 개념도 처리할 수 있습니다.
관련 모델로는 Soundify가 있습니다.
Text-to-Audio 모델
영상 제작에 있어서 사운드도 빼놓을 수 없는 부분입니다.
AudioLM
이 모델은 Google에서 개발했으며 장거리 일관성을 갖춘 고품질 오디오를 생성하는 데 사용할 수 있습니다.
AudioLM의 특별한 점은 입력 오디오를 개별 토큰 시퀀스에 매핑하고 이 표현 공간에서 오디오 생성을 언어 모델링 작업으로 사용한다는 것입니다.
AudioLM은 원시 오디오 파형의 대규모 자료에 대한 교육을 통해 간단한 안내에 따라 자연스럽고 일관적인 연속 음성을 생성하는 방법을 성공적으로 배웠습니다. 이 방법은 훈련 중에 상징적 표현을 추가하지 않고도 인간의 목소리가 아닌 연속적인 피아노 음악 등의 음성으로 확장될 수도 있습니다.
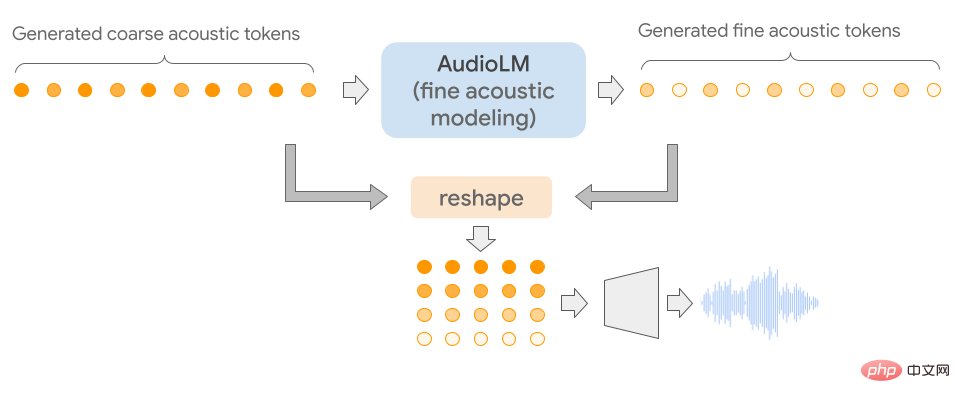
오디오 신호에는 여러 스케일의 추상화가 포함되므로 오디오 합성 중에 일관성을 보이면서 여러 스케일에서 높은 오디오 품질을 달성하는 것은 매우 어렵습니다. AudioLM 모델은 신경 오디오 압축, 자기 지도 표현 학습 및 언어 모델링의 최신 기술을 결합하여 구현됩니다.
주관적 평가를 위해 평가자는 10초 동안 샘플을 듣고 사람의 음성인지 합성 음성인지 판단하게 됩니다. 수집된 1000개의 평가를 기준으로 비율은 51.2%이며 이는 무작위로 할당된 라벨과 통계적으로 다르지 않습니다. 즉, 인간은 합성 샘플과 실제 샘플을 구별할 수 없습니다.
다른 관련 모델로는 Jukebox 및 Whisper가 있습니다.
Text-to-Text 모델
질문 및 답변 작업에 일반적으로 사용됩니다.
ChatGPT
OpenAI에서 개발한 인기 있는 ChatGPT는 대화 방식으로 사용자와 상호 작용합니다.
사용자가 질문이나 프롬프트 텍스트의 전반부를 요청하면 모델은 후속 부분을 완료하고 잘못된 입력 전제 조건을 식별하고 부적절한 요청을 거부할 수 있습니다.
구체적으로 ChatGPT의 알고리즘은 Transformer이며, 훈련 과정은 주로 인간 피드백을 기반으로 한 강화 학습입니다.
