
집 >데이터 베이스 >MySQL 튜토리얼 >mysql 팬텀 읽기란 무엇입니까?
mysql 팬텀 읽기란 무엇입니까?

- PHP中文网원래의
- 2023-04-19 15:46:473302검색
mysql에서 팬텀 읽기는 사용자가 특정 범위의 데이터 행을 읽을 때 다른 트랜잭션이 해당 범위에 새 행을 삽입하는 것을 의미합니다. 범위. "팬텀" 라인. 소위 팬텀 읽기(Phantom Read)는 SELECT를 통해 쿼리한 데이터 세트가 실제 데이터 세트가 아니라 사용자가 SELECT 문을 통해 특정 레코드가 존재하지 않지만 실제 테이블에 존재할 수 있음을 쿼리하는 것을 의미합니다.

이 튜토리얼의 운영 환경: windows7 시스템, mysql8 버전, Dell G3 컴퓨터.
팬텀리딩이란 무엇인가요
먼저 트랜잭션의 격리 수준을 살펴보겠습니다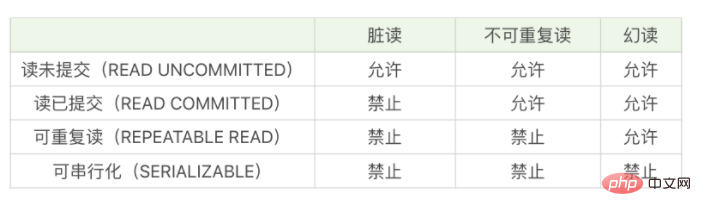
그럼 팬텀리딩에 대해 이야기하기 전에 먼저 팬텀리딩에 대한 나의 이해에 대해 말씀드리겠습니다.
소위 환상리딩의 핵심은 "환상"이라는 단어는 굉장히 몽환적이고 신비롭다. 그것이 사실인지 아닌지 불확실하다. 마치 안개에 휩싸인 것과 같다. 상대방을 실제로 볼 수 없고, 사람들에게 환상이라는 느낌을 주는 것이 바로 '환상'이다. 소위 팬텀 읽기(phantom read)는 SELECT 문을 통해 쿼리한 데이터 세트가 실제 데이터 세트가 아니지만 SELECT 문을 통해 쿼리한 특정 레코드가 실제 테이블에 존재할 수 있음을 의미합니다.
내가 환상 읽기와 비반복 읽기를 이해하는 방법은 다음과 같습니다.
-
유령 읽기는 존재 여부에 관한 것입니다. 이전에는 존재하지 않았지만 지금 존재한다면 그것은 존재합니다. 환상 읽기 li>幻读说的是存不存在的问题:原来不存在的,现在存在了,则是幻读 -
不可重复读说的是变没变化的问题:原来是A,现在却变为了B,则为不可重复读
幻读,目前我了解的有两种说法:
说法一:事务 A 根据条件查询得到了 N 条数据,但此时事务 B 删除或者增加了 M 条符合事务 A 查询条件的数据,这样当事务 A 再次进行查询的时候真实的数据集已经发生了变化,但是A却查询不出来这种变化,因此产生了幻读。
这一种说法强调幻读在于某一个范围内的数据行变多或者是变少了,侧重说明的是数据集不一样导致了产生了幻读。
说法二:幻读并不是说两次读取获取的结果集不同,幻读侧重的方面是某一次的 select 操作得到的结果所表征的数据状态无法支撑后续的业务操作。更为具体一些:A事务select 某记录是否存在,结果为不存在,准备插入此记录,但执行 insert 时发现此记录已存在,无法插入,此时就发生了幻读。产生这样的原因是因为有另一个事务往表中插入了数据。
我个人更赞成第一种说法。
说法二这种情况也属于幻读,说法二归根到底还是数据集发生了改变,查询得到的数据集与真实的数据集不匹配。
对于说法二:当进行INSERT的时候,也需要隐式的读取,比如插入数据时需要读取有没有主键冲突,然后再决定是否能执行插入。如果这时发现已经有这个记录了,就没法插入。所以,SELECT 显示不存在,但是INSERT的时候发现已存在,说明符合条件的数据行发生了变化,也就是幻读的情况,而不可重复读指的是同一条记录的内容被修改了。
举例来说明:说法二说的是如下的情况:
有两个事务A和B,A事务先开启,然后A开始查询数据集中有没有id = 30的数据,查询的结果显示数据中没有id = 30的数据。紧接着又有一个事务B开启了,B事务往表中插入了一条id = 30的数据,然后提交了事务。然后A再开始往表中插入id = 30的数据,由于B事务已经插入了id = 30的数据,自然是不能插入,紧接着A又查询了一次,结果发现表中没有id = 30的数据呀,A事务就很纳闷了,怎么会插入不了数据呢。当A事务提交以后,再次查询,发现表中的确存在id = 30的数据。但是A事务还没提交的时候,却查不出来?
