
OpenAI를 다시 이겨보세요! Google, 100개 이상의 언어를 자동으로 인식하고 번역하는 20억 매개변수 범용 모델 출시

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-04-25 12:04:061612검색
지난주 OpenAI는 ChatGPT API와 Whisper API를 출시하여 개발자 카니발을 촉발시켰습니다.
3월 6일, 구글은 벤치마크 모델인 USM을 출시했습니다. 100개 이상의 언어를 지원할 수 있을 뿐만 아니라 매개변수 수도 20억 개에 달했습니다.
물론 모델은 아직 공개되지 않았습니다. "이것은 바로 Google입니다!"
간단히 말해서 USM 모델은 1,200만 시간의 음성, 280억 개의 문장, 300개의 다양한 언어를 포괄하는 레이블이 없는 데이터 세트에서 사전 훈련되었으며, 주석이 달린 더 작은 데이터 세트에서 훈련되었습니다. -동조.
Google 연구원들은 미세 조정에 사용되는 주석 훈련 세트가 Whisper의 1/7에 불과하지만 USM은 동등하거나 더 나은 성능을 가지며 새로운 언어 및 데이터에 효과적으로 적응할 수 있다고 말했습니다.

논문 주소: https://arxiv.org/abs/2303.01037
결과에 따르면 USM은 다국어 자동 음성 인식 및 음성 텍스트 번역에만 효과적인 것이 아닙니다. 작업 평가 SOTA가 구현되어 실제로 YouTube 자막 생성에 사용될 수 있습니다.
현재 자동 감지 및 번역을 지원하는 언어에는 주류 영어, 중국어, 아삼어 등 작은 언어가 포함됩니다.
가장 중요한 점은 구글이 지난해 IO 컨퍼런스에서 시연한 미래 AR 글래스의 실시간 번역에도 사용할 수 있다는 점이다.

Jeff Dean이 직접 발표했습니다: AI가 1000개 언어를 지원하도록 하세요
Microsoft와 Google이 누가 더 나은 AI 챗봇을 가지고 있는지 논쟁할 때, 대규모 언어 모델의 사용이 멈추지 않는다는 것을 알아야 합니다. 거기.
구글은 지난해 11월 '세계에서 가장 많이 사용되는 언어 1,000개를 지원하는 인공지능 언어 모델을 개발'하는 새로운 프로젝트를 처음 발표했다.

같은 해 메타는 "만능 번역기"를 만드는 것을 목표로 200개 이상의 언어를 번역할 수 있다고 말하면서 "No Language Left Behind"라는 모델도 출시했습니다.
최신 모델 출시를 Google에서는 목표를 향한 '중요한 단계'라고 표현합니다.
언어 모델 구축에는 수많은 영웅들이 경쟁하고 있다고 할 수 있습니다.
소문에 따르면 Google은 올해 연례 I/O 컨퍼런스에서 인공지능을 활용한 20개 이상의 제품을 선보일 계획이라고 합니다.
현재 자동 음성 인식은 많은 문제에 직면해 있습니다.
- 기존 지도 학습 방법은 확장성이 부족합니다.
기존 방법에서는 오디오 데이터가 시간이 많이 걸리고 비용이 많이 듭니다. 수동 태그 노화 광범위한 표현이 부족한 언어에서는 찾기 어려운 기존 필사본이 있는 소스에서 수집한 돈 또는 컬렉션입니다.
- 언어 적용 범위와 품질을 확장하는 동시에 모델은 계산 효율적인 방식으로 개선되어야 합니다
이를 위해서는 알고리즘이 별도의 작업 없이 다양한 소스의 대량 데이터를 사용할 수 있어야 합니다. 재교육과 새로운 언어 및 사용 사례에 대한 일반화 기능을 통해 모델 업데이트를 완전히 활성화해야 합니다.
미세 조정된 자기 지도 학습
논문에 따르면 USM 교육은 페어링되지 않은 오디오 데이터 세트, 페어링되지 않은 텍스트 데이터 세트 및 페어링된 ASR 코퍼스의 세 가지 데이터베이스를 사용합니다.
- 페어링되지 않은 오디오 데이터 세트
YT-NTL-U(1,200만 시간 이상의 YouTube 태그 없는 오디오 데이터) 및 Pub-U(429,000시간 이상) 포함 Spe ECH 콘텐츠 51개 언어로 제공)
- 페어링되지 않은 텍스트 데이터세트
Web-NTL(1140개 이상의 언어로 280억 문장) ...
- USM은 표준 인코더-디코더 구조를 사용하며 디코더는 CTC, RNN-T 또는 LAS일 수 있습니다. USM은 인코더의 경우 Conformor 또는 Convolution-enhanced Transformer를 사용합니다.
교육 과정은 세 단계로 나뉩니다.