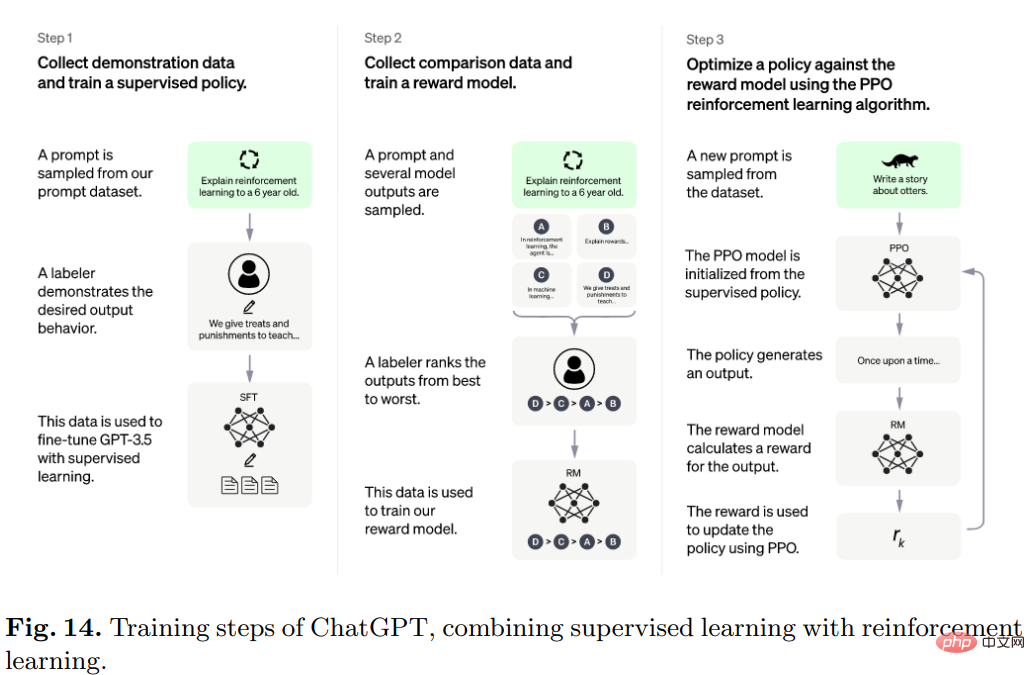
초기 모델은 지도 학습 하에서 미세 조정을 사용하여 학습되고, 인간은 사용자와 AI 보조자 역할을 서로에게 대화를 제공한 다음 모델이 반환한 응답을 수정하여 사용합니다. 정답은 모델을 개선하는 데 도움이 됩니다.
제작된 데이터세트를 InstructGPT의 데이터세트와 혼합하고 대화형 형식으로 변환하세요.
다른 관련 모델로는 LaMDA 및 PEER가 있습니다.
Text-to-Code 모델
은 특별한 유형의 텍스트, 즉 코드를 생성한다는 점을 제외하면 text-to-text와 유사합니다.
Codex
OpenAI에서 개발한 이 모델은 텍스트를 코드로 번역할 수 있습니다.
Codex는 기본적으로 모든 프로그래밍 작업에 적용할 수 있는 일반 프로그래밍 모델입니다.
프로그래밍 시 인간 활동은 두 부분으로 나눌 수 있습니다. 1) 문제를 더 간단한 문제로 분해하고, 2) 이러한 문제를 기존 코드(라이브러리, API 또는 함수)에 매핑합니다.
두 번째 부분은 프로그래머들이 가장 시간을 많이 낭비하는 부분이면서 Codex가 가장 잘하는 부분이기도 합니다.
교육 데이터는 2020년 5월 GitHub에 호스팅된 공개 소프트웨어 저장소에서 수집되었으며, 179GB의 Python 파일이 포함되어 있고 이미 강력한 자연어 표현이 포함되어 있는 GPT-3을 기반으로 미세 조정되었습니다.
관련 모델에는 Alphacode도 포함됩니다
Text-to-Science 모델
과학 연구 텍스트도 AI 텍스트 생성의 목표 중 하나이지만, 아직 성과를 얻기까지는 갈 길이 멉니다.
Galaxica
이 모델은 Meta AI와 Papers with Code가 공동 개발했으며 대규모 과학 텍스트 모델을 자동으로 구성하는 데 사용할 수 있습니다.
Galactica의 가장 큰 장점은 여러 에피소드를 훈련한 후에도 모델이 여전히 과적합되지 않으며 토큰을 반복적으로 사용하면 업스트림 및 다운스트림 성능이 향상된다는 것입니다.
모든 데이터가 공통 마크다운 형식으로 처리되어 다양한 소스의 지식을 혼합할 수 있으므로 데이터 세트의 설계는 이 접근 방식에 매우 중요합니다.