其实,这便是可重复读的作用。
过程如下图所示:

上图中操作的t表的创建语句如下:
CREATE TABLE `t` ( `id` int(11) NOT NULL, `c` int(11) DEFAULT NULL, `d` int(11) DEFAULT NULL, PRIMARY KEY (`id`), KEY `c` (`c`) -- 创建索引 ) ENGINE=InnoDB; INSERT INTO t VALUES(0,0,0),(5,5,5), (10,10,10),(15,15,15),(20,20,20),(25,25,25);
MySQL使用的InnoDB引擎默认的隔离级别是可重复读Non-repeatable read는 변화의 문제에 관한 것입니다. 예전에는 A였지만 지금은 B로 바뀌었고, 그 다음에는 non-repeatable read입니다
환상 읽기, 지금까지 이해한 이론은 두 가지가 있습니다. 🎜🎜🎜🎜 이론 1🎜: 트랜잭션 A가 조건부 쿼리를 기반으로 N개의 데이터를 얻었지만 이때, 트랜잭션 B는 트랜잭션 A의 쿼리 조건에 맞는 M개의 데이터를 삭제하거나 추가했습니다. 이렇게 트랜잭션 A가 다시 쿼리하면 실제 데이터 세트가 변경되었지만 A는 이 변경 사항을 쿼리할 수 없으므로 팬텀 읽기가 발생합니다. 🎜🎜🎜이 설명은 특정 범위에 데이터 행이 더 많거나 적을 때 가상 읽기가 발생한다는 점을 강조합니다. 서로 다른 데이터 세트가 가상 읽기로 이어진다는 점을 강조합니다. 🎜🎜🎜🎜두 번째 진술🎜: 팬텀 읽기는 두 번의 읽기로 얻은 결과 세트가 다르다는 것을 의미하지 않습니다. 팬텀 읽기의 초점은 특정 선택 작업의 결과로 표시되는 데이터 상태가 후속 비즈니스 작업을 지원할 수 없다는 것입니다. 좀 더 구체적으로 말하자면, 트랜잭션 A가 특정 레코드가 존재하는지 여부를 선택했는데, 그 결과 존재하지 않는 것으로 나타났습니다. 이 레코드를 삽입하려고 준비했지만, 삽입 실행 시 이 레코드가 이미 존재하여 삽입할 수 없는 것으로 나타났습니다. 이번에는 가상 읽기가 발생합니다. 그 이유는 다른 트랜잭션이 테이블에 데이터를 삽입했기 때문입니다. 🎜🎜
🎜 개인적으로 첫 번째 말씀에 더 동의합니다. 🎜🎜두 번째 인수도 가상 읽기입니다. 두 번째 인수는 데이터 세트가 변경되었으며 쿼리로 얻은 데이터 세트가 실제 데이터 세트와 일치하지 않는다는 것입니다. 🎜🎜 문장 2의 경우: INSERT를 수행할 때 암시적 읽기도 필요합니다. 예를 들어 데이터를 삽입할 때 기본 키 충돌이 있는지 읽은 다음 삽입을 수행할 수 있는지 여부를 결정해야 합니다. 해당 레코드가 이미 존재하는 것으로 확인되면 삽입할 수 없습니다. 따라서 SELECT는 존재하지 않는다고 표시하지만 INSERT 중에 존재하는 것으로 발견되는데 이는 조건에 맞는 데이터 행이 변경되었음을 의미하는데, 이는 팬텀 읽기(Phantom Read)의 경우이고, 비반복 읽기(Non-repeatable Read)는 내용이 변경되었음을 의미한다. 동일한 레코드가 수정되었습니다. 🎜🎜예를 들어 설명하자면, 두 번째 문은 다음 상황에 대해 설명합니다. 🎜 두 개의 트랜잭션 A와 B가 있습니다. 트랜잭션 A가 먼저 열리고 A는 데이터에 ID = 30인 데이터가 있는지 쿼리하기 시작합니다. 쿼리 결과는 데이터에 ID가 30인 데이터가 없음을 나타냅니다. 그 직후 또 다른 트랜잭션 B가 열렸습니다. 트랜잭션 B는 ID = 30인 데이터 조각을 테이블에 삽입한 다음 트랜잭션을 제출했습니다. 