
Python 퀀트 트레이딩 실습: 주식 데이터 획득 및 분석

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-04-15 21:13:012336검색
정량매매(자동매매라고도 함)는 수학적 모델을 적용하여 컴퓨터 프로그램에서 보낸 지시에 따라 투자자가 판단하고 거래를 수행할 수 있도록 돕는 투자 방법입니다. 퀀트 트레이딩의 주요 장점은 다음과 같습니다.
- 빠른 탐지
- 객관적이고 합리적
- 자동화
퀀트 트레이딩의 핵심은 전략도 수학적 또는 물리적 모델을 기반으로 만들어지며 수학적 언어를 변환하는 것입니다. 컴퓨터 언어. 퀀트 트레이딩의 과정은 데이터 수집부터 데이터 분석 및 처리까지 이루어집니다.
Data Acquisition
데이터 분석의 첫 번째 단계는 데이터를 얻는 것, 즉 데이터 수집입니다. 데이터를 얻는 방법은 다양합니다. 일반적으로 데이터 소스는 크게 외부 소스(외부 구매, 웹 크롤링, 무료 오픈 소스 데이터 등)와 내부 소스(자사 매출 데이터, 재무 데이터 등)로 구분됩니다. .).
우리는 데이터를 생산하지 않기 때문에 외부에서만 데이터를 얻을 수 있습니다. 액세스 방법은 타사 오픈 소스 라이브러리 tushare입니다.
tushare를 사용하여 과거 주식 데이터를 얻으세요
tushare는 무료 오픈 소스 Python 금융 데이터 인터페이스 패키지입니다. 주로 주식 등 금융 데이터의 데이터 수집, 정리, 처리 및 데이터 저장 프로세스를 구현하고, 재무 분석가에게 분석하기 쉬운 빠르고 깨끗하며 다양한 데이터를 제공하여 데이터 수집 작업량을 줄일 수 있습니다.
tushare 라이브러리를 설치하고 Jupter Notebook에 다음 명령을 입력합니다.
%pip install tushare
커널을 다시 시작한 후 다음 명령을 입력합니다.
import tushare
print("tushare版本号{}".format(tushare.__version__))tushare版本号1.2.85
개별 주식의 과거 거래 데이터를 얻습니다(이동 평균 데이터 포함). 사용자는 일일 K-라인, 주간 K-라인, 월간 K-라인은 물론 5분, 15분, 30분 및 매개변수 설정을 통한 60분 K라인 데이터. 본 인터페이스는 최근 3년간의 일별 데이터만 얻을 수 있으며, 이동평균 데이터와 연계하여 종목 선정 및 분석에 적합합니다. Python 코드는 다음과 같습니다.
importtushareasts
ts.get_hist_data('000001') #一次性获取全部日k线数据
'''
参数说明:
code:股票代码,即6位数字代码,或者指数代码(sh=上证指数 sz=深圳成指 hs300=沪深300指数 sz50=上证50 zxb=中小板 cyb=创业板)
start:开始日期,格式YYYY-MM-DD
end:结束日期,格式YYYY-MM-DD
ktype:数据类型,D=日k线 W=周 M=月 5=5分钟 15=15分钟 30=30分钟 60=60分钟,默认为D
retry_count:当网络异常后重试次数,默认为3
pause:重试时停顿秒数,默认为0
例如:
ts.get_hist_data('000001', ktype='W') #获取周k线数据
ts.get_hist_data('000001', ktype='M') #获取月k线数据
ts.get_hist_data('000001', ktype='5') #获取5分钟k线数据
ts.get_hist_data('000001', ktype='15') #获取15分钟k线数据
ts.get_hist_data('000001', ktype='30') #获取30分钟k线数据
ts.get_hist_data('000001', ktype='60') #获取60分钟k线数据
ts.get_hist_data('sh')#获取上证指数k线数据
ts.get_hist_data('sz')#获取深圳成指k线数据
ts.get_hist_data('hs300')#获取沪深300指数k线数据
ts.get_hist_data('000001',start='2021-01-01',end='2021-03-20') #获取”000001”从2021-01-01到2021-03-20的k线数据
'''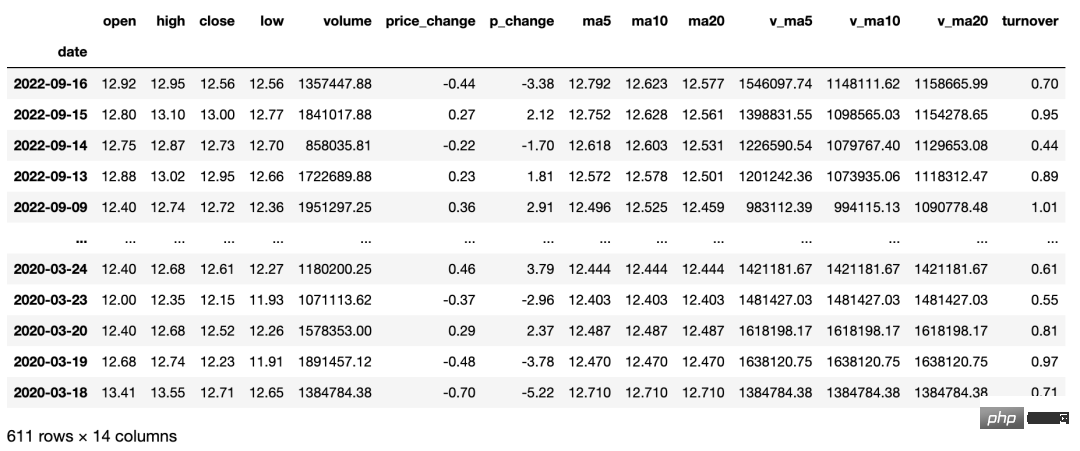
반환값에 대해 설명하면 다음과 같습니다.
