
'A Dream of Red Mansions'의 절반을 ChatGPT 입력 상자로 옮기고 싶으십니까? 먼저 이 문제를 해결해보자

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-05-01 21:01:05949검색

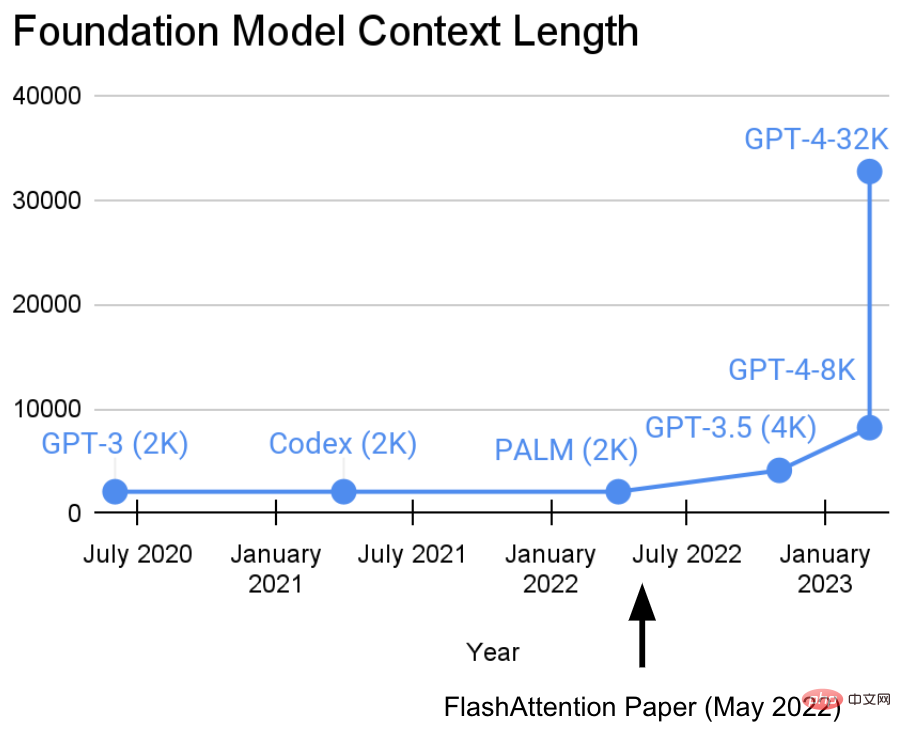
지난 2년 동안 스탠포드 대학의 Hazy Research Laboratory는 시퀀스 길이를 늘리는 중요한 작업에 참여했습니다.
그들의 견해: 더 긴 시퀀스는 기본 기계 학습 모델의 새로운 시대를 열 것입니다. 모델은 더 긴 컨텍스트, 여러 미디어 소스, 복잡한 데모 등에서 학습할 수 있습니다.현재 이 연구는 새로운 진전을 이루었습니다. Hazy Research 연구소의 Tri Dao와 Dan Fu는 FlashAttention 알고리즘의 연구 및 홍보를 주도하여 32k의 시퀀스 길이가 가능하며 현재 기본 모델 시대(OpenAI, Microsoft, NVIDIA 및 기타 회사)에서 널리 사용될 것임을 입증했습니다. 모델은 FlashAttention 알고리즘을 사용하고 있습니다).
- 논문 주소: https://arxiv.org/abs/2205.14135
- 코드 주소: https://github.com/HazyResearch/flash-attention
이 기사에서 저자는 높은 수준에서 시퀀스 길이를 늘리는 새로운 방법을 소개하고 새로운 프리미티브 세트에 대한 "브리지"를 제공합니다.