그러면 A는 id = 30인 데이터를 테이블에 삽입하기 시작합니다. 트랜잭션 B는 이미 id = 30인 데이터를 삽입했기 때문에 자연스럽게 삽입할 수 없습니다. 그런 다음 A는 다시 쿼리하여 id = 30인 데이터가 없음을 발견합니다. 테이블, 트랜잭션 A가 매우 혼란스럽습니다. 왜 데이터를 삽입할 수 없나요? 트랜잭션 A가 제출된 후 다시 쿼리하여 ID = 30인 데이터가 테이블에 존재하는지 확인합니다. 그런데 거래 A가 제출되기 전에는 알 수 없었나요? 🎜 사실 이게
반복읽기의 역할이죠. 🎜🎜과정은 아래와 같습니다: 🎜🎜🎜🎜위 그림에서 동작하는 t 테이블의 생성문은 다음과 같습니다. 🎜SELECT * FROM player WHERE ...🎜MySQL에서 사용하는 InnoDB 엔진의 기본 격리 수준은
Repeatable Read이며, 이는 동일한 트랜잭션에서 동일한 쿼리를 두 번 실행하면 결과가 동일해야 함을 의미합니다. 따라서 트랜잭션 A가 종료되기 전에 트랜잭션 B가 테이블에 데이터를 추가했더라도 반복 읽기를 유지하기 위해 새로 추가된 데이터는 트랜잭션 A에서 어떻게 쿼리하더라도 쿼리할 수 없습니다. 그러나 실제 테이블의 경우 테이블의 데이터가 실제로 증가했습니다. 🎜
A查询不到这个数据,不代表这个数据不存在。查询得到了某条数据,不代表它真的存在。这样是是而非的查询,就像是幻觉一样,似真似假,故为幻读。
产生幻读的原因归根到底是由于查询得到的结果与真实的结果不匹配。
幻读 VS 不可重复读
-
幻读重点在于数据是否存在。原本不存在的数据却真实的存在了,这便是幻读。在同一个事务中,第一次读取到结果集和第二次读取到的结果集不同。(对比上面的例子,当B事务INSERT以后,A事务中再进行插入,此次插入相当于一次隐式查询)。引起幻读的原因在于另一个事务进行了INSERT操作。 -
不可重复读重点在于数据是否被改变了。在一个事务中对同一条记录进行查询,第一次读取到的数据和第二次读取到的数据不一致,这便是可重复读。引起不可重复读的原因在于另一个事务进行了UPDATE或者是DELETE操作。
简单来说:幻读是说数据的条数发生了变化,原本不存在的数据存在了。不可重复读是说数据的内容发生了变化,原本存在的数据的内容发生了改变。
可重复读隔离下为什么会产生幻读?
在可重复读隔离级别下,普通的查询是快照读,是不会看到别的事务插入的数据的。因此,幻读在 当前读 下才会出现。
什么是快照读,什么是当前读?
快照读读取的是快照数据。不加锁的简单的 SELECT都属于快照读,比如这样:
SELECT * FROM player WHERE ...
当前读就是读取最新数据,而不是历史版本的数据。加锁的 SELECT,或者对数据进行增删改都会进行当前读。这有点像是 Java 中的 volatile 关键字,被 volatile 修饰的变量,进行修改时,JVM 会强制将其写回内存,而不是放在 CPU 缓存中,进行读取时,JVM 会强制从内存读取,而不是放在 CPU 缓存中。这样就能保证其可见行,保证每次读取到的都是最新的值。如果没有用 volatile 关键字修饰,变量的值可能会被放在 CPU 缓存中,这就导致读取到的值可能是某次修改的值,不能保证是最新的值。
说多了,我们继续来看,如下的操作都会进行 当前读。
SELECT * FROM player LOCK IN SHARE MODE; SELECT * FROM player FOR UPDATE; INSERT INTO player values ... DELETE FROM player WHERE ... UPDATE player SET ...
