
Redis 고가용성 아키텍처 구축부터 원리 분석까지

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2022-11-24 18:02:272491검색
이 글은 Redis에 대한 관련 지식을 제공하며, 고가용성 아키텍처 구축부터 원리 분석까지 관련 내용을 주로 소개합니다. 모두에게 도움이 되기를 바랍니다.

추천 학습: Redis 비디오 튜토리얼
회사의 최근 시스템 최적화로 인해 얼마 전 큰 테이블을 테이블로 나누었다가 이제 다시 Redis 작업을 하고 있습니다. Redis 관련하여 요구 사항 중 하나는 (회사 특성상) Alibaba Cloud에서 Redis 서비스를 회사 자체 서버로 마이그레이션하는 것입니다. 저는 이번 기회에 Redis의 고가용성 클러스터 아키텍처를 검토했습니다. Redis 클러스터 모드에는 마스터-슬레이브 복제 모드, 센티널 모드, 클러스터 클러스터 모드 등 세 가지가 있습니다. 일반적으로 센티널 클러스터와 클러스터 클러스터가 더 자주 사용됩니다.
지속성 메커니즘
클러스터 아키텍처를 이해하기 전에 먼저 Redis의 지속성 메커니즘을 소개해야 합니다. 지속성은 후속 클러스터에 관련되기 때문입니다. Redis 지속성은 Redis 서비스가 다운될 때 클러스터 아키텍처에서 데이터 복구 또는 마스터-슬레이브 노드 데이터 동기화를 방지하기 위해 일부 규칙에 따라 메모리에 캐시된 데이터를 저장하는 것입니다. Redis 지속성에는 RDB와 AOF의 두 가지 방법이 있습니다. 버전 4.0 이후에는 새로운 하이브리드 지속성 모드가 도입되었습니다.
RDB
RDB는 기본적으로 Redis에서 활성화되는 지속성 메커니즘입니다. 지속성 방법은 스냅샷을 생성하고 사용자 가 구성한 규칙에 따라 디스크에 다운로드하는 것입니다. X 내에서 최소한 Y 개의 변경 사항이 발생했습니다. 초" dump.rdb 바이너리 파일입니다. 기본적으로 Redis는 세 가지 구성으로 구성됩니다. 즉, 900초 이내에 캐시 키 변경이 최소 1회 발생하고, 300초 이내에 캐시 키 변경이 최소 10회 발생하고, 60초 이내에 변경이 10,000회 이상 발생합니다. "X秒内至少发生过Y次改动",生成快照并落盘到dump.rdb二进制文件中。默认情况下,redis配置了三种,分别为900秒内至少发生过1次缓存key的改动,300秒内至少发生过10次缓存key的改动以及60秒内至少发生过10000次改动。

除了redis自动快照持久化数据外,还有两个命令可以帮助我们手动进行内存数据快照,这两个命令分别为save和bgsave。

save:以同步的方式进行数据快照,当缓存数据量大,会阻塞其他命令的执行,效率不高。
bgsave:以异步的方式进行数据快照,有redis主线程fork出一个子进程来进行数据快照,不会阻塞其他命令的执行,效率较高。由于是采用异步快照的方式,那么就有可能发生在快照的过程中,有其他命令对数据进行了修改。为了避免这个问题reids采用了写时复制(Cpoy-On-Write)的方式,因为此时进行快照的进程是由主线程fork出来的,所以享有主线程的资源,当快照过程中发生数据改动时,那么该数据会被复制一份并生成副本数据,子进程会将改副本数据写入到dump.rdb文件中。
RDB快照是以二进制的方式进行存储的,所以在数据恢复时,速度会比较快,但是它存在数据丢失的风险。假如设置的快照规则为60秒内至少发生100次数据改动,那么在50秒时,redis服务由于某种原因突然宕机了,那在这50秒内的所有数据将会丢失。
AOF
AOF是Redis的另一种持久化方式,与RDB不同时是,AOF记录着每一条更改数据的命令并保存到磁盘下的appendonly.aof文件中,当redis服务重启时,会加载该文将并再次执行文件中保存的命令,从而达到数据恢复的效果。默认情况下,AOF是关闭的,可以通过修改conf配置文件来进行开启。
# appendonly no 关闭AOF持久化 appendonly yes # 开启AOF持久化 # The name of the append only file (default: "appendonly.aof") appendfilename "appendonly.aof" # 持久化文件名
AOF提供了三种方式,可以让命令保存到磁盘。默认情况下,AOF采用appendfsync everysec
제외 Redis의 영구 데이터 자동 스냅샷 외에도 메모리 데이터를 수동으로 스냅샷하는 데 도움이 되는 두 가지 명령이 있습니다. 이 두 명령은 save 및 bgsave입니다. 
