
대형 모델의 혼합 정밀도 훈련의 한계를 해결하는 방법

- WBOY앞으로
- 2023-04-13 20:28:011847검색
대규모 딥 러닝 모델을 훈련하려면 혼합 정밀도가 필수가 되었지만 많은 과제도 안고 있습니다. 모델 매개변수와 기울기를 낮은 정밀도의 데이터 유형(예: FP16)으로 변환하면 훈련 속도가 빨라질 수 있지만 수치적 안정성 문제도 발생합니다. FP16 트레이닝에 사용되는 그래디언트는 오버플로되거나 부족할 가능성이 높기 때문에 옵티마이저에 의한 부정확한 계산이 발생하고 누산기가 데이터 유형 범위를 초과하는 등의 문제가 발생합니다.

이 글에서는 하이브리드 정밀 훈련의 수치적 안정성 문제에 대해 논의하겠습니다. 수치적 불안정성을 처리하기 위해 대규모 교육 작업이 며칠 동안 보류되어 프로젝트가 지연되는 경우가 많습니다. 따라서 Tensor Collection Hook을 도입하여 훈련 중에 기울기 조건을 모니터링함으로써 모델의 내부 상태를 더 잘 이해하고 수치적 불안정성을 더 빠르게 식별할 수 있습니다.
초기 학습 단계에서 모델의 내부 상태를 이해하여 이후 학습에서 모델이 불안정해지기 쉬운지 판단하는 것은 매우 좋은 방법입니다. 학습의 처음 몇 시간 내에 기울기 불안정성을 식별할 수 있다면 효율성을 크게 향상시키도록 도와주세요. 따라서 이 기사에서는 주목할 만한 일련의 주의 사항과 수치적 불안정성에 대한 해결 방법을 제공합니다.
혼합 정밀 훈련
딥 러닝이 더 큰 기본 모델을 향해 계속 발전함에 따라. GPT 및 T5와 같은 대규모 언어 모델은 이제 NLP를 지배하고 CLIP과 같은 대조 모델은 CV의 기존 지도 모델보다 더 잘 일반화됩니다. 특히 CLIP의 텍스트 임베딩 학습 기능은 훈련하기 어려웠던 이전 CV 모델의 기능을 뛰어넘는 제로샷 및 소수샷 추론을 수행할 수 있음을 의미합니다.
이러한 대형 모델은 일반적으로 시각적, 텍스트 모두 깊은 변환기 네트워크를 포함하며 수십억 개의 매개변수를 포함합니다. GPT3에는 1,750억 개의 매개변수가 있으며 CLIP은 수백 테라바이트의 이미지에 대해 학습되었습니다. 모델과 데이터의 크기는 모델이 대규모 GPU 클러스터에서 훈련하는 데 몇 주 또는 몇 달이 걸린다는 것을 의미합니다. 훈련 속도를 높이고 필요한 GPU 수를 줄이기 위해 모델은 종종 혼합 정밀도로 훈련됩니다.
하이브리드 정밀 훈련은 FP32 대신 FP16에서 일부 훈련 작업을 수행합니다. FP16에서 수행되는 작업은 더 적은 메모리를 필요로 하며 최신 GPU에서는 FP32보다 최대 8배 빠르게 처리될 수 있습니다. FP16에서 훈련된 대부분의 모델은 정확도가 낮지만 과도한 매개변수화로 인해 성능 저하가 나타나지 않습니다.
Volta 아키텍처에 Tensor 코어를 도입한 NVIDIA를 사용하면 정밀도가 낮은 부동 소수점 가속 훈련이 더 빨라집니다. 딥 러닝 모델에는 많은 매개변수가 있으므로 매개변수 하나의 정확한 값은 일반적으로 중요하지 않습니다. 32비트 대신 16비트로 숫자를 표현하면 Tensor Core 레지스터에 더 많은 매개변수를 한 번에 넣을 수 있어 각 작업의 병렬성이 향상됩니다.

