
인간은 AI가 학습할 수 있는 고품질 코퍼스가 충분하지 않으며 2026년에는 고갈될 것입니다. 네티즌: 대규모 인간 텍스트 생성 프로젝트가 시작되었습니다!

- PHPz앞으로
- 2023-04-16 17:49:031439검색
AI의 식욕은 너무 크고 인간 코퍼스 데이터로는 더 이상 충분하지 않습니다.
Epoch 팀의 새로운 논문에 따르면 AI는 5년 이내에 모든 고품질 코퍼스를 사용하게 될 것입니다.

이것은 인간 언어 데이터의 증가율을 고려한 예측 결과라는 것을 알아야 합니다. 즉, 지난 몇 년간 인간이 작성한 새로운 논문과 코드가 모두 AI에 공급된다고 해도, 충분하지 않습니다.
이러한 개발이 계속된다면 수준 향상을 위해 고품질 데이터에 의존하는 대규모 언어 모델은 곧 병목 현상에 직면하게 될 것입니다.
일부 네티즌들은 이미 가만히 앉아있을 수 없습니다.
이건 정말 말도 안됩니다. 인간은 인터넷에 있는 모든 내용을 읽지 않고도 효과적으로 스스로를 훈련할 수 있습니다.
우리에게는 더 많은 데이터가 아닌 더 나은 모델이 필요합니다.
일부 네티즌들은 AI가 뱉은 것을 먹게 하는 것이 낫다고 비웃었습니다.
AI 자체에서 생성한 텍스트를 저품질 데이터로 AI에 공급할 수 있습니다.

한 번 살펴볼까요? 인간이 남긴 데이터는 얼마나 될까요?
텍스트 및 이미지 데이터 "인벤토리"는 어떻습니까?
이 논문은 주로 텍스트와 이미지 데이터를 예측합니다.
먼저 텍스트 데이터입니다.
데이터의 품질은 보통 좋은 것부터 나쁜 것까지 다양합니다. 저자는 기존의 대형 모델과 기타 데이터에서 사용하는 데이터 유형을 기준으로 사용 가능한 텍스트 데이터를 저품질 부분과 고품질 부분으로 나누었습니다.
고품질 코퍼스는 Wikipedia, 뉴스, GitHub의 코드, 출판된 서적 등을 포함하여 Pile, PaLM 및 MassiveText와 같은 대규모 언어 모델에서 사용되는 학습 데이터 세트를 의미합니다.
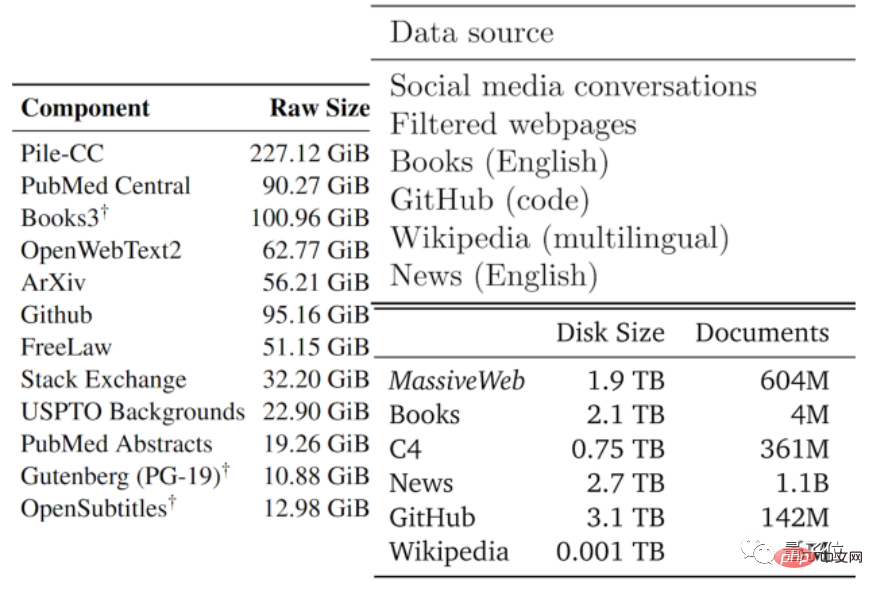
Reddit 등 소셜 미디어의 트윗, 비공식 팬픽션(팬픽)에서 품질이 낮은 코퍼스가 나옵니다.
통계에 따르면 고품질 언어 데이터 재고에는 약 4.6×10^12~1.7×10^13 단어만 남아 있는데, 이는 현재 최대 텍스트 데이터 세트보다 한 자릿수도 안되는 수치입니다.
성장률을 종합하면 2023년에서 2027년 사이에 AI에 의해 고품질 텍스트 데이터가 고갈될 것으로 예측하고 있으며, 추정 노드는 2026년경이다.