저장: 동기식으로 데이터 스냅샷을 수행합니다. 캐시된 데이터의 양이 많으면 다른 명령의 실행이 차단되어 비효율적입니다.

- bgsave: 데이터 스냅샷을 비동기 방식으로 수행합니다. Redis 기본 스레드는 데이터 스냅샷을 생성하기 위해 하위 프로세스를 분기합니다. 그리고 더 효율적입니다. 비동기식 스냅샷이 사용되므로 스냅샷 프로세스 중에 다른 명령으로 데이터가 수정될 수 있습니다. 이러한 문제를 피하기 위해 reids에서는 이때 스냅샷을 찍는 프로세스가 메인 스레드에 의해 포크되기 때문에, 쓰기 시 복사(Cpoy-On-Write) 방식을 채택합니다. 스냅샷 프로세스 중에 데이터 변경이 발생하면 데이터가 복사되고 복사본 데이터가 생성되며 하위 프로세스는 수정된 복사본 데이터를 dump.rdb 파일에 씁니다.
appendfsync always #每次有新的改写命令时,都会追加到磁盘的aof文件中。数据安全性最高,但效率最慢。 appendfsync everysec # 每一秒,都会将改写命令追加到磁盘中的aof文件中。如果发生宕机,也只会丢失1秒的数据。 appendfsync no #不会主动进行命令落盘,而是由操作系统决定什么时候写入到磁盘。数据安全性不高。 AOF는 명령을 디스크에 저장하는 세 가지 방법을 제공합니다. 기본적으로 AOF는 명령 지속성을 위해 appendfsync Everysec를 사용합니다. |
AOF를 켠 후 redis 서비스를 다시 시작해야 합니다. 해당 rewrite 명령이 다시 실행되면 작업 명령이 aof 파일에 기록됩니다. | |
|---|---|---|
| RDB에 비해 AOF는 데이터 보안이 높지만 서비스를 계속 실행할수록 AOF의 파일 크기가 점점 커지고 다음에 데이터를 복원할 때 속도가 빨라집니다. 더 느립니다. RDB와 AOF가 모두 활성화되면 redis는 데이터를 복원할 때 AOF에 우선순위를 부여합니다. 결국 AOF는 데이터 손실을 줄입니다. | ||
