
20가지 클래식 Redis 인터뷰 질문 및 답변 요약(공유)

- 青灯夜游앞으로
- 2023-03-07 18:53:414802검색
이 기사에는 여러분을 위한 20가지 고전적인 Redis 인터뷰 질문이 여러분에게 도움이 되기를 바랍니다.

1. Redis란 무엇인가요? 주로 어떤 용도로 사용되나요?
Redis, 정식 영어명은 Remote Dictionary Server(Remote Dictionary Service)로 ANSI C 언어로 작성된 오픈소스 로그형 Key-Value 데이터베이스로 네트워크를 지원하며 메모리 기반으로 구성이 가능합니다. 지속되며 다국어 API를 제공합니다.
MySQL 데이터베이스와 다르게 Redis 데이터는 메모리에 저장됩니다. 읽기 및 쓰기 속도는 매우 빠르며 초당 100,000회 이상의 읽기 및 쓰기 작업을 처리할 수 있습니다. 따라서 Redis는 캐싱에도 널리 사용됩니다. 또한 Redis는 분산 잠금에도 자주 사용됩니다. 또한 Redis는 트랜잭션, 지속성, LUA 스크립트, LRU 기반 이벤트 및 다양한 클러스터 솔루션을 지원합니다. 2 Redis의 기본 데이터 구조 유형에 대해 이야기해 보겠습니다.
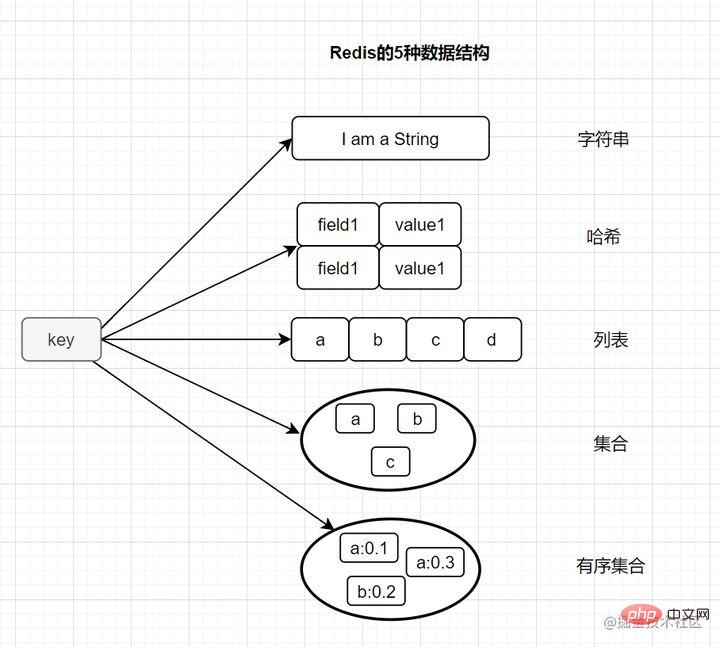
대부분의 친구들은 Redis에 다음과 같은 5가지 기본 유형이 있다는 것을 알고 있습니다.
String(문자열)- Hash(해시)
- List(목록) )
- Set(세트)
- zset(ordered set)
- 3가지 특수 데이터 구조 유형도 있습니다
- Hyperloglog
- Bitmap
 문자열 (string)
문자열 (string)
- 간단한 사용 예:
키 값 설정, <code>키 가져오기등 - 애플리케이션 시나리오: 공유 세션, 분산 잠금, 카운터, 현재 제한.
set key value、get key等 - 应用场景:共享session、分布式锁,计数器、限流。
- 内部编码有3种,
int(8字节长整型)/embstr(小于等于39字节字符串)/raw(大于39个字节字符串)
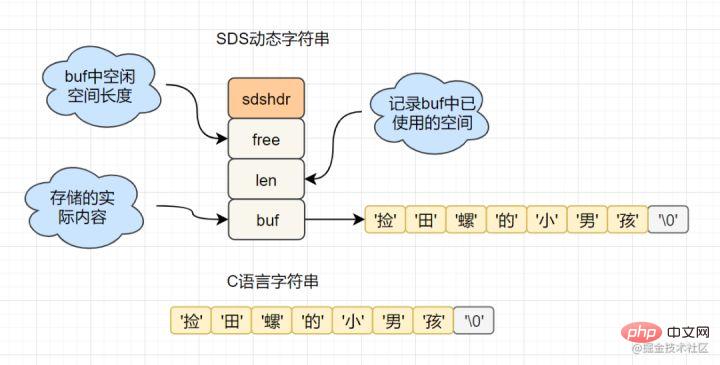
C语言的字符串是char[]实现的,而Redis使用SDS(simple dynamic string) 封装,sds源码如下:
struct sdshdr{
unsigned int len; // 标记buf的长度
unsigned int free; //标记buf中未使用的元素个数
char buf[]; // 存放元素的坑
}SDS 结构图如下:
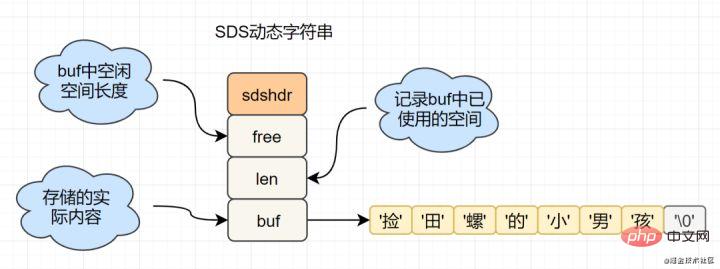
Redis为什么选择SDS结构,而C语言原生的char[]不香吗?
举例其中一点,SDS中,O(1)时间复杂度,就可以获取字符串长度;而C 字符串,需要遍历整个字符串,时间复杂度为O(n)
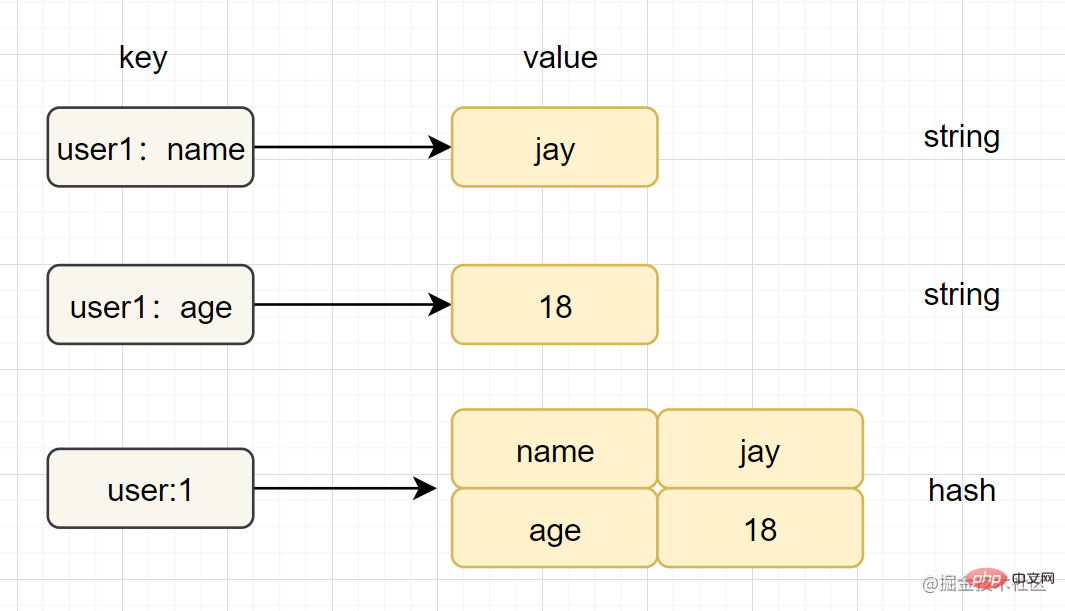
Hash(哈希)
- 简介:在Redis中,哈希类型是指v(值)本身又是一个键值对(k-v)结构
- 简单使用举例:
hset key field value、hget key field - 内部编码:
ziplist(压缩列表)、hashtable(哈希表) - 应用场景:缓存用户信息等。
- 注意点:如果开发使用hgetall,哈希元素比较多的话,可能导致Redis阻塞,可以使用hscan。而如果只是获取部分field,建议使用hmget。
字符串和哈希类型对比如下图:
List(列表)
- 简介:列表(list)类型是用来存储多个有序的字符串,一个列表最多可以存储2^32-1个元素。
- 简单实用举例:
lpush key value [value ...]、lrange key start end - 内部编码:ziplist(压缩列表)、linkedlist(链表)
- 应用场景:消息队列,文章列表,
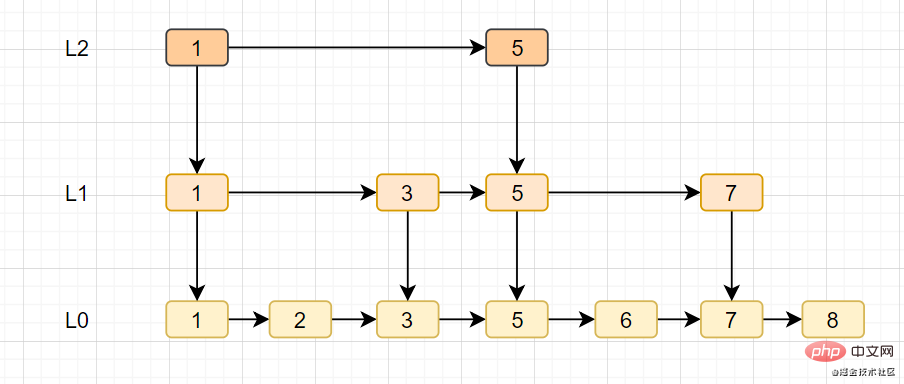
一图看懂list类型的插入与弹出:
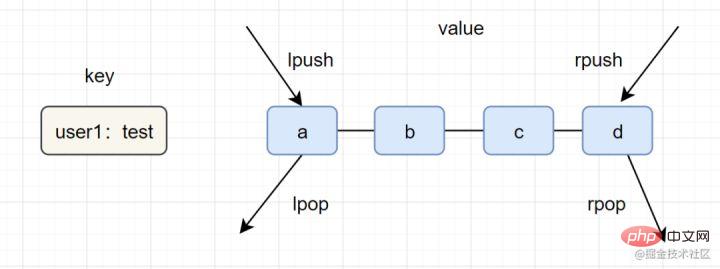
list应用场景参考以下:
- lpush+lpop=Stack(栈)
- lpush+rpop=Queue(队列)
- lpsh+ltrim=Capped Collection(有限集合)
- lpush+brpop=Message Queue(消息队列)
Set(集合)
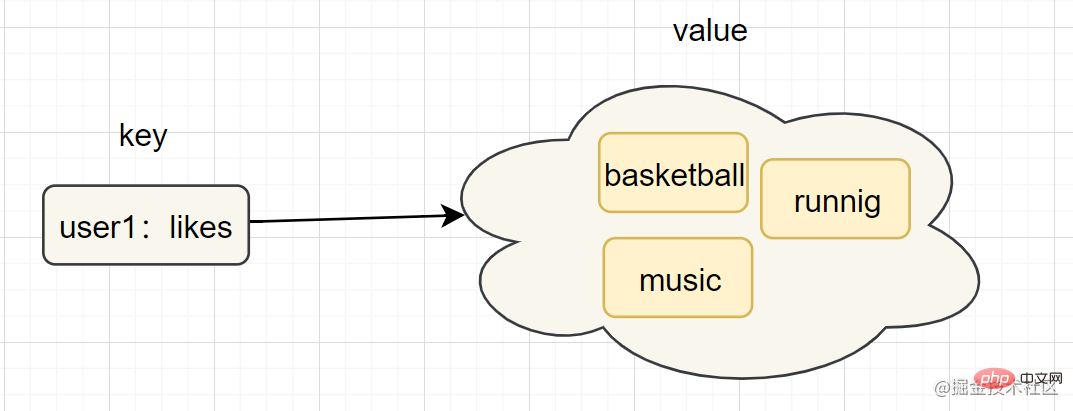
- 简介:集合(set)类型也是用来保存多个的字符串元素,但是不允许重复元素
- 简单使用举例:
sadd key element [element ...]、smembers key - 内部编码:
intset(整数集合)、hashtable(哈希表)내부 인코딩에는 -
C 언어 문자열은
char[]로 구현되며 Redis는 SDS(Simple Dynamic String) - 을 사용하여 캡슐화됩니다. sds 소스 코드는 다음과 같습니다.