- 날짜: 날짜;
- 최저가: 최고가;
- 최저가: 거래량;
- pchange: 증가 또는 감소;
- ma10: 10일 평균 가격
- ma20: 5일 평균 거래량; v_ma10: 10일 평균 평균 거래량;
- v_ma20: 20일 평균 거래량;
- 회전율: 회전율(참고: 지수에는 이 항목이 없습니다).
- tushare를 사용하여 모든 주식에 대한 실시간 데이터를 얻으세요
- 개별 주식의 과거 거래 데이터는 지연된 데이터입니다. 실시간으로 변하는 가격 데이터에 직면하여, 보다 편리해진 그날의 실시간 시장 상황을 활용하여 Python 수량화를 통해 시장 상황을 빠르게 파악하고 현재 상황에 맞는 우수 주식을 선택할 수 있습니다.
- 다음은 타사 라이브러리 tushare의 get_today_all()을 사용하여 모든 주식의 실시간 데이터를 가져옵니다(공휴일인 경우 이전 거래일입니다). 코드는 다음과 같습니다.
importtushareasts ts.get_today_all()
정량적 전략이든 단순한 기계 학습 프로젝트이든 데이터 전처리는 매우 중요한 부분입니다. 정량적 학습의 관점에서 데이터 전처리에는 주로 데이터 정리, 정렬, 결측값 또는 이상값 처리, 통계 분석, 상관 분석, 주성분 분석(PCA) 등이 포함됩니다.
전작들은 일반적인 주식 데이터를 수집했기 때문에 이번 장에서 소개할 데이터 전처리는 조건에 맞지 않는 주식 데이터를 미리 제거한 뒤, 나머지 주식을 최적화하고 선별하는 것이다. 이 장에서는 주로 Pandas 라이브러리를 사용하므로 독자는 필터링 아이디어를 이해하는 데 중점을 두어야 합니다.ST 주식 정리
 ST 주식은 일반적으로 비정상적인 재무 상태나 기타 조건을 가진 상장 기업의 주식이 거래에 있어 특별 대우(Special Treatment)가 필요함을 나타냅니다. "특혜"로 인해 ST 앞에 약어가 붙으므로 이러한 주식을 ST 주식이라고 합니다.
ST 주식은 일반적으로 비정상적인 재무 상태나 기타 조건을 가진 상장 기업의 주식이 거래에 있어 특별 대우(Special Treatment)가 필요함을 나타냅니다. "특혜"로 인해 ST 앞에 약어가 붙으므로 이러한 주식을 ST 주식이라고 합니다.
주식 이름 앞에 ST를 붙이는 것은 시장에 대한 경고입니다. 그러나 이러한 주식은 위험이 높고 수익이 높다는 의미입니다. 해당 종목은 투자 리스크가 있으므로 상장폐지 리스크에 주의할 필요가 있습니다. 특히, 2021년 4월경에 회사가 연속으로 적자를 기록하여 중국 증권감독관리위원회에 재무제표를 제출할 경우 상장폐지 리스크가 발생할 수 있습니다. 주식의 매매거래규칙도 호가일에 5% 인상, 5% 감소로 제한됩니다.