| RDB | AOF | |
| 복구 효율성 | 높음 | 낮음 |
混合模式
由于RDB持久化方式容易造成数据丢失,AOF持久化方式数据恢复较慢,所以在redis4.0版本后,新出来混合持久化模式。混合持久化将RDB和AOF的优点进行了集成,并而且依赖于AOF,所以在使用混合持久化前,需要开启AOF。在开启混合持久化后,当发生AOF重写时,会将内存中的数据以RDB的数据格式保存到aof文件中,在下一次的重写之前,混合持久化会追加保存每条改写命令到aof文件中。当需要恢复数据时,会加载保存的rdb内容数据,然后再继续同步aof指令。
# AOF重写配置,当aof文件达到60MB并且比上次重写后的体量多100%时自动触发AOF重写 auto-aof-rewrite-percentage 100 auto-aof-rewrite-min-size 64mb aof-use-rdb-preamble yes # 开启混合持久化# aof-use-rdb-preamble no # 关闭混合持久化
AOF重写是指当aof文件越来越大时,redis会自动优化aof文件中无用的命令,从而减少文件体积。比如在处理文章阅读量时,每查看一次文章就会执行一次Incr命令,但是随着阅读量的不断增加,aof文件中的incr命令也会积累的越来越多。在AOF重写后,将会删除这些没用的Incr命令,将这些命令直接替换为set key value命令。除了redis自动重写AOF,如果需要,也可以通过bgrewriteaof命令手动触发。
主从复制
在生产环境中,一般不会直接配置单节点的redis服务,这样压力太大。为了缓解redis服务压力,可以搭建主从复制,做读写分离。redis主从复制,是有一个主节点Master和多个从节点Slave组成。主从节点间的数据同步只能是单向传输的,只能由Master节点传输到Slave节点。
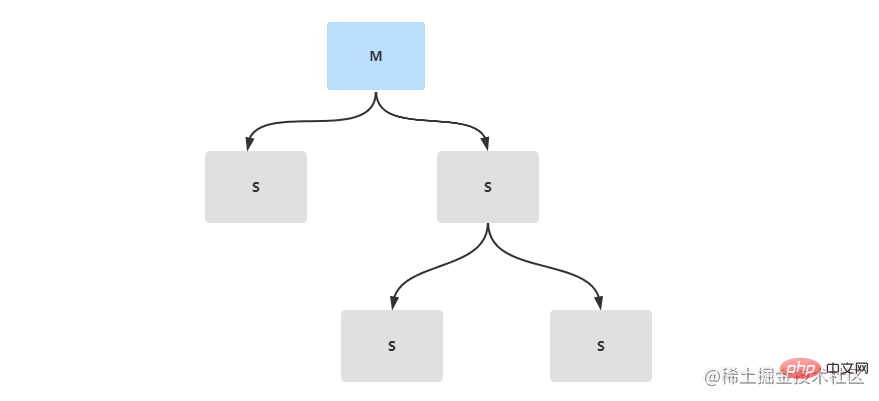
环境配置
