
MiniGPT-4는 사진을 보고 채팅을 하며 웹사이트를 스케치하고 구축할 수도 있습니다. Stable Diffusion의 비디오 버전이 출시되었습니다.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-04-28 12:10:181310검색
目录
- 잠재성 정렬: 잠재 확산 모델을 사용한 고해상도 비디오 합성
- MiniGPT-4: 고급 대형 언어 모델로 비전 언어 이해 향상
- OpenAssistant 대화 - 대규모 언어 모델 정렬 민주화
- Inpaint Anything: 무엇이든 세그먼트화하여 이미지 인페인팅을 충족
- 마스크 적응 CLIP을 사용한 개방형 어휘 의미론적 분할
- Plan4MC: 오픈 월드 Minecraft 작업을 위한 기술 강화 학습 및 계획
- T2Ranking: 통과 순위를 위한 대규모 중국 벤치마크
- ArXiv Weekly Radiostation:NLP、CV、ML 更多精选论文(附音频)
论文 1:잠재력을 정렬하세요 초: 높음 -잠재 확산 모델을 사용한 해상도 비디오 합성
- 작자: Andreas Blattmann 、 Robin Rombach 等
- 论文地址:https://arxiv.org/pdf/2304.08818.pdf
摘要: 近日慕尼黑大school、英伟达等机构的研究者利扩散模型(LDM)实现了高分辨率的长视频합성。
재论文中,研究者将视频模型应용于真实世界问题并生成了高分辨率的长视频。他们关注两个关的视频生成问题,一是高分辨率真实world驾驶数据的视频合成,其는 自动驾驶环境中作为模拟引擎具有巨大潜력;二是文本指导视频生成,用于创意内容生成。
为此,研究者提take了视频潜扩散模型(Video LDM),并将 LDM 扩视到了计算密集型任务 —— 高分辨率视频生成.与以往视频生成 DM 工작품상比,他们仅在图image上预训练 비디오 LDM(或者使用可用 预训练图image LDM),从而允许利用大规模图image数据集。
接着将时间维島引入潜지금공중 DM 、并에서 编码图image序列(即视频)上仅训练这些时间层的同时固定预训练空间层,从而将 LDM 图image生成器转换为视频生成器(下图左)。最后以类似方式微调 LDM 的解码器以实现做到最高 1280×2048、最长 4 .7 秒。
论文 2:MiniGPT -4:고급 대형 언어 모델을 통한 비전 언어 이해 강화
작자:朱德尧、陈军、沈晓倩、李祥、Mohamed H. Elhoseiny
- 论文地址:https:// minigpt-4.github.io/
- 摘要: 来自阿卜杜拉國王科技大大 (KAUST) 团队上 开发了一个 GPT-4 的类似产 제품 ——MiniGPT -4。MiniGPT-4 ऺ了许多类似于 GPT-4 적 기능, 例如生成详细的图image描述并从Hand写草稿创建网站。能力,包括根据给给图image创작동사화诗歌,提供解决图示的问题的解决方案, 根据foodphotos 教用户如何烹饪等。
MiniGPT-4 使用一个投影层将一个冻结视觉编码器와 一个冻结의 LLM(Vicuna)对齐。MiniGPT-4由一个预训练的 ViT 와 Q-Former 视觉编码器, 一个单独的线性投影层 and 一个先进的 Vicuna 大型语言模型组成.MiniGPT-4 只需要训练线性层,用来将视觉特征与 Vicuna 对齐。
예시: 스케치로 웹사이트 만들기.

추천: 3일 만에 거의 10,000개의 별을 획득하고, 별 차이 없는 GPT-4 사진 인식 능력, MiniGPT-4 사진 보기 및 채팅, 웹 사이트 구축을 위한 스케치를 경험해 보세요.
Paper 3 : OpenAsistant 대화 - 대형 언어 모델 조정 민주화 : Andreas Köpf, Yannic Kilcher 등. com/ file/d/10iR5hKwFqAKhL3umx8muOWSRm7hs5FqX/view
- 요약: 대규모 정렬 연구를 민주화하기 위해 (Stable Diffusion에서 사용하는 오픈 소스 데이터를 제공하는) LAION AI와 같은 기관의 연구자들이 다음을 수집했습니다. 방대한 양의 텍스트 기반 입력 및 피드백을 통해 언어 모델 또는 기타 AI 애플리케이션을 훈련하기 위해 특별히 설계된 다양하고 고유한 데이터세트인 OpenAssistant Conversations가 생성됩니다.