int(8바이트 긴 정수)/embstr(39바이트 문자열 이하)/raw(39바이트 문자열보다 큼) 3가지 유형이 있습니다zadd user:ranking:2021-03-03 Jay 3SDS 구조 다이어그램은 다음과 같습니다. :
🎜🎜Redis가 🎜SDS🎜를 선택한 이유 구조, C 언어 기본 char[] 맛있지 않나요? 🎜🎜예를 들어 SDS에서는 O(1) 시간 복잡도로 문자열 길이를 얻을 수 있지만 C 문자열의 경우 전체 문자열을 순회해야 하며 시간 복잡도는 O(n)입니다.🎜 blockquote >🎜Hash(Hash)🎜🎜🎜소개: Redis에서 해시 유형은 키-값 쌍(k-v) 구조인 v(값) 자체를 참조합니다.🎜🎜간단한 사용 예:hset key field value, <code>hget 키 필드🎜🎜내부 인코딩:ziplist(압축 목록),hashtable(해시 테이블)🎜🎜애플리케이션 시나리오: 캐싱 사용자 정보 등 🎜🎜🎜Note🎜: hgetall을 개발에 사용하고 해시 요소가 많으면 Redis가 차단될 수 있습니다. hscan을 사용할 수 있습니다. 일부 필드만 가져오려면 hmget을 사용하는 것이 좋습니다. 🎜🎜🎜문자열과 해시 유형의 비교는 다음과 같습니다. 🎜🎜🎜🎜List(list)🎜🎜🎜소개: list(list) 유형은 순서가 지정된 여러 문자열을 저장하는 데 사용됩니다. 목록은 최대 2^32-1 요소를 저장할 수 있습니다. 🎜🎜간단하고 실용적인 예:
lpush 키 값 [값 ...],lrange 키 시작 끝🎜🎜내부 인코딩: ziplist(압축 목록), linkedlist(연결 목록) )🎜 🎜응용 시나리오: 메시지 대기열, 기사 목록, 🎜🎜🎜한 그림에서 목록 유형의 삽입 및 팝업 이해: 🎜🎜🎜🎜lpush+lpop=Stack(스택) 🎜🎜lpush+rpop=Queue( 큐) 🎜🎜lpsh+ltrim =Capped Collection(제한된 컬렉션)🎜🎜lpush+brpop=Message Queue(메시지 큐)🎜🎜🎜Set(세트)🎜🎜sadd 키 요소 [요소 ...],smembers 키🎜🎜내부 인코딩:intset (정수 집합), hashtable( 해시 테이블)🎜🎜🎜Note🎜: smembers, lrange 및 hgetall은 상대적으로 무거운 명령이며 Redis를 차단할 가능성이 있는 경우 sscan을 사용하여 완료할 수 있습니다. . 🎜🎜응용 시나리오: 사용자 태그, 난수 복권 생성, 사회적 요구. 🎜🎜🎜주문세트(zset)🎜
- 소개: 정렬된 문자열 모음이며 요소는 반복될 수 없습니다.
- 간단한 형식 예:
zadd 주요 점수 멤버 [점수 멤버...],zrank 키 멤버zadd key score member [score member ...],zrank key member- 底层内部编码:
기본 내부 인코딩:ziplist(压缩列表)、skiplist(跳跃表)ziplist(압축 목록),skiplist(건너뛰기 목록)- 응용 시나리오: 순위, 사회적 요구(예: 사용자 좋아요).
2.2 Redis의 세 가지 특수 데이터 유형
3. 왜 그렇게 빠른가요?
- Geo: Redis 3.2에서 도입된 지리적 위치 위치 확인은 지리적 위치 정보를 저장하고 저장된 정보에 대해 작동하는 데 사용됩니다.
- HyperLogLog: 통계 웹사이트용 UV와 같은 카디널리티 통계 알고리즘에 사용되는 데이터 구조입니다.
- 비트맵: 요소의 상태를 매핑하려면 1비트를 사용하세요. Redis에서는 하위 레이어가 문자열 유형을 기반으로 합니다. 비트맵을 단위로 사용하여 배열로 변환할 수 있습니다.
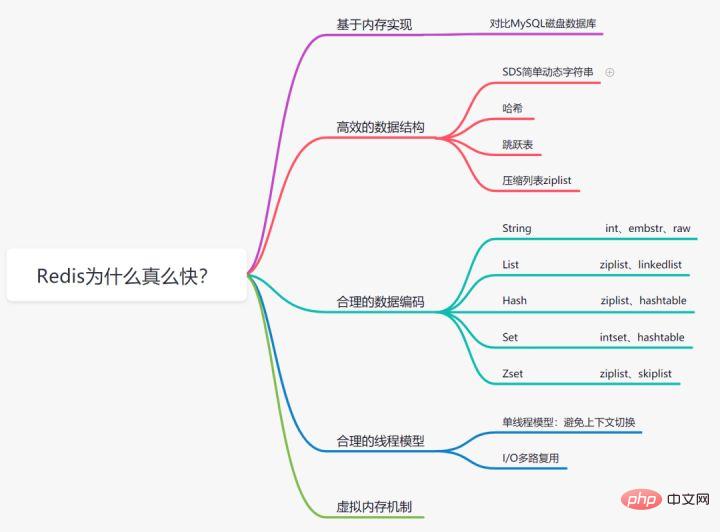
Redis가 빠른 이유
3.1 메모리 저장 기반
우리 모두는 메모리 읽기 및 쓰기가 디스크보다 훨씬 빠르다는 것을 알고 있습니다. Redis는 MySQL 데이터베이스에 비해 메모리 저장 기반으로 구현된 데이터베이스입니다. 데이터가 디스크에 저장되어 디스크 I/O 소비가 절약됩니다.3.2 효율적인 데이터 구조
Mysql 인덱스는 효율성을 높이기 위해 B+ 트리 데이터 구조를 선택한다는 것을 알고 있습니다. 실제로, 합리적인 데이터 구조는 애플리케이션/프로그램을 더 빠르게 만들 수 있습니다. 먼저 Redis의 데이터 구조 및 내부 인코딩 다이어그램을 살펴보겠습니다.SDS 단순 동적 문자열
- 문자열 길이 처리: Redis는 문자열 길이를 가져오고 시간 복잡도는 O(1)입니다. , C 언어에서는 처음부터 순회해야 하며 복잡성은 O(n)입니다.
- 공간 사전 할당: 문자열을 자주 수정할수록 메모리 할당이 더 자주 발생합니다. 성능을 소모하며, SDS 수정 및 공간 확장은 성능 손실을 줄이기 위해 사용되지 않는 공간을 추가로 할당해야 합니다.
- Lazy 공간 해제: SDS가 단축되면 초과된 메모리 공간을 재활용하는 대신 Free가 초과된 공간을 기록합니다. 이후 변경 사항이 있으면 Free로 기록된 공간을 직접 사용하여 할당을 줄입니다.
- 바이너리 안전성: Redis는 일부 바이너리 데이터, C 언어에서 발견되는 문자열을 저장할 수 있습니다.
- I/O: 네트워크 I/O
- 다채널: 여러 네트워크 연결
- 멀티플렉싱: 동일한 스레드를 재사용합니다.
- IO 멀티플렉싱은 실제로 여러 파일 핸들을 모니터링할 수 있는 스레드를 구현하는 동기식 IO 모델입니다. 파일 핸들이 준비되면 파일 핸들 없이 해당 읽기 및 쓰기 작업을 수행하도록 애플리케이션에 알릴 수 있습니다. 애플리케이션이 차단되고 CPU가 넘겨집니다.
단일 스레드 모델
- Redis는 단일 스레드 모델이며, 단일 스레딩은 불필요한 CPU 컨텍스트 전환 및 경쟁 잠금 소비를 방지합니다. 정확하게는 단일 스레드이기 때문에 특정 명령을 너무 오랫동안 실행하면(예: hgetall 명령) 차단이 발생합니다. Redis는 빠른 실행 시나리오를 위한 데이터베이스입니다. 이므로 smembers, lrange, hgetall 등과 같은 명령은 주의해서 사용해야 합니다.
- Redis 6.0은 속도를 높이기 위해 멀티스레딩을 도입했으며, 명령 실행 및 메모리 작업은 여전히 단일 스레드입니다.
3.5 가상 메모리 메커니즘
Redis는 일반 시스템처럼 시스템 기능을 호출하지 않고 이동 및 요청에 일정 시간을 낭비하지 않고 VM 메커니즘을 직접 구축합니다.
Redis의 가상 메모리 메커니즘은 무엇인가요?
가상 메모리 메커니즘은 자주 액세스하지 않는 데이터(콜드 데이터)를 메모리에서 디스크로 일시적으로 교환하여 액세스해야 하는 다른 데이터(핫 데이터)를 위한 귀중한 메모리 공간을 확보합니다. VM 기능은 핫 데이터와 콜드 데이터의 분리를 실현할 수 있으므로 핫 데이터는 여전히 메모리에 있고 콜드 데이터는 디스크에 저장됩니다. 이렇게 하면 메모리 부족으로 인해 액세스 속도가 느려지는 문제를 피할 수 있습니다.
4. 캐시 고장, 캐시 침투, 캐시 눈사태란 무엇인가요?
4.1 캐시 침투 문제
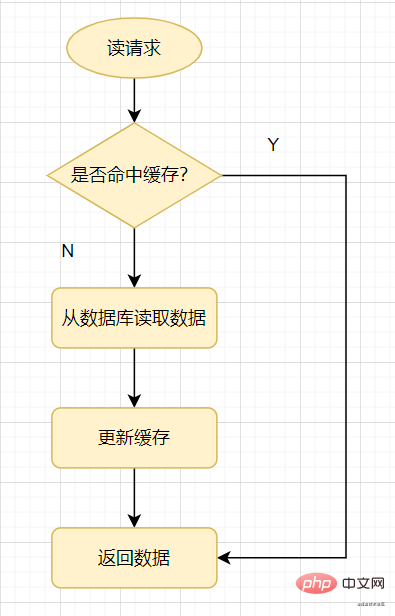
먼저 캐시를 사용하는 일반적인 방법을 살펴보겠습니다. 읽기 요청이 오면 먼저 캐시를 확인하고, 캐시가 값에 도달하면 직접 반환합니다. 히트하고 데이터베이스를 확인한 다음 데이터베이스 값을 캐시로 업데이트하고 반환합니다.
캐시 읽기
캐시 침투: 확실히 존재하지 않는 데이터를 조회하는 것을 말합니다. 캐시에 도달하지 않았기 때문에 데이터를 찾을 수 없으면 데이터베이스에서 조회해야 합니다. 존재하지 않는 데이터는 요청이 있을 때마다 데이터베이스에서 쿼리되어야 하므로 데이터베이스에 부담을 줍니다.
간단히 말하면, 읽기 요청에 접근할 때 캐시나 데이터베이스 모두 특정 값을 갖고 있지 않으며, 이로 인해 이 값에 대한 모든 쿼리 요청이 데이터베이스에 침투하게 됩니다.
캐시 침투는 일반적으로 다음과 같은 상황으로 인해 발생합니다.
- 비합리적인 비즈니스 설계 예를 들어 대부분의 사용자는 가드를 활성화하지 않았지만 모든 요청은 캐시로 이동하여 특정 사용자 ID를 쿼리합니다. 보호 장치가 있는지 확인하십시오.
- 캐시 및 데이터베이스 데이터가 실수로 삭제되는 등의 업무/운영 및 유지/개발 오류.
- 해커에 의한 불법 요청 공격 예를 들어, 해커는 존재하지 않는 비즈니스 데이터를 읽기 위해 의도적으로 수많은 불법 요청을 조작합니다.
캐시 침투를 피하는 방법은 무엇입니까? 일반적으로 세 가지 방법이 있습니다.
- 1. 불법 요청인 경우 API 입구에서 매개변수를 확인하고 불법 값을 필터링합니다.
- 2. 쿼리 데이터베이스가 비어 있으면 캐시에 null 값이나 기본값을 설정할 수 있습니다. 그러나 쓰기 요청이 들어오면 캐시 일관성을 보장하기 위해 캐시를 업데이트해야 하며 동시에 캐시에 대한 적절한 만료 시간이 설정됩니다. (비즈니스에서 자주 사용되며 간단하고 효과적입니다.)
- 3. Bloom 필터를 사용하면 데이터 존재 여부를 빠르게 확인할 수 있습니다. 즉, 쿼리 요청이 들어오면 Bloom 필터를 통해 해당 값이 존재하는지 먼저 판단한 후 계속해서 존재하는지 확인하는 것입니다.
Bloom 필터 원리: 초기 값이 0인 비트맵 배열과 N개의 해시 함수로 구성됩니다. 키에 대해 N개의 해시 알고리즘을 수행하여 N개의 값을 비트 배열에서 해시하고 1로 설정합니다. 그런 다음 확인 시 이러한 특정 위치가 모두 1이면 블룸 필터링을 통해 서버는 키가 존재한다고 판단합니다. .
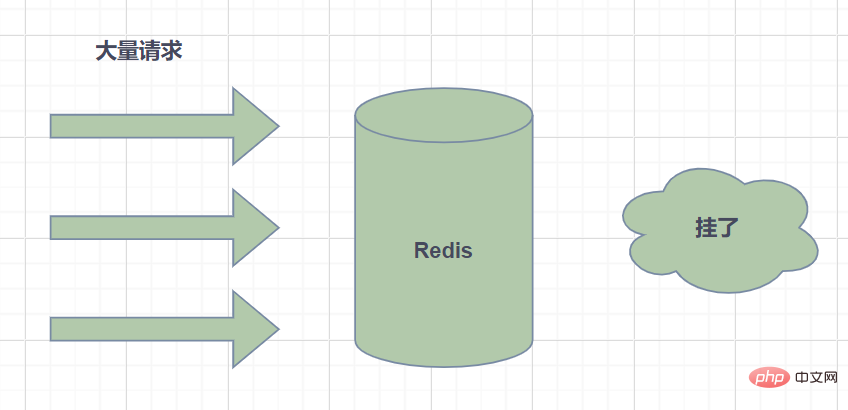
4.2 캐시 스노우런 문제
캐시 스노우런: 캐시에 있는 대용량 데이터의 만료 시간을 말하며 쿼리 데이터가 방대하고 요청이 데이터베이스에 직접 액세스하여 과도한 부담을 유발합니다. 데이터베이스는 물론 다운타임까지 발생합니다.