하지만 FP16을 위한 훈련은 쉽지 않습니다. FP16은 절대값이 65,504보다 크거나 5.96e-8보다 작은 숫자를 표현할 수 없기 때문입니다. PyTorch와 같은 딥 러닝 프레임워크에는 FP16(그라디언트 스케일링 및 자동 혼합 정밀도)의 한계를 처리하기 위한 도구가 내장되어 있습니다. 그러나 이러한 안전 검사가 이루어지더라도 매개변수나 경사도가 사용 가능한 범위를 벗어나기 때문에 대규모 교육 작업이 실패하는 경우가 많습니다. 딥 러닝의 일부 구성 요소는 FP32에서 잘 작동하지만, 예를 들어 BN에는 FP16의 한계 내에서 수치적 불안정성을 초래하거나 모델이 올바르게 수렴하는 데 충분한 정확도를 제공하지 못할 수 있는 매우 세밀한 조정이 필요한 경우가 많습니다. 이는 모델을 FP16으로 맹목적으로 변환할 수 없음을 의미합니다.
그래서 딥 러닝 프레임워크는 사전 정의된 FP16 안전 작업 목록을 통해 훈련되는 자동 혼합 정밀도(AMP)를 사용합니다. AMP는 안전하다고 간주되는 모델 부분만 변환하는 동시에 더 높은 정밀도가 필요한 작업을 FP32에서 유지합니다. 또한 혼합 정밀도 훈련 모델에서는 0 기울기에 가까운 일부 손실(FP16의 최소 범위 미만)에 특정 값을 곱하여 더 큰 기울기를 얻은 다음 최적화 프로그램을 적용하여 모델 가중치를 업데이트하면 너무 작은 그래디언트 문제를 해결하기 위한 조정을 그래디언트 스케일링이라고 합니다.
다음은 PyTorch의 일반적인 AMP 훈련 루프의 예입니다.

