
ChatGLM 사용 시 함정을 피하기 위한 몇 가지 팁

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-05-02 13:58:062232검색
어제 데이터 기술 카니발에서 돌아온 후 ChatGLM 세트를 배포하고 데이터베이스 운영 및 유지 관리 지식 기반을 교육하기 위해 대규모 언어 모델 사용을 연구할 계획이라고 말했는데 많은 친구들이 이미 그것을 믿지 않았습니다. 당신 나이, 라오 바이, 아직도 이런 것들을 던질 수 있습니까? 이 친구들의 의심을 풀기 위해 오늘은 지난 이틀 동안 ChatGLM을 던지는 과정을 여러분과 공유하고, ChatGLM 던지기에 관심이 있는 친구들을 위해 함정을 피하는 몇 가지 팁도 공유하겠습니다.
ChatGLM-6B는 2023년 칭화대학교 KEG 연구소와 Zhipu AI가 공동으로 훈련한 언어 모델 GLM을 기반으로 개발되었습니다. 사용자의 질문과 요구 사항에 적절한 응답과 지원을 제공하는 대규모 언어 모델입니다. 위의 답변은 ChatGLM 자체에서 답변한 것입니다. GLM-6B는 62억 개의 매개변수를 갖춘 오픈 소스 사전 학습 모델이며 상대적으로 작은 하드웨어 환경에서 로컬로 실행할 수 있다는 것이 특징입니다. 이 기능을 사용하면 대규모 언어 모델을 기반으로 하는 애플리케이션이 수천 가구에 들어갈 수 있습니다. KEG 연구소의 목적은 더 큰 GLM-130B 모델(GPT-3.5에 해당하는 1,300억 개의 매개변수)을 8방향 RTX 3090을 사용하여 저가형 환경에서 교육할 수 있도록 하는 것입니다.
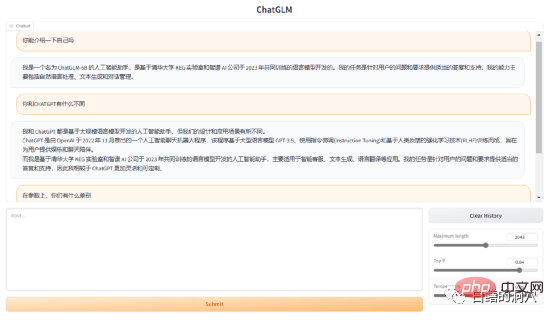
이 목표가 실제로 달성될 수 있다면 대규모 언어 모델을 기반으로 일부 애플리케이션을 만들고 싶은 사람들에게 확실히 좋은 소식이 될 것입니다. ChatGLP-6B의 현재 FP16 모델은 13G가 조금 넘는 수준이고, INT-4 양자화 모델은 4GB 미만이며 비디오 메모리가 6GB인 RTX 3060TI에서 실행할 수 있습니다.
배포 전에는 이런 상황을 잘 몰랐기 때문에 높지도 낮지도 않은 12GB RTX 3060을 구입해서 설치와 배포를 완료한 후에도 FP16 모델을 아직 실행하지 못했습니다. 집에서 테스트하고 검증하는 방법을 더 잘 알았더라면 그냥 더 저렴한 3060TI를 샀을 거에요. 무손실 FP16 모델을 실행하려면 24GB 비디오 메모리를 갖춘 3090을 구입해야 합니다.
자신의 컴퓨터에서 ChatGLP-6B의 기능을 테스트하려는 경우 THUDM/ChatGLM-6B 모델을 직접 다운로드할 필요가 없을 수도 있습니다. Huggingface에 일부 패키지된 정량 모델이 있을 수 있습니다. 다운로드되었습니다. 모델 다운로드 속도가 매우 느리므로 int4 정량 모델을 직접 다운로드할 수 있습니다.
12G 비디오 메모리가 탑재된 RTX 3060 그래픽 카드가 장착된 I7 8코어 PC에서 이 설치를 완료했습니다. 이 컴퓨터는 제 업무용 컴퓨터이기 때문에 WSL 하위 시스템에 ChatGLM을 설치했습니다. WINDOWS WSL 하위 시스템에 ChatGLM을 설치하는 것은 LINUX 환경에 직접 설치하는 것보다 더 복잡합니다. 가장 큰 함정은 그래픽 카드 드라이버 설치입니다. ChatGLM을 Linux에 직접 배포하는 경우 NVIDIA 드라이버를 직접 설치하고 modprobe를 통해 네트워크 카드 드라이버를 활성화해야 합니다. WSL에 설치하는 것은 상당히 다릅니다.
ChatGLM은 github에서 다운로드할 수 있으며 웹사이트에는 WINDOWS WSL에 ChatGLM을 배포하기 위한 문서를 포함하여 몇 가지 간단한 문서가 있습니다. 그러나 이 분야의 초보자이고 이 문서에 따라 완전히 배포하면 수많은 함정에 직면하게 됩니다.