说白了,快照读就是普通的读操作,而当前读包括了 加锁的读取 和 DML(DML只是对表内部的数据操作,不涉及表的定义,结构的修改。主要包括insert、update、deletet) 操作。
比如在可重复读的隔离条件下,我开启了两个事务,在另一个事务中进行了插入操作,当前事务如果使用当前读 是可以读到最新的数据的。

MySQL中如何实现可重复读
当隔离级别为可重复读的时候,事务只在第一次 SELECT 的时候会获取一次 Read View,而后面所有的 SELECT 都会复用这个 Read View。也就是说:对于A事务而言,不管其他事务怎么修改数据,对于A事务而言,它能看到的数据永远都是第一次SELECT时看到的数据。这显然不合理,如果其它事务插入了数据,A事务却只能看到过去的数据,读取不了当前的数据。
既然都说到 Read View 了,就不得不说 MVCC (多版本并发控制) 机制了。MVCC 其实字面意思还比较好理解,为了防止数据产生冲突,我们可以使用时间戳之类的来进行标识,不同的时间戳对应着不同的版本。比如你现在有1000元,你借给了张三 500 元, 之后李四给了你 500 元,虽然你的钱的总额都是 1000元,但是其实已经和最开始的 1000元不一样了,为了判断中途是否有修改,我们就可以采用版本号来区分你的钱的变动。
如下,在数据库的数据表中,id,name,type 这三个字段是我自己建立的,但是除了这些字段,其实还有些隐藏字段是 MySQL 偷偷为我们添加的,我们通常是看不到这样的隐藏字段的。

我们重点关注这两个隐藏的字段:
db_trx_id: 이 데이터 행을 조작하는 트랜잭션 ID, 즉 데이터를 삽입하거나 업데이트한 마지막 트랜잭션 ID입니다. 트랜잭션을 시작할 때마다 데이터베이스에서 트랜잭션 ID(즉, 트랜잭션 버전 번호)를 가져옵니다. 이 트랜잭션 ID는 ID 크기를 통해 트랜잭션의 시간 순서를 판단할 수 있습니다.
db_roll_ptr: 이 레코드의 Undo Log 정보를 가리키는 롤백 포인터입니다. 실행 취소 로그란 무엇입니까? 특정 레코드를 수정해야 할 때 MySQL은 나중에 수정 사항이 취소되어 이전 상태로 롤백될 수 있다고 우려하므로 수정하기 전에 현재 데이터를 파일에 저장한 후 수정하는 것이 좋습니다. , Undo Log 이 아카이브 파일로 이해될 수 있습니다. 이는 게임을 할 때와 마찬가지로 특정 레벨에 도달하면 먼저 파일을 저장한 후 다음 레벨에 도전하지 못하면 이전 저장 지점으로 돌아가는 것과 같습니다. 처음부터 시작합니다.
MVCC(다중 버전 동시성 제어) 메커니즘에서 동일한 행 레코드를 업데이트하는 여러 트랜잭션은 여러 기록 스냅샷을 생성하며 이러한 기록 스냅샷은 실행 취소 로그에 저장됩니다. 아래 그림과 같이 현재 라인에 기록된 롤백 포인터는 이전 상태를 가리키고, 이전 상태의 롤백 포인터는 이전 상태의 이전 상태를 가리킨다. 이런 방식으로 이론적으로는 롤백 포인터를 탐색하여 데이터 행의 모든 상태를 찾을 수 있습니다.
실행 취소 로그의 도식
우리가 본 것이 단지 하나의 데이터일 것이라고는 예상하지 못했지만 MySQL은 이 데이터의 여러 버전을 은밀히 저장하고 이 데이터에 대한 많은 파일을 저장했습니다. 여기서 질문이 나옵니다. 트랜잭션을 시작할 때 트랜잭션의 특정 데이터 조각을 쿼리하려고 하는데 각 데이터 조각이 여러 버전에 해당합니다. 이때 어떤 버전의 행 레코드를 읽어야 할까요?
이번에는 행 가시성 문제를 해결하는 데 도움이 되는 Read View 메커니즘을 사용해야 합니다. 읽기 보기는 현재 트랜잭션이 열릴 때 모든 활성(아직 커밋되지 않은) 트랜잭션 목록을 저장합니다.
읽기 보기에는 몇 가지 중요한 속성이 있습니다:
- trx_ids, 현재 시스템에서 활성화된 트랜잭션 ID 세트
- low_limit_id, 활성 트랜잭션 중에서 가장 큰 트랜잭션 ID
- up_limit_id, active 트랜잭션의 트랜잭션 ID
- creator_trx_id, 이 읽기 보기를 생성한 트랜잭션 ID
앞서 말했듯이 레코드의 각 행에는 숨겨진 필드가 있습니다db_trx_id는 이 행을 운영하는 트랜잭션 ID를 나타냅니다. 트랜잭션 ID는 자동으로 증가합니다. ID 크기를 통해 트랜잭션의 시간 순서를 판단할 수 있습니다.
