
ChatGPT와 강화 학습을 사용하여 'Minecraft'를 플레이하면 Plan4MC가 24개의 복잡한 작업을 극복합니다.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-04-25 08:37:061174검색
개방된 환경에서 다양한 업무를 학습하는 것은 범용 에이전트의 중요한 능력입니다. 인기 있는 오픈 월드 게임인 Minecraft는 무한히 생성되는 복잡한 세계와 수많은 공개 작업을 갖추고 있으며 최근 몇 년간 개방형 학습 연구를 위한 중요한 테스트 환경이 되었습니다.
Minecraft에서 복잡한 작업을 학습하는 것은 현재 강화 학습 알고리즘에 있어서 큰 도전입니다. 한편, 에이전트는 무한한 세계에서 국부적인 관찰을 통해 자원을 탐색하고 탐색의 어려움에 직면하게 된다. 반면, 복잡한 작업은 종종 긴 실행 시간이 필요하고 많은 암시적 하위 작업을 완료해야 합니다. 예를 들어, 돌곡괭이를 만드는 데에는 나무 베기, 나무 곡괭이 만들기, 거친 돌 파기 등 10개 이상의 하위 작업이 포함되며, 이를 완료하려면 에이전트가 수천 단계를 수행해야 합니다. 에이전트는 작업을 완료해야만 보상을 받을 수 있으며, 희박한 보상을 통해 작업을 배우기가 어렵습니다.

사진: 마인크래프트에서 돌곡괭이를 만드는 과정.
MineRL 다이아몬드 채굴 대회와 관련된 현재 연구에서는 일반적으로 전문가가 입증한 데이터 세트를 사용하는 반면, VPT와 같은 연구에서는 다수의 분류된 데이터 학습 전략을 사용합니다. 추가 데이터 세트가 없으면 강화 학습으로 Minecraft를 훈련하는 작업은 매우 비효율적입니다. MineAgent는 PPO 알고리즘을 사용하여 몇 가지 간단한 작업만 완료할 수 있습니다. 또한 모델 기반 SOTA 방법 Dreamer-v3은 환경 시뮬레이터를 단순화할 때 원석을 얻는 방법을 배우기 위해 1천만 단계를 샘플링해야 합니다.
북경 대학교와 베이징 Zhiyuan 인공 지능 연구소 팀은 전문가 데이터 없이 Minecraft 멀티태스킹을 효율적으로 해결하는 방법인 Plan4MC을 제안했습니다. 저자는 강화 학습과 계획 방법을 결합하여 복잡한 작업 해결을 기본 기술 학습과 기술 계획의 두 부분으로 분해합니다. 저자는 세 가지 유형의 세분화된 기본 기술을 훈련하기 위해 내재적 보상 강화 학습 방법을 사용합니다. 에이전트는 대규모 언어 모델을 사용하여 스킬 관계 그래프를 구축하고 그래프 검색을 통해 작업 계획을 얻습니다. 실험적인 부분에서 Plan4MC는 현재 24개의 복잡하고 다양한 작업을 완료할 수 있으며 모든 기본 방법에 비해 성공률이 크게 향상되었습니다.

- 페이퍼 링크: https://arxiv.org/abs/2303.16563
- 코드 링크: https://github.com/PKU-RL/Plan4MC
- 프로젝트 홈페이지 : https://sites.google.com/view/plan4mc
1. Minecraft 멀티 태스킹
Minecraft에서는 플레이어가 탐색을 통해 수백 가지 아이템을 얻을 수 있습니다. 태스크는 초기 조건과 대상 항목의 조합으로 정의됩니다. 예를 들어 "
작업대를 초기화하고 익힌 쇠고기를 얻습니다." 이 작업을 해결하는 데에는 "소고기 얻기", "작업대와 거친 돌로 화로 만들기"와 같은 단계가 포함됩니다. 이러한 세분화된 단계를 스킬이라고 합니다. 인간은 이러한 기술을 습득하고 결합하여 각 작업을 독립적으로 학습하는 것이 아니라 세상의 다양한 작업을 완료합니다. Plan4MC의 목표는 많은 기술을 습득하기 위한 전략을 학습하고 계획을 통해 기술을 작업에 결합하는 것입니다.