- 이 데이터 세트는 광범위한 주제와 글쓰기 스타일을 다루는 인간이 생성하고 주석을 추가한 보조자 스타일의 대화 자료입니다. 이는 35개 언어로 66,497개의 대화 트리에 배포된 161,443개의 메시지로 구성됩니다. 이 코퍼스는 13,500명 이상의 자원봉사자가 참여한 글로벌 크라우드소싱 노력의 산물입니다. SOTA 명령 모델을 생성하려는 모든 개발자에게 귀중한 도구입니다. 그리고 전체 데이터 세트는 누구나 자유롭게 접근할 수 있습니다. 또한, OpenAssistant Conversations 데이터 세트의 효율성을 입증하기 위해 연구에서는 작업을 이해하고, 타사 시스템과 상호 작용하며, 동적으로 정보를 검색할 수 있는 채팅 기반 도우미인 OpenAssistant도 제안합니다. 이는 틀림없이 인간 데이터에 대해 훈련된 최초의 완전 오픈 소스 대규모 명령 미세 조정 모델입니다.
결과에 따르면 OpenAssistant의 응답은 GPT-3.5-turbo(ChatGPT)보다 더 인기가 있는 것으로 나타났습니다.
OpenAssistant 대화 데이터는 웹 앱 인터페이스를 사용하여 수집되며 프롬프트, 프롬프트 태그, 프롬프트 또는 보조자로 응답 메시지 추가, 응답 태그 지정 및 보조 응답 순위 지정의 5단계로 구성됩니다.
추천:
ChatGPT, 세계 최대 오픈 소스 대안.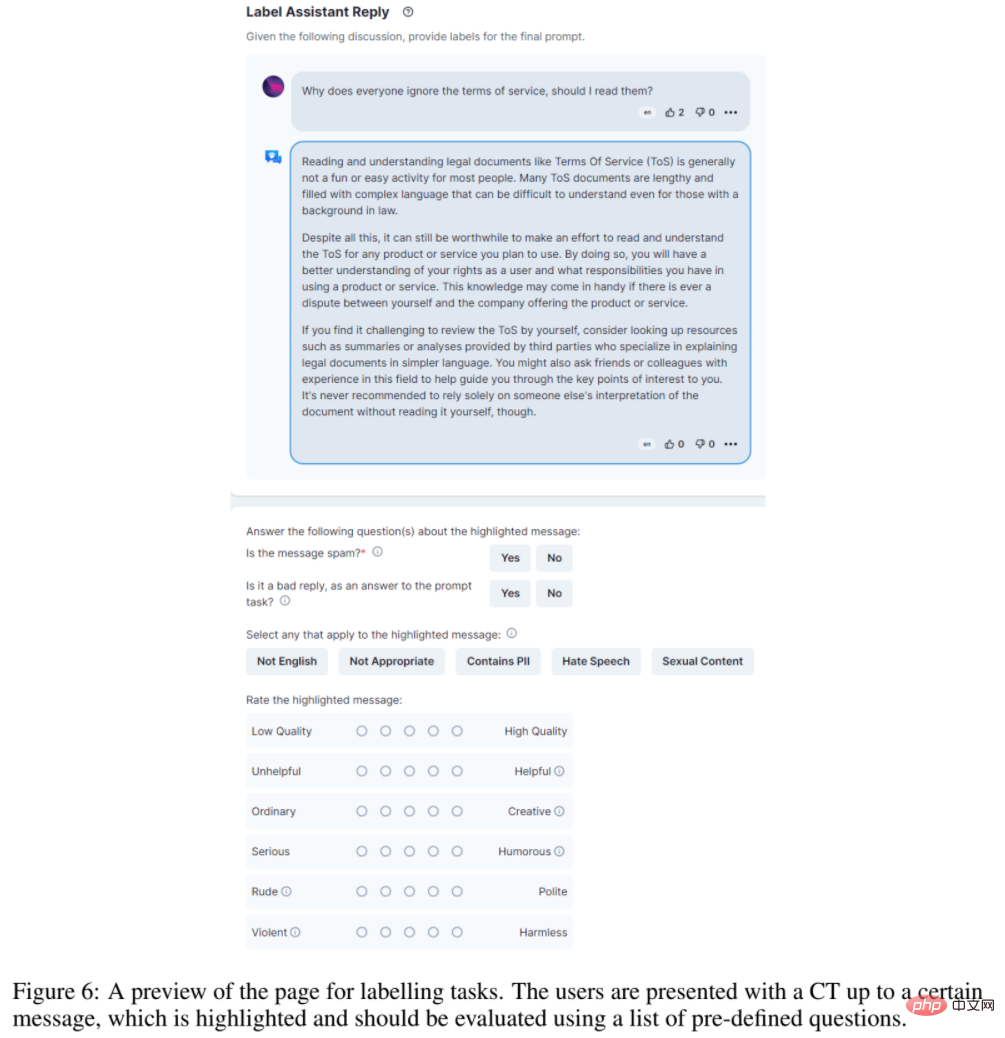
논문 4: 무엇이든 Inpaint: 무엇이든 분할하여 이미지 Inpainting을 만납니다
저자: Tao Yu, Runseng Feng 등
논문 주소: http://arxiv.org / abs/ 2304.06790