- 캐시 폭설은 일반적으로 동시에 많은 양의 데이터가 만료될 때 발생합니다. 따라서 만료 시간을 균등하게 설정하는 것, 즉 만료 시간을 상대적으로 이산적으로 설정하면 해결할 수 있습니다. 더 큰 고정 값 + 더 작은 임의 값을 사용하는 경우 5시간 + 0 ~ 1800초입니다.
- Redis 오류로 인해 캐시 폭설이 발생할 수도 있습니다. 이를 위해서는 Redis 고가용성 클러스터를 구축해야 합니다.
4.3 캐시 고장 문제
캐시 고장: 핫스팟 키가 특정 시점에 만료되는 경우를 말하며, 이 시점에서 이 키에 대한 동시 요청이 많아 결과적으로 많은 수의 요청이 db를 조회했습니다.
캐시 고장은 실제로 약간 비슷해 보이지만 캐시 충돌은 데이터베이스가 과도한 압력을 받거나 심지어 다운되었다는 의미입니다. 캐시 고장은 단지 DB 데이터베이스 수준에 대한 동시 요청 수가 많은 것입니다. 고장은 캐시 스노우런의 하위 집합이라고 간주할 수 있습니다. 일부 기사에서는 둘 사이의 차이점이 분석이 특정 단축키 캐시를 목표로 하는 반면 Xuebeng은 많은 키를 목표로 한다는 점이라고 생각합니다.
두 가지 해결책이 있습니다:
- 1 뮤텍스 잠금 방식을 사용하세요. 캐시가 실패하면 db 데이터를 즉시 로드하는 대신 먼저 (Redis의 setnx)와 같은 성공적인 반환과 함께 일부 원자성 작업 명령을 사용하여 작업합니다. 성공하면 db 데이터베이스 데이터를 로드하고 캐시를 설정합니다. 그렇지 않으면 캐시를 다시 가져오십시오.
- 2. "만료되지 않음"은 만료 시간이 설정되지 않았지만 핫스팟 데이터가 만료되려고 할 때 비동기 스레드가 업데이트되고 만료 시간을 설정한다는 의미입니다.
5. 단축키 문제가 무엇이며 단축키 문제를 해결하는 방법
단축키가 무엇인가요? Redis에서는 액세스 빈도가 높은 키를 핫스팟 키로 호출합니다.
특정 핫스팟 키에 대한 요청이 서버 호스트로 전송되는 경우 요청량이 특히 많아 호스트 리소스가 부족하거나 다운타임이 발생하여 정상적인 서비스에 영향을 줄 수 있습니다.
그리고 핫스팟 키는 어떻게 생성되나요? 두 가지 주요 이유가 있습니다:
- 플래시 세일, 핫 뉴스 및 읽기가 많고 쓰기가 적은 기타 시나리오와 같이 사용자가 소비하는 데이터는 생성된 데이터보다 훨씬 큽니다.
- 요청 샤딩이 집중되어 단일 Redi 서버의 성능을 초과합니다. 예를 들어 고정 이름 키와 해시가 동일한 서버에 속하면 즉시 액세스량이 많아 머신 병목 현상을 초과하고 핫이 발생합니다. 주요 문제.
그렇다면 일상적인 개발에서 단축키를 식별하는 방법은 무엇일까요?
- 경험을 바탕으로 어떤 단축키를 결정합니다.
- 클라이언트 통계 보고
- 서비스 에이전트 계층에 보고
단축키 문제를 해결하는 방법은 무엇입니까?
- Redis 클러스터 확장: 샤드 복사본을 추가하여 읽기 트래픽 균형을 유지합니다.
- 핫 키를 다른 서버에 배포합니다.
- 2차 수준 캐시, 즉 JVM 로컬 캐시를 사용하여 Redis 읽기 요청을 줄입니다.
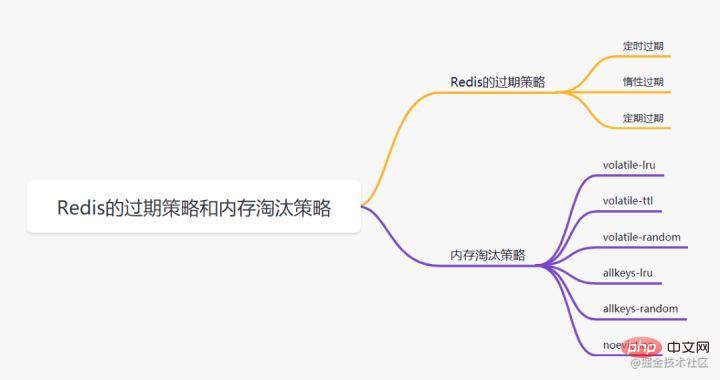
6. Redis 만료 전략 및 메모리 제거 전략
6.1 Redis 만료 전략
여기 있습니다
set key的时候,可以给它设置一个过期时间,比如expire key 60. 이 키가 60초 후에 만료되도록 지정합니다. Redis는 60초 후에 이를 어떻게 처리합니까? 먼저 몇 가지 만료 전략을 소개하겠습니다.Timed 만료
만료 시간이 있는 각 키는 타이머를 생성해야 하며, 만료 시간에 도달하면 키가 즉시 삭제됩니다. 이 전략은 만료된 데이터를 즉시 지울 수 있고 메모리 친화적이지만 만료된 데이터를 처리하는 데 많은 양의 CPU 리소스를 차지하므로 캐시 응답 시간과 처리량에 영향을 미칩니다.
지연 만료
키에 액세스할 때만 키가 만료되었는지 판단하고, 만료되면 삭제됩니다. 이 전략은 CPU 자원을 최대한 절약할 수 있지만 메모리에는 매우 비우호적입니다. 극단적인 경우에는 만료된 많은 수의 키에 다시 액세스할 수 없으므로 삭제되지 않고 많은 양의 메모리를 차지할 수 있습니다.
주기적인 만료
특정 시간마다 특정 수의 데이터베이스 만료 사전에 있는 특정 수의 키가 스캔되고 만료된 키가 지워집니다. 이 전략은 처음 두 가지의 절충안입니다. 예약된 스캔의 시간 간격과 각 스캔의 제한된 시간 소비를 조정함으로써 다양한 상황에서 CPU와 메모리 리소스 간의 최적의 균형을 달성할 수 있습니다.
만료 사전은 만료 시간이 설정된 모든 키의 만료 시간 데이터를 저장합니다. 여기서 키는 키 공간의 키에 대한 포인터이고 값은 밀리초 정밀도로 키의 UNIX 타임스탬프로 표시되는 만료 시간입니다. 키 공간은 Redis 클러스터에 저장된 모든 키를 나타냅니다.
Redis는 지연 만료와 주기적 만료 두 가지 만료 전략을 모두 사용합니다.
- 假设Redis当前存放30万个key,并且都设置了过期时间,如果你每隔100ms就去检查这全部的key,CPU负载会特别高,最后可能会挂掉。
- 因此,redis采取的是定期过期,每隔100ms就随机抽取一定数量的key来检查和删除的。
- 但是呢,最后可能会有很多已经过期的key没被删除。这时候,redis采用惰性删除。在你获取某个key的时候,redis会检查一下,这个key如果设置了过期时间并且已经过期了,此时就会删除。
但是呀,如果定期删除漏掉了很多过期的key,然后也没走惰性删除。就会有很多过期key积在内存内存,直接会导致内存爆的。或者有些时候,业务量大起来了,redis的key被大量使用,内存直接不够了,运维小哥哥也忘记加大内存了。难道redis直接这样挂掉?不会的!Redis用8种内存淘汰策略保护自己~
6.2 Redis 内存淘汰策略
- volatile-lru:当内存不足以容纳新写入数据时,从设置了过期时间的key中使用LRU(最近最少使用)算法进行淘汰;
- allkeys-lru:当内存不足以容纳新写入数据时,从所有key中使用LRU(最近最少使用)算法进行淘汰。
- volatile-lfu:4.0版本新增,当内存不足以容纳新写入数据时,在过期的key中,使用LFU算法进行删除key。
- allkeys-lfu:4.0版本新增,当内存不足以容纳新写入数据时,从所有key中使用LFU算法进行淘汰;
- volatile-random:当内存不足以容纳新写入数据时,从设置了过期时间的key中,随机淘汰数据;。
- allkeys-random:当内存不足以容纳新写入数据时,从所有key中随机淘汰数据。
- volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的key中,根据过期时间进行淘汰,越早过期的优先被淘汰;
- noeviction:默认策略,当内存不足以容纳新写入数据时,新写入操作会报错。
7.说说Redis的常用应用场景
- 缓存
- 排行榜
- 计数器应用
- 共享Session
- 分布式锁
- 社交网络
- 消息队列
- 位操作
7.1 缓存
我们一提到redis,自然而然就想到缓存,国内外中大型的网站都离不开缓存。合理的利用缓存,比如缓存热点数据,不仅可以提升网站的访问速度,还可以降低数据库DB的压力。并且,Redis相比于memcached,还提供了丰富的数据结构,并且提供RDB和AOF等持久化机制,强的一批。
7.2 排行榜
当今互联网应用,有各种各样的排行榜,如电商网站的月度销量排行榜、社交APP的礼物排行榜、小程序的投票排行榜等等。Redis提供的
zset数据类型能够实现这些复杂的排行榜。比如,用户每天上传视频,获得点赞的排行榜可以这样设计:
- 1.用户Jay上传一个视频,获得6个赞,可以酱紫:
zadd user:ranking:2021-03-03 Jay 3
- 2.过了一段时间,再获得一个赞,可以这样:
zincrby user:ranking:2021-03-03 Jay 1
- 3.如果某个用户John作弊,需要删除该用户:
zrem user:ranking:2021-03-03 John
- 4.展示获取赞数最多的3个用户
zrevrangebyrank user:ranking:2021-03-03 0 27.3 计数器应用
各大网站、APP应用经常需要计数器的功能,如短视频的播放数、电商网站的浏览数。这些播放数、浏览数一般要求实时的,每一次播放和浏览都要做加1的操作,如果并发量很大对于传统关系型数据的性能是一种挑战。Redis天然支持计数功能而且计数的性能也非常好,可以说是计数器系统的重要选择。
7.4 共享Session
如果一个分布式Web服务将用户的Session信息保存在各自服务器,用户刷新一次可能就需要重新登录了,这样显然有问题。实际上,可以使用Redis将用户的Session进行集中管理,每次用户更新或者查询登录信息都直接从Redis中集中获取。
7.5 分布式锁
几乎每个互联网公司中都使用了分布式部署,分布式服务下,就会遇到对同一个资源的并发访问的技术难题,如秒杀、下单减库存等场景。
- 동기화 또는 재진입 잠금 로컬 잠금을 사용하면 확실히 작동하지 않습니다.
- 동시성이 크지 않다면 데이터베이스의 비관적 잠금과 낙관적 잠금을 사용해도 문제가 없습니다.
- 그러나 동시성이 높은 상황에서는 데이터베이스 잠금을 사용하여 리소스에 대한 동시 액세스를 제어하면 데이터베이스 성능에 영향을 미칩니다.
- 실제로 Redis의 setnx를 사용하여 분산 잠금을 구현할 수 있습니다.
7.6 소셜 네트워크
좋아요/싫어요, 팬, 공통 친구/좋아요, 푸시, 풀다운 새로 고침 등은 일반적으로 소셜 네트워킹 사이트의 방문 횟수가 상대적으로 적기 때문에 소셜 네트워킹 사이트의 필수 기능입니다. 이러한 유형의 데이터를 저장하는 것은 매우 적합하며 Redis에서 제공하는 데이터 구조는 이러한 기능을 비교적 쉽게 구현할 수 있습니다.
7.7 메시지 대기열
메시지 대기열은 ActiveMQ, RabbitMQ, Kafka 및 기타 널리 사용되는 메시지 대기열 미들웨어와 같은 대규모 웹 사이트에 꼭 필요한 미들웨어입니다. 주로 비즈니스 분리, 트래픽 피크 감소 및 비동기 처리에 사용됩니다. 실시간 비즈니스가 낮습니다. Redis는 간단한 메시지 큐 시스템을 구현할 수 있는 게시/구독 및 차단 큐 기능을 제공합니다. 또한 이는 전문적인 메시지 미들웨어와 비교할 수 없습니다.
7.8비트 연산
은 수억 명의 사용자의 시스템 체크인, 중복 로그인 횟수 통계, 사용자의 온라인 여부 등 수억 개의 데이터가 있는 시나리오에서 사용됩니다. Tencent에는 10억 명의 사용자가 있습니다. 몇 밀리초 내에 사용자가 온라인 상태인지 어떻게 확인할 수 있나요? 각 사용자에 대한 키를 생성한 다음 하나씩 기록하라고 말하지 마십시오(필요한 메모리를 계산할 수 있으며 이는 매우 무섭고 유사한 요구 사항이 많이 있습니다. 여기서 적절한 작업을 사용하십시오. setbit, getbit 및 bitcount 명령의 원칙은 다음과 같습니다. Redis에서 충분히 긴 배열을 구축하고, 각 배열 요소는 0과 1의 두 값만 가질 수 있으며, 이 배열의 아래 첨자 인덱스는 사용자 ID를 나타내는 데 사용됩니다(반드시 숫자) 그렇다면 당연히 수억 개의 큰 배열은 첨자와 요소 값(0 및 1)을 통해 메모리 시스템을 구축할 수 있습니다.