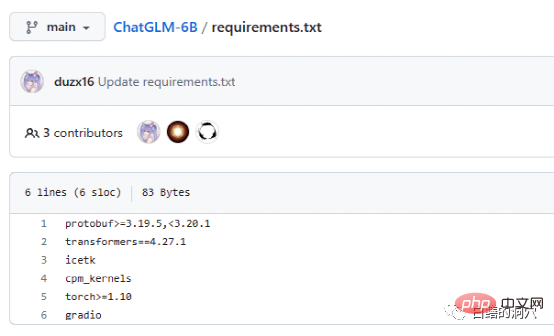
Requriements.txt 문서에는 ChatGLM에서 사용하는 주요 오픈 소스 구성 요소의 목록과 버전 번호가 나열되어 있습니다. 핵심은 변환기이며, 실제로 요구 사항은 그다지 엄격하지 않습니다. 그리고 조금 낮으면 괜찮습니다. 큰 문제이지만 안전상의 이유로 같은 버전을 사용하는 것이 좋습니다. Icetk는 토큰 처리용이고, cpm_kernels는 중국 처리 모델 및 cuda의 핵심 호출이며, protobuf는 구조화된 데이터 저장용입니다. Gradio는 Python을 사용하여 AI 애플리케이션을 빠르게 생성하기 위한 프레임워크입니다. Torch에 대한 소개는 필요하지 않습니다.
ChatGLM은 GPU가 없는 환경에서도 CPU와 32GB의 물리 메모리를 사용해 구동할 수 있지만, 구동 속도가 매우 느려 시연 검증용으로만 사용할 수 있습니다. ChatGLM을 플레이하려면 GPU를 장착하는 것이 가장 좋습니다.
WSL에 ChatGLM을 설치할 때 가장 큰 함정은 그래픽 카드 드라이버입니다. Git의 ChatGLM에 대한 문서는 이 프로젝트에 대해 잘 모르거나 그러한 배포를 한 번도 해본 적이 없는 사람들에게는 매우 혼란스럽습니다. 사실 소프트웨어 배포는 번거롭지 않지만 그래픽 카드 드라이버는 매우 까다롭습니다.
WSL 하위 시스템에 배포되기 때문에 LINUX는 완전한 LINUX가 아닌 에뮬레이션 시스템일 뿐입니다. 따라서 NVIDIA 그래픽 드라이버는 WINDOWS에만 설치하면 되며 WSL에서 활성화할 필요가 없습니다. 그러나 WSL의 LINUX 가상 환경에는 CUDA TOOLS를 설치해야 합니다. WINDOWS의 NVIDIA 드라이버는 공식 홈페이지에서 최신 드라이버를 설치해야 하며, WIN10/11과 함께 제공되는 호환 드라이버를 사용할 수 없으므로, 공식 홈페이지에서 최신 드라이버를 다운로드하여 설치하는 것을 생략하지 마세요.
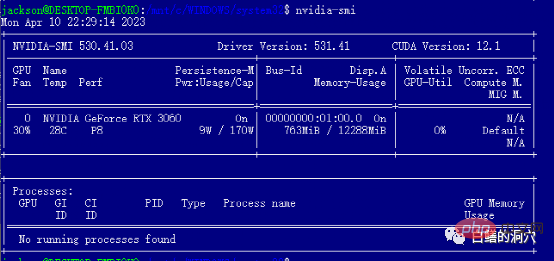
WIN 드라이버를 설치한 후 WSL에 직접 cuda 도구를 설치할 수 있습니다. 설치 후 nvidia-smi를 실행하면 축하합니다. 첫 번째 구멍을 성공적으로 피한 것입니다. 실제로, cuda 도구를 설치할 때 몇 가지 함정에 직면하게 됩니다. 즉, 시스템에 적절한 버전의 gcc, gcc-dev, make 및 기타 컴파일 관련 도구가 설치되어 있어야 합니다. 이러한 구성 요소가 없으면 cuda 도구 설치가 실패합니다.
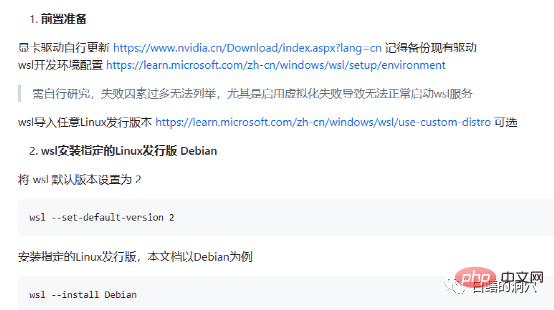
위의 함정 준비는 실제로 NVIDIA 드라이버의 함정을 피하고 후속 설치가 여전히 매우 원활합니다. 시스템 선택 측면에서는 여전히 Debian 호환 Ubuntu를 선택하는 것이 좋습니다. Ubuntu의 새 버전은 매우 똑똑하며 많은 소프트웨어의 버전 호환성 문제를 해결하고 일부 소프트웨어의 자동 버전 다운그레이드를 실현하는 데 도움이 될 수 있습니다.