우리는 이런 종류의 "지뢰 주식"(ST 주식)을 피하고 싶기 때문에 다음 코드를 사용하여 ST 주식을 정리할 수 있습니다.
import tushareasts
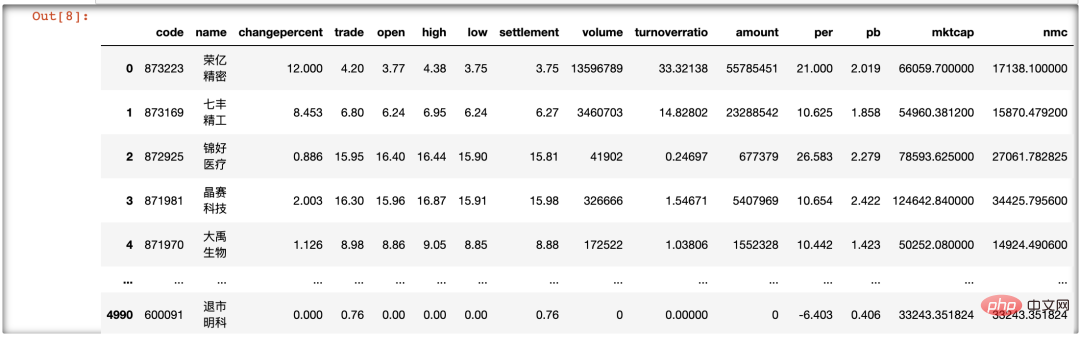
csv_data=ts.get_today_all()
csv_data[~csv_data.name.str.contains('ST')]我们对 csv_data 的 name 列进行操作,筛选出包含 ST 字母的行,并对整个 DataFrame 取反,进而筛选出不含 ST 股票的行。经过观察,我们发现在运行结果中没有 ST 股票,实现了数据的初步清洗。
清洗掉没成交量的股票
首先要明确定义,什么是没有成交量的股票。没有成交量不是成交量为零,而是一支股票单位时间的成交量不活跃。成交量是反映股市上人气聚散的一面镜子。人气旺盛、 买卖踊跃,成交量自然放大:相反人气低迷、买卖不活跃,成交量必定萎缩。成交量是观察庄家大户动态的有效途径。
下面开始清洗没成交量的股票,在原来的基础上增加代码如下:
import tushareasts
csv_data=ts.get_today_all()
csv_data=csv_data[~csv_data.name.str.contains('ST')]
csv_data[csv_data["volume"]>15000000]#15万手在以上代码中,我们对 csv_data 的 volume 列进行操作。15 万手是过滤掉不活跃、没成交量的股票,主要以小盘股居多。
其运行结果为:

Index 出现了调行现象,即为去掉成交量小手 15 万手的股票。
清洗掉成交额过小的股票
成交额是成交价格与成交数量的乘积,它是指当天已成交股票的金额总数。成交最的至少取决于市场的投资热情。我们每天看大盘,一个重要的指标就是大 A 股成交量是否超过一万亿元,超过即为成交活跃。
筛选成交额超过 1 亿元的股票,代码如下:
import tushareasts
csv_data=ts.get_today_all()
csv_data=csv_data[~csv_data.name.str.contains('ST')]
csv_data=csv_data[csv_data["volume"]>15000000]#15万手
csv_data["amount"]=round(csv_data["amount"]/100000000,2)#一亿,保留2位
csv_data[(csv_data["amount"]>1)]筛选股票的数量没有锐减,这是因为成交额-成交价格×成交量。有些股票价格低,成交量巨大,乘积刚刚超过 1亿元;有些股票价格高,成交量相对小一些,乘积仍然超过1亿元。同成交额,2元股票相对于 20 元与 200 元股票,其成交量相差10 倍到 100 倍之多。同成交量,有些股票成交额为 100 亿元,相对于成交额仅有 1亿元的股票,也有百倍之多。
用户可以对 1亿元这个参数进行调参,不过笔者不是特别支持。因为将成交额变大即是对大盘股产生偏重,而前面成交量的筛选也己经对大盘股的成交量进行了偏重筛选,这样双重筛选下来,就会全部变成大盘股,数据偏置严重,没有合理性。预处理的思想也是先将数据进行简单的筛选。笔者认为后期的策略相对于这里的调参更为重要,策略是日后交易的核心。
清洗掉换手率低的股票
换手率=某一段时期内的成交量/流通总股数×100% 。一般情况下,大多数股票每日换手率在1%~2.5%之间(不包括初上市的股票)。70%股票的换手率基本在 3%以下,3%就成为一种分界。
当一支股票的换手率在 3%~7%之间时,该股进入相对活跃状态。当换手率在 7%~10%之间时,则为强势股的出现,股价处于高度活跃中。
筛选换手率超过3的股票,代码如下:
importtushareasts
