
CLIP은 정말 현실적이지 않나요? 중국어를 더 잘 이해하는 모델이 필요합니다

- PHPz앞으로
- 2023-04-25 08:58:072006검색
이 글에서는 다모아카데미 매직커뮤니티 ModelScope에서 최근 오픈소스로 공개한 중국 CLIP 대규모 사전 학습 이미지 및 텍스트 표현 모델을 소개합니다. 텍스트 검색 및 제로 샘플 이미지 분류와 동시에 코드와 모델이 모두 오픈 소스이므로 사용자는 Magic을 사용하여 빠르게 시작할 수 있습니다.

- 모델 사용 입구: https://modelscope.cn/models/damo/multi-modal_clip-vit-base-patch16_zh/summary
- Github: https://github.com/OFA- Sys/English-CLIP
- paper: https://arxiv.org/pdf/2211.01335.pdf
- 이미지 및 텍스트 검색 데모: https://modelscope.cn/studios/damo/chinese_clip_applications/summary
1. 소개
현재 인터넷 생태계에는 이미지 및 텍스트 검색, 이미지 분류, 비디오 및 이미지 및 텍스트 콘텐츠 및 기타 시나리오와 같은 수많은 다중 모드 관련 작업 및 시나리오가 있습니다. 최근 몇 년 동안 인터넷을 통해 인기를 끌었던 이미지 생성은 더욱 인기를 끌며 빠르게 그 범위에서 벗어났습니다. 이러한 작업 뒤에는 강력한 이미지 및 텍스트 이해 모델이 분명히 필요합니다. 2021년 OpenAI가 출시한 CLIP 모델은 다들 익숙하실 거라 믿습니다. 간단한 이미지-텍스트 트윈타워 비교 학습과 대량의 이미지-텍스트 코퍼스를 통해 이 모델은 상당한 이미지-텍스트 특징 정렬 기능을 갖추고 있으며, 활용이 가능합니다. Zero-sample 이미지 분류에서는 Cross-modal Retrieval에서 뛰어난 결과를 보이며 DALLE2, Stable Diffusion 등의 이미지 생성 모델의 핵심 모듈로도 사용됩니다.
하지만 아쉽게도 OpenAI CLIP의 사전 학습은 주로 영어 세계의 그래픽 및 텍스트 데이터를 사용하므로 중국어를 자연스럽게 지원하지 못합니다. 비록 번역된 텍스트를 통해 Multilingual-CLIP(mCLIP)의 다국어 버전을 증류한 연구자들이 커뮤니티에 있다고 해도 여전히 중국 세계의 텍스트에 대한 이해도가 그다지 좋지 않은 것 같습니다. "Spring Festival Couplets"를 검색하면 반환되는 내용은 크리스마스 관련 콘텐츠입니다.

mCLIP 데모 검색 "Spring Festival Couplets" 검색 반환 결과
이것은 또한 우리가 중국어를 더 잘 이해하는 CLIP이 필요합니다. 우리 언어는 중국 세계의 이미지도 더 잘 이해합니다.
2. 방법
DAMO 아카데미 연구진은 LAION-5B 중국어 하위 집합인 Wukong과 Visual Genome의 번역 이미지인 COCO를 포함하여 대규모 중국어 이미지-텍스트 쌍 데이터(약 2억 규모)를 수집했습니다. 텍스트 데이터 등 대부분의 훈련 이미지와 텍스트는 공개 데이터 세트에서 가져오므로 재현의 어려움이 크게 줄어듭니다. 훈련 방법 측면에서, 모델의 훈련 효율성과 모델 효과를 효과적으로 향상시키기 위해 연구원들은 2단계 훈련 프로세스를 설계했습니다. 그림에 표시된 것처럼 첫 번째 단계에서 모델은 기존 이미지 사전 학습 모델과 텍스트 사전 학습 모델을 사용하여 Chinese-CLIP의 트윈 타워를 각각 초기화하고 이미지 측 매개변수를 동결하여 언어 모델을 허용하는 것을 보여줍니다. 기존 이미지 사전 훈련 표현 공간과 연결하는 동시에 훈련 오버헤드가 줄어듭니다. 이어 두 번째 단계에서는 이미지 측 매개변수를 동결 해제하여 이미지 모델과 언어 모델을 연관시키면서 중국 특성을 지닌 데이터 분포를 모델링한다. 연구원들은 처음부터 사전 훈련하는 것과 비교할 때 이 방법이 여러 다운스트림 작업에서 훨씬 더 나은 실험 결과를 보여 주었으며 훨씬 더 높은 수렴 효율성은 또한 더 적은 훈련 오버헤드를 의미한다는 것을 발견했습니다. 훈련의 한 단계에서 텍스트 측면만 훈련하는 것과 비교하여 훈련의 두 번째 단계를 추가하면 다운스트림 그래픽 및 텍스트 작업, 특히 영어 데이터 세트에서 번역되지 않은 중국어 기본 그래픽 및 텍스트 작업에 대한 효과를 효과적으로 더욱 향상시킬 수 있습니다.