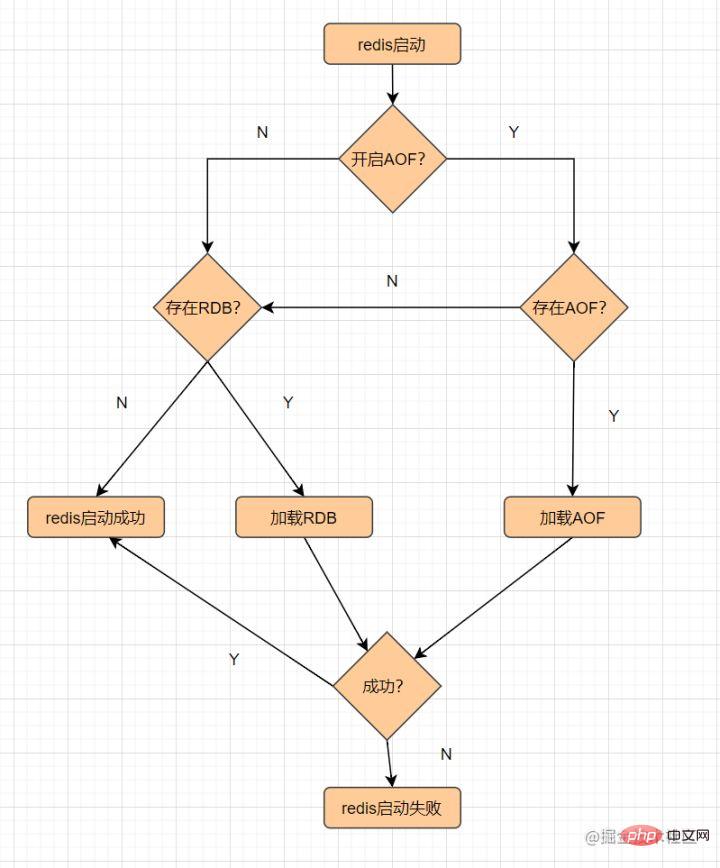
8. Redis의 장점과 단점은 무엇입니까? 비관계형 K-V 데이터베이스는 메모리를 기반으로 하기 때문에 Redis 서버가 중단되면 데이터가 손실됩니다. 데이터 손실을 방지하기 위해 Redis는 데이터를 디스크에 저장하는 것을 의미하는 지속성
을 제공합니다. 지속성 메커니즘에는RDB 및 AOF 두 가지가 있습니다. 영구 파일 로드 프로세스는 다음과 같습니다.
8.1 RDB
RDB. 이는 메모리 데이터를 스냅샷 형식으로 디스크에 저장합니다.
스냅샷이란 이렇게 이해하면 됩니다. 현재 순간의 데이터를 사진으로 찍어 저장하는 것입니다.
RDB 지속성은 지정된 시간 내에 지정된 횟수의 쓰기 작업을 수행하는 것을 의미합니다. 데이터 세트 스냅샷은 Redis의 기본 지속 방식으로 디스크에 기록되며, 작업이 완료된 후 지정된 디렉터리에파일이 생성됩니다. 주요 RDB 트리거 메커니즘은 다음과 같습니다.RDB의 장점
dump.rdb文件,Redis 重启的时候,通过加载dump.rdb
백업, 전체 복제 등 대규모 데이터 복구 시나리오에 적합합니다.
RDB의 단점
실시간 지속성/2차 수준 지속성을 달성할 수 없습니다. 새 버전과 이전 버전이 존재합니다. RDB 형식 호환성 문제
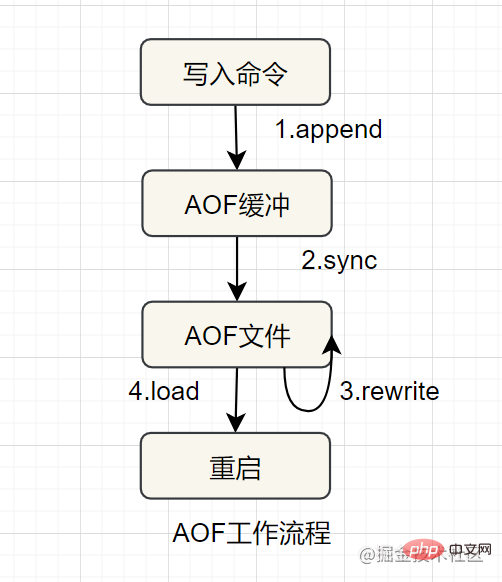
- AOF
AOF(파일만 추가) 지속성, 로그 형식을 사용하여 각 쓰기 작업 기록 , 파일에 추가하고 데이터 복원을 다시 시작할 때 AOF 파일에서 명령을 다시 실행합니다. 이는 주로 데이터 지속성의 실시간 문제를 해결합니다. AOF의 작업 흐름은 다음과 같습니다.
AOF는 일관성과 무결성이 더 높습니다.
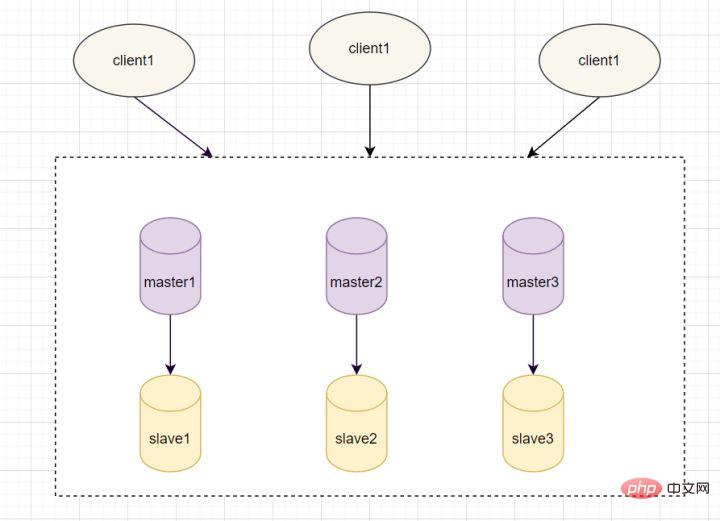
Redis를 사용하는 방법은 무엇입니까? Redis 서비스의 단일 지점 배포는 절대 아닙니다. 단일 지점 배포가 중단되면 더 이상 사용할 수 없습니다. 고가용성을 달성하기 위해 일반적인 방법은 여러 복사본을 복사하는 것입니다. 하나의 머신이 다운되더라도 계속해서 서비스를 제공할 수 있습니다. Redis에는 고가용성을 달성하기 위한 세 가지 배포 모드가 있습니다:
마스터-슬레이브 모드, 센티넬 모드
- 9.1 마스터-슬레이브 모드
마스터-슬레이브 모드에서 Redis는 여러 개의 시스템을 배포합니다. 각 머신에는 읽기 및 쓰기 작업을 담당하는 마스터 노드와 읽기 작업만 담당하는 슬레이브 노드가 있습니다. 슬레이브 노드의 데이터는 마스터 노드에서 나오며 구현 원리는 마스터-슬레이브 복제 메커니즘
입니다.
마스터-슬레이브 복제에는 전체 복제와 증분 복제가 포함됩니다. 일반적으로 슬레이브가 마스터에 처음 연결을 시작하거나 처음 연결한 것으로 간주할 때 full copy를 사용합니다. 전체 복사 과정은 다음과 같습니다.
- 1 .슬레이브는 마스터에게 동기화 명령을 보냅니다.
- 2. SYNC 명령을 받은 후 마스터는 bgsave 명령을 실행하여 전체 RDB 파일을 생성합니다.
- 3. 마스터는 버퍼를 사용하여 RDB 스냅샷 생성 중 모든 쓰기 명령을 기록합니다.
- 4. 마스터는 bgsave를 실행한 후 RDB 스냅샷 파일을 모든 슬레이브에 보냅니다.
- 5. RDB 스냅샷 파일을 수신한 후 슬레이브는 수신된 스냅샷을 로드하고 구문 분석합니다.
- 6. 마스터는 버퍼를 사용하여 RDB 동기화 중에 생성된 모든 작성된 명령을 기록합니다.
- 7. 마스터 스냅샷이 전송된 후 버퍼의 쓰기 명령을 슬레이브로 보내기 시작합니다.
- 8.salve는 명령 요청을 수락하고 마스터 버퍼에서 쓰기 명령을 실행합니다.
redis2.8 이후 버전에서는 sync 명령이 시스템 리소스를 소비하고 psync가 더 효율적이기 때문에 psync를 사용하여 sync를 대체했습니다.
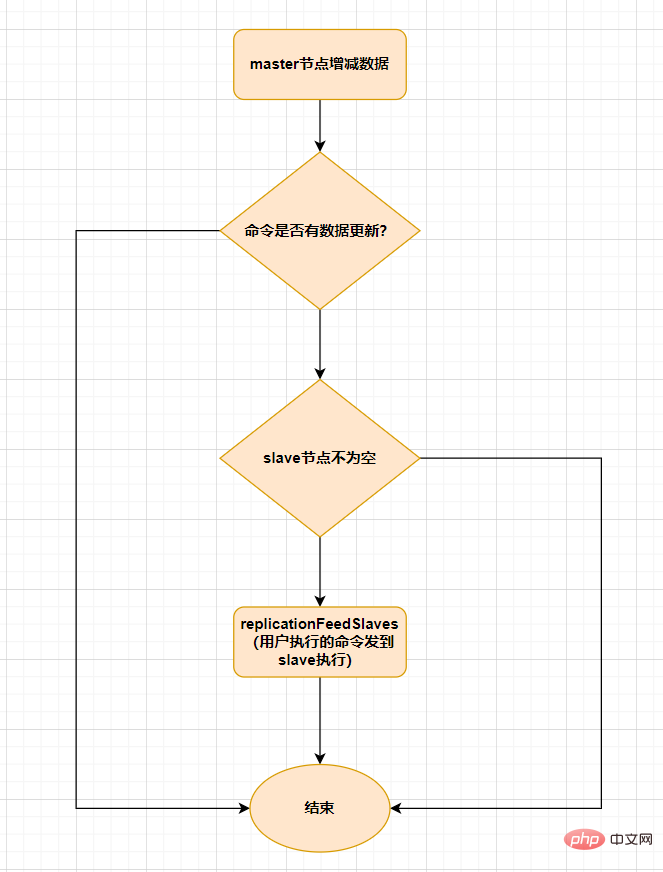
슬레이브가 마스터와 완전히 동기화된 후 마스터의 데이터가 다시 업데이트되면 증분 복제가 실행됩니다.
마스터 노드에서 데이터가 증가하거나 감소하면
replicationFeedSalves()函数,接下来在 Master节点上调用的每一个命令会使用replicationFeedSlaves()가 트리거되어 슬레이브 노드에 동기화됩니다. 이 기능을 실행하기 전에 마스터 노드는 사용자가 실행한 명령에 데이터 업데이트가 있는지 확인하고, 데이터 업데이트가 있고 슬레이브 노드가 비어 있지 않은 경우 이 기능을 실행합니다. 이 기능의 기능은 다음과 같습니다. 사용자가 실행한 명령을 모든 슬레이브 노드에 전송하고 슬레이브 노드가 이를 실행하도록 합니다. 프로세스는 다음과 같습니다.
9.2 Sentinel 모드
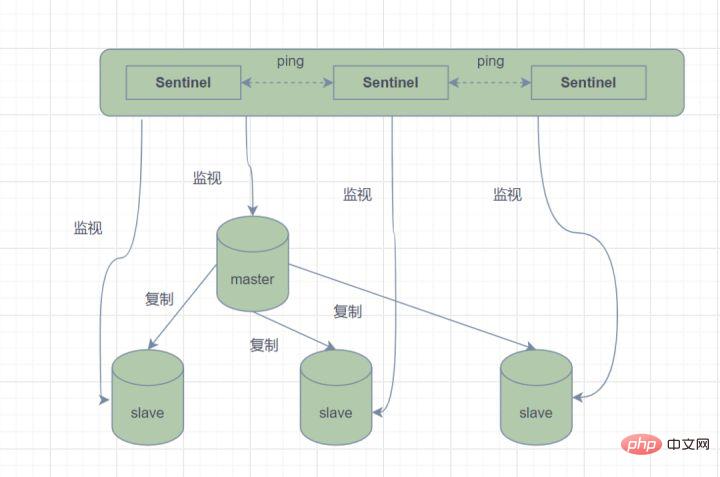
마스터-슬레이브 모드에서는 마스터 노드가 장애로 인해 서비스를 제공할 수 없게 되면 수동으로 슬레이브 노드를 마스터 노드로 승격시켜야 하며, 동시에 애플리케이션에 마스터 노드 주소를 업데이트하도록 알립니다. 분명히 이 오류 처리 방법은 대부분의 비즈니스 시나리오에서 허용되지 않습니다. Redis는 이러한 문제를 해결하기 위해 2.8부터 공식적으로 Redis Sentinel(Sentinel) 아키텍처를 제공합니다.