조금 빠른 것 같네요...
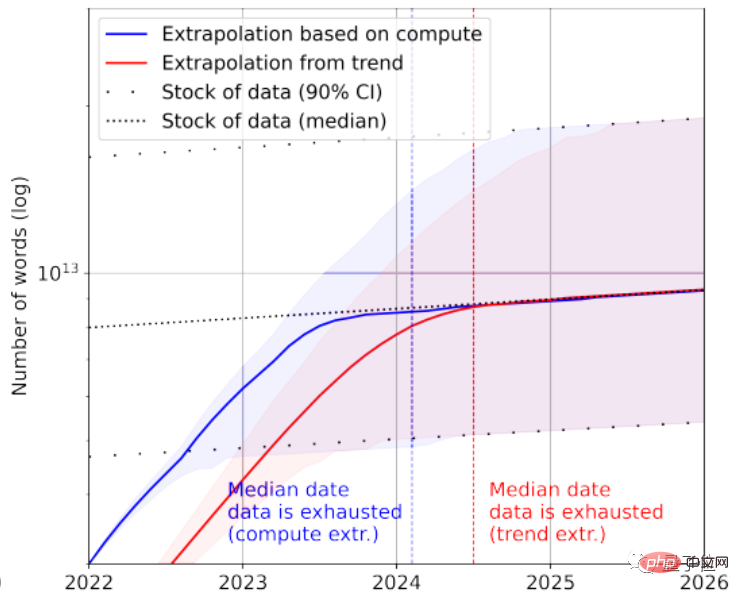
물론 저품질의 텍스트 데이터도 구조에 추가될 수 있습니다. 통계에 따르면 현재 전체 텍스트 데이터 재고에는 7×10^13~7×10^16 단어가 남아 있으며 이는 가장 큰 데이터 세트보다 1.5~4.5배 더 큰 규모입니다.
데이터 품질에 대한 요구 사항이 높지 않으면 AI는 2030년에서 2050년 사이에 모든 텍스트 데이터를 사용합니다.
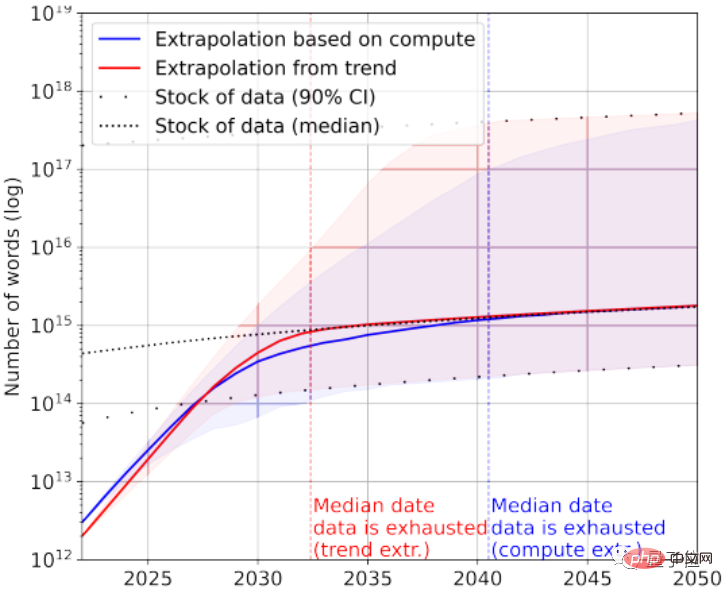
이미지 데이터를 다시 보면 여기 종이는 화질에 따른 구분이 없습니다.
현재 가장 큰 이미지 데이터 세트에는 3×10^9 이미지가 있습니다.
통계에 따르면 현재 총 이미지 수는 약 8.11×10^12~2.3×10^13으로, 이는 가장 큰 이미지 데이터 세트보다 3~4자리 더 많습니다.
논문에서는 2030년에서 2070년 사이에 AI가 이러한 이미지를 고갈시킬 것이라고 예측합니다.