트랜잭션을 시작하고 특정 레코드에 대한 쿼리를 준비할 때 해당 레코드의 db_trx_id up_limit_id를 찾습니다. 이는 이 거래가 시작되기 전에 이 기록이 제출되어야 함을 의미합니다. 이는 과거 데이터이므로 select를 통해 이 기록을 확실히 찾을 수 있습니다.
그러나 발견되면 쿼리할 레코드의 db_trx_id > up_limit_id입니다. 이게 무슨 뜻인가요? 트랜잭션을 열었을 때 이 레코드가 아직 존재하지 않았어야 한다는 뜻입니다. 나중에 생성되었으며 현재 트랜잭션에서 볼 수 없어야 합니다. 이때 롤백 포인터 + 실행 취소 로그를 사용할 수 있습니다. 기록의 과거 버전을 찾아 현재 거래로 반환합니다. 이번 글에서는 팬텀리딩이란 무엇인가요? 이 장에 제시된 예입니다. 트랜잭션 A가 시작되면 데이터베이스에 레코드(30, 30, 30)가 없습니다. 트랜잭션 A가 시작된 후 트랜잭션 B는 레코드(30, 30, 30)를 데이터베이스에 삽입합니다. 이때 트랜잭션 A는 새로 삽입된 레코드를 스냅샷 읽기를 수행하기 위해 잠금 없이 select를 사용할 때 이 레코드를 쿼리할 수 없습니다. 우리의 기대와 일치합니다. 트랜잭션 A의 경우 이 레코드(30, 30, 30)의 db_trx_id는 트랜잭션 A가 시작될 때의 up_limit_id보다 커야 하므로 이 레코드는 트랜잭션 A에서 볼 수 없습니다. 조회해야 할 레코드의
trx_id가 up_limit_id trx_id low_limit_id 조건을 만족하는 경우 해당 행 레코드가 위치한 트랜잭션 trx_id이 현재 creator_trx_id 트랜잭션이 생성되어 여전히 활성 상태일 수 있으므로 trx_ids 컬렉션을 탐색해야 합니다. trx_id가 trx_ids 컬렉션에 있으면 이 트랜잭션 trx_id이 여전히 활성 상태임을 증명합니다. 레코드에 Undo Log가 있으면 롤백 포인터를 통해 레코드의 기록 버전 데이터를 쿼리할 수 있습니다. trx_id가 trx_ids 컬렉션에 없으면 거래 trx_id가 제출되었고 행 레코드가 표시됨을 증명합니다. 从图中你能看到回滚指针将数据行的所有快照记录都通过链表的结构串联了起来,每个快照的记录都保存了当时的 db_trx_id,也是那个时间点操作这个数据的事务 ID。这样如果我们想要找历史快照,就可以通过遍历回滚指针的方式进行查找。 最后,再来强调一遍:事务只在第一次 SELECT 的时候会获取一次 因此,如下图所示,在 可重复读 的隔离条件下,在该事务中不管进行多少次 以WHERE heigh > 2.08为条件 的查询,最终结果得到都是一样的,尽管可能会有其它事务对这个结果集进行了更改。 即便是给每行数据都加上行锁,也无法解决幻读,行锁只能阻止修改,无法阻止数据的删除。而且新插入的数据,自然是数据库中不存在的数据,原本不存在的数据自然无法对其加锁,因此仅仅使用行锁是无法阻止别的事务插入数据的。 为了解决幻读问题,InnoDB 只好引入新的锁,也就是间隙锁 表 t 主键索引上的行锁和间隙锁 怎么加间隙锁呢?使用写锁(又叫排它锁,X锁)时自动生效,也就是说我们执行 如下图所示,如果在事务A中执行了 数据表的创建语句如下 需要注意的是,由于创建数据表的时候仅仅只在c字段上创建了索引,因此使用条件 因此当B想插入一条数据(1, 1, 1)时就会被阻塞住,因为它的主键位于位于(0, 5]这个区间,被禁止插入。 还需要注意的一点是, 如下: A事务对id = 5的数据加了写锁,B事务再对id = 5的数据加写锁则会失败,若B事务加读锁同样也会失败。 갭 잠금의 목적은 이 간격에 데이터가 삽입되는 것을 방지하는 것입니다. 따라서 트랜잭션 A가 추가된 후에도 트랜잭션 B는 계속해서 갭 잠금을 추가합니다. 이는 모순되지 않습니다. 그러나 쓰기 잠금과 읽기 잠금은 다릅니다. 【관련 추천: mysql 비디오 튜토리얼】Read View