- 요약: 중국 과학 기술 대학과 동부 공과 대학의 연구팀은 SAM(Segment Anything Model)을 기반으로 하는 "Inpaint Anything"(IA) 모델을 제안했습니다. 기존 이미지 복구 모델과 달리 IA 모델은 마스크를 생성하는 데 세부적인 작업이 필요하지 않으며 한 번의 클릭으로 선택한 객체 표시를 지원합니다. IA는 모든 항목을 제거하고(모든 항목 채우기), 모든 항목을 교체할 수 있습니다. Anything)에서는 타겟 제거, 타겟 채우기, 배경 교체 등을 포함한 다양한 일반적인 이미지 복구 애플리케이션 시나리오를 다룹니다.
- 저자: Feng Liang, Bichen Wu 등
- 논문 주소: https://arxiv . org/pdf/2210.04150.pdf
- 저자: Haoqi Yuan, Chi Zhang 등
- 논문 주소: https:/ /arxiv .org/abs/2303.16563
- 저자: Xiaohui Xie, Qian Dong 등
- 논문 주소: https://arxiv.org/abs/2304.03679
IA에는 세 가지 주요 기능이 있습니다. (i) 무엇이든 제거: 사용자는 제거하려는 개체를 클릭하기만 하면 IA는 흔적을 남기지 않고 개체를 제거하여 효율적인 "마법 제거"를 달성합니다. : 동시에 사용자는 텍스트 프롬프트(텍스트 프롬프트)를 통해 객체에 채우고 싶은 내용을 IA에 추가로 알릴 수 있으며, IA는 내장된 AIGC(AI 생성 콘텐츠) 모델(예: Stable Diffusion [2)을 구동합니다. ]) 마음대로 "컨텐츠 생성"을 달성하기 위해 해당 컨텐츠가 채워진 객체를 생성합니다. (iii) 무엇이든 바꾸기: 사용자는 유지해야 하는 객체를 클릭하여 선택하고 텍스트 프롬프트를 사용하여 IA에 교체할 것을 알릴 수도 있습니다. 개체 개체의 배경을 지정된 내용으로 교체하여 생생한 "환경 변화"를 얻을 수 있습니다. IA의 전체 프레임워크는 아래 그림에 나와 있습니다.
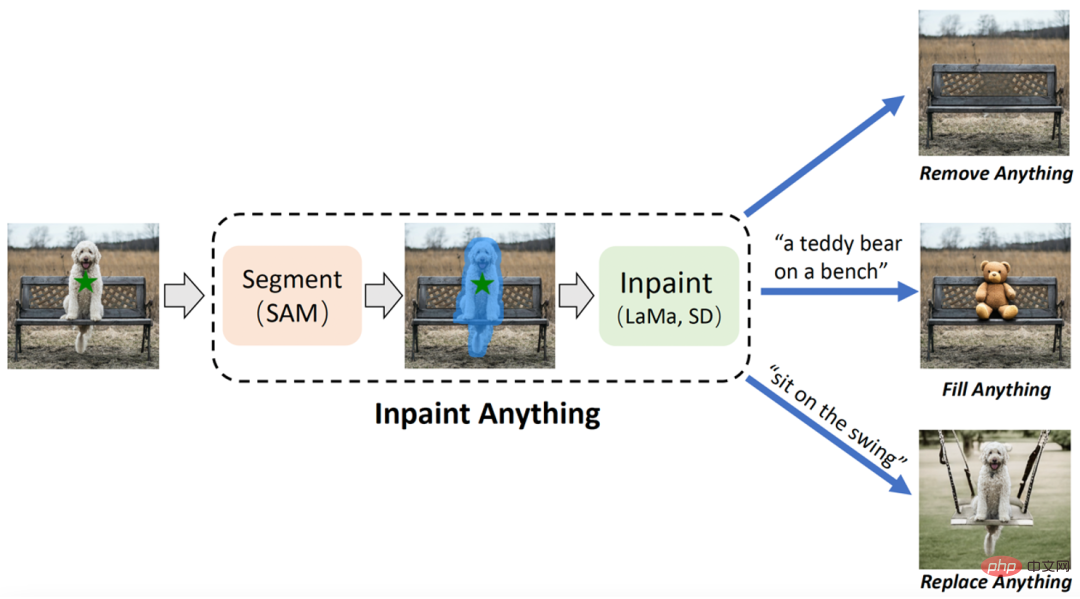
권장 사항: 세밀하게 표시할 필요가 없습니다. 개체를 클릭하면 개체 제거, 콘텐츠 채우기 및 장면 교체가 가능합니다.