Sentinel 모드는 하나 이상의 Sentinel 인스턴스로 구성된 Sentinel 시스템으로 모든 Redis 마스터 노드와 슬레이브 노드를 모니터링할 수 있으며, 모니터링되는 마스터 노드가 오프라인 상태가 되면 아래의 오프라인 마스터 A 슬레이브 노드를 자동으로 제거합니다. 서버가 새로운 마스터 노드로 업그레이드됩니다. 그러나 Sentinel 프로세스가 Redis 노드를 모니터링하는 경우 문제가 발생할 수 있습니다(Single Point Problem). 따라서 여러 Sentinel을 사용하여 Redis 노드를 모니터링할 수 있으며 각 Sentinel도 서로 모니터링합니다.
Sentinel 모드
간단히 말하면 Sentinel 모드에는 세 가지 기능이 있습니다.
- 명령을 보내고 Redis 서버(마스터 서버 및 슬레이브 서버 포함)가 실행 상태를 모니터링하기 위해 돌아올 때까지 기다립니다.
- Sentinel 모니터 마스터 노드가 다운되면 자동으로 슬레이브 노드에서 마스터 노드로 전환한 다음 게시 및 구독 모드를 통해 다른 슬레이브 노드에 알리고 구성 파일을 수정하여 호스트를 전환하게 합니다.
- 센티널은 또한 고가용성을 달성하기 위해 서로 모니터링합니다.
페일오버 프로세스는 무엇인가요?
메인 서버가 다운되고 Sentinel 1이 이 결과를 먼저 감지한다고 가정하면 시스템이 페일오버 프로세스를 즉시 수행하지 않을 뿐입니다. 메인 서버를 사용할 수 없는 경우, 이 현상은 오프라인에서 주관적입니다. 후속 센티널도 주 서버를 사용할 수 없음을 감지하고 숫자가 특정 값에 도달하면 센티널 간에 투표가 진행됩니다. 투표 결과는 하나의 센티널에 의해 시작되어 장애 조치 작업을 수행합니다. 전환이 성공한 후 각 센티널은 게시-구독 모드를 사용하여 모니터링하는 슬레이브 서버를 호스트로 전환합니다. 이 프로세스를 목표 오프라인이라고 합니다. 이렇게 하면 모든 것이 클라이언트에게 투명해집니다.
Sentinel의 작동 모드는 다음과 같습니다.
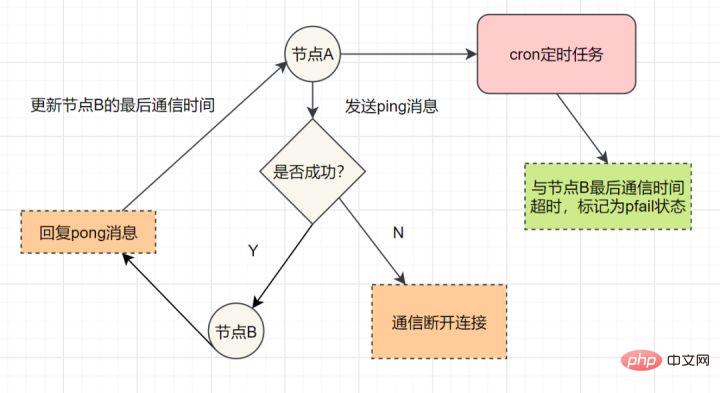
각 Sentinel은 마스터, 슬레이브 및 자신이 알고 있는 기타 Sentinel 인스턴스에 초당 한 번씩 PING 명령을 보냅니다.
PING 명령에 대한 마지막 유효한 응답 이후의 시간이 down-after-milliseconds 옵션에 지정된 값을 초과하는 경우 인스턴스는 Sentinel에 의해 주관적으로 오프라인으로 표시됩니다.
마스터가 주관적 오프라인 상태로 표시되면 이 마스터를 모니터링하는 모든 Sentinel은 마스터가 실제로 주관적 오프라인 상태에 진입했는지 1초에 한 번씩 확인해야 합니다.
충분한 수의 센티널(구성 파일에 지정된 값 이상)이 마스터가 지정된 시간 범위 내에 실제로 주관적인 오프라인 상태에 진입했음을 확인하면 마스터는 객관적으로 오프라인으로 표시됩니다.
일반적인 상황에서 각 센티널은 자신이 알고 있는 모든 마스터와 슬레이브에게 10초마다 한 번씩 INFO 명령을 보냅니다.
마스터가 Sentinel에 의해 객관적으로 오프라인으로 표시되면 Sentinel이 오프라인 마스터의 모든 슬레이브에 INFO 명령을 보내는 빈도가 10초에 한 번에서 1초에 한 번으로 변경됩니다.
충분하지 않은 경우 동의하는 센티넬 마스터가 오프라인인 경우 마스터의 객관적인 오프라인 상태가 제거됩니다. 마스터가 Sentinel의 PING 명령에 대해 유효한 응답을 다시 반환하면 마스터의 주관적인 오프라인 상태가 제거됩니다.
9.3 클러스터 클러스터 모드
센티넬 모드는 읽기와 쓰기의 분리를 구현하는 마스터-슬레이브 모드를 기반으로 하며 자동으로 전환할 수도 있으며 시스템 가용성이 더 높습니다. 하지만 각 노드에 저장되는 데이터가 동일하기 때문에 메모리가 낭비되고 온라인 확장이 쉽지 않습니다. 그리하여 클러스터 클러스터가 탄생하게 되었습니다. Redis 3.0에 추가되어 Redis의 분산 스토리지를 구현한 것입니다. 데이터를 분할합니다. 즉, 각 Redis 노드에 서로 다른 콘텐츠를 저장하여 온라인 확장 문제를 해결합니다. 또한 복제 및 장애 조치 기능도 제공합니다.
클러스터 클러스터 노드의 통신
Redis 클러스터는 여러 노드로 구성됩니다. 각 노드는 어떻게 서로 통신합니까? 가십 프로토콜을 통해!
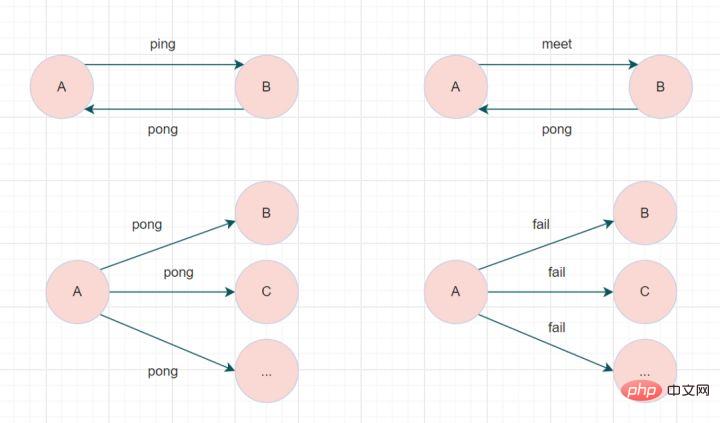
Redis Cluster 클러스터는 Gossip 프로토콜을 통해 통신합니다. 노드는 지속적으로 정보를 교환합니다. 교환되는 정보에는 노드 실패, 새 노드 가입, 마스터-슬레이브 노드 변경 정보 등이 포함됩니다. 일반적으로 사용되는 가십 메시지는 핑(Ping), 퐁(Pong), 만남(Meet), 실패(Fail)의 네 가지 유형으로 구분됩니다.
- 미트 메시지: 새로운 노드에 참여하도록 알립니다. 메시지 발신자는 수신자에게 현재 클러스터에 가입하라고 알립니다. Meet 메시지 통신이 정상적으로 완료된 후 수신 노드는 클러스터에 가입하고 주기적으로 ping 및 pong 메시지 교환을 수행합니다.
- Ping 메시지: 클러스터에서 가장 자주 교환되는 메시지입니다. 클러스터의 각 노드는 1초마다 여러 다른 노드에 ping 메시지를 보내며, 이를 통해 노드가 온라인인지 여부를 감지하고 서로 상태 정보를 교환합니다.
- 퐁 메시지: 핑이나 미팅 메시지를 받으면 메시지의 정상적인 통신을 확인하기 위해 보낸 사람에게 응답 메시지로 회신합니다. Pong 메시지는 자체 상태 데이터를 내부적으로 캡슐화합니다. 노드는 자체 퐁 메시지를 클러스터에 브로드캐스트하여 전체 클러스터에 자체 상태를 업데이트하도록 알릴 수도 있습니다.
- 실패 메시지: 노드가 클러스터의 다른 노드가 오프라인임을 확인하면 실패 메시지를 수신한 후 다른 노드가 해당 노드를 오프라인 상태로 업데이트합니다.
특히 각 노드는 클러스터 버스를 통해 다른 노드와 통신합니다. 통신 시에는 특수한 포트 번호, 즉 외부 서비스 포트 번호에 10000을 더한 번호를 사용하세요. 예를 들어, 노드의 포트 번호가 6379인 경우 다른 노드와 통신하는 데 사용되는 포트 번호는 16379입니다. 노드 간 통신은 특수 바이너리 프로토콜을 사용합니다.
해시 슬롯 알고리즘
분산 저장소이기 때문에 클러스터 클러스터에서 사용하는 분산 알고리즘은 일관된 해시? 아니요, 해시 슬롯 알고리즘입니다.
슬롯 알고리즘 전체 데이터베이스는 16384개의 슬롯(슬롯)으로 나누어집니다. Redis에 들어오는 각 키-값 쌍은 키에 따라 해시되어 이 16384개의 슬롯 중 하나에 할당됩니다. 사용된 해시 맵도 비교적 간단합니다. CRC16 알고리즘을 사용하여 16비트 값을 계산한 다음 모듈로 16384를 계산합니다. 데이터베이스의 각 키는 이러한 16384개 슬롯 중 하나에 속하며 클러스터의 각 노드는 이러한 16384개 슬롯을 처리할 수 있습니다.
클러스터의 각 노드는 해시 슬롯의 일부를 담당합니다. 예를 들어 현재 클러스터에는 노드 A, B, C가 있고 각 노드의 해시 슬롯 수는 16384/3이므로 다음과 같습니다.
- 노드 A가 해시 슬롯 0~5460을 담당
- 노드 B가 해시 슬롯 5461~10922를 담당
- 노드 C가 해시 슬롯 10923~16383을 담당
Redis 클러스터 클러스터
Redis 클러스터 클러스터에서, 16384개의 슬롯이 일치하는지 확인해야 합니다. 모든 노드가 정상적으로 작동하고 있습니다. 노드에 장애가 발생하면 해당 노드가 담당하는 슬롯도 무효화되고 전체 클러스터가 작동하지 않게 됩니다.
따라서 고가용성을 보장하기 위해 클러스터 클러스터는 마스터-슬레이브 복제를 도입하고 하나의 마스터 노드는 하나 이상의 슬레이브 노드에 해당합니다. 다른 마스터 노드가 마스터 노드 A를 ping할 때 마스터 노드의 절반 이상이 A와 통신하는 시간이 초과되면 마스터 노드 A가 다운된 것으로 간주됩니다. 마스터 노드가 다운되면 슬레이브 노드가 활성화됩니다.
Redis의 각 노드에는 두 가지가 있습니다. 하나는 슬롯이고 값 범위는 0~16383입니다. 다른 하나는 클러스터로, 클러스터 관리 플러그인으로 이해될 수 있습니다. 우리가 액세스하는 키가 도착하면 Redis는 CRC16 알고리즘을 기반으로 16비트 값을 얻은 다음 모듈로 16384 결과를 가져옵니다. Jiangzi의 각 키는 0에서 16383 사이의 해시 슬롯에 해당합니다. 이 값을 사용하여 해당 슬롯에 해당하는 노드를 찾은 다음 자동으로 해당 노드로 점프하여 액세스 작업을 수행합니다.