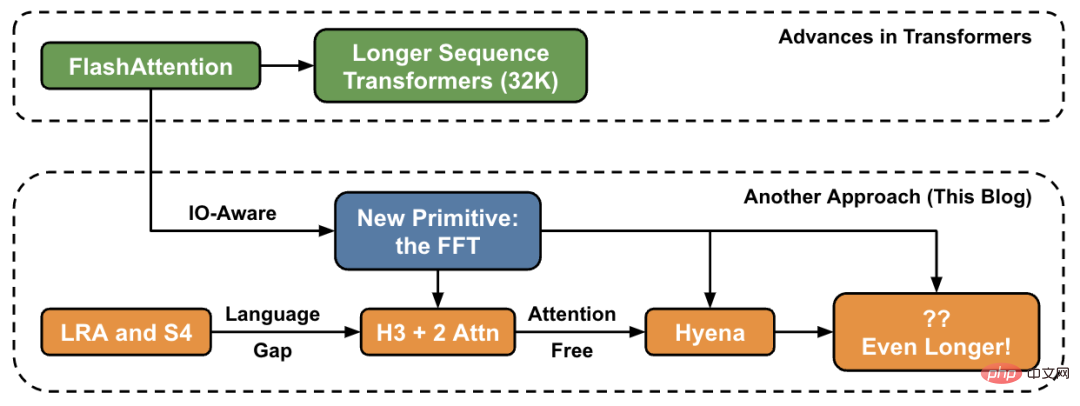
Hazy Research 연구실에서는 이 작업이 Hippo로 시작되었고, S4, H3, 그리고 이제 하이에나로 이어졌습니다. 이러한 모델은 수백만 또는 수십억 단위의 컨텍스트 길이를 처리할 수 있는 잠재력을 가지고 있습니다.
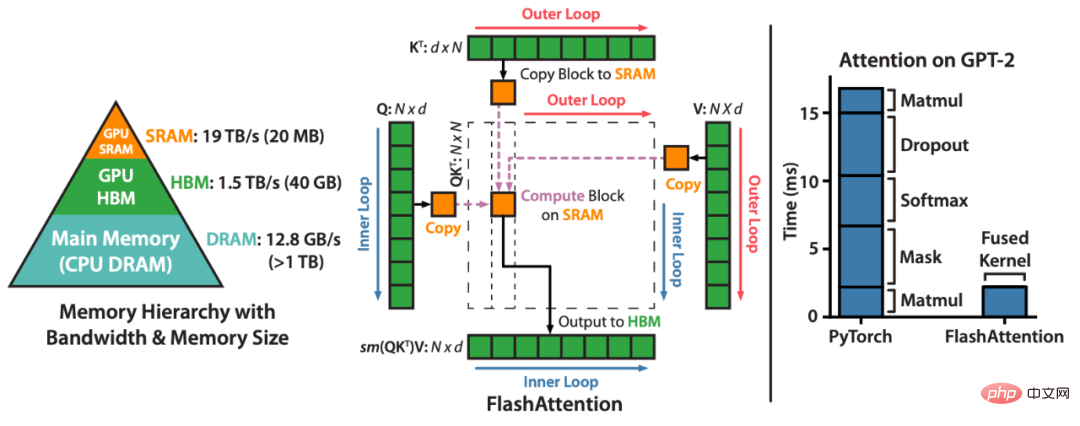
FlashAttention은 근사치 없이 주의 집중 속도를 높이고 메모리 사용량을 줄입니다. 블로그 게시물에는 “6개월 전 FlashAttention을 출시한 이후 많은 조직과 연구실에서 FlashAttention을 채택하여 교육 및 추론을 가속화하는 것을 보게 되어 매우 기쁩니다.”라고 나와 있습니다.FlashAttention은 주의 계산을 재정렬하고 고전적인 기술(타일링, 재계산)을 활용하여 시퀀스 길이에 따라 메모리 사용량을 2차에서 선형으로 줄이고 속도를 높이는 알고리즘입니다. 각 어텐션 헤드에 대해 메모리 읽기/쓰기를 줄이기 위해 FlashAttention은 전통적인 타일링 기술을 사용하여 GPU HBM(메인 메모리)에서 SRAM(빠른 캐시)으로 쿼리, 키 및 값 블록을 로드하고 어텐션을 계산하고 출력을 씁니다. HBM으로 돌아왔습니다. 이러한 메모리 읽기/쓰기 감소로 인해 대부분의 경우 속도가 크게 향상됩니다(2~4배).