다음 단계에서는 음성 표현 학습 모델을 추가로 훈련합니다.
MOST(Multi-Object Supervised Pre-training)를 사용하여 다른 텍스트 데이터의 정보를 통합합니다.
모델은 텍스트를 입력으로 사용하는 추가 인코더 모듈을 도입하고 음성 인코더와 텍스트 인코더의 출력을 결합하고 레이블이 없는 음성, 레이블이 있는 음성의 출력을 결합하는 추가 레이어를 도입합니다. 텍스트 데이터에 대한 모델을 공동으로 훈련합니다. .
마지막 단계는 ASR(자동 음성 인식) 및 AST(자동 음성 번역) 작업을 미세 조정하는 것입니다. 사전 훈련된 USM 모델은 적은 양의 감독 데이터로도 좋은 성능을 달성할 수 있습니다.
USM 전반적인 교육 프로세스
Google에서는 YouTube 자막, 다운스트림 ASR 작업 홍보 및 자동 음성 번역에서 USM을 테스트했습니다.
YouTube 다국어 자막 성능
감독되는 YouTube 데이터에는 73개 언어가 포함되어 있으며 언어당 평균 데이터 시간은 3,000시간 미만입니다. 제한된 감독 데이터에도 불구하고 이 모델은 73개 언어에서 30% 미만의 평균 단어 오류율(WER)을 달성했는데, 이는 미국 내 최첨단 모델보다 낮습니다.
또한 Google은 이를 400,000시간 이상의 주석 데이터로 훈련한 Whisper 모델(big-v2)과 비교했습니다.
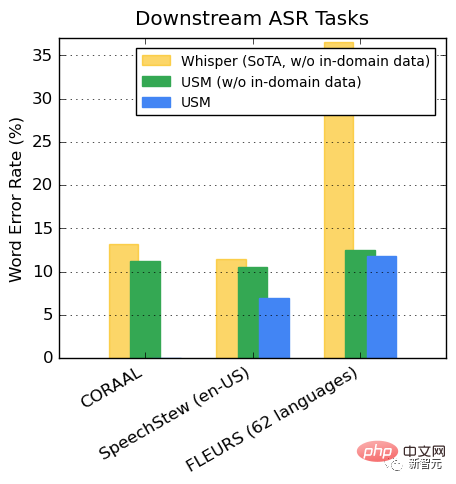
Whisper가 디코딩할 수 있는 18개 언어 중 디코딩 오류율은 40% 미만인 반면, 평균 USM 오류율은 32.7%에 불과합니다. ㅋㅋㅋ 102 언어)은 도메인 내 훈련 데이터 유무에 관계없이 더 낮은 WER을 나타냅니다.
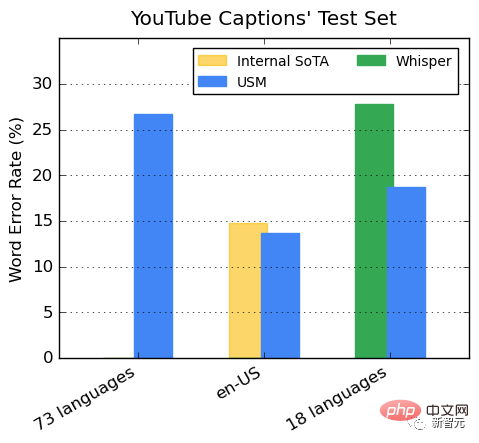 두 모델의 FLEURS 차이는 특히나 확연합니다.
두 모델의 FLEURS 차이는 특히나 확연합니다.
AST 작업 성능
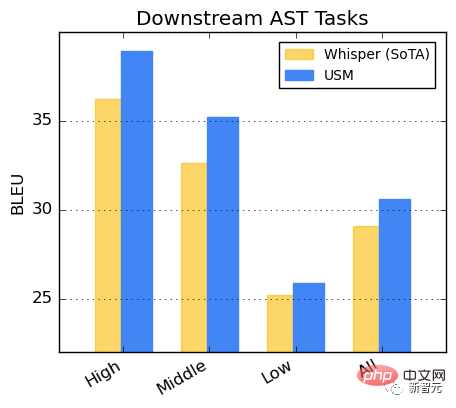
CoVoST 데이터세트에서 USM을 미세 조정합니다.
 리소스 가용성에 따라 데이터 세트의 언어를 높음, 중간, 낮음의 세 가지 범주로 나눕니다. 각 범주의 BLEU 점수를 계산합니다(높을수록 더 좋음). .
리소스 가용성에 따라 데이터 세트의 언어를 높음, 중간, 낮음의 세 가지 범주로 나눕니다. 각 범주의 BLEU 점수를 계산합니다(높을수록 더 좋음). .
연구에 따르면 BEST-RQ 사전 훈련은 음성 표현 학습을 대규모 데이터 세트로 확장하는 효과적인 방법인 것으로 나타났습니다.
MOST의 텍스트 삽입과 결합하면 다운스트림 음성 작업의 품질이 향상되어 FLEURS 및 CoVoST 2 벤치마크에서 최첨단 성능을 달성합니다.
경량 잔여 어댑터 모듈을 교육함으로써 MOST는 새로운 도메인에 빠르게 적응할 수 있는 능력을 나타냅니다. 나머지 어댑터 모듈은 매개변수를 2%만 증가시킵니다.
Google은 USM이 현재 100개 이상의 언어를 지원하며 앞으로 1,000개 이상의 언어로 확장할 것이라고 밝혔습니다. 이 기술을 사용하면 모든 사람이 전 세계를 안전하게 여행할 수 있습니다.
심지어 향후 Google AR 안경 제품의 실시간 번역은 많은 팬들을 끌어들일 것입니다.
 그러나 이 기술의 적용은 아직 갈 길이 멀다.
그러나 이 기술의 적용은 아직 갈 길이 멀다.
결국 구글은 세계를 향한 IO 컨퍼런스 연설에서 아랍어 텍스트를 거꾸로 써서 많은 네티즌들의 눈길을 끌기도 했습니다.
위 내용은 OpenAI를 다시 이겨보세요! Google, 100개 이상의 언어를 자동으로 인식하고 번역하는 20억 매개변수 범용 모델 출시의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!