虽然数据是分开存储在不同节点上的,但是对客户端来说,整个集群Cluster,被看做一个整体。客户端端连接任意一个node,看起来跟操作单实例的Redis一样。当客户端操作的key没有被分配到正确的node节点时,Redis会返回转向指令,最后指向正确的node,这就有点像浏览器页面的302 重定向跳转。
故障转移
Redis集群实现了高可用,当集群内节点出现故障时,通过故障转移,以保证集群正常对外提供服务。
redis集群通过ping/pong消息,实现故障发现。这个环境包括主观下线和客观下线。
主观下线: 某个节点认为另一个节点不可用,即下线状态,这个状态并不是最终的故障判定,只能代表一个节点的意见,可能存在误判情况。
主观下线
客观下线: 指标记一个节点真正的下线,集群内多个节点都认为该节点不可用,从而达成共识的结果。如果是持有槽的主节点故障,需要为该节点进行故障转移。
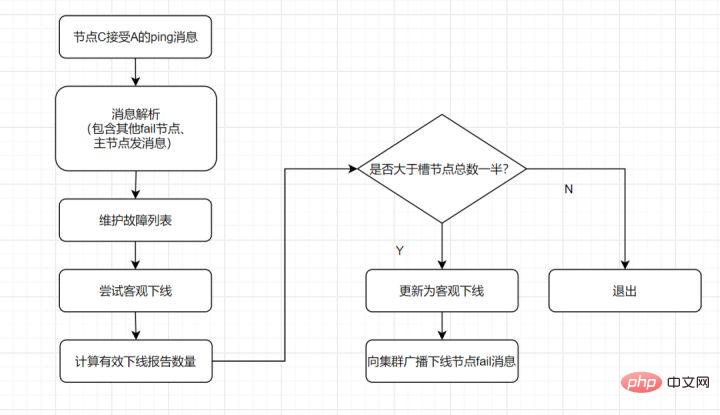
- 假如节点A标记节点B为主观下线,一段时间后,节点A通过消息把节点B的状态发到其它节点,当节点C接受到消息并解析出消息体时,如果发现节点B的pfail状态时,会触发客观下线流程;
- 当下线为主节点时,此时Redis Cluster集群为统计持有槽的主节点投票,看投票数是否达到一半,当下线报告统计数大于一半时,被标记为客观下线状态。
流程如下:
客观下线
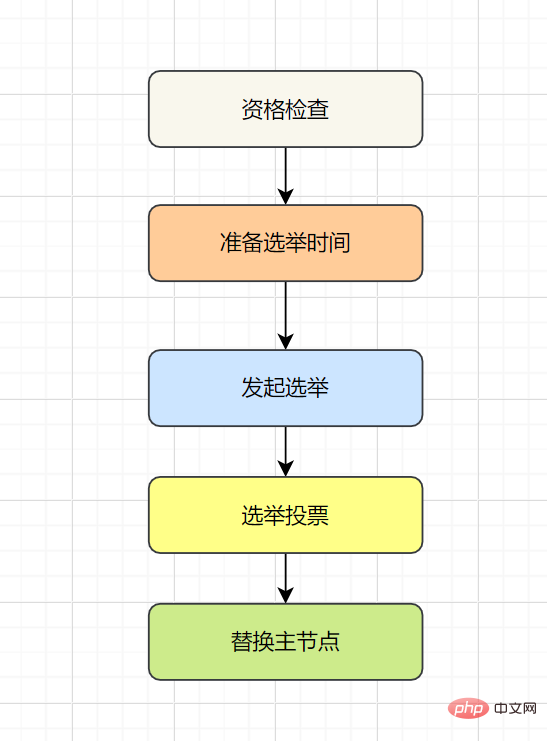
故障恢复:故障发现后,如果下线节点的是主节点,则需要在它的从节点中选一个替换它,以保证集群的高可用。流程如下:
- 资格检查:检查从节点是否具备替换故障主节点的条件。
- 准备选举时间:资格检查通过后,更新触发故障选举时间。
- 发起选举:到了故障选举时间,进行选举。
- 选举投票:只有持有槽的主节点才有票,从节点收集到足够的选票(大于一半),触发替换主节点操作
10. 使用过Redis分布式锁嘛?有哪些注意点呢?
分布式锁,是控制分布式系统不同进程共同访问共享资源的一种锁的实现。秒杀下单、抢红包等等业务场景,都需要用到分布式锁,我们项目中经常使用Redis作为分布式锁。
选了Redis分布式锁的几种实现方法,大家来讨论下,看有没有啥问题哈。
- 命令setnx + expire分开写
- setnx + value值是过期时间
- set的扩展命令(set ex px nx)
- set ex px nx + 校验唯一随机值,再删除
10.1 命令setnx + expire分开写
if(jedis.setnx(key,lock_value) == 1){ //加锁 expire(key,100); //设置过期时间 try { do something //业务请求 }catch(){ } finally { jedis.del(key); //释放锁 } }如果执行完
setnx加锁,正要执行expire设置过期时间时,进程crash掉或者要重启维护了,那这个锁就“长生不老”了,别的线程永远获取不到锁啦,所以分布式锁不能这么实现。10.2 setnx + value值是过期时间
long expires = System.currentTimeMillis() + expireTime; //系统时间+设置的过期时间 String expiresStr = String.valueOf(expires); // 如果当前锁不存在,返回加锁成功 if (jedis.setnx(key, expiresStr) == 1) { return true; } // 如果锁已经存在,获取锁的过期时间 String currentValueStr = jedis.get(key); // 如果获取到的过期时间,小于系统当前时间,表示已经过期 if (currentValueStr != null && Long.parseLong(currentValueStr) < System.currentTimeMillis()) { // 锁已过期,获取上一个锁的过期时间,并设置现在锁的过期时间(不了解redis的getSet命令的小伙伴,可以去官网看下哈) String oldValueStr = jedis.getSet(key_resource_id, expiresStr); if (oldValueStr != null && oldValueStr.equals(currentValueStr)) { // 考虑多线程并发的情况,只有一个线程的设置值和当前值相同,它才可以加锁 return true; } } //其他情况,均返回加锁失败 return false; }笔者看过有开发小伙伴是这么实现分布式锁的,但是这种方案也有这些缺点:
- 过期时间是客户端自己生成的,分布式环境下,每个客户端的时间必须同步。
- 没有保存持有者的唯一标识,可能被别的客户端释放/解锁。
- 锁过期的时候,并发多个客户端同时请求过来,都执行了
jedis.getSet(),最终只能有一个客户端加锁成功,但是该客户端锁的过期时间,可能被别的客户端覆盖。10.3:set的扩展命令(set ex px nx)(注意可能存在的问题)
if(jedis.set(key, lock_value, "NX", "EX", 100s) == 1){ //加锁 try { do something //业务处理 }catch(){ } finally { jedis.del(key); //释放锁 } }这个方案可能存在这样的问题:
- 锁过期释放了,业务还没执行完。
- 锁被别的线程误删。
10.4 set ex px nx + 校验唯一随机值,再删除
if(jedis.set(key, uni_request_id, "NX", "EX", 100s) == 1){ //加锁 try { do something //业务处理 }catch(){ } finally { //判断是不是当前线程加的锁,是才释放 if (uni_request_id.equals(jedis.get(key))) { jedis.del(key); //释放锁 } } }在这里,判断当前线程加的锁和释放锁是不是一个原子操作。如果调用jedis.del()释放锁的时候,可能这把锁已经不属于当前客户端,会解除他人加的锁。
一般也是用lua脚本代替。lua脚本如下:
if redis.call('get',KEYS[1]) == ARGV[1] then return redis.call('del',KEYS[1]) else return 0 end;这种方式比较不错了,一般情况下,已经可以使用这种实现方式。但是存在锁过期释放了,业务还没执行完的问题(实际上,估算个业务处理的时间,一般没啥问题了)。
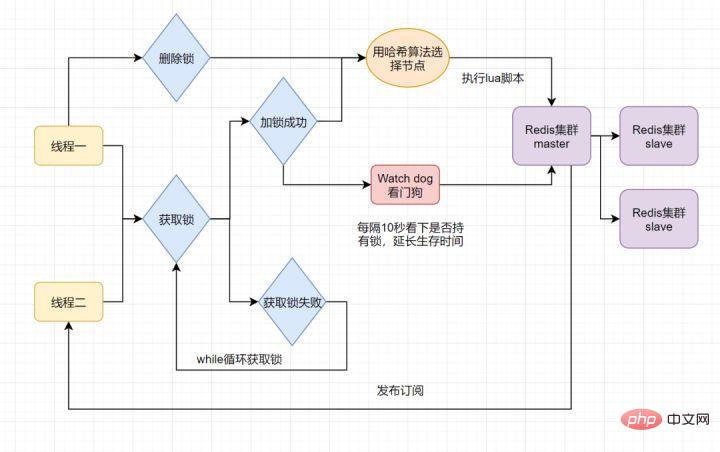
11. 使用过Redisson嘛?说说它的原理
分布式锁可能存在锁过期释放,业务没执行完的问题。有些小伙伴认为,稍微把锁过期时间设置长一些就可以啦。其实我们设想一下,是否可以给获得锁的线程,开启一个定时守护线程,每隔一段时间检查锁是否还存在,存在则对锁的过期时间延长,防止锁过期提前释放。
当前开源框架Redisson就解决了这个分布式锁问题。我们一起来看下Redisson底层原理是怎样的吧:
只要线程一加锁成功,就会启动一个
watch dog看门狗,它是一个后台线程,会每隔10秒检查一下,如果线程1还持有锁,那么就会不断的延长锁key的生存时间。因此,Redisson就是使用Redisson解决了锁过期释放,业务没执行完问题。12. 什么是Redlock算法
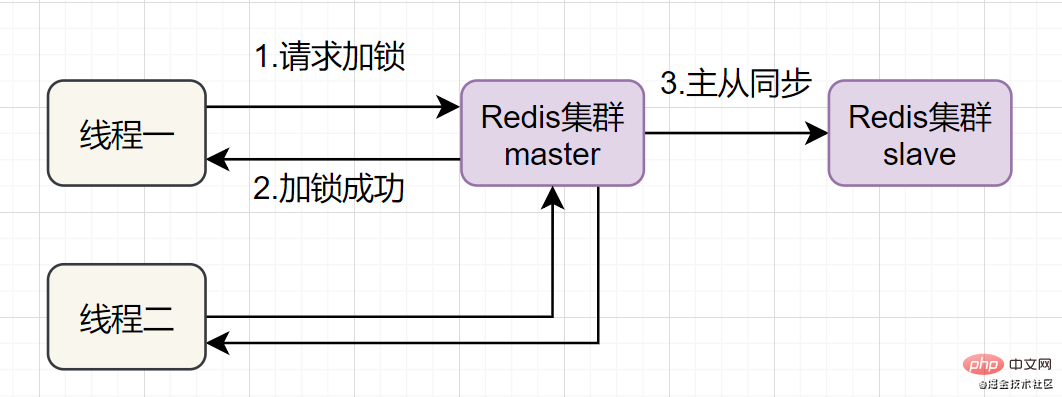
Redis一般都是集群部署的,假设数据在主从同步过程,主节点挂了,Redis分布式锁可能会有哪些问题呢?一起来看些这个流程图:
如果线程一在Redis的master节点上拿到了锁,但是加锁的key还没同步到slave节点。恰好这时,master节点发生故障,一个slave节点就会升级为master节点。线程二就可以获取同个key的锁啦,但线程一也已经拿到锁了,锁的安全性就没了。
为了解决这个问题,Redis作者 antirez提出一种高级的分布式锁算法:Redlock。Redlock核心思想是这样的:
搞多个Redis master部署,以保证它们不会同时宕掉。并且这些master节点是完全相互独立的,相互之间不存在数据同步。同时,需要确保在这多个master实例上,是与在Redis单实例,使用相同方法来获取和释放锁。
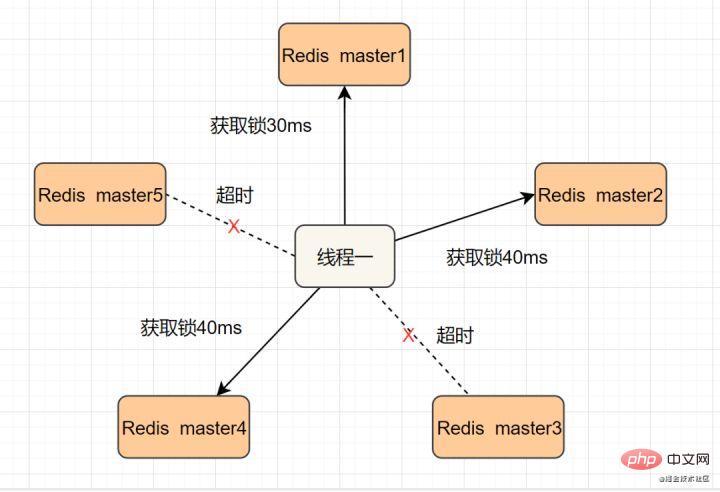
我们假设当前有5个Redis master节点,在5台服务器上面运行这些Redis实例。
RedLock的实现步骤:如下
- 1.获取当前时间,以毫秒为单位。
- 2.按顺序向5个master节点请求加锁。客户端设置网络连接和响应超时时间,并且超时时间要小于锁的失效时间。(假设锁自动失效时间为10秒,则超时时间一般在5-50毫秒之间,我们就假设超时时间是50ms吧)。如果超时,跳过该master节点,尽快去尝试下一个master节点。
- 3.客户端使用当前时间减去开始获取锁时间(即步骤1记录的时间),得到获取锁使用的时间。当且仅当超过一半(N/2+1,这里是5/2+1=3个节点)的Redis master节点都获得锁,并且使用的时间小于锁失效时间时,锁才算获取成功。(如上图,10s> 30ms+40ms+50ms+4m0s+50ms)
- 如果取到了锁,key的真正有效时间就变啦,需要减去获取锁所使用的时间。
- 如果获取锁失败(没有在至少N/2+1个master实例取到锁,有或者获取锁时间已经超过了有效时间),客户端要在所有的master节点上解锁(即便有些master节点根本就没有加锁成功,也需要解锁,以防止有些漏网之鱼)。
简化下步骤就是:
- 按顺序向5个master节点请求加锁
- 根据设置的超时时间来判断,是不是要跳过该master节点。
- 如果大于等于三个节点加锁成功,并且使用的时间小于锁的有效期,即可认定加锁成功啦。
- 如果获取锁失败,解锁!
13. Redis的跳跃表
跳跃表
- 스킵 테이블은 순서 집합 zset의 기본 구현 중 하나입니다.
- 스킵 테이블은 평균 O(logN), 최악의 경우 O(N) 복잡도 노드 조회를 지원하며 다음을 통해 노드를 일괄 처리할 수도 있습니다. 순차적 작업.
