
데이터 소스는 여전히 인공지능의 주요 병목 현상이다

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-04-09 10:41:031196검색
이번 주에 발표된 Appen의 "인공 지능 및 기계 학습 현황" 보고서에 따르면 대행사는 여전히 인공 지능 및 기계 학습 프로그램을 유지하기 위해 훌륭하고 깨끗한 데이터를 얻기 위해 고군분투하고 있습니다.

Appen이 504명의 비즈니스 리더와 기술 전문가를 대상으로 실시한 설문 조사에 따르면, 인공 지능의 4단계, 데이터 소스 모델 평가 단계 - 데이터 소스는 다음과 같습니다. 대부분의 리소스는 가장 오래 걸리고 가장 까다롭습니다.
Appen의 조사에 따르면 데이터 소스는 기업 AI 예산의 평균 34%를 소비하며, 데이터 준비, 모델 테스트 및 배포는 각각 24%, 모델 평가는 15%를 차지합니다. 이 설문 조사는 Harris Poll이 실시했으며 미국, 영국, 아일랜드 및 독일의 IT 의사 결정자, 비즈니스 리더 및 관리자, 기술 실무자가 포함되었습니다.
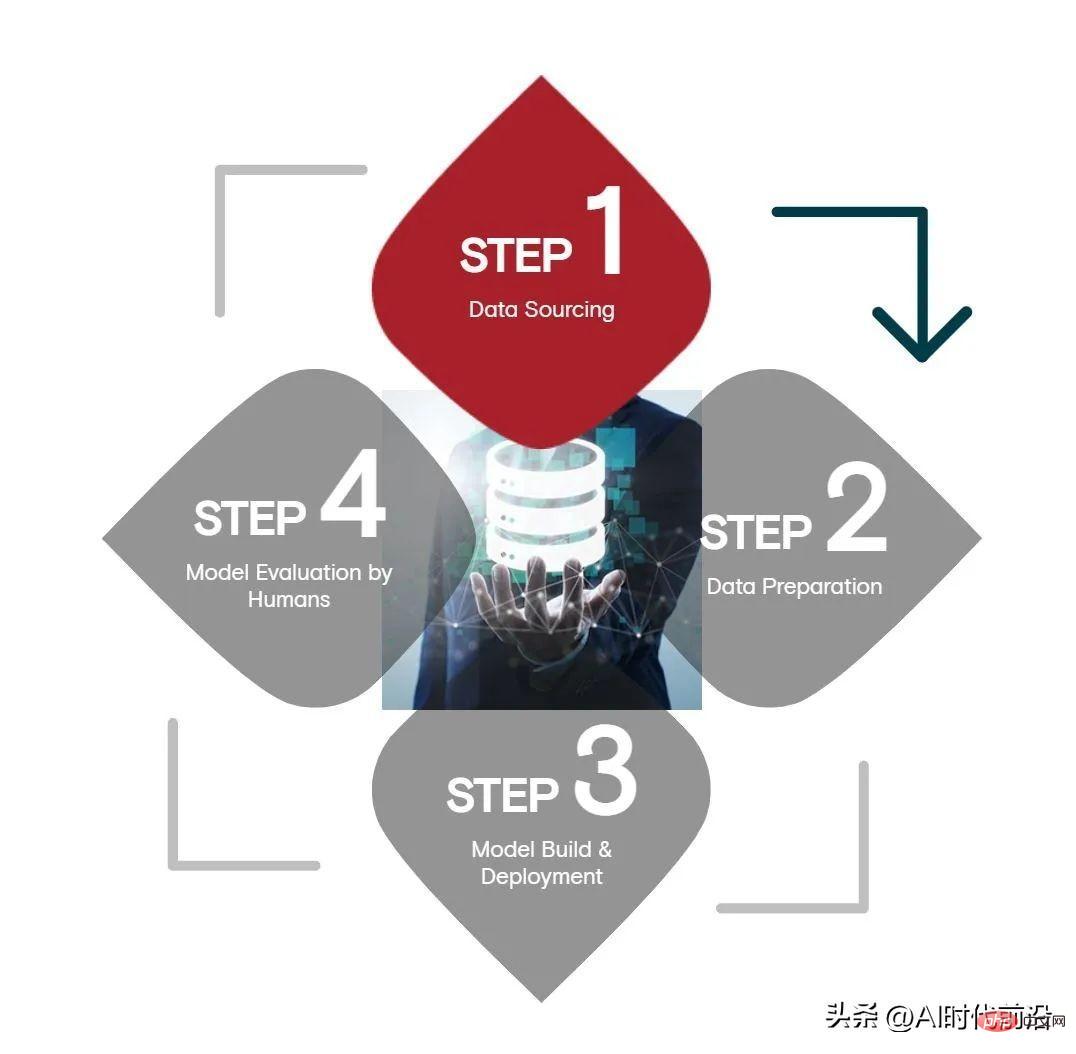
시간 측면에서 데이터 소스는 약 26%의 시간을 소비하고, 데이터 준비 시간은 24%, 모델 테스트, 배포 및 모델 평가 시간은 각각 23%입니다. 마지막으로 기술자의 42%는 데이터 소싱이 AI 수명주기에서 가장 어려운 단계라고 생각합니다. 다른 단계는 모델 평가(41%), 모델 테스트 및 배포(38%), 데이터 준비(34%)입니다. ) .