Google 연구원들은 다양한 모델이 장거리 종속성을 얼마나 잘 처리하는지 평가하기 위해 2020년에 LRA(Long Range Arena) 벤치마크를 출시했습니다. LRA는 최대 16K의 시퀀스 길이(Path-X: 공간 일반화 편향 없이 픽셀로 펼쳐진 이미지 분류)를 사용하여 텍스트, 이미지, 수학적 표현과 같은 다양한 데이터 유형 및 양식을 포괄하는 다양한 작업을 테스트할 수 있습니다. Transformer를 더 긴 시퀀스로 확장하는 데 많은 훌륭한 작업이 있었지만 그 중 많은 부분이 정확성을 희생하는 것 같습니다(아래 이미지 참조). Path-X 열을 참고하세요. 모든 Transformer 메서드와 해당 변형은 무작위 추측보다 성능이 훨씬 나쁩니다. 이제 Albert Gu의 리더십 하에 개발된 S4에 대해 알아봅시다. Albert Gu는 LRA 벤치마크 결과에서 영감을 받아 장거리 종속성을 더 잘 모델링하는 방법을 찾고 싶었습니다. 직교 다항식과 재귀 모델 및 컨벌루션 모델 간의 관계에 대한 장기간 연구를 바탕으로 S4를 출시했습니다. —— 새로운 시퀀스 모델 구조화된 상태 공간 모델(SSM)을 기반으로 합니다. 핵심은 길이 N의 시퀀스를 2N으로 확장할 때 SSM의 시간 복잡도가 또한 Hazy Research가 FlashAttention을 출시했을 때 이미 Transformer의 시퀀스 길이를 늘리는 것이 가능했습니다. 또한 Transformer는 시퀀스 길이를 16K로 늘리는 것만으로도 Path-X에서 우수한 성능(63%)을 달성했다는 사실도 발견했습니다. 하지만 언어 모델링에서 S4의 품질 격차는 최대 5%에 달합니다. 이러한 격차를 줄이기 위해 연구자들은 언어가 어떤 속성을 가져야 하는지 결정하기 위해 연관 회상과 같은 합성 언어를 연구해 왔습니다. 최종 디자인은 H3(Hungry Hungry Hippos)입니다. 두 개의 SSM을 쌓고 출력을 곱셈 게이트로 곱하는 새로운 레이어입니다. H3를 사용하여 Hazy Research의 연구원은 GPT 스타일 Transformer의 거의 모든 Attention 레이어를 교체했으며 Pile의 400B 토큰에 대한 교육 시 복잡성 및 다운스트림 평가 측면에서 Transformer를 일치시킬 수 있었습니다. Long Range Arena 벤치마크 및 S4
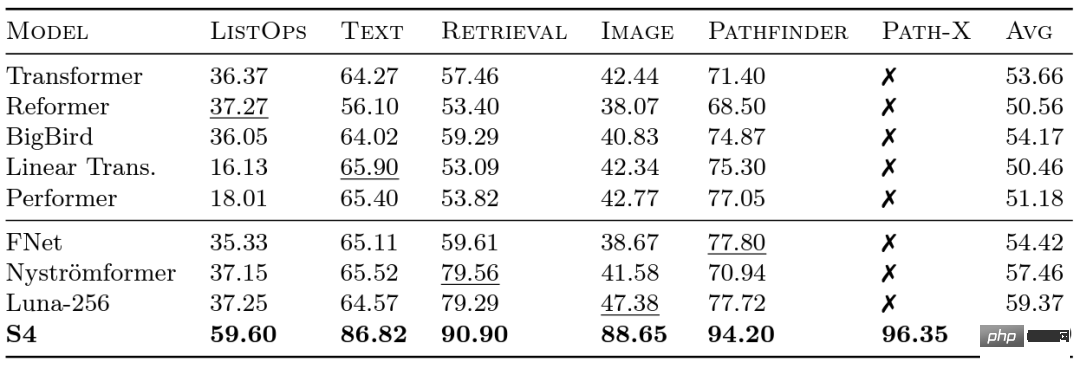
 라는 것입니다. 이는 제곱 수준에서 증가하는 어텐션 메커니즘과 달리입니다! S4는 LRA에서 장거리 종속성을 성공적으로 모델링했으며 Path-X에서 평균 이상의 성능을 달성한 최초의 모델이 되었습니다(현재 96.4% 정확도 달성!). S4 출시 이후 많은 연구자들이 이를 기반으로 Scott Linderman 팀의 S5 모델, Ankit Gupta의 DSS(및 Hazy Research Laboratory의 후속 S4D), Hasani 및 Lechner의 Liquid-S4와 같은 새로운 모델을 개발하고 혁신해 왔습니다. 등 모델.