논문 5: 마스크 적응 CLIP을 사용한 개방형 어휘 의미론적 분할
요약: Meta와 UTAustin은 Segment Anything 모델이 분리할 범주를 알 수 있도록 하는 새로운 개방형 언어 스타일 모델(개방형 어휘 분할, OVSeg)을 공동으로 제안했습니다. .
효과적인 관점에서 OVSeg는 Segment Anything과 결합하여 세분화된 개방형 언어 분할을 완성할 수 있습니다. 예를 들어, 아래 그림 1에서는 해바라기, 흰 장미, 국화, 카네이션, 녹색 패랭이꽃 등 꽃의 종류를 식별합니다.

권장: Meta/UTAustin은 새로운 개방형 클래스 분할 모델을 제안합니다.
문서 6: Plan4MC: 오픈 월드 Minecraft 작업을 위한 기술 강화 학습 및 계획
요약: 북경 대학과 베이징 Zhiyuan 인공 지능 연구소의 팀은 전문가 데이터 없이 Minecraft 멀티태스킹을 효율적으로 해결하는 방법인 Plan4MC를 제안했습니다. 저자는 강화 학습과 계획 방법을 결합하여 복잡한 작업 해결을 기본 기술 학습과 기술 계획이라는 두 부분으로 분해합니다. 저자는 세 가지 유형의 세분화된 기본 기술을 훈련하기 위해 내재적 보상 강화 학습 방법을 사용합니다. 에이전트는 대규모 언어 모델을 사용하여 스킬 관계 그래프를 구축하고 그래프 검색을 통해 작업 계획을 얻습니다. 실험적인 부분에서 Plan4MC는 현재 24개의 복잡하고 다양한 작업을 완료할 수 있으며 모든 기본 방법에 비해 성공률이 크게 향상되었습니다.

권장: ChatGPT 및 강화 학습을 사용하여 "Minecraft"를 플레이하면 Plan4MC가 24개의 복잡한 작업을 극복합니다.
문서 7: T2Ranking: 통과 순위를 위한 대규모 중국 벤치마크
요약: 단락 정렬 ing은 매우 중요한 일이다 정보검색 분야의 이슈는 학계와 산업계에서 폭넓은 관심을 받아온 중요하고 도전적인 주제입니다. 문단 순위 모델의 효율성은 검색 엔진 사용자 만족도를 높이고 질의응답 시스템, 독해 등 정보 검색 관련 애플리케이션에 도움이 될 수 있습니다. 이러한 맥락에서 문단 정렬 관련 연구 작업을 지원하기 위해 MS-MARCO, DuReader_retrieval 등과 같은 일부 벤치마크 데이터 세트를 구축했습니다. 그러나 일반적으로 사용되는 데이터 세트의 대부분은 영어 장면에 중점을 두고 있습니다. 중국어 장면의 경우 기존 데이터 세트는 데이터 규모, 세분화된 사용자 주석 및 위음성 예제 문제에 대한 솔루션에 한계가 있습니다. 이에 본 연구에서는 실제 검색 로그를 기반으로 새로운 한문 문단 순위 벤치마크 데이터 세트인 T2Ranking을 구축하였다.
T2Ranking은 30만개 이상의 실제 쿼리와 200만개 이상의 인터넷 문단으로 구성되어 있으며, 전문 주석자가 제공하는 4단계 세분화된 관련성 주석을 포함하고 있습니다. 현재 데이터와 일부 기본 모델은 Github에 게시되었으며 관련 연구 작업은 SIGIR 2023에서 리소스 논문으로 승인되었습니다.