저자는 MineDojo 시뮬레이터에서 다양한 동작(나무 자르기, 거친 바위 파기, 동물과 상호 작용), 다양한 지형을 다루고 37가지 기본 기술을 포함하는 24가지 테스트 작업을 구축했습니다. 개별 작업을 완료하려면 수십 단계의 기술과 수천 단계의 환경 상호 작용이 필요합니다.务 그림: 24개 작업 설정
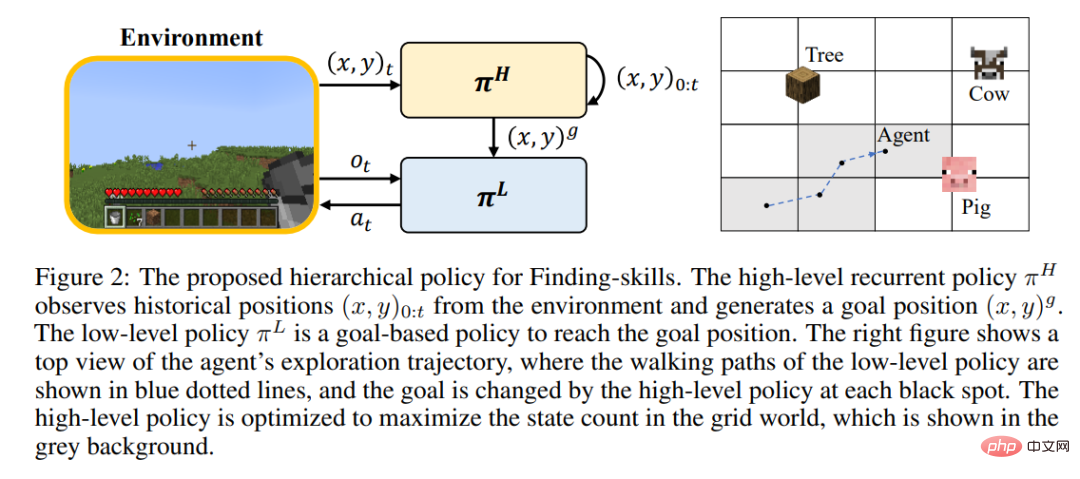
2, Plan4mc 방법 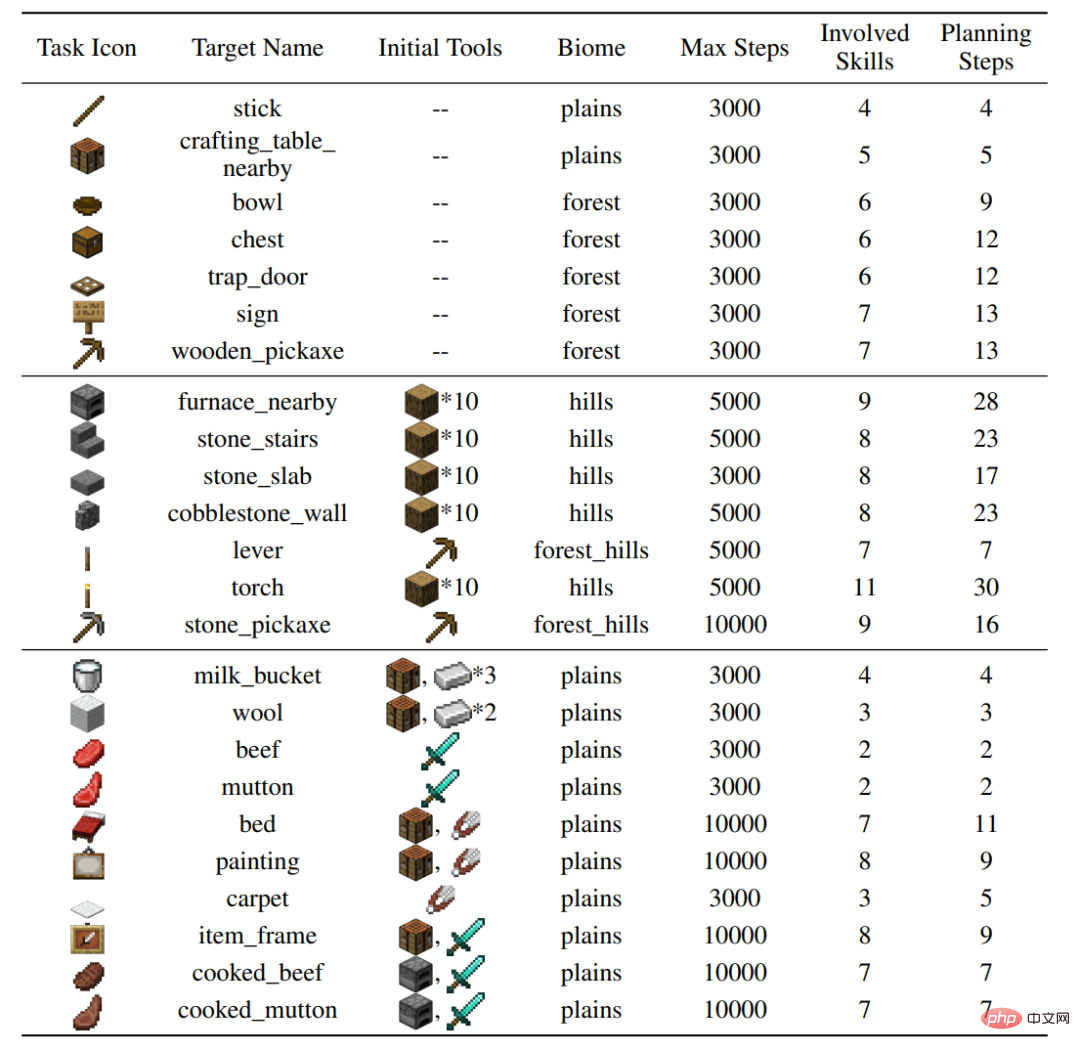
학습 기술
강화 학습은 플레이어가 훈련 중에 대규모로 달리고 세계를 탐험하는 것을 어렵게 만들기 때문에 여전히 많은 기술을 숙달할 수 없습니다. 저자는 탐색과 탐색의 단계를 분리하고, '나무 베기' 스킬을 '나무 찾기'와 '나무 얻기'로 더욱 세분화하자고 제안했다. Minecraft의 모든 기술은 세분화된 기본 기술의 세 가지 범주로 나뉩니다.
- 찾기: 대상 아이템이 주어지면 플레이어는 해당 아이템을 찾고 접근하기 위해 세계를 탐험해야 합니다.
- 작업: 기존 도구를 사용하여 작업대 배치, 동물과 상호 작용, 블록 파기 등 근처의 일부 작업을 완료하세요.
- 합성: 낮은 레벨의 아이템을 사용해 높은 레벨의 아이템을 합성하세요.
각 기술 유형에 대해 저자는 효율적인 학습을 위한 강화 학습 모델과 내재적 보상을 설계합니다. 수색 스킬은 계층적 전략을 사용하는데, 상위 전략은 목표 위치 부여 및 탐색 범위 증가를 담당하고, 하위 전략은 목표 위치 도달을 담당한다. 운영 기술은 MineCLIP 모델의 본질적인 보상과 결합된 PPO 알고리즘을 사용하여 교육됩니다. 합성 스킬은 한 번의 동작만 사용하여 완료합니다. 수정되지 않은 MineDojo 시뮬레이터에서 모든 기술을 익히려면 환경과 상호 작용하는 650만 단계만 필요합니다.
계획 알고리즘
Plan4MC는 계획을 위해 기술 간의 종속성을 사용합니다. 다른 기술들.