그라디언트 스케일러는 손실에 다양한 양을 곱합니다. 그래디언트에서 nan이 관찰되면 nan이 사라질 때까지 승수가 절반으로 감소하고, nan이 발생하지 않으면 기본적으로 2000단계마다 승수가 점차 증가합니다. 이렇게 하면 기울기가 FP16 범위 내로 유지되는 동시에 기울기가 0이 되는 것을 방지할 수 있습니다.
훈련 불안정 사례
두 프레임워크의 최선의 노력에도 불구하고 PyTorch와 TensorFlow에 내장된 도구는 FP16에서 발생하는 수치적 불안정성을 방지할 수 없습니다.
HuggingFace의 T5 구현에서 모델 변형은 훈련 후에도 INF 값을 생성했습니다. 매우 깊은 T5 모델에서는 Attention 값이 여러 레이어에 걸쳐 누적되어 결국 FP16 범위 외부에 도달하므로 BN 레이어에서는 nan과 같은 무한한 값이 발생합니다. 그들은 FP16에서 INF 값을 최대값으로 변경하여 이 문제를 해결했으며 이것이 추론에 미미한 영향을 미친다는 것을 발견했습니다.
또 다른 일반적인 문제는 ADAM 최적화 프로그램의 한계입니다. 소규모 업데이트로 ADAM은 그라디언트의 첫 번째 및 두 번째 순간의 이동 평균을 사용하여 모델의 각 매개 변수에 대한 학습 속도를 조정합니다.
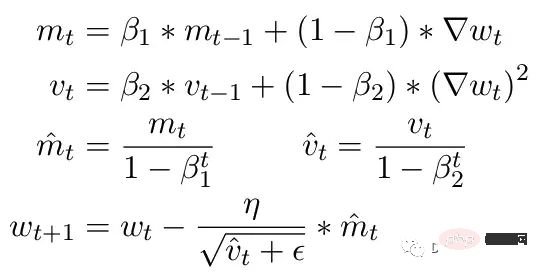
여기서 Beta1과 Beta2는 각 순간의 이동 평균 매개변수이며 일반적으로 각각 .9와 .999로 설정됩니다. 베타 매개변수를 단계 수의 거듭제곱으로 나누면 업데이트의 초기 편향이 제거됩니다. 업데이트 단계에서는 0으로 나누는 오류를 방지하기 위해 두 번째 모멘트 매개변수에 작은 엡실론이 추가됩니다. 엡실론의 일반적인 기본값은 1e-8입니다. 그러나 FP16의 최소값은 5.96e-8입니다. 즉, 두 번째 순간이 너무 작으면 업데이트가 0으로 나누어집니다. 따라서 PyTorch에서는 훈련이 분기되지 않도록 업데이트가 이 단계에서 변경 사항을 건너뜁니다. 그러나 문제는 여전히 존재합니다. 특히 Beta2=.999의 경우 5.96e-8보다 작은 기울기는 오랫동안 매개변수 가중치 업데이트를 중지할 수 있으며 최적화 프로그램은 불안정한 상태에 들어갈 수 있습니다.
ADAM의 장점은 이 두 모멘트를 이용하여 각 매개변수의 학습률을 조정할 수 있다는 것입니다. 학습 매개변수가 느린 경우 학습 속도가 빨라지고, 학습 매개변수가 빠른 경우 학습 속도가 느려질 수 있습니다. 그러나 여러 단계에서 그래디언트가 0으로 계산되면 작은 양수 값이라도 학습률이 하향 조정되기 전에 모델이 분기되는 원인이 됩니다.
또한 PyTorch에는 현재 혼합 정밀도를 사용할 때 자동으로 엡실론을 1e-7로 변경하는 문제가 있습니다. 이는 양수 값으로 다시 이동할 때 그래디언트가 분기되는 것을 방지하는 데 도움이 될 수 있습니다. 그러나 그렇게 하면 기울기가 동일한 범위에 있다는 것을 알 때 ε을 늘리면 학습률에 적응하는 최적화 프로그램의 능력이 감소합니다. 따라서 맹목적으로 엡실론을 증가시키는 것은 0 기울기로 인한 훈련 정체 문제를 해결할 수 없습니다.
CLIP 훈련의 그라데이션 스케일링
훈련에서 발생할 수 있는 불안정성을 추가로 입증하기 위해 CLIP 이미지 모델에 대한 일련의 실험을 구성했습니다. CLIP은 시각적 변환기와 해당 이미지를 설명하는 텍스트 임베딩을 통해 이미지를 동시에 학습하는 대조 학습 기반 모델입니다. 비교 구성 요소는 각 데이터 배치의 원래 설명과 이미지를 다시 일치시키려고 시도합니다. 손실은 배치 단위로 계산되므로 더 큰 배치에 대한 교육이 더 나은 결과를 제공하는 것으로 나타났습니다.
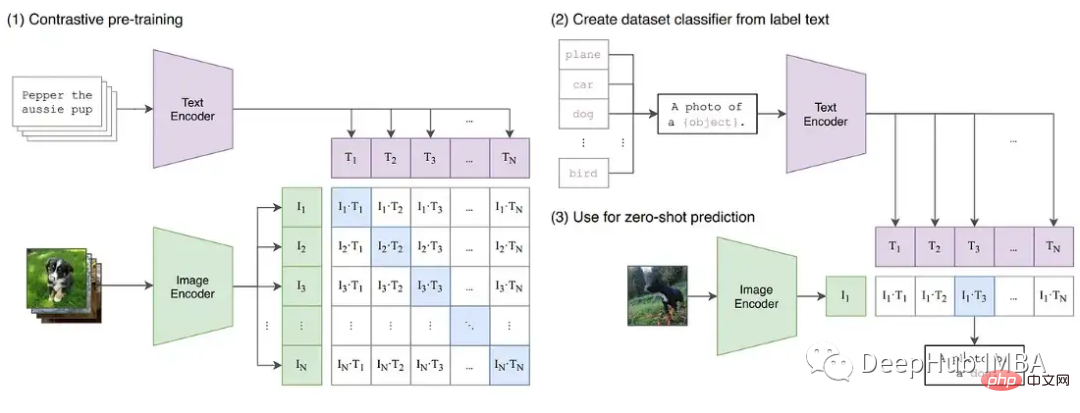
CLIP은 GPT와 유사한 언어 모델과 ViT 이미지 모델이라는 두 가지 변환기 모델을 동시에 교육합니다. 두 모델의 깊이는 경사 성장이 FP16 한계를 초과할 기회를 만듭니다. OpenClip(arxiv 2212.07143) 구현에서는 FP16을 사용할 때의 훈련 불안정성을 설명합니다.
Tensor Collection Hook
훈련 중 내부 모델 상태를 더 잘 이해하기 위해 TCH(Tensor Collection Hook)를 개발했습니다. TCH는 모델을 래핑하고 가중치, 기울기, 손실, 입력, 출력 및 최적화 상태에 대한 요약 정보를 주기적으로 수집할 수 있습니다.
예를 들어 이 실험에서는 훈련 중 기울기 조건을 찾아 기록하려고 합니다. 예를 들어 10단계마다 각 레이어에서 그래디언트 노름, 최소값, 최대값, 절대값, 평균, 표준편차를 수집하고 그 결과를 텐서보드에 시각화할 수 있습니다.