추천: 실제 검색어 30만 개, 인터넷 문단 200만 개, 한자 문단 순위 벤치마크 데이터 세트 공개.
ArXiv Weekly Radiostation
Heart of Machine은 Chu Hang, Luo Ruotian 및 Mei Hongyuan이 시작한 ArXiv Weekly Radiostation과 협력합니다. 7개의 논문을 바탕으로 NLP, CV, ML 10을 포함한 이번 주의 더 중요한 논문을 선정합니다. 각 분야별 선정 논문과 논문 초록 소개를 오디오 형식으로 제공합니다.
이번 주 선정 NLP 논문 10편은
1. DSTC9 및 DSTC10에 대한 HLTPR@RWTH의 대화 시스템(Hermann Ney 제공)
2. 절충점 탐색: 고도로 특정한 방사선학 NLI 작업을 위한 통합 대형 언어 모델과 로컬 미세 조정 모델(Wei Liu 제공) , Dinggang Shen )
3. 측면 기반 감정 분석의 견고성: 모델, 데이터 및 훈련 재검토(Tat-Seng Chua에서)
4. 확률론적 앵무새를 찾고 있습니다. 미세 조정은 쉽지만 다른 LLM으로는 감지하기 어려움(Rachid Guerraoui 제공)
5. 카멜레온: 대규모 언어 모델을 사용한 플러그 앤 플레이 구성 추론(Kai-Wei Chang, Song-Chun Zhu, Jianfeng Gao)
6. MER 2023: 다중 레이블 학습, 양식 견고성 및 반지도 학습(Meng Wang, Erik Cambria, Guoying Zhao)
7. NCBI 웹 API 사용(Zhiyong Lu)
8. 사전 훈련된 언어 모델을 사용한 생물 의학 텍스트 요약에 대한 설문 조사(Sophia Ananiadou)
10. 이기종 데이터 호수 (Christopher Ré) 2. Align-DETR: 단순 IoU 인식 BCE 손실로 DETR 개선(Xiangyu Zhang)
3 퓨샷 이미지 생성에서 호환되지 않는 지식 전송 탐색(Shuicheng Yan)
4. 비디오 질문 답변을 위한 학습 상황 하이퍼 그래프. (무바라크 샤에서)
5. 단일 클립 이상의 비디오 생성. (Ming-Hsuan Yang에서)
6. Vision Transformer를 통한 비균질 안개 제거에 대한 데이터 중심 솔루션. (류환에게서)
7. 이벤트 카메라를 이용한 뉴로모픽 광학 흐름 및 실시간 구현. (루카 베니니, 다비데 스카라무짜 중에서)
8. 대화형 이미지 검색을 위한 언어 기반 로컬 침투. (레이 장에서)
9. LipsFormer: Vision Transformers에 Lipschitz 연속성을 소개합니다. (레이 장에서)
10. UVA: 뷰 합성, 포즈 렌더링, 형상 및 텍스처 편집을 위한 통합 볼륨 아바타를 지향합니다. (Dacheng Tao에서)
本周 10 篇 ML 精选论文是:
1. 효과적인 지평선을 통해 RL 이론과 실제를 연결합니다. (스튜어트 러셀에서)
2. 투명하고 강력한 데이터 기반 풍력 터빈 전력 곡선 모델을 지향합니다. (클라우스-로베르트 뮐러 중에서)
3. 개방형 지속적인 학습: 참신함 감지 및 지속적인 학습 통합. (Bing Liu에서)
4. 잠재 공간에서의 학습은 심층 신경 연산자의 예측 정확도를 향상시킵니다. (George Em Karniadakis에서)
5. 그래프 신경망 분리: 하나가 아닌 여러 개의 간단한 GNN을 동시에 훈련합니다. (Xuelong Li에서)
6. 모델 기반 신경망의 일반화 및 추정 오류 한계. (Yonina C. Eldar에서)
7. RAFT: 생성 기반 모델 정렬을 위해 순위가 지정된 FineTuning을 보상합니다. (퉁 장에서)
8. GAN을 위한 적응형 합의 최적화 방법. (파완 쿠마르에서)
9. 경사하강법에 대한 각도 기반 동적 학습 속도입니다. (파완 쿠마르에서)
10. AGNN: 과도한 평활화를 완화하기 위해 그래프 정규화 신경망을 교대로 사용합니다. (원중궈에서)
위 내용은 MiniGPT-4는 사진을 보고 채팅을 하며 웹사이트를 스케치하고 구축할 수도 있습니다. Stable Diffusion의 비디오 버전이 출시되었습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!