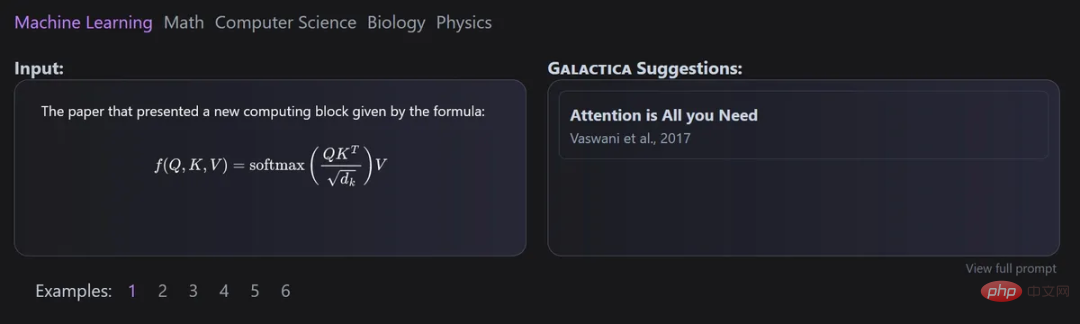
인용은 특정 토큰을 통해 처리되므로 연구자는 모든 입력 상황에서 인용을 예측할 수 있습니다. 인용을 예측하는 Galactica 모델의 능력은 규모에 따라 증가합니다.
또한 이 모델은 모든 크기의 모델에 대해 GeLU 활성화가 포함된 디코더 전용 설정에서 Transformer 아키텍처를 사용하여 SMILES 화학 공식 및 단백질 서열과 관련된 다중 모드 작업을 수행할 수 있습니다.
Minerva
메인 미네르바의 목적은 수학적, 과학적 문제를 해결하는 것입니다. 이를 위해 대량의 훈련 데이터를 수집하고 정량적 추론 문제, 대규모 모델 개발 문제를 해결하고 일류 추론 기술을 채택했습니다.
Minerva 샘플링 언어 모델 아키텍처는 단계별 추론을 사용하여 입력 문제를 해결합니다. 즉, 입력에는 외부 도구를 도입하지 않고 계산 및 기호 연산이 포함되어야 합니다.
기타 모델
앞서 언급한 카테고리에 속하지 않는 모델도 있습니다.
AlphaTensor
Deepmind가 개발한 이 모델은 새로운 알고리즘을 발견하는 능력으로 인해 업계에서 완전히 혁신적인 모델입니다.
게시된 예에서 AlphaTensor는 보다 효율적인 행렬 곱셈 알고리즘을 만들었습니다. 이 알고리즘은 매우 중요하므로 신경망부터 과학 컴퓨팅 프로그램까지 모든 것이 이 효율적인 곱셈 계산의 이점을 누릴 수 있습니다.
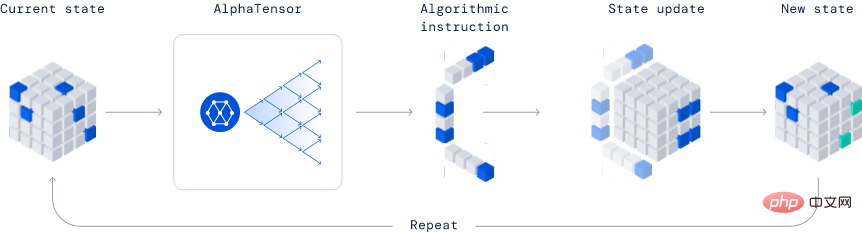
이 방법은 Deep Reinforcement Learning 방법을 기반으로 하며, AlphaTensor 에이전트의 훈련 과정은 싱글 플레이어 게임을 플레이하는 것이며 목표는 제한된 요소 공간에서 텐서 분해를 찾는 것입니다.
TensorGame의 각 단계에서 플레이어는 행렬의 다양한 항목을 결합하여 곱셈을 수행하는 방법을 선택하고 올바른 곱셈 결과를 얻는 데 필요한 연산 수에 따라 보너스 포인트를 획득해야 합니다. AlphaTensor는 특수 신경망 아키텍처를 사용하여 합성 훈련 게임의 대칭성을 활용합니다.
GATO
이 모델은 Deepmind가 개발한 일반 에이전트로 다중 모드, 다중 작업 또는 다중 구현 일반화 전략으로 사용할 수 있습니다.
같은 무게를 지닌 동일한 네트워크는 Atari 게임 플레이, 사진 설명, 채팅, 블록 쌓기 등 매우 다양한 기능을 호스팅할 수 있습니다.