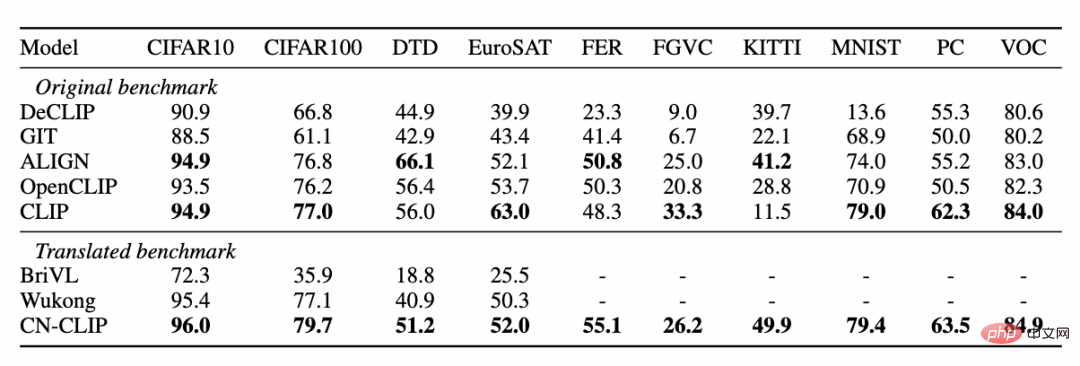
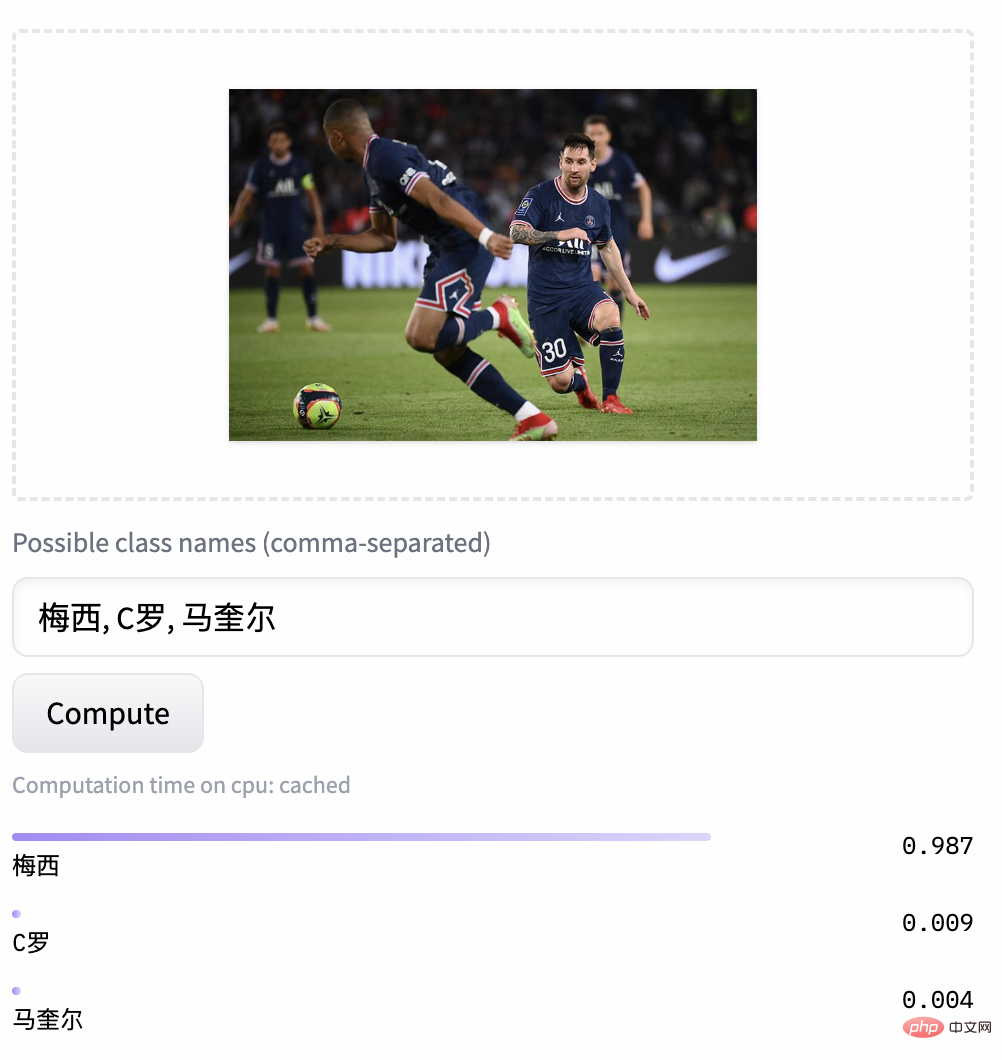
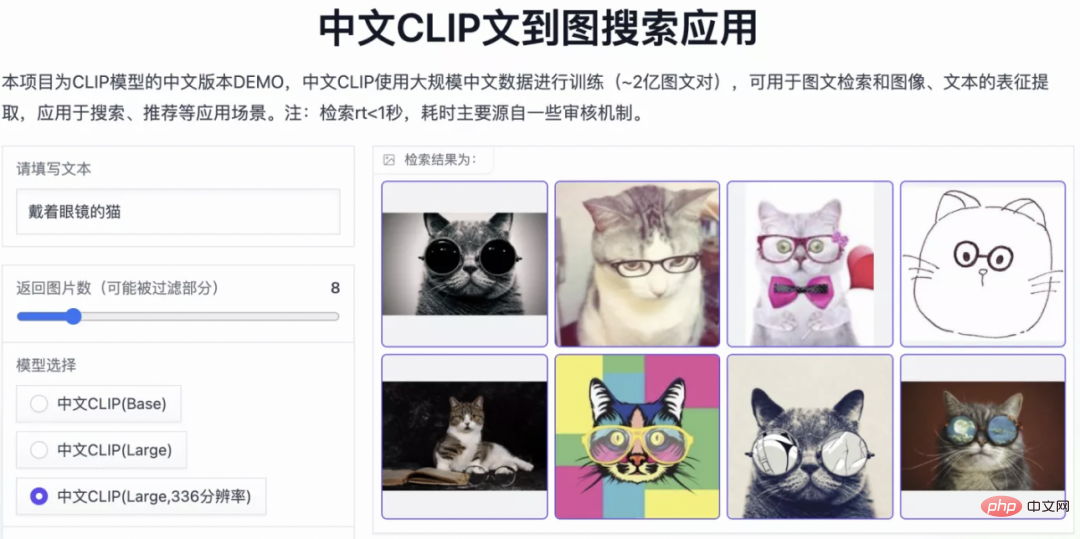
두 데이터 세트(MUGE 중국 전자상거래 이미지 및 텍스트 검색 및 Flickr30K-CN 번역 버전 일반 이미지 및 텍스트 검색)에 대해 사전 훈련이 계속됨에 따라 제로샷 효과의 변화 추세를 관찰하세요. . 이 전략을 사용하여 연구원들은 가장 작은 ResNet-50, ViT-Base 및 Large부터 ViT-Huge까지 다양한 크기의 모델을 훈련했으며 이제 사용자는 필요에 따라 가장 적합한 모델을 사용할 수 있습니다. 모델: 여러 실험 데이터에 따르면 Chinese-CLIP은 중국어 크로스 모달 검색에서 최고의 성능을 달성할 수 있으며 그 중 중국 기본 전자상거래 이미지 검색 데이터 세트 MUGE, 중국어 여러 규모의 CLIP은 이 규모에서 최고의 성능을 달성했습니다. 