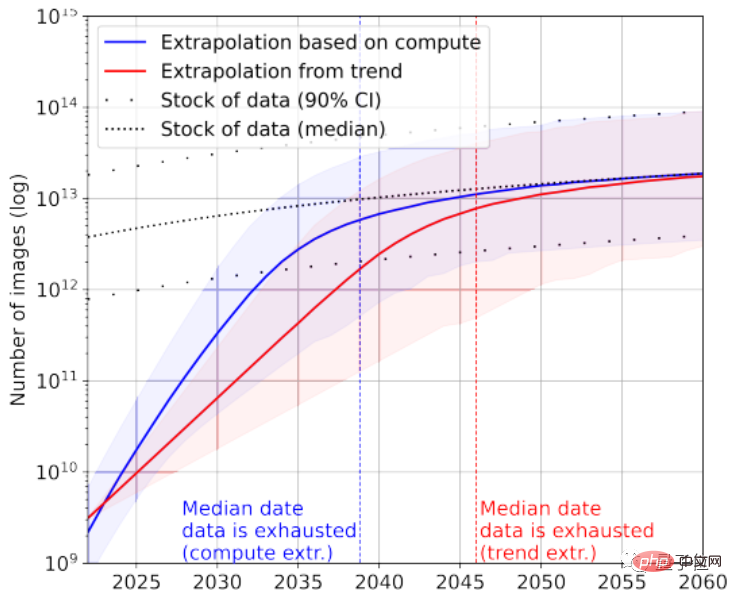
분명히 대형 언어 모델은 이미지 모델보다 더 심각한 "데이터 부족" 상황에 직면합니다.
그렇다면 어떻게 이런 결론이 나왔나요?
네티즌이 게시한 일일 평균 게시물 수 계산
본 논문은 텍스트 이미지 데이터 생성 효율성과 학습 데이터 세트의 증가를 두 가지 관점에서 분석합니다.
논문에 나오는 통계가 모두 레이블이 지정된 데이터는 아니라는 점에 주목할 필요가 있습니다. 비지도 학습이 상대적으로 인기가 있다는 점을 고려하면 레이블이 없는 데이터도 포함되어 있습니다.
텍스트 데이터를 예로 들면 대부분의 데이터는 소셜 플랫폼, 블로그 및 포럼에서 생성됩니다.
텍스트 데이터 생성 속도를 추정하려면 총 인구, 인터넷 보급률, 인터넷 사용자가 생성하는 평균 데이터 양의 세 가지 요소를 고려해야 합니다.
예를 들어, 이는 과거 인구 데이터와 인터넷 사용자 수를 기반으로 한 예상 미래 인구 및 인터넷 사용자 증가 추세입니다.
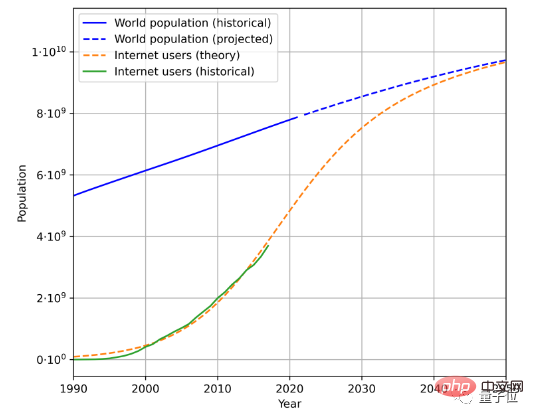
사용자가 생성한 평균 데이터 양과 결합하면 데이터 생성 속도는 계산됩니다. (복잡한 지리적, 시간적 변화로 인해 논문에서는 사용자가 생성하는 평균 데이터량의 계산 방법을 단순화했습니다.)
이 방법에 따르면 언어 데이터의 증가율은 약 7%로 계산되지만 이 증가율은 시간이 지남에 따라 점차 감소합니다.
2100년에는 언어 데이터 증가율이 1%로 감소할 것으로 예상됩니다.
이미지 데이터를 분석하는 데에도 비슷한 방법이 사용됩니다. 현재 증가율은 약 8%입니다. 그러나 이미지 데이터의 증가율도 2100년에는 약 1%로 둔화됩니다.
논문에서는 고품질 데이터로 훈련된 이미지이든 텍스트 대형 모델이든 데이터 증가율이 크게 증가하지 않거나 새로운 데이터 소스가 등장하면 특정 단계에서 병목 현상이 발생할 수 있다고 믿습니다.
일부 네티즌들은 이에 대해 농담을 했고, 미래에는 SF 스토리 같은 일이 일어날 수도 있습니다.
AI를 훈련시키기 위해 인간은 대규모 텍스트 생성 프로젝트를 시작했고 모두가 AI를 위한 글을 쓰기 위해 열심히 노력하고 있습니다.
일종의 "AI 교육"이라고 합니다.
우리는 매년 14만~260만 단어의 텍스트 데이터를 AI에 보냅니다. 인간을 배터리로 사용하는 것보다 더 멋있게 들리나요?
어떻게 생각하세요?
논문 주소: https://arxiv.org/abs/2211.04325
참조 링크: https://twitter.com/emollick/status/1605756428941246466
위 내용은 인간은 AI가 학습할 수 있는 고품질 코퍼스가 충분하지 않으며 2026년에는 고갈될 것입니다. 네티즌: 대규모 인간 텍스트 생성 프로젝트가 시작되었습니다!의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!