어려움에도 불구하고 조직은 이를 실현하기 위해 열심히 노력하고 있습니다. Appen에 따르면 응답자의 5분의 4(81%)가 AI 이니셔티브를 지원하기에 충분한 데이터를 보유하고 있다고 답했습니다. 성공의 열쇠는 다음과 같습니다. 기업의 대다수(88%)가 Appen과 같은 외부 AI 교육 데이터 제공업체를 사용하여 데이터를 보강합니다.
그러나 데이터의 정확성은 여전히 의문의 여지가 있습니다. Appen은 응답자의 20%만이 80% 이상의 데이터 정확도를 보고한 것으로 나타났습니다. 단지 6%(약 20명 중 1명)만이 자신의 데이터가 90% 정확하거나 더 좋다고 답했습니다.
이를 염두에 두고 Appen의 설문 조사에 따르면 응답자의 거의 절반(46%)이 데이터 정확성이 중요하다고 생각합니다. 2%만이 데이터 정확성이 크게 필요하지 않다고 생각하는 반면, 51%는 데이터 정확성이 매우 중요하다고 생각합니다.
Appen의 CTO Wilson Pang은 데이터 품질의 중요성에 대해 다른 견해를 갖고 있으며, 그의 고객 중 48%는 데이터 품질이 중요하지 않다고 믿고 있습니다.
보고서에서는 “품질이 풍부한 데이터가 더 나은 모델 출력과 일관된 처리 및 의사 결정을 제공하므로 AI 및 ML 모델의 성공에 데이터 정확성이 매우 중요합니다.”라고 보고서에서는 말합니다. “좋은 결과를 얻으려면 데이터 세트가 정확하고 포괄적이어야 합니다. , 확장 가능합니다.”
딥 러닝과 데이터 중심 AI의 등장으로 AI 성공의 힘이 우수한 데이터 과학 및 머신 러닝 모델링에서 우수한 데이터 수집 및 태그로 바뀌었습니다. 이는 오늘날의 전이 학습 기술에서 특히 그렇습니다. 인공 지능 실무자는 사전 훈련된 대규모 언어 또는 컴퓨터 비전 모델을 버리고 자체 데이터를 사용하여 그 중 일부를 다시 훈련할 것입니다.
더 나은 데이터는 불필요한 편견이 AI 모델에 스며드는 것을 방지하여 AI가 초래할 수 있는 나쁜 결과를 방지하는 데도 도움이 됩니다. 이는 대규모 언어 모델의 경우 특히 그렇습니다.
보고서에서는 다음과 같이 말합니다. “다국어 웹 스크래핑 데이터에 대해 훈련된 대규모 언어 모델(LLM)이 증가하면서 기업은 또 다른 과제에 직면하게 되었습니다. 훈련 코퍼스는 인종, 성별 및 종교적 편견뿐만 아니라 독성 언어로 가득 차 있기 때문입니다. 모델은 종종 바람직하지 않은 동작을 나타냅니다.”
몇 가지 해결 방법(훈련 방법 변경, 훈련 데이터 및 모델 출력 필터링, 테스트별 학습 피드백 받기)이 있지만 네트워크 데이터의 편향은 까다로운 문제를 야기하지만 더 많은 연구가 이루어졌습니다. "인간 중심의 LLM" 벤치마크와 모델 평가 방법에 대한 좋은 표준을 만들려면 필요합니다.