准备三台linux服务器,其中一台作为redis的主节点,两台作为reids的从节点。如果没有足够的机器可以在同一台机器上面将redis文件多复制两份并更改端口号,这样可以搭建一个伪集群。
| IP | 主/从节点 | 端口 | 版本 |
|---|---|---|---|
| 192.168.36.128 | 主 | 6379 | 5.0.14 |
| 192.168.36.130 | 从 | 6379 | 5.0.14 |
| 192.168.36.131 | 从 | 6379 | 5.0.14 |
- 配置从节点36.130,36.131机器中reids.conf
修改redis.conf文件中的replicaof,配置主节点的ip和端口号,并且开启从节点只读。


- 启动主节点36.128机器中reids服务
./src/redis-server redis.conf
 3. 依次启动从节点36.130,36.131机器中的redis服务
3. 依次启动从节点36.130,36.131机器中的redis服务
./src/redis-server redis.conf
启动成功后可以看到日志中显示已经与Master节点建立的连接。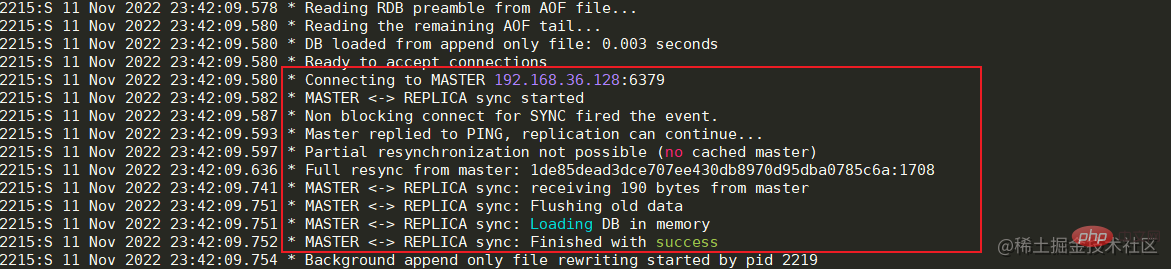 如果出现与Master节点的连接被拒,那么先检查Master节点的服务器是否开启防火墙,如果开启,可以开放6379端口或者关闭防火墙。如果防火墙被关闭但连接仍然被拒,那么可以修改Master节点服务中的redis.conf文件。将bing 127.0.0.1修改为本机对外的网卡ip或者直接注释掉即可,然后重启服务器即可。
如果出现与Master节点的连接被拒,那么先检查Master节点的服务器是否开启防火墙,如果开启,可以开放6379端口或者关闭防火墙。如果防火墙被关闭但连接仍然被拒,那么可以修改Master节点服务中的redis.conf文件。将bing 127.0.0.1修改为本机对外的网卡ip或者直接注释掉即可,然后重启服务器即可。

- 查看状态
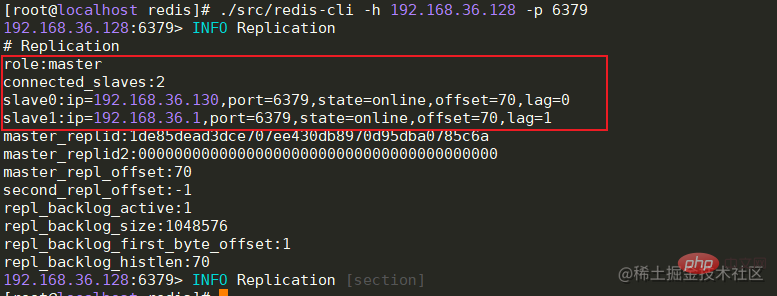