- 스킵 목록 구현은 zskiplist 및 zskiplistNode 두 가지 구조로 구성됩니다. 여기서 zskiplist는 스킵 테이블 정보(예: 헤더 노드, 테일 노드, 길이)를 저장하는 데 사용되고 zskiplistNode는 스킵 목록 노드를 나타내는 데 사용됩니다.
- 스킵 리스트는 연결 리스트를 기반으로 하며, 검색 효율성을 높이기 위해 다단계 인덱스를 추가합니다.
14. MySQL과 Redis는 어떻게 이중 쓰기 일관성을 보장합니까?
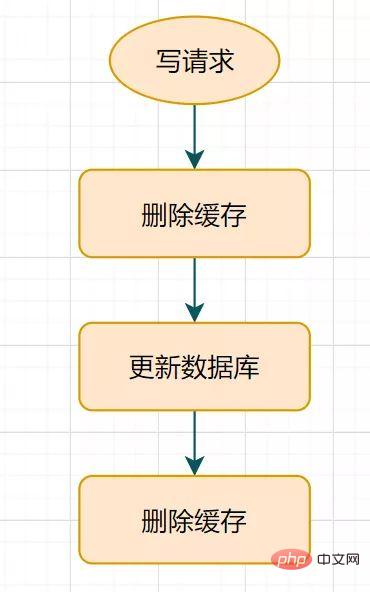
- 캐시 지연 이중 삭제
- 캐시 재시도 메커니즘 삭제
- biglog 읽기 및 캐시 비동기 삭제
14.1 지연된 이중 삭제?
지연 이중 삭제란 무엇인가요? 순서도는 다음과 같습니다.
지연된 이중 삭제 프로세스
- 캐시를 먼저 삭제하고
- 데이터베이스를 업데이트하고
- 잠깐(예: 1초) 잠자기 상태에서 캐시를 다시 삭제합니다.
잠깐 잠드는 데 보통 얼마나 걸리나요? 모두 1초인가요?
이 대기 시간 = 비즈니스 로직 데이터를 읽는 데 걸리는 시간 + 수백 밀리초. 읽기 요청이 종료되었는지 확인하기 위해 쓰기 요청은 읽기 요청으로 인해 발생할 수 있는 캐시된 더티 데이터를 삭제할 수 있습니다.
이 솔루션도 나쁘지 않습니다. 수면 시간(예: 단 1초)에만 더티 데이터가 있을 수 있으며, 일반 기업에서는 이를 허용합니다. 하지만 캐시 삭제에 두 번째 실패하면 어떻게 될까요? 캐시와 데이터베이스 데이터가 여전히 일치하지 않을 수 있습니다. 그렇죠? 키에 자연 만료 만료 시간을 설정하고 자동으로 만료되도록 하는 것은 어떻습니까? 기업은 만료 기간 내에 데이터 불일치를 수용해야 합니까? 아니면 다른 더 나은 해결책이 있습니까?
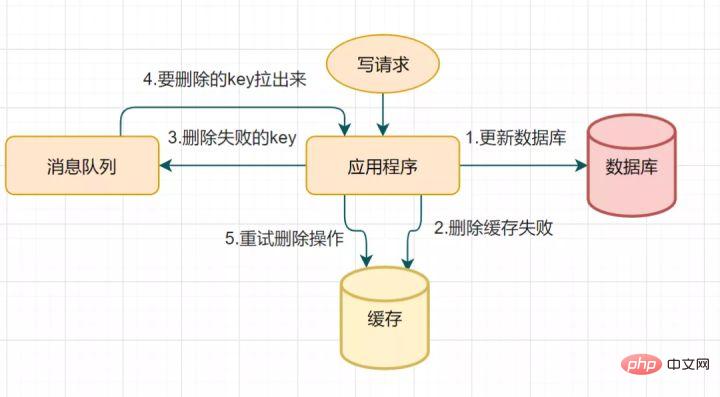
14.2 캐시 삭제 재시도 메커니즘
지연된 이중 삭제로 인해 두 번째 단계에서 캐시 삭제에 실패하여 데이터 불일치 문제가 발생할 수 있습니다. 이 솔루션을 사용하여 최적화할 수 있습니다. 삭제에 실패하면 몇 번 더 삭제하여 캐시 삭제가 성공했는지 확인하세요~ 그러면 삭제 캐시 재시도 메커니즘
삭제 캐시 재시도 프로세스
- 를 도입할 수 있습니다. 데이터베이스 업데이트 요청 쓰기
- 어떤 이유로 캐시 삭제에 실패했습니다
- 삭제에 실패한 키를 메시지 큐에 넣습니다
- 메시지 큐에서 메시지를 소비하고 삭제할 키를 가져옵니다
- 다시 시도하세요. 캐시 삭제 작업
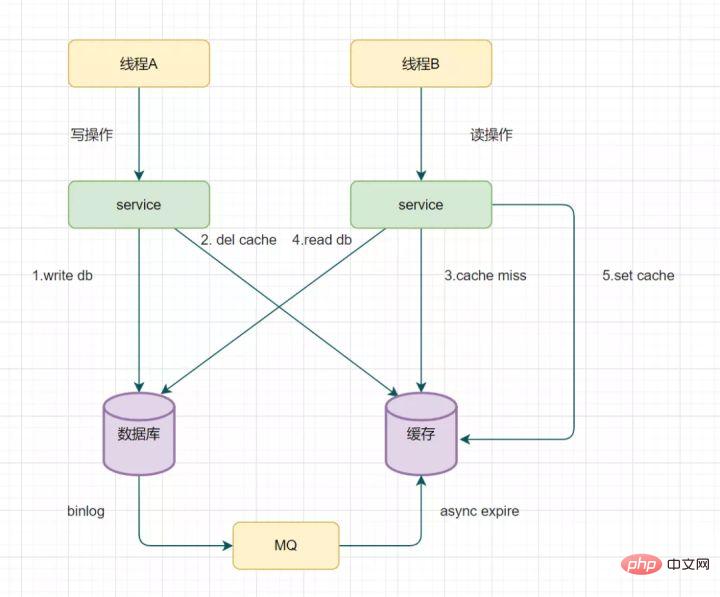
14.3 biglog를 읽고 비동기적으로 캐시 삭제
캐시 메커니즘 삭제를 다시 시도하는 것은 괜찮지만 비즈니스 코드 침입이 많이 발생할 수 있습니다. 실제로 데이터베이스의 binlog를 통해 키를 비동기적으로 제거하는 방식으로 최적화할 수도 있습니다.
mysql을 예로 들어보세요
- Alibaba 운하를 사용하여 binlog 로그를 수집하여 MQ 대기열로 보낼 수 있습니다
- 그런 다음 ACK 메커니즘을 통해 이 업데이트 메시지를 확인 및 처리하고, 캐시를 삭제하고, 데이터 캐시를 보장합니다. 일관성
15. Redis 6.0 이후 멀티스레딩이 변경된 이유는 무엇입니까?
- Redis 6.0 이전에는 Redis가 소켓 읽기, 구문 분석, 실행, 소켓 쓰기 등을 포함한 클라이언트 요청을 처리할 때 모두 순차 및 직렬 메인 스레드에 의해 처리되었습니다. 이것이 소위 "단일 스레드"입니다.
- Redis6.0 이전에는 왜 멀티스레딩을 사용하지 않았나요? Redis를 사용하면 CPU가 병목 현상을 일으키는 경우가 거의 없습니다. Redis는 주로 메모리와 네트워크의 제한을 받습니다. 예를 들어 일반적인 Linux 시스템에서 Redis는 파이프라이닝을 사용하여 초당 100만 개의 요청을 처리할 수 있으므로 애플리케이션이 주로 O(N) 또는 O(log(N)) 명령을 사용하는 경우 CPU를 거의 차지하지 않습니다.
Redis의 멀티 스레딩 사용이 단일 스레딩을 완전히 포기한다는 의미는 아닙니다. Redis는 여전히 단일 스레드 모델을 사용하여 데이터 읽기 및 쓰기와 프로토콜 분석을 처리합니다. 명령을 실행하기 위해 여전히 단일 스레드를 사용합니다.
이의 목적은 Redis의 성능 병목 현상이 CPU가 아닌 네트워크 IO에 있기 때문입니다. 멀티 스레딩을 사용하면 IO 읽기 및 쓰기 효율성이 향상되어 Redis의 전반적인 성능이 향상됩니다.
16. Redis 트랜잭션 메커니즘에 대해 이야기해 보겠습니다.
Redis는 MULTI, EXEC, WATCH와 같은 일련의 명령을 통해 트랜잭션 메커니즘을 구현합니다. 트랜잭션은 한 번에 여러 명령 실행을 지원하며 트랜잭션의 모든 명령은 직렬화됩니다. 트랜잭션 실행 프로세스 중에 대기열의 명령은 직렬화되어 순서대로 실행되며 다른 클라이언트가 제출한 명령 요청은 트랜잭션 실행 명령 시퀀스에 삽입되지 않습니다.
간단히 말하면 Redis 트랜잭션은 큐에 있는 일련의 명령을 순차적으로, 일회적으로, 배타적으로 실행하는 것입니다.
Redis 트랜잭션 실행 과정은 다음과 같습니다.트랜잭션 시작(MULTI)
17 Redis 해시 충돌에 대해 어떻게 해야 할까요?- 큐에 넣기 명령
- 트랜잭션 실행(EXEC), 트랜잭션 취소(DISCARD)
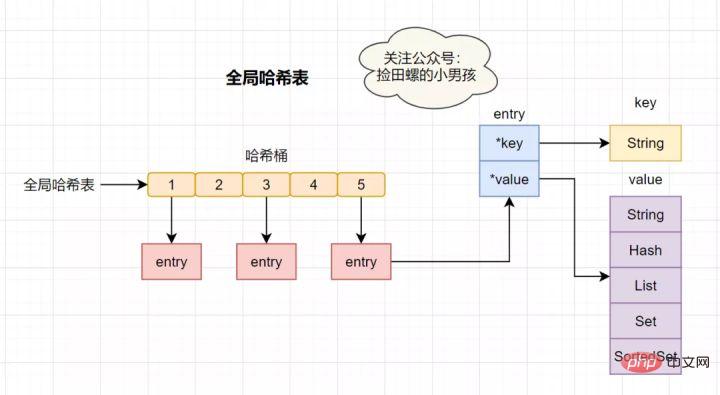
Redis는 전역 해시를 사용하여 모든 키-값 쌍을 저장하는 K-V 인메모리 데이터베이스입니다. 이 해시 테이블은 여러 개의 해시 버킷으로 구성됩니다. 해시 버킷의 항목 요소는
key 및value 포인터를 저장합니다. 여기서 *key는 실제 키를 가리키고 *value는 실제 값을 가리킵니다.
해시 테이블 조회 속도는 매우 빠르며, Java의 HashMap과 다소 비슷합니다. 이를 통해 O(1) 시간 복잡도로 키-값 쌍을 빠르게 찾을 수 있습니다. 먼저 키를 통해 해시 값을 계산하고 해당 해시 버킷 위치를 찾은 다음 항목을 찾고 항목에서 해당 데이터를 찾습니다.
해시 충돌이란 무엇인가요?
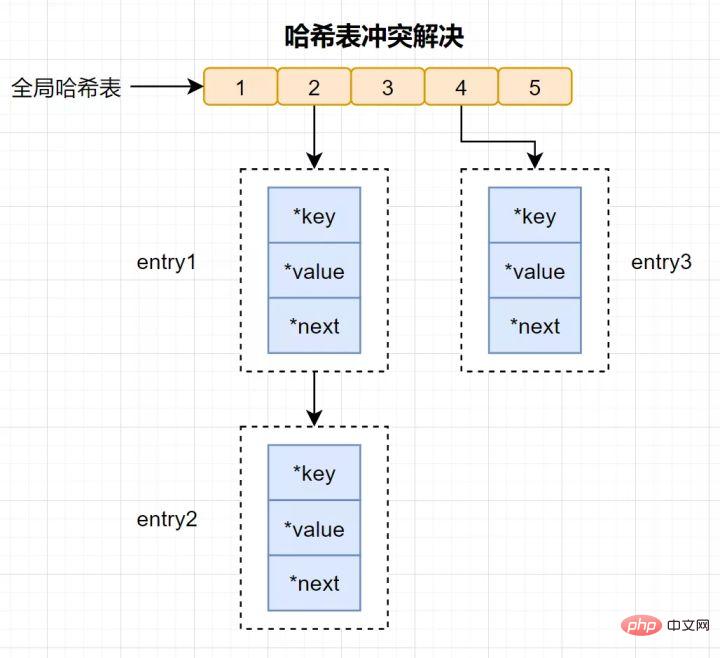
해시 충돌: 동일한 해시 값이 서로 다른 키를 통해 계산되어 동일한 해시 버킷이 생성됩니다.
해시 충돌을 해결하기 위해 Redis는 Chain Hash를 사용합니다. 체인 해싱은 동일한 해시 버킷의 여러 요소가 연결 목록에 저장되고 포인터를 사용하여 차례로 연결되는 것을 의미합니다.
일부 독자에게는 여전히 질문이 있을 수 있습니다. 해시 충돌 체인의 요소는 포인터를 통해 하나씩만 검색한 다음 작동할 수 있습니다. 해시 테이블에 많은 양의 데이터가 삽입되면 충돌이 많아지고 충돌 연결 리스트가 길어져 쿼리 효율성이 떨어지게 됩니다.