영어 기반 Flickr30K-CN 및 기타 데이터 세트에서 중국어 CLIP은 제로 샘플 또는 미세 조정 설정에 관계없이 Wukong, Taiyi 및 R2D2와 같은 국내 기본 모델을 크게 초과할 수 있습니다. 이는 Chinese-CLIP의 더 큰 중국어 사전 훈련 이미지와 텍스트 코퍼스에 기인하며, Chinese-CLIP은 훈련 비용을 최소화하고 전체 이미지 측면을 동결시키기 위해 기존의 일부 국내 이미지 및 텍스트 표현 모델과 다릅니다. 중국 분야에 더 잘 적응하기 위해 두 가지 단계적 훈련 전략을 사용합니다. MUGE 중국 전자상거래 이미지 및 텍스트 검색 데이터 세트 실험 결과 Flickr30K-CN 중국어 이미지 및 텍스트 검색 데이터 세트에 대한 실험 결과 동시에 연구원들은 제로샷 이미지 분류 데이터 세트에 대한 중국어 CLIP의 효과를 검증했습니다. 중국 분야에는 권위 있는 제로샷 이미지 분류 작업이 많지 않기 때문에 연구원들은 현재 데이터 세트의 영어 번역 버전을 테스트하고 있습니다. Chinese-CLIP은 중국어 프롬프트 및 카테고리 라벨을 통해 이러한 작업에서 CLIP과 비슷한 성능을 달성할 수 있습니다. 