全部节点启动成功后,Master节点可以查看从节点的连接状态,offset偏移量等信息。
info replication # 主节点查看连接信息
数据同步流程
全量数据同步
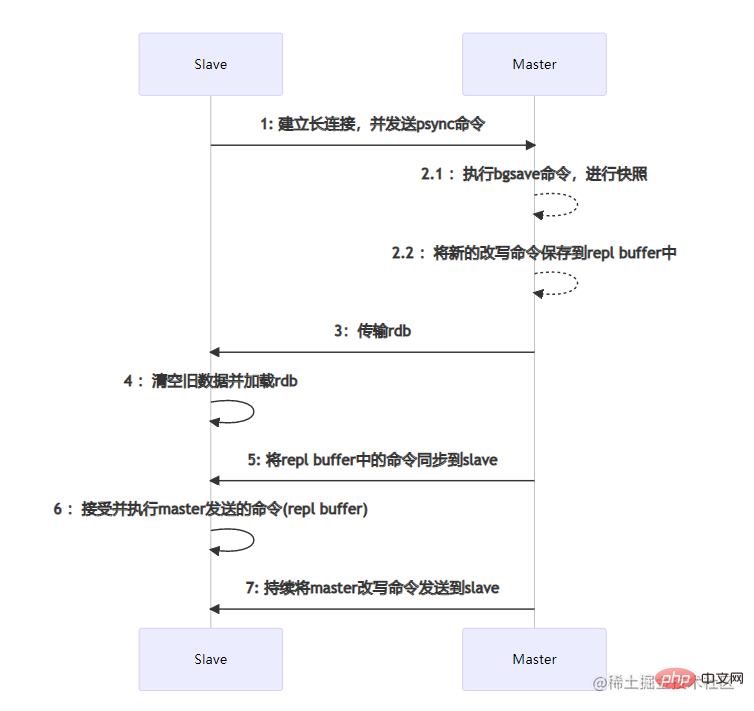 主从节点之间的数据同步是通过建立socket长连接来进行传输的。当Slave节点启动时,会与Master节点建立长连接,并且发送psync同步数据命令。当Master节点收到psync命令时,会执行pgsave进行rdb内存数据快照(这里的rdb快照与conf文件中是否开启rdb无关),如果在快照过程中有新的改写命令,那么Master节点会将这些命令保存到repl buffer缓冲区中。当快照结束后,会将rdb传输给Slave节点。Slave节点在接收到rdb后,如果存在旧数据,那么会将这些旧数据清除并加载rdb。加载完成后会接受master缓存在repl buffer中的新命令。在这些步骤全部执行完成后,主从节点已经算连接成功了,后续Master节点的命令会不断的发送到Slave节点。如果在高并发的情况下,可能会存在数据延迟的情况。
主从节点之间的数据同步是通过建立socket长连接来进行传输的。当Slave节点启动时,会与Master节点建立长连接,并且发送psync同步数据命令。当Master节点收到psync命令时,会执行pgsave进行rdb内存数据快照(这里的rdb快照与conf文件中是否开启rdb无关),如果在快照过程中有新的改写命令,那么Master节点会将这些命令保存到repl buffer缓冲区中。当快照结束后,会将rdb传输给Slave节点。Slave节点在接收到rdb后,如果存在旧数据,那么会将这些旧数据清除并加载rdb。加载完成后会接受master缓存在repl buffer中的新命令。在这些步骤全部执行完成后,主从节点已经算连接成功了,后续Master节点的命令会不断的发送到Slave节点。如果在高并发的情况下,可能会存在数据延迟的情况。部分数据同步
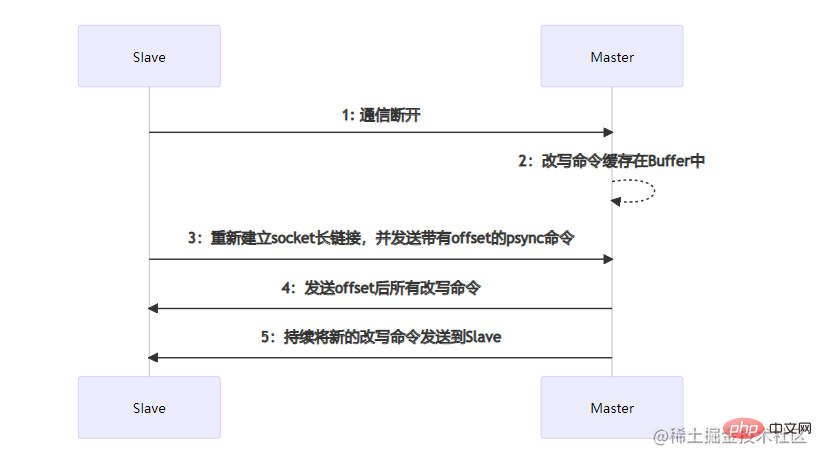