효율성을 유지하기 위해 Redis는 해시 테이블에서 rehash 작업을 수행합니다. 이는 해시 버킷을 추가하고 충돌을 줄이는 것을 의미합니다. 재해시를 더욱 효율적으로 만들기 위해 Redis는 기본적으로 두 개의 전역 해시 테이블을 사용합니다. 하나는 현재 사용하는 기본 해시 테이블이고 다른 하나는 확장용인 백업 해시 테이블입니다. 18. RDB 생성 중에 Redis가 쓰기 요청을 동시에 처리할 수 있나요?
예Redis는 RDB를 생성하는 두 가지 지침, 즉 save 및 bgsave를 제공합니다.
저장 명령이라면 메인 스레드에서 실행되기 때문에 차단됩니다.
- bgsave 명령인 경우 RDB 파일을 작성하기 위해 하위 프로세스를 포크합니다. 스냅샷 지속성은 하위 프로세스에 의해 완전히 처리되며 상위 프로세스는 클라이언트 요청을 계속 처리할 수 있습니다.
- 19. Redis 하단에는 어떤 프로토콜이 사용되나요?
RESP, 정식 영어 이름은 Redis Serialization Protocol입니다. 이는 Redis용으로 특별히 설계된 직렬화 프로토콜 집합입니다. 이 프로토콜은 실제로 Redis 버전 1.2에 등장했습니다. 그러나 redis2.0이 되어서야 마침내 redis 통신 프로토콜의 표준이 되었습니다.
RESP는 주로 구현이 간단하고 구문 분석 속도가 빠르며 가독성이 좋다는 장점이 있습니다
.20. Bloom 필터
캐시 침투
문제를 해결하기 위해Bloom 필터를 사용할 수 있습니다. 블룸 필터란 무엇입니까? 블룸 필터는 공간을 거의 차지하지 않는 데이터 구조입니다. 긴 바이너리 벡터와 해시 매핑 함수 집합으로 구성되어 있으며 요소가 집합에 있는지 여부, 공간 효율성 및 쿼리 시간을 검색하는 데 사용됩니다. 단점은 오인식률이 높고 삭제가 어렵다는 점입니다.
블룸 필터의 원리는 무엇인가요?
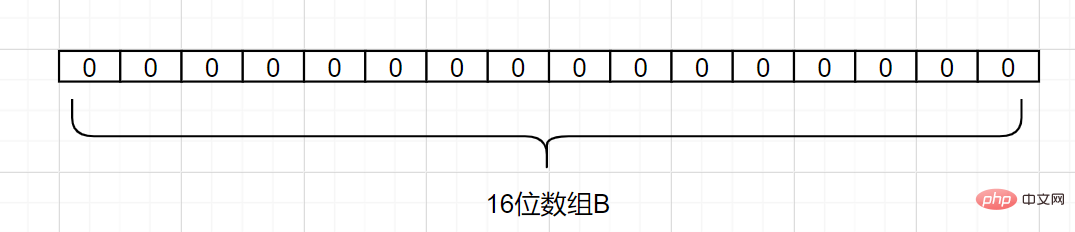
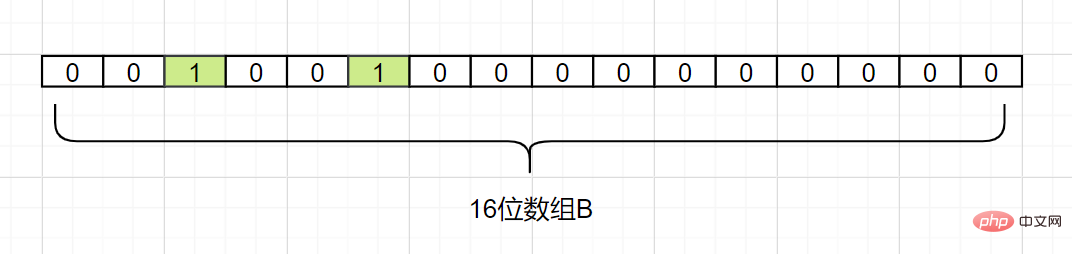
세트 A가 있고 A에 n개의 요소가 있다고 가정합니다.k 해싱 함수를 사용하여 A의 각 요소 는 길이가 비트인 배열 B의 다른 위치에 매핑되고 이 위치의 이진수는 모두 1로 설정됩니다. 검사할 요소가 이러한 k 해시 함수에 의해 매핑되고 k 위치의 이진수 가 모두 1인 것으로 확인되면 이 요소는 집합 A에 속할 가능성이 높습니다. 반대로 는 집합 A에 속해서는 안 됩니다. . 세트 A에 3개의 요소, 즉 {d1, d2, d3
}이 있다고 가정해 보겠습니다. 해시 함수는Hash1 1개입니다. 이제 A의 각 요소를 길이가 16비트인 배열 B에 매핑합니다.
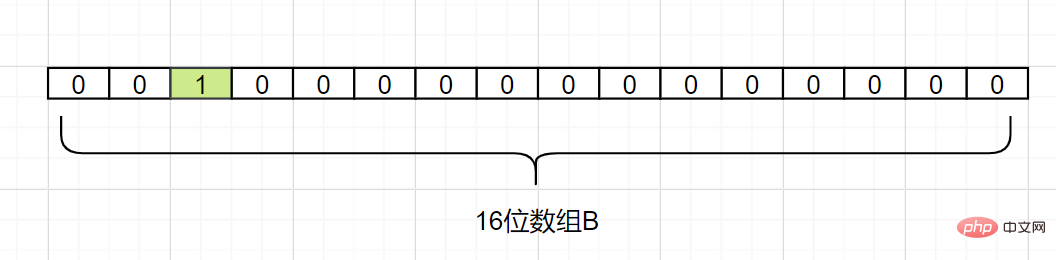
이제 d1을 매핑합니다. Hash1(d1) = 2라고 가정하고 다음과 같이 배열 B의 첨자 2가 있는 그리드를 1로 변경합니다.
이제 Hash1을 가정하여 매핑합니다. (d2) = 5이면 배열 B의 첨자 5가 있는 그리드를 다음과 같이 1로 변경합니다.
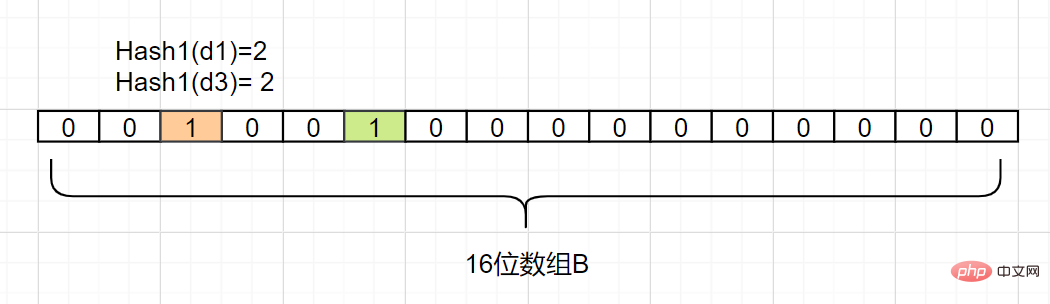
그런 다음 Hash1(d3)도 2와 같다고 가정하고
d3도 매핑합니다. 첨자 2를 1로 사용하는 그리드:
따라서 요소 dn이 세트 A에 있는지 확인하고 싶습니다. Hash1(dn)에서 얻은 인덱스 첨자가 0인 경우에만 계산하면 됩니다. 이는 이 요소
가 집합 A에 속하지 않는다는 의미입니다. 색인 첨자가 1이면 어떻게 될까요? 그러면
A의 요소가 될 수 있습니다. 보시다시피 d1과 d3에서 얻은 아래 첨자 값은 둘 다 1일 수도 있고 다른 숫자로 매핑될 수도 있습니다. Bloom 필터에는 다음과 같은단점이 있습니다. 해시 충돌으로 인해 거짓 긍정이 발생합니다. 판단 오류다. 이 오류를 어떻게 줄이나요?
- 더 많은 해시 함수 매핑을 구축하여 해시 충돌 확률을 줄입니다
- 동시에 B 배열의 비트 길이를 늘리면 해시 함수에서 생성되는 데이터 범위가 늘어나고 해시 충돌 확률도 줄일 수 있습니다
다른 Hash2해시 맵 함수를 추가합니다. Hash2(d1)=6, Hash2(d3)=8이라고 가정하면 다음과 같이 충돌하지 않습니다.
오류가 있어도 찾을 수 있습니다. , Bloom 필터는 전체 데이터를 저장하지 않으며 단지 일련의 해시 맵 함수를 사용하여 위치를 계산한 다음 이진 벡터를 채웁니다. 숫자가 큰인 경우 Bloom 필터는 매우 작은 오류율을 통해 많은 저장 공간을 절약할 수 있어 비용면에서 매우 효율적입니다. 현재 Bloom 필터에는
Google의 Guava 클래스 라이브러리및 Twitter의 Algebird 클래스 라이브러리와 같이 해당 구현을 구현하는 오픈 소스 클래스 라이브러리가 이미 있습니다. 이를 쉽게 얻을 수도 있고 제공되는 비트맵을 기반으로 자신만의 디자인을 구현할 수도 있습니다. 레디스와 함께. 더 많은 프로그래밍 관련 지식을 보려면
프로그래밍 비디오
 🎜🎜List(list)🎜🎜🎜소개: list(list) 유형은 순서가 지정된 여러 문자열을 저장하는 데 사용됩니다. 목록은 최대 2^32-1 요소를 저장할 수 있습니다. 🎜🎜간단하고 실용적인 예:
🎜🎜List(list)🎜🎜🎜소개: list(list) 유형은 순서가 지정된 여러 문자열을 저장하는 데 사용됩니다. 목록은 최대 2^32-1 요소를 저장할 수 있습니다. 🎜🎜간단하고 실용적인 예: 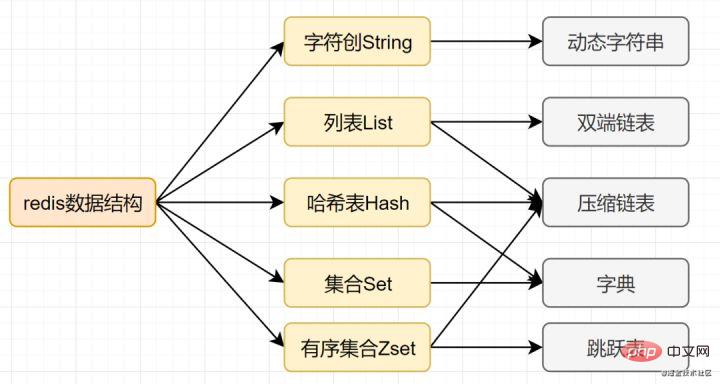

 파일이 클수록 데이터 복구 속도가 느려집니다.
파일이 클수록 데이터 복구 속도가 느려집니다. 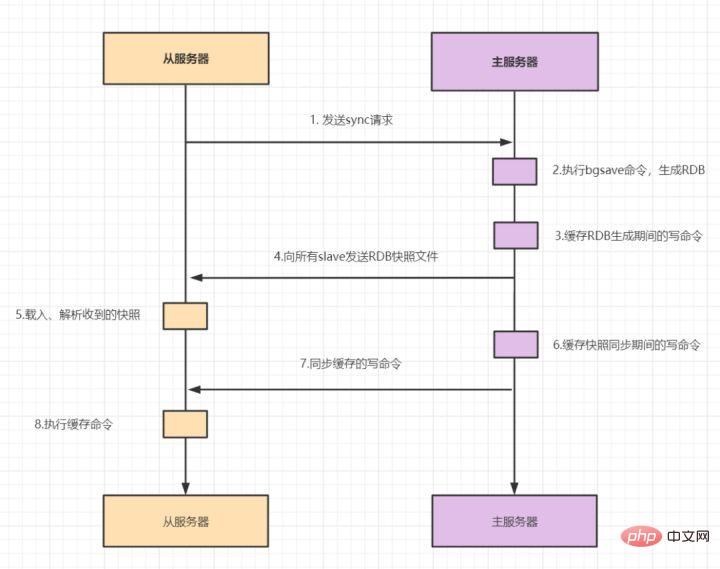

 요소는
요소는 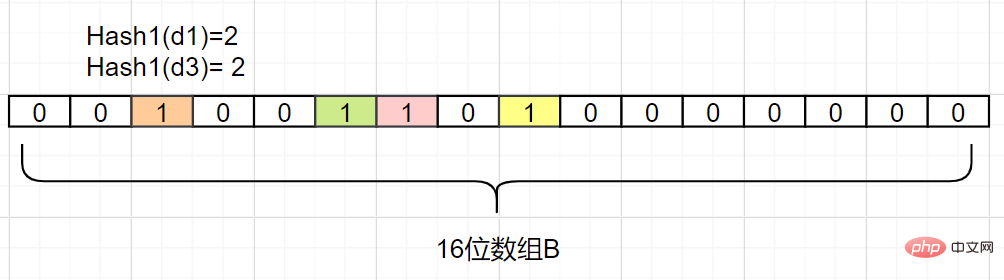
위 내용은 20가지 클래식 Redis 인터뷰 질문 및 답변 요약(공유)의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!