라는 것입니다. 이는 제곱 수준에서 증가하는 어텐션 메커니즘과 달리입니다! S4는 LRA에서 장거리 종속성을 성공적으로 모델링했으며 Path-X에서 평균 이상의 성능을 달성한 최초의 모델이 되었습니다(현재 96.4% 정확도 달성!). S4 출시 이후 많은 연구자들이 이를 기반으로 Scott Linderman 팀의 S5 모델, Ankit Gupta의 DSS(및 Hazy Research Laboratory의 후속 S4D), Hasani 및 Lechner의 Liquid-S4와 같은 새로운 모델을 개발하고 혁신해 왔습니다. 등 모델. 모델링의 단점
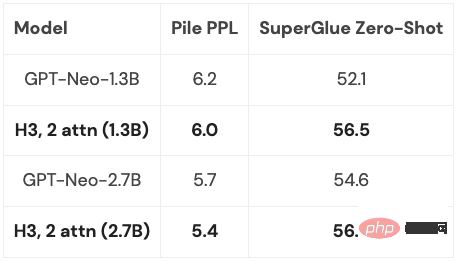
H3 레이어는 SSM을 기반으로 구축되었으므로 시퀀스 길이 측면에서 계산 복잡성도  비율로 증가합니다. 두 가지 주의 레이어는 여전히 전체 모델을 복잡하게 만듭니다.
비율로 증가합니다. 두 가지 주의 레이어는 여전히 전체 모델을 복잡하게 만듭니다.
 이 문제는 나중에 자세히 설명합니다.
이 문제는 나중에 자세히 설명합니다.
물론, Hazy Research만이 이 방향을 고려하는 것은 아닙니다. GSS는 또한 게이트가 있는 SSM이 언어 모델링에서 Attention과 잘 작동할 수 있다는 것을 발견했습니다(이 영감을 받은 H3). Meta는 Mega 모델을 출시했으며, 또한 SSM과 Attention을 결합합니다. BiGS 모델은 BERT 스타일 모델의 Attention을 대체하고 RWKV는 완전 루프 접근 방식을 연구해 왔습니다.
새로운 진행: 하이에나
일련의 이전 작업을 기반으로 Hazy Research의 연구원들은 영감을 받아 새로운 아키텍처인 하이에나를 개발했습니다. 그들은 H3의 마지막 두 주의 레이어를 제거하고 더 긴 시퀀스 길이에 대해 거의 선형적으로 성장하는 모델을 얻으려고 했습니다. 두 가지 간단한 아이디어가 답을 찾는 열쇠라는 것이 밝혀졌습니다.
- 각 SSM은 입력 시퀀스와 길이가 동일한 컨벌루션 필터로 볼 수 있습니다. 따라서 SSM은 입력 시퀀스와 동일한 크기의 컨볼루션으로 대체되어 동일한 계산 노력으로 보다 강력한 모델을 얻을 수 있습니다. 특히, 컨볼루셔널 필터는 신경 분야 문헌의 강력한 방법을 활용하고 CKConv/FlexConv에 대한 작업을 통해 또 다른 작은 신경망에 의해 암시적으로 매개변수화됩니다. 또한 컨볼루션은 O(NlogN) 시간에 계산될 수 있습니다. 여기서 N은 시퀀스 길이이며 거의 선형 스케일링을 달성합니다.
- H3의 게이팅 동작은 다음과 같이 요약될 수 있습니다. H3는 입력의 세 가지 투영을 취하고 반복적으로 컨볼루션을 수행하고 게이팅을 적용합니다. 하이에나에서는 단순히 더 많은 프로젝션과 더 많은 게이트를 추가하는 것만으로도 보다 표현력이 풍부한 아키텍처로 일반화하고 주의를 기울여 격차를 줄이는 데 도움이 됩니다.