저자는 대규모 언어 모델 ChatGPT와 상호 작용하여 모든 기술 간의 관계를 생성하고 기술의 방향성 비순환 그래프를 구성했습니다. 기획 알고리즘은 아래 그림과 같이 스킬 그래프에 대한 깊이 우선 검색입니다.

대규모 언어 모델을 사용하는 내부 독백, DEPS 및 기타 대화형 계획 방법과 비교하여 Plan4MC는 대규모 언어 모델의 계획 프로세스에서 오류를 효과적으로 방지할 수 있습니다.
3. 실험 결과
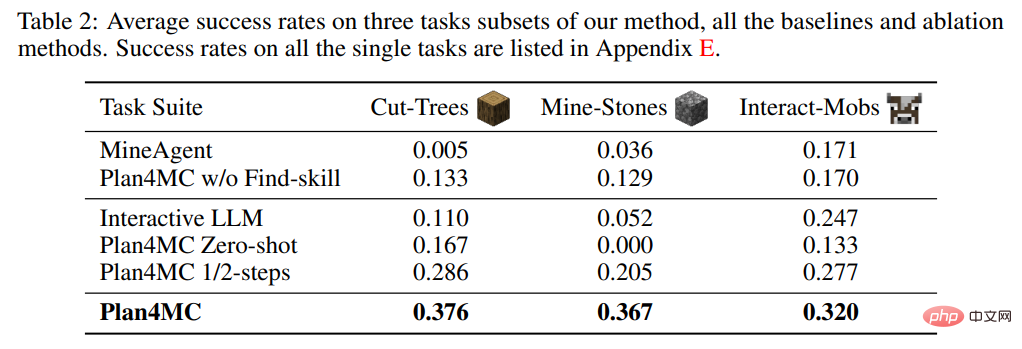
저자는 학습 능력 연구에서 작업 분해가 없는 MineAgent와 검색 능력을 세분화하지 않은 제거 실험인 Plan4MC w/o Find를 도입했습니다. 표 2는 Plan4MC가 세 가지 작업 세트 모두에서 기본 방법보다 훨씬 뛰어난 성능을 보여줍니다. MineAgent의 성능은 소 젖 짜기, 양털 깎기 등 간단한 작업에서는 Plan4MC에 가깝지만, 나무 베기, 거친 돌 파기 등 탐색하기 어려운 작업은 수행할 수 없습니다. 기술 세분화가 없는 방법은 모든 작업에서 Plan4MC보다 성공률이 낮습니다.
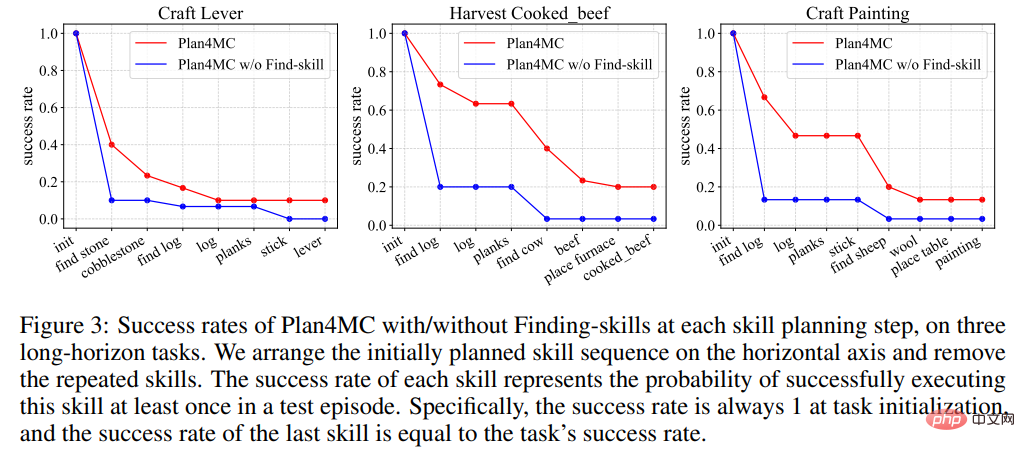
그림 3은 작업을 완료하는 과정에서 각 방법이 목표를 찾는 단계에서 실패 확률이 더 높아 성공률 곡선이 감소하는 것을 보여줍니다. 이 단계에서 기술 세분화가 없는 방법의 실패 확률은 Plan4MC의 실패 확률보다 훨씬 높습니다.