Appen은 데이터 관리가 인공지능이 직면한 가장 큰 장애물로 남아 있다고 말했습니다. 조사 결과, 41%의 사람들이 데이터 관리가 인공지능 주기의 가장 큰 병목 현상이라고 믿고 있는 것으로 나타났습니다. 4위는 데이터 부족으로, 응답자의 30%가 이를 AI 성공의 가장 큰 장애물로 꼽았습니다.
하지만 좋은 소식이 있습니다. 기업이 데이터를 관리하고 준비하는 데 소요되는 시간이 줄어들고 있다는 것입니다. Appen은 작년 보고서의 53%에 비해 올해의 비율은 47%를 조금 넘었다고 말했습니다.
"대부분의 응답자가 외부 데이터 공급자를 사용하는 경우 데이터 소싱 및 준비를 아웃소싱함으로써 데이터 과학자가 데이터를 적절하게 관리, 정리 및 레이블 지정하는 데 필요한 시간을 절약하고 있다고 추론할 수 있습니다."라고 데이터 레이블링 회사는 말합니다.
그러나 데이터의 오류율이 상대적으로 높은 것으로 판단할 때 조직은 데이터 소스 및 준비 프로세스(내부 또는 외부)를 축소해서는 안 됩니다. AI 프로세스를 구축하고 유지하는 데는 경쟁적인 요구 사항이 많이 있습니다. 자격을 갖춘 데이터 전문가를 고용해야 하는 요구 사항은 Appen이 파악한 또 다른 주요 요구 사항이었습니다. 그러나 데이터 관리에 상당한 진전이 있을 때까지 조직은 팀에게 계속해서 데이터 품질의 중요성을 강조하도록 압력을 가해야 합니다.
또한 설문 조사에 따르면 조직의 93%가 AI 윤리가 AI 프로젝트의 "기초"가 되어야 한다는 데 강력하게 또는 어느 정도 동의하는 것으로 나타났습니다. Appen CEO인 Mark Brayan은 좋은 시작이었지만 아직 해야 할 일이 많다고 말했습니다. Brayan은 보도 자료에서 "문제는 많은 사람들이 열악한 데이터 세트로 훌륭한 AI를 구축하려고 시도하면서 목표 달성에 큰 장애물이 된다는 것입니다"라고 말했습니다.
Appen에 따르면 보고서에 따르면 맞춤 수집된 AI는 다음과 같습니다. 기업 내 데이터는 여전히 인공 지능에 사용되는 기본 데이터 세트로, 데이터의 38%~42%를 차지합니다. 합성 데이터는 조직 데이터의 24~38%를 차지할 정도로 놀라울 만큼 강력한 성능을 보였으며, 사전 레이블이 지정된 데이터(일반적으로 데이터 서비스 제공업체)는 데이터의 23~31%를 차지했습니다.
특히 합성 데이터는 민감한 AI 프로젝트에서 편향 발생률을 줄일 수 있는 잠재력을 가지고 있으며, Appen 설문 조사 참가자 중 97%가 "포괄적인 교육 데이터 세트 개발"에 합성 데이터를 사용한다고 답했습니다.
보고서의 다른 흥미로운 결과는 다음과 같습니다.
- 77%의 조직이 월별 또는 분기별로 모델을 재교육합니다. (AI 시대 최전선의 해석: 인공 지능은 완전히 고정되지 않으며, 애플리케이션 요구에 따라 지속적으로 개선되며 지속적으로 업데이트되어야 합니다.)
- 55%의 미국 기업은 경쟁사보다 앞서 있다고 주장하는 반면, 유럽의 비율은 44%입니다(AI Times Frontier 해석: 유럽 기업은 약간 낮음). -미국인보다 중요합니다.)
- 조직의 42%가 인공지능이 "광범위하게" 출시되었다고 보고했으며, "2021년 인공지능 현황 보고서"에서는 이 비율이 51%였습니다. (AI 최전선의 해석; 시대: 인공 지능 애플리케이션이 점점 더 널리 보급되고 있습니다.)
- 기관의 7%가 AI 예산이 500만 달러를 초과한다고 보고했습니다. 이는 작년의 9%와 비교됩니다. (AI 시대 최전선의 해석: 한편으로는 비용을 절감하는 인공지능의 점진적인 성숙에 기인할 수도 있지만, 인공지능이 더 이상 '명품'이 아니라 점차 고급화되고 있음을 보여준다. 기업의 "필수품"입니다.)
위 내용은 데이터 소스는 여전히 인공지능의 주요 병목 현상이다의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!