如何解决幻读
(Gap Lock)。顾名思义,间隙锁,锁的就是两个值之间的空隙。比如文章开头的表 t,初始化插入了 6 个记录,这就产生了 7 个间隙。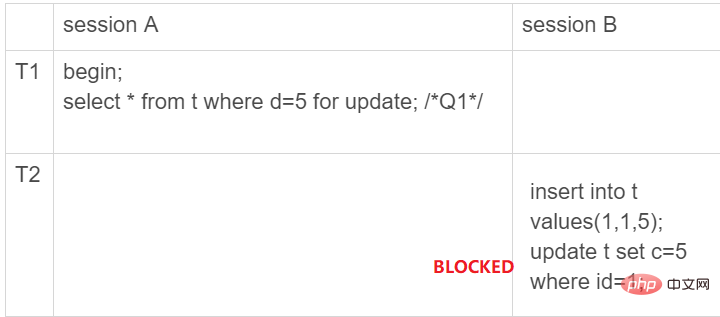
也就是说这时候,在一行行扫描的过程中,不仅将给行加上了行锁,还给行两边的空隙,也加上了间隙锁。现在你知道了,数据行是可以加上锁的实体,数据行之间的间隙,也是可以加上锁的实体。但是间隙锁跟我们之前碰到过的锁都不太一样。
SELECT * FEOM t FOR UPDATE要把整个表所有记录锁起来,就形成了 7 个 next-key lock,分别是 (负无穷,0]、(0,5]、(5,10]、(10,15]、(15,20]、(20, 25]、(25, 正无穷]。SELECT * FEOM t FOR UPDATE时便会自动触发间隙锁。会给主键加上上图所示的锁。SELECT * FROM t WHERE d = 5 FOR UPDATE以后,事务B则无法插入数据了,因此就避免了产生幻读。CREATE TABLE `t` (
`id` int(11) NOT NULL,
`c` int(11) DEFAULT NULL,
`d` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `c` (`c`) -- 创建索引
) ENGINE=InnoDB;
INSERT INTO t VALUES(0,0,0),(5,5,5),
(10,10,10),(15,15,15),(20,20,20),(25,25,25);
WHERE id = 5查找时是会扫描全表的。因此,SELECT * FROM t WHERE d = 5 FOR UPDATE实际上锁住了整个表,如上图所示,产生了七个间隙,这七个间隙都不允许数据的插入。间隙锁和间隙锁是不会产生冲突的。读锁(又称共享锁,S锁)和写锁会冲突,写锁和写锁也会产生冲突。但是间隙锁和间隙锁是不会产生冲突的
A事务对id = 5的数据加了读锁,B事务再对id = 5的数据加写锁则会失败,若B事务加读锁则会成功。读锁和读锁可以兼容,读锁和写锁则不能兼容。
在加了间隙锁以后,当A事务开启以后,并对(5, 10]这个区间加了间隙锁,那么B事务则无法插入数据了。
但是当A事务对(5, 10]加了间隙锁以后,B事务也可以对这个区间加间隙锁。
쓰기 잠금은 다른 트랜잭션이 읽거나 쓰는 것을 허용하지 않는 반면, 읽기 잠금은 쓰기를 허용하므로 의미상 충돌이 있습니다. 당연히 이 두 개의 잠금을 동시에 추가할 수는 없습니다.
쓰기 잠금과 쓰기 잠금도 마찬가지입니다. 쓰기 잠금은 읽기나 쓰기를 허용하지 않습니다. 생각해 보면 트랜잭션 A는 데이터에 쓰기 잠금을 추가하는데, 이는 다른 트랜잭션이 데이터에 대해 작동하는 것을 원하지 않는다는 의미입니다. 그런 다음 이 데이터에 다른 데이터를 사용할 수 있는 경우 쓰기 잠금을 추가하는 것은 데이터에 대한 작업을 수행하는 것과 동일하며 이는 쓰기 잠금의 의미를 위반하므로 당연히 허용되지 않습니다.
위 내용은 mysql 팬텀 읽기란 무엇입니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!