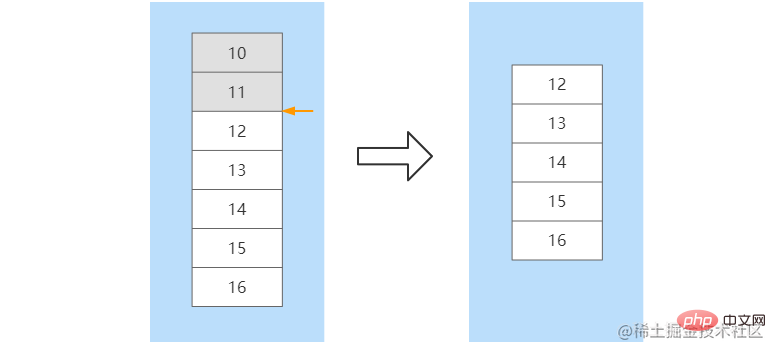
部分数据同步发生在Slave节点发生宕机,并且在短时间内进行了服务恢复。短时间内主从节点之间的数据差额不会太大,如果执行全量数据同步将会比较耗时。部分数据同步时,Slave会向Master节点建立socket长连接并发送带有一个offset偏移量的数据同步请求,这个offset可以理解数据同步的位置。Master节点在收到数据同步请求后,会根据offset结合buffer缓冲区内新的改写命令进行位置确定。如果确定了offset的位置,那么就会将这个位置往后的所有改写命令发送到Slave节点。如果没有确定offset的位置,那么会再次执行全量数据同步。比如,在Slave节点没有宕机之前命令已经同步到了offset=11这个位置,当该节点重启后,向Master节点发送该offset,Master根据offset在缓冲区中进行定位,在定位到11这个位置后,将该位置往后的所有命令发送给Slave。在数据同步完成后,后续Master节点的命令会不断的发送到该Slave节点
优缺点
-
优点
- 可以实现一主多从,读写分离,减轻Master节点读操作压力
- 是哨兵,集群架构的基础
-
缺点
- 자동 마스터-슬레이브 전환 기능이 없습니다. 마스터 노드가 다운되면 수동으로 마스터 노드를 전환해야 합니다.
- 마스터 노드가 다운되면 데이터가 불일치하기 쉽습니다. 동기화되지 않으면 데이터 손실이 발생합니다
Sentinel 모드
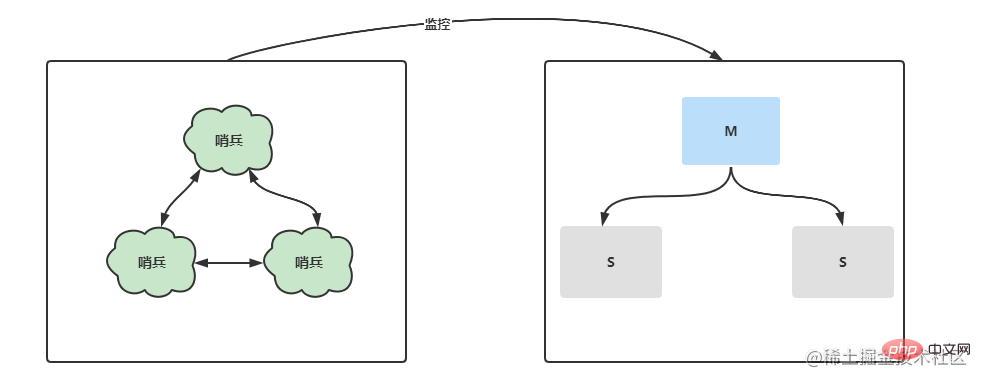
Sentinel 모드는 마스터-슬레이브 복제를 더욱 최적화하고 별도의 센티넬 프로세스를 분리하여 마스터-슬레이브 아키텍처에서 서버 상태를 모니터링합니다. 센티널은 짧은 시간 내에 새로운 마스터를 선출하고 마스터-슬레이브 전환을 수행합니다. 뿐만 아니라 다중 센티널 노드에서는 각 센트리가 서로 모니터링하고 센티널 노드가 다운되었는지 여부를 모니터링합니다.