TensorBoard는 --logdir 입력으로 out_dir을 사용하여 시작할 수 있습니다.

Experiments
CLIP의 교육 불안정성을 재현하기 위해 Laion 50억 이미지 데이터 세트의 하위 집합을 사용하여 OpenCLIP을 교육했습니다. TCH로 모델을 래핑하고 모델 기울기, 가중치, 최적화 모멘트 상태를 정기적으로 저장하여 불안정성이 발생할 때 모델 내부에서 어떤 일이 일어나는지 관찰할 수 있습니다.
vvi-h-14 변형부터 OpenCLIP 작성자는 훈련 중 안정성 문제를 설명합니다. Pre-training 체크포인트부터 학습률을 CLIP 학습 후반부 학습률과 비슷하게 1~e4까지 높입니다. 훈련이 300단계에 도달하면 의도적으로 더 어려운 훈련 배치 10개가 연속적으로 도입됩니다.
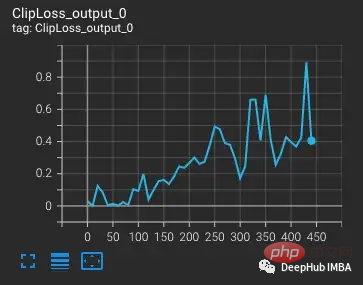
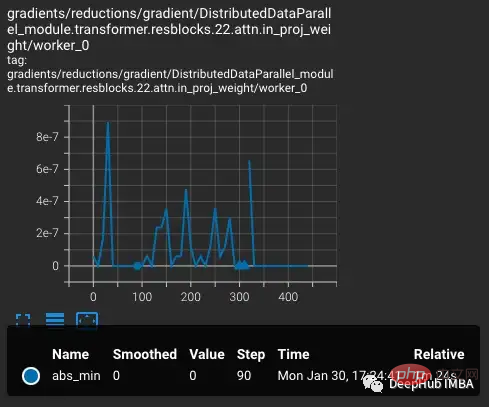
학습률이 증가할수록 손실도 증가하는데, 이는 예상되는 현상입니다. 단계 300에서 더 어려운 상황이 도입되면 손실이 크지는 않지만 작지만 증가합니다. 모델은 어려운 사례를 찾았지만 nan이 기울기에 나타나기 때문에(두 번째 플롯에서 삼각형으로 표시됨) 이러한 단계에서 대부분의 가중치를 업데이트하지 않습니다. 이 어려운 사례 세트를 통과한 후에는 기울기가 0으로 떨어집니다.
PyTorch Gradient Scaling
여기서 무슨 일이 일어나고 있나요? 왜 Gradient가 0인가요? 문제는 PyTorch의 Gradient Scaling에 있습니다. 경사 조정은 혼합 정밀도 훈련에서 중요한 도구입니다. 수백만 또는 수십억 개의 매개변수가 있는 모델에서는 하나의 매개변수의 기울기가 작고 종종 FP16의 최소 범위보다 낮기 때문입니다.
하이브리드 정밀 훈련이 처음 제안되었을 때 딥 러닝 과학자들은 모델이 훈련 초기에 예상대로 훈련되었지만 결국에는 분기되는 경우가 많다는 사실을 발견했습니다. 훈련이 진행됨에 따라 기울기는 더 작아지는 경향이 있고 일부 언더플로 FP16은 0이 되어 훈련이 불안정해집니다.