csv_data=ts.get_today_all()
csv_data=csv_data[~csv_data.name.str.contains('ST')]
csv_data=csv_data[csv_data["volume"]>15000000]#15万手
csv_data["amount"]=round(csv_data["amount"]/100000000,2)#一亿,保留2位
csv_data=csv_data[(csv_data["amount"]>1)]
csv_data["liutongliang"]=csv_data["nmc"]/csv_data["trade"]#增加流通盘的列
csv_data["turnoverratio"]=round(csv_data["turnoverratio"],2)#换手率保留2位
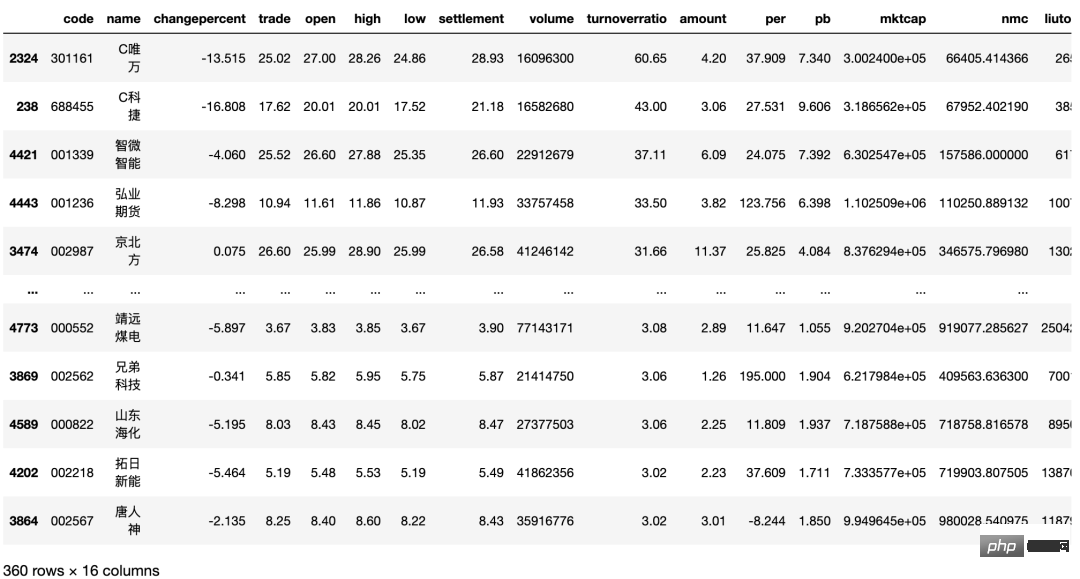
csv_data[csv_data["turnoverratio"]>3]筛选股票的数量减半。换手率低于 3%当然也有不错的股票,但是根据正态分布,我们不选取小概率事件。选择换手率较好的股票,意味着该文股票的交投越活跃,人们购买该支股票的意愿越高,该股票属于热门股。
换手率商一般意味股票流通性好,进出市场比较容易,不会出现想买买不到、想卖卖不出的现象,具有我较强的变现能力。然而值得注意的是,换手率较高的股票,往往也是短线资金追逐的对象,投机性较强,股价起伏较大,风险也相对较大。
将换手率降序排列并保存数据
换手率是最重要的一个指标,所以将筛选出来的股票换手率进行降序排列并保存,以备日后取证与研究。
将序排列用 sort_values() 两数,保存用 to_csv() 函数。这两个函数都很常用,也比较简单。代码如下:
import tushare as ts
def today_data():
csv_data=ts.get_today_all()
csv_data=csv_data[~csv_data.name.str.contains('ST')]
csv_data=csv_data[csv_data["volume"]>15000000]#15万手
csv_data["amount"]=round(csv_data["amount"]/100000000,2)#一亿,保留2位
csv_data=csv_data[(csv_data["amount"]>1)]
csv_data["liutongliang"]=csv_data["nmc"]/csv_data["trade"]#增加流通盘的列
csv_data["turnoverratio"]=round(csv_data["turnoverratio"],2)#换手率保留2位
csv_data=csv_data[csv_data["turnoverratio"]>3]
csv_data=csv_data.sort_values(by="turnoverratio", ascending=False)
return csv_data经过一系列的数据清洗与筛选,选择出符合要求的股票数据并保存到 Jupter Notebook 中。我们将上述代码进行函数化处理,并命名为 get_data.py。
以后,只要运行如下代码,就会将得到的 csv_data 显示出来:
import get_data get_data.today_data()
模块化后,将去掉大量重复代码,重加专注一个功能,也会增强代码的可读性。
本文摘编自《Python量化交易实战》,经出版方授权发布。(ISBN:9787522602820)
위 내용은 Python 퀀트 트레이딩 실습: 주식 데이터 획득 및 분석의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!