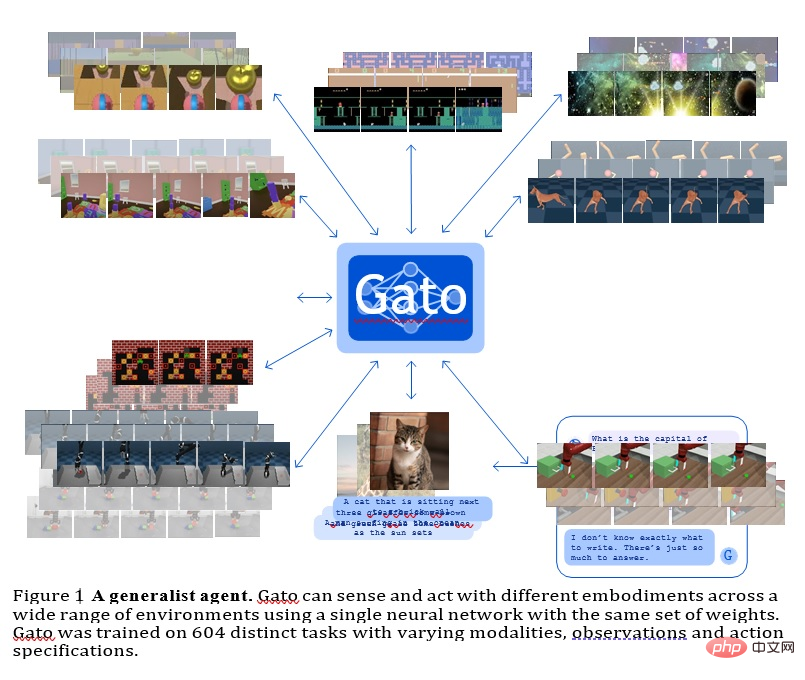
모든 작업에서 단일 신경 시퀀스 모델을 사용하면 많은 이점이 있습니다. 자체 귀납적 편향을 사용하여 전략적 모델을 직접 제작할 필요성이 줄어들고 훈련 데이터의 양과 다양성이 늘어납니다.
이 범용 에이전트는 많은 작업에 성공하며, 추가 데이터를 거의 추가하지 않고도 조정하여 더 많은 작업에 성공할 수 있습니다.
현재 GATO에는 실제 로봇의 모델 규모를 실시간으로 제어할 수 있는 약 12억 개의 매개변수가 있습니다.
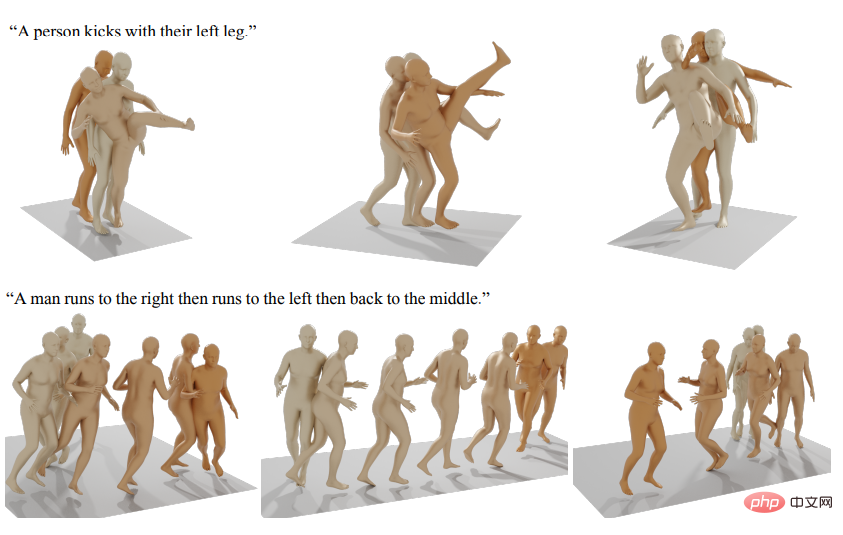
다른 생성 인공 지능 모델에는 인간 동작 생성 등이 포함됩니다.
참고자료: https://arxiv.org/abs/2301.04655
위 내용은 하나의 기사에서 모든 SOTA 생성 모델을 읽어보세요. 9개 카테고리의 21개 모델에 대한 전체 리뷰입니다!의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!