환경 구성
| IP | 마스터/슬레이브 노드 | Port | Sentinel Port | Version |
|---|---|---|---|---|
| 192.16 8.36.12 8 | 마스터 | 6379 | 26379 | 5.0 .14 |
| 192.168.36.130 | 6379 | 26379 | 5.0.14 | |
| 192.168.36.131 | 에서from | 6379 | 26379 | 5.0.14 |
主从复制是哨兵模式的基础,所以在搭建哨兵前需要完成主从复制的配置。在搭建完主从后,哨兵的搭建就容易很多。
找到安装目录下的sentinel.conf文件并进行修改。主要修改两个地方,分别为哨兵端口port和监控的主节点ip地址和端口号。


在配置完成后,可以使用命令启动各机器的哨兵服务。启动成功后,可查看redis服务和哨兵服务的进行信息。
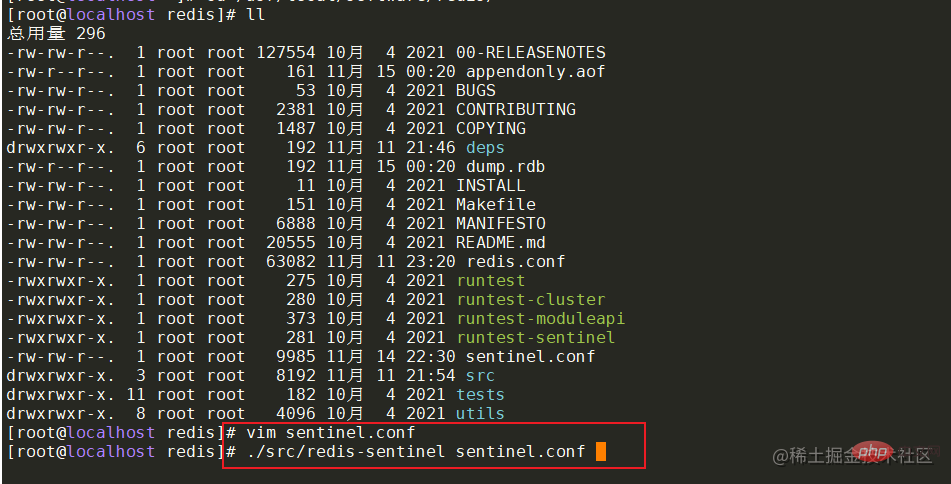
 搭建成功后,就来通过代码演示主节点宕机的情况下,哨兵是否会帮助系统自动进行主备切换。在springboot项目中引入对应的pom,并配置对应的redis哨兵信息。
搭建成功后,就来通过代码演示主节点宕机的情况下,哨兵是否会帮助系统自动进行主备切换。在springboot项目中引入对应的pom,并配置对应的redis哨兵信息。
<dependency> <groupid>org.springframework.boot</groupid> <artifactid>spring-boot-starter-data-redis</artifactid> <version>2.2.2.RELEASE</version></dependency><dependency> <groupid>org.apache.commons</groupid> <artifactid>commons-pool2</artifactid> <version>2.4.2</version></dependency>
server: port: 8081spring: redis: sentinel: master: mymaster # 主服务节点 nodes: 192.168.36.128:26379,192.168.36.130:26379,192.168.36.131:26379 #哨兵节点 timeout: 3000 #连接超时时间
@Slf4j
@RestController
public class RedisTest {
@Resource
private StringRedisTemplate stringRedisTemplate;
/*
* 每秒钟向redis中写入数据,中途kill掉主节点进程,模拟宕机
*/
@GetMapping("/redis/testSet")
public void test(@RequestParam(name = "key") String key,
@RequestParam(name = "value") String value) throws InterruptedException {
int idx=0;
for(;;){
try {
idx++;
stringRedisTemplate.opsForValue().set(key+idx, value);
log.info("=====存储成功:{},{}=====",key+idx,value);
}catch (Exception e){
log.error("====连接redis服务器失败:{}====",e.getMessage());
}
Thread.sleep(1000);
}
}
}
当启动服务后,通过节后向后端传递数据,可以看到输出的日志,表示redis哨兵集群已经可以正常运行了。那么这个时候kill掉36.128机器上的主节点,模拟服务宕机。通过日志可以知道,服务出现异常了,在过十几秒发现哨兵已经自动帮系统进行了主从切换,并且服务也可以正常访问了。
2022-11-14 22:20:23.134 INFO 8764 --- [nio-8081-exec-2] com.gz.redis.RedisTest : =====存储成功:test14,123===== 2022-11-14 22:20:24.142 INFO 8764 --- [nio-8081-exec-2] com.gz.redis.RedisTest : =====存储成功:test15,123===== 2022-11-14 22:20:24.844 INFO 8764 --- [xecutorLoop-1-1] i.l.core.protocol.ConnectionWatchdog : Reconnecting, last destination was /192.168.36.128:6379 2022-11-14 22:20:26.909 WARN 8764 --- [ioEventLoop-4-4] i.l.core.protocol.ConnectionWatchdog : Cannot reconnect