기울기 언더플로우를 해결하기 위해 초기 기술에서는 단순히 손실에 고정된 양을 곱하고 더 큰 기울기를 계산한 다음 가중치 업데이트를 동일한 고정된 양으로 조정했습니다(하이브리드 정밀 훈련 중에 가중치는 계속 저장됨). FP32에서). 그러나 때때로 이 고정 금액으로는 여전히 충분하지 않습니다. PyTorch의 그래디언트 스케일링과 같은 최신 기술은 일반적으로 65536인 더 큰 승수로 시작합니다. 그러나 이 값이 너무 높아 큰 기울기가 FP16 값을 오버플로할 수 있으므로 기울기 스케일러는 오버플로되는 nan 기울기를 모니터링합니다. nan이 관찰되면 이 단계에서 가중치 업데이트를 건너뛰어 승수를 절반으로 줄이고 다음 단계로 진행합니다. 이는 그라데이션에서 난이 관찰되지 않을 때까지 계속됩니다. 그라디언트 스케일러가 2000단계에서 nan을 감지하지 못하면 승수를 두 배로 늘리려고 시도합니다.
위의 예에서 그래디언트 스케일러는 예상대로 정확하게 작동합니다. 손실이 예상보다 큰 경우 세트를 전달하여 오버플로로 이어지는 더 큰 기울기를 생성합니다. 그러나 문제는 이제 승수가 낮고, 더 작은 기울기가 0으로 떨어지고, 기울기 스케일러가 nan만 0 기울기를 모니터링하지 않는다는 것입니다.
위의 예는 의도적으로 어려운 예를 그룹화했기 때문에 처음에는 다소 의도적인 것처럼 보일 수 있습니다. 그러나 며칠 동안 훈련한 후에는 대규모 배치의 경우 nan 이상 현상이 발생할 확률이 확실히 높아집니다. 따라서 그래디언트를 0으로 밀어넣기에 충분한 난을 만날 확률은 매우 높습니다. 실제로 어려운 샘플을 도입하지 않더라도 수천 번의 훈련 단계 이후에는 항상 그래디언트가 0인 경우가 종종 발견됩니다.
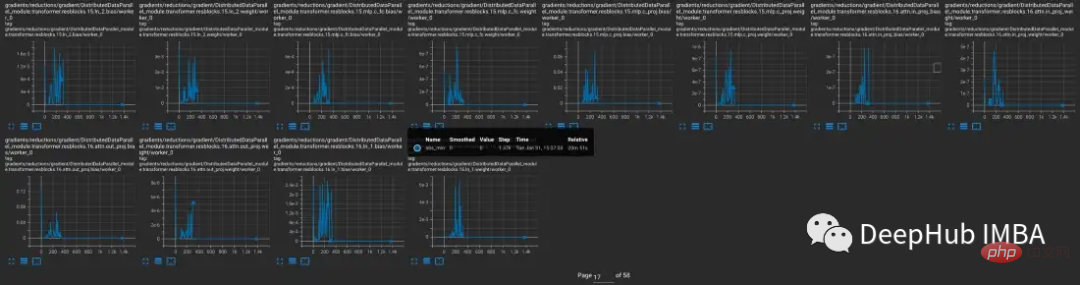
그라디언트 언더플로우를 생성하는 모델
문제가 발생하는 경우와 발생하지 않는 경우를 더 자세히 살펴보기 위해 CLIP을 일반적으로 혼합 정밀도로 훈련된 더 작은 CV 모델인 YOLOV5와 비교했습니다. 두 경우 모두 훈련 중에 각 레이어의 0 그래디언트 빈도가 추적되었습니다.