제로 샘플 분류 실험 결과 zero 샘플 이미지 분류 예 중국어-CLIP은 어떻게 사용하나요? 매우 간단합니다. 기사 시작 부분에 있는 링크를 클릭하여 Moda 커뮤니티를 방문하거나 오픈 소스 코드를 사용하면 단 몇 줄만으로 이미지 및 텍스트 특징 추출 및 유사성 계산을 완료할 수 있습니다. 빠른 사용과 경험을 위해 Moda 커뮤니티에서는 구성된 환경을 갖춘 노트북을 제공합니다. 오른쪽 상단을 클릭하면 사용할 수 있습니다. Chinese-CLIP은 또한 사용자가 자신의 데이터를 사용하여 미세 조정을 할 수 있도록 지원하고 모든 사람이 다양한 크기의 Chinese-CLIP 모델 효과를 실제로 경험할 수 있도록 이미지 및 텍스트 검색 데모도 제공합니다. 이번에 Damoda 커뮤니티는 Chinese-CLIP 프로젝트를 시작했습니다. 이 프로젝트는 대다수의 중국 다중 모드 연구 및 업계 사용자에게 탁월한 사전 훈련된 이미지 및 텍스트 이해 모델을 제공하여 모든 사람이 특징 및 유사성 계산, 이미지 및 텍스트 검색, 제로샷 분류 등의 장벽 없이 이미지와 텍스트를 빠르게 시작할 수 있으며 이미지 생성과 같은 보다 복잡한 다중 모드 애플리케이션을 구축하는 데 사용할 수 있습니다. 중국 복합분야에서 자신의 재능을 뽐내고 싶은 친구들, 놓치지 마세요! 그리고 이는 Moda 커뮤니티의 애플리케이션 중 하나일 뿐입니다. ModelScope를 사용하면 AI 분야의 많은 기본 모델이 애플리케이션 기반 역할을 수행하여 보다 혁신적인 모델, 애플리케이션, 심지어 제품의 탄생을 지원할 수 있습니다. 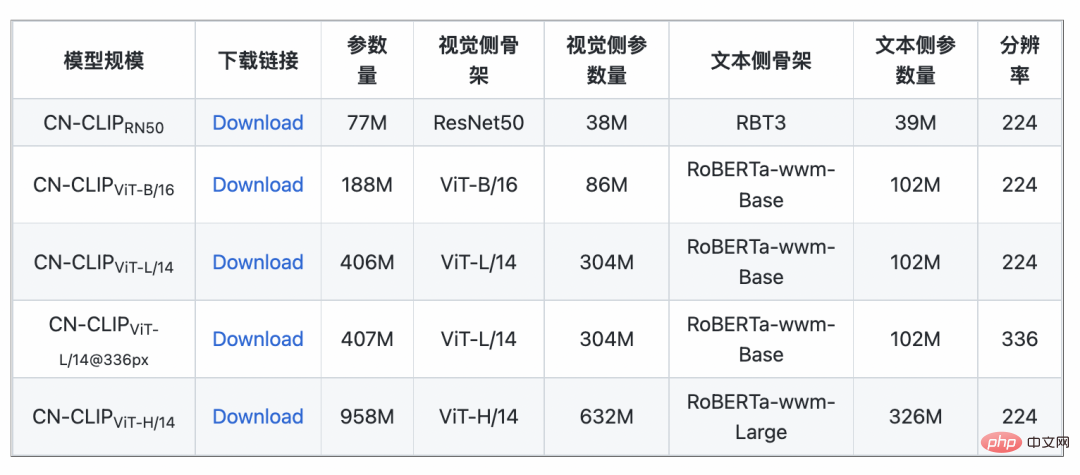
3. 실험
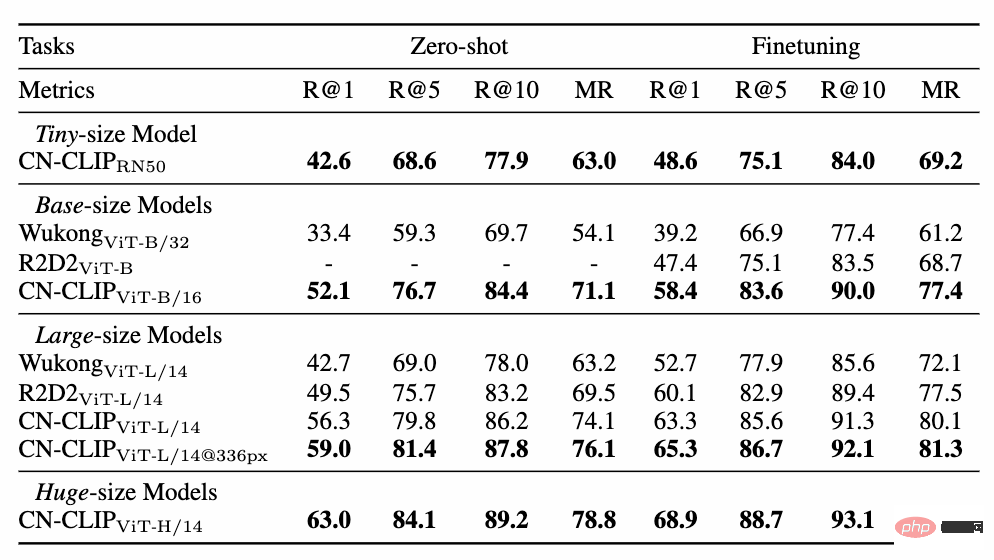
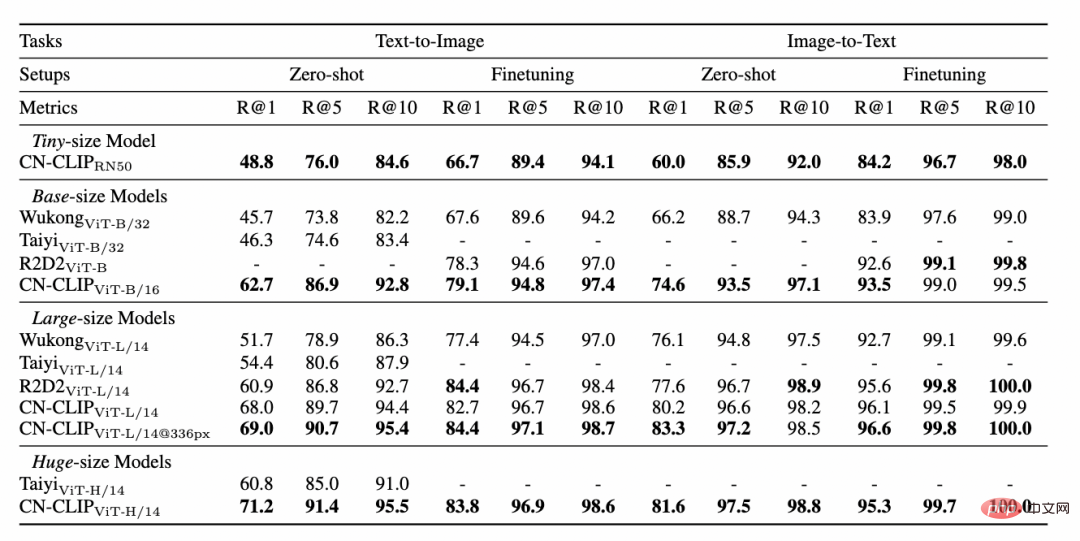
4. 빠른 사용

5. 결론
위 내용은 CLIP은 정말 현실적이지 않나요? 중국어를 더 잘 이해하는 모델이 필요합니다의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!