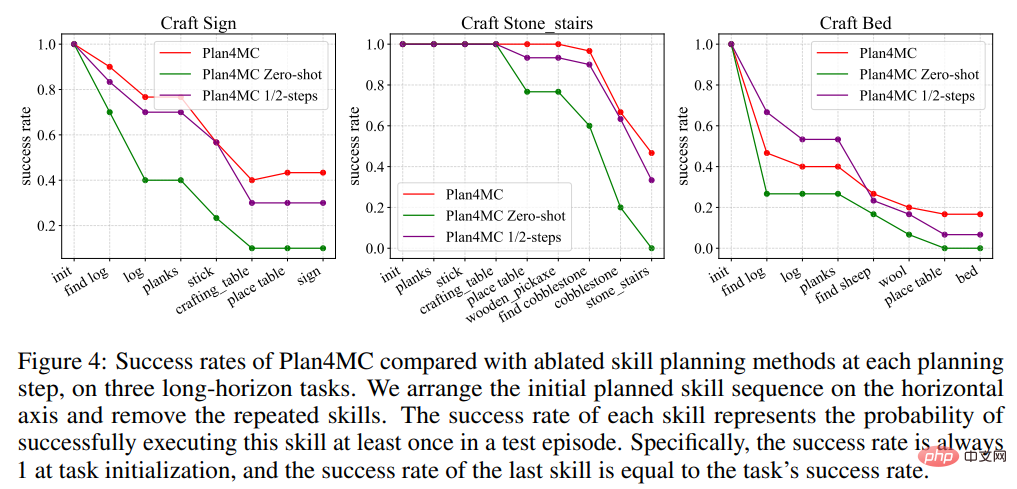
계획에 관한 연구에서 저자는 ChatGPT를 활용한 대화형 계획의 기본 방법인 Interactive LLM과 두 가지 절제 실험(스킬 실행 실패 시 다시 계획을 세우지 않는 Zero-shot 방법과 최대 절반의 사용)을 소개했습니다. 상호작용 단계 수 1/2단계 방법. 표 2는 Interactive LLM이 동물과 상호 작용하는 작업 세트에서는 Plan4MC에 가깝게 수행되지만 더 많은 계획 단계가 필요한 다른 두 작업 세트에서는 제대로 수행되지 않음을 보여줍니다. 제로샷 방법은 모든 작업에서 제대로 수행되지 않습니다. 절반의 단계를 사용하는 성공률은 Plan4MC보다 크게 낮지 않습니다. Plan4MC는 더 적은 단계로 작업을 효율적으로 완료할 수 있는 것 같습니다.
4. 요약
저자는 강화학습과 계획을 활용하여 마인크래프트에서 멀티태스킹을 해결하는 Plan4MC를 제안했습니다. 탐색 난이도와 표본 효율성 문제를 해결하기 위해 저자는 내재적 보상이 포함된 강화 학습을 사용하여 기본 기술을 훈련하고 대규모 언어 모델을 사용하여 작업 계획을 위한 기술 그래프를 구축합니다. 저자는 수많은 어려운 Minecraft 작업에서 ChatGPT를 포함한 다양한 기본 방법과 비교하여 Plan4MC의 장점을 확인했습니다.
결론: 강화 학습 기술 + 대규모 언어 모델 + 작업 계획을 통해 Daniel Kahneman이 설명한 System1/2 인간 의사 결정 모델을 구현할 수 있습니다.
위 내용은 ChatGPT와 강화 학습을 사용하여 'Minecraft'를 플레이하면 Plan4MC가 24개의 복잡한 작업을 극복합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!