학습의 처음 9000단계에서 CLIP의 레이어 중 5-20%는 그래디언트 언더플로를 표시하는 반면 Yolo의 레이어는 가끔씩만 언더플로를 표시합니다. CLIP의 언더플로우 비율도 시간이 지남에 따라 증가하여 훈련의 안정성을 떨어뜨립니다.
CLIP 범위의 기울기 크기가 YOLO 범위의 기울기 크기보다 훨씬 크기 때문에 기울기 스케일링을 사용해도 이 문제가 해결되지 않습니다. CLIP의 경우 그라디언트 스케일러가 FP16에서 더 큰 그라디언트를 최대값에 더 가깝게 이동하는 반면 가장 작은 그라디언트는 최소값 아래에 유지됩니다.
CLIP 해결 시 그래디언트 불안정성을 해결하는 방법
경우에 따라 그래디언트 스케일러의 매개변수를 조정하면 언더플로우를 방지하는 데 도움이 될 수 있습니다. CLIP의 경우 더 큰 승수로 시작하여 증가 간격을 단축하도록 수정을 시도할 수 있습니다.

그러나 오버플로를 방지하고 작은 기울기를 0으로 되돌리기 위해 승수가 즉시 떨어지는 것을 발견했습니다.

스케일링을 개선하는 한 가지 솔루션은 매개변수 범위에 더 잘 적응하도록 만드는 것입니다. 예를 들어, 혼합 정밀도 훈련을 위한 적응형 손실 스케일링(Adaptive Loss Scaling for Mixed Precision Training) 논문에서는 언더플로우를 방지할 수 있는 전체 모델 대신 레이어별로 손실 스케일링을 수행할 것을 권장합니다. 그리고 우리의 실험은 보다 적응적인 접근 방식의 필요성을 보여줍니다. CLIP 레이어 내의 그라데이션은 여전히 전체 FP16 범위를 포괄하므로 훈련 안정성을 보장하려면 각 개별 매개변수에 맞게 스케일링을 조정해야 합니다. 그러나 이러한 세부적인 조정에는 많은 메모리가 필요하므로 훈련 배치 크기가 줄어듭니다.
최신 하드웨어는 더욱 효율적인 솔루션을 제공합니다. 예를 들어, BFloat16(BF16)은 더 넓은 범위를 위해 정밀도를 교환하는 또 다른 16비트 데이터 유형입니다. FP16은 5.96e-8~65,504를 처리하는 반면 BF16은 FP32와 동일한 범위인 1.17e-38~3.39e38을 처리할 수 있습니다. 그러나 BF16의 정확도는 FP16보다 낮기 때문에 일부 모델이 수렴되지 않습니다. 그러나 대형 변압기 모델의 경우 BF16은 수렴을 감소시키는 것으로 나타나지 않았습니다.
우리는 일련의 하드 관찰을 삽입하는 동일한 테스트를 실행합니다. BF16에서는 하드 케이스가 도입될 때 그래디언트 스파이크가 발생한 다음 관찰된 범위 증가 NaN으로 인해 그래디언트 스케일링이 그래디언트에서 발생하지 않기 때문에 일반 훈련으로 돌아갑니다.

FP16과 BF16의 CLIP을 비교한 결과, BF16에서는 간헐적인 그래디언트 언더플로우만 있는 것으로 나타났습니다.