다음 설치 과정은 설치 가이드를 완전히 따라야 원활하게 완료할 수 있습니다. 한편으로는 /etc/apt/sources.list의 설치 소스를 교체하는 작업이 가이드에 따라 완료되는 것이 가장 좋습니다. , 설치 속도도 훨씬 빨라집니다. 또한, 소프트웨어 버전 호환성 문제도 방지됩니다. 물론 교체하지 않는다고 해서 후속 설치 프로세스에 반드시 영향을 미치는 것은 아닙니다.
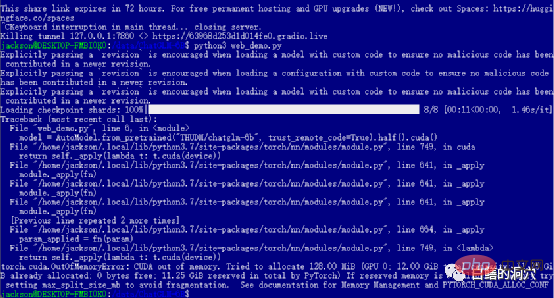
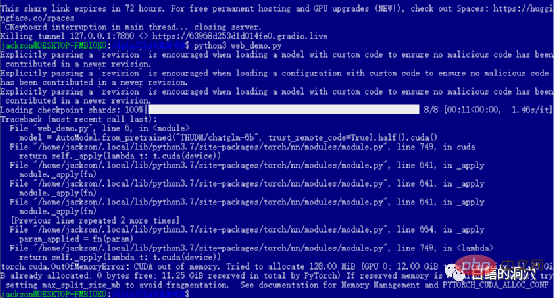
이전 레벨을 성공적으로 통과했다면 마지막 단계에 진입하여 web_demo를 시작합니다. python3 web_demo.py를 실행하면 WEB 대화의 예를 시작할 수 있습니다. 이때, 3060에 비디오 메모리가 12GB밖에 안되는 가난한 사람이라면 PYTORCH_CUDA_ALLOC_CONF를 최소 21로 설정해도 이 오류를 피할 수 없습니다. 이때는 너무 게을러서는 안 됩니다. Python 스크립트를 다시 작성하면 됩니다.
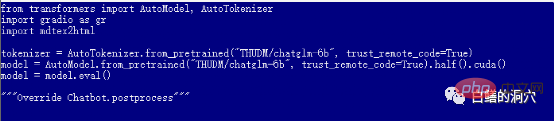
기본 web_demo.py는 FP16 사전 학습된 모델을 사용합니다. 13GB를 초과하는 모델은 기존 12GB에 절대 로드되지 않으므로 이 코드를 약간 조정해야 합니다.

퀀타이즈(4)로 변경하여 INT4 양자화 모델을 로드하거나, 퀀타이즈(8)로 변경하여 INT8 양자화 모델을 로드할 수 있습니다. 이렇게 하면 그래픽 카드 메모리가 충분해 다양한 대화를 할 수 있도록 지원할 수 있습니다.
web_demo.py가 시작되기 전에는 실제로 모델 다운로드가 시작되지 않으므로 13GB 모델을 다운로드하는 데 시간이 오래 걸립니다. 이 작업은 한밤중에 수행해도 됩니다. Thunder를 직접 사용할 수 있습니다. 다운로드 도구가 포옹 얼굴에서 모델을 미리 다운로드할 때까지 기다리세요. 모델에 대해 전혀 모르고 다운로드한 모델을 설치하는 데 능숙하지 않은 경우 THUDM/chatglm-6b-int4 코드에서 모델 이름을 수정하고 다음에서 4GB 미만의 INT4 양자화 모델을 직접 다운로드할 수도 있습니다. 인터넷은 속도가 훨씬 빠르며 손상된 그래픽 카드는 어쨌든 FP16 모델을 실행할 수 없습니다.
이 시점에서는 웹 페이지를 통해 ChatGLM과 대화할 수 있지만 이는 문제의 시작에 불과합니다. 미세 조정된 모델을 훈련할 수 있을 때만 ChatGLM으로의 여정이 진정으로 시작될 수 있습니다. 이런 종류의 플레이에는 여전히 많은 에너지와 돈이 필요하므로 함정에 들어갈 때는 조심하세요.
마지막으로, 더 많은 사람들이 저렴한 비용으로 대규모 언어 모델을 사용할 수 있게 된 칭화대학교 KEG 연구소의 친구들에게 매우 감사드립니다.
위 내용은 ChatGLM 사용 시 함정을 피하기 위한 몇 가지 팁의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!