하이에나는 Perplexity 및 다운스트림 작업에서 Transformer와 일치할 수 있는 완전히 선형에 가까운 시간 컨볼루션 모델을 처음으로 제안했으며 실험에서 좋은 결과를 얻었습니다. 그리고 중소 규모 모델은 PILE의 하위 집합에 대해 훈련되었으며 성능은 Transformer와 비슷했습니다.
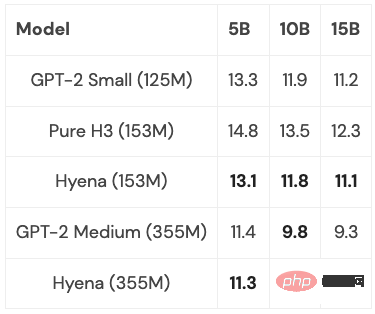
몇 가지 최적화를 통해(자세한 내용은 아래 참조) 시퀀스 길이가 2K일 때 하이에나 이 모델은 동일한 크기의 Transformer보다 약간 느리지만 시퀀스 길이가 길수록 빠릅니다.
다음으로 고려해야 할 것은 이러한 모델을 어느 정도 일반화할 수 있는가입니다. PILE(4000억 토큰)의 전체 크기로 확장할 수 있습니까? H3와 하이에나의 아이디어를 결합하면 어떤 일이 벌어지고, 어디까지 갈 수 있을까요?
FFT 또는 더 기본적인 접근 방식인가요?
이러한 모든 모델에서 일반적인 기본 연산은 FFT입니다. 이는 컨볼루션을 계산하는 효율적인 방법이며 O(NlogN) 시간만 걸립니다. 그러나 FFT는 주요 아키텍처가 특수 행렬 곱셈 장치 및 GEMM(예: NVIDIA GPU의 텐서 코어)인 최신 하드웨어에서 제대로 지원되지 않습니다.
FFT를 일련의 행렬 곱셈 연산으로 다시 작성하면 효율성 격차를 줄일 수 있습니다. 연구팀 구성원들은 나비 행렬을 사용하여 희소 훈련을 탐색함으로써 이 목표를 달성했습니다. 최근 Hazy Research 연구원들은 나비 분해를 사용하여 FFT 계산을 일련의 행렬 곱셈 연산으로 변환함으로써 FlashConv 및 FlashButterfly와 같은 빠른 컨볼루션 알고리즘을 구축하기 위해 이러한 연결을 활용했습니다.
또한 이전 작업을 바탕으로 더 깊은 연결을 만들 수 있습니다. 이러한 행렬을 학습하는 것도 포함되며 시간은 같지만 추가 매개변수가 추가됩니다. 연구자들은 일부 소규모 데이터 세트에서 이러한 연관성을 탐색하기 시작했으며 초기 결과를 얻었습니다. 우리는 이 연결이 무엇을 가져올 수 있는지 명확하게 볼 수 있습니다(예: 언어 모델에 적합하게 만드는 방법):

이 확장은 더 깊이 살펴볼 가치가 있습니다. 이 확장은 어떤 유형의 변환과 그것은 당신에게 무엇을 할 수 있게 합니까? 이를 언어 모델링에 적용하면 어떻게 될까요?
이것은 흥미로운 방향이며, 뒤따르는 것은 우리가 이 새로운 영역을 더 깊이 탐구할 수 있게 해주는 더 길고 긴 시퀀스와 새로운 아키텍처가 될 것입니다. 고해상도 이미징, 새로운 데이터 형식, 책 전체를 읽을 수 있는 언어 모델 등과 같이 긴 시퀀스 모델의 이점을 얻을 수 있는 응용 프로그램에 특별한 주의를 기울여야 합니다. 책 전체를 언어 모델에 제공하여 읽고 스토리라인을 요약하도록 하거나, 코드 생성 모델이 작성한 코드를 기반으로 새 코드를 생성하도록 한다고 상상해 보세요. 가능한 시나리오가 너무 많고 모두 매우 흥미 롭습니다.
위 내용은 'A Dream of Red Mansions'의 절반을 ChatGPT 입력 상자로 옮기고 싶으십니까? 먼저 이 문제를 해결해보자의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!