PyTorch 1.12 이상에서는 AMP를 조금만 변경하면 BF16을 활성화할 수 있습니다.

더 높은 정밀도가 필요한 경우 Tensorfloat32(TF32) 데이터 유형을 사용해 볼 수 있습니다. Nvidia가 Ampere GPU에 도입한 TF32는 FP16의 정밀도를 유지하면서 BF16의 추가 범위 비트를 추가하는 19비트 부동 소수점입니다. FP16 및 BF16과 달리 혼합 정밀도로 활성화되지 않고 FP32를 직접 대체하도록 설계되었습니다. PyTorch에서 TF32를 활성화하려면 훈련 시작 부분에 두 줄을 추가하세요.

여기서 참고할 사항: PyTorch 1.11 이전에는 이 데이터 유형을 지원하는 GPU에서 TF32가 기본적으로 활성화되었습니다. PyTorch 1.11부터는 수동으로 활성화해야 합니다. TF32의 훈련 속도는 BF16 및 FP16보다 느리지만 이론적인 FLOPS는 FP16의 절반에 불과하지만 여전히 FP32의 훈련 속도보다 훨씬 빠릅니다.
Amazon AWS를 사용하는 경우: BF16 및 TF32는 P4d, P4de, G5, Trn1 및 DL1 인스턴스에서 사용할 수 있습니다.
문제가 발생하기 전에 수정하세요
위의 예에서는 FP16 전체 제한 사항을 식별하고 수정하는 방법을 보여줍니다. 그러나 이러한 문제는 훈련 후반부에 나타나는 경우가 많습니다. 훈련 초기에 OpenCLIP 훈련에서와 같이 모델이 더 높은 손실을 생성하고 이상치에 덜 민감하면 문제가 발생하기까지 며칠이 걸릴 수 있으며 값비싼 계산 시간을 낭비하게 됩니다.
FP16과 BF16 모두 장점과 단점이 있습니다. FP16의 한계로 인해 훈련이 불안정하고 지연될 수 있습니다. 그러나 BF16은 정확도가 낮고 수렴성이 낮을 수 있습니다. 따라서 우리는 훈련 초기에 FP16 불안정성에 취약한 모델을 식별하여 불안정성이 발생하기 전에 정보에 입각한 결정을 내릴 수 있기를 원합니다. 따라서 후속 훈련 불안정성을 나타내지 않는 모델을 다시 비교하면 두 가지 추세를 찾을 수 있습니다.

FP16에서 훈련된 YOLO 모델과 BF16에서 훈련된 CLIP 모델 모두 경사 언더플로율이 일반적으로 1% 미만이고 시간이 지나도 안정적이라는 것을 보여줍니다.

FP16에서 훈련된 CLIP 모델은 훈련의 처음 1000단계에서 언더플로우 비율이 5~10%이며 시간이 지남에 따라 상승 추세를 보여줍니다.
그래서 TCH를 사용하여 경사 언더플로우 속도를 추적하면 처음 4~6시간의 훈련 내에 경사도 불안정성이 높아지는 추세를 식별할 수 있습니다. 이 추세가 관찰되면 BF16으로 전환하십시오.
요약
하이브리드 정밀 훈련은 기존 대형 기본 모델 훈련에서 중요한 부분이지만 수치적 안정성에 특별한 주의가 필요합니다. 모델이 혼합 정밀도 데이터 유형의 한계에 직면하는 경우를 진단하려면 모델의 내부 상태를 이해하는 것이 중요합니다. 모델을 TCH로 래핑하면 매개변수나 경사도가 수치 한계에 접근하는지 추적하고 불안정성이 발생하기 전에 훈련 변경을 수행할 수 있어 잠재적으로 훈련 실행 실패 일수가 줄어들 수 있습니다.
위 내용은 대형 모델의 혼합 정밀도 훈련의 한계를 해결하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!