to [192.168.36.128:6379]: Connection refused: no further information: /192.168.36.128:6379 2022-11-14 22:20:28.165 ERROR 8764 --- [nio-8081-exec-2] com.gz.redis.RedisTest : ====连接redis服务器失败:Redis command timed out; nested exception is io.lettuce.core.RedisCommandTimeoutException: Command timed out after 3 second(s)==== 2022-11-14 22:20:31.199 INFO 8764 --- [xecutorLoop-1-1] i.l.core.protocol.ConnectionWatchdog : Reconnecting, last destination was 192.168.36.128:6379
2022-11-14 22:20:52.189 ERROR 8764 --- [nio-8081-exec-2] com.gz.redis.RedisTest : ====连接redis服务器失败:Redis command timed out; nested exception is io.lettuce.core.RedisCommandTimeoutException: Command timed out after 3 second(s)==== 2022-11-14 22:20:53.819 WARN 8764 --- [ioEventLoop-4-2] i.l.core.protocol.ConnectionWatchdog : Cannot reconnect to [192.168.36.128:6379]: Connection refused: no further information: /192.168.36.128:6379 2022-11-14 22:20:56.194 ERROR 8764 --- [nio-8081-exec-2] com.gz.redis.RedisTest : ====连接redis服务器失败:Redis command timed out; nested exception is io.lettuce.core.RedisCommandTimeoutException: Command timed out after 3 second(s)==== 2022-11-14 22:20:57.999 INFO 8764 --- [xecutorLoop-1-2] i.l.core.protocol.ConnectionWatchdog : Reconnecting, last destination was 192.168.36.128:6379 2022-11-14 22:20:58.032 INFO 8764 --- [ioEventLoop-4-4] i.l.core.protocol.ReconnectionHandler : Reconnected to 192.168.36.131:6379 2022-11-14 22:20:58.040 INFO 8764 --- [nio-8081-exec-2] com.gz.redis.RedisTest : =====存储成功:test24,123===== 2022-11-14 22:20:59.051 INFO 8764 --- [nio-8081-exec-2] com.gz.redis.RedisTest : =====存储成功:test25,123===== 2022-11-14 22:21:00.057 INFO 8764 --- [nio-8081-exec-2] com.gz.redis.RedisTest : =====存储成功:test26,123===== 2022-11-14 22:21:01.065 INFO 8764 --- [nio-8081-exec-2] com.gz.redis.RedisTest : =====存储成功:test27,123=====
故障转移
在多个哨兵的模式下,每个哨兵都会向redis节点发送心跳包来检测节点的运行状态。如果某个哨兵发现主节点连接超时了,没有收到心跳,那么系统并不会立刻进行故障转移,这种情况叫做主观下线。如果后续的哨兵节点发现,与主节点的心跳也失败了并且哨兵数量超过2个,那么这个时候就会认为主节点客观下线,并且会进行故障转移,这个客观下线的数值可以在哨兵的配置文件中进行配置。
sentinel monitor master 192.168.36.128 6378 2
在故障转移前,需要选举出一个哨兵leader来进行Master节点的重新选举。哨兵的选举过程大致可以分为三步:
当某个的哨兵确定主节点已经下线时,会像其他哨兵发送is-master-down-by-addr命令,要求将自己设为leader,并处理故障转移工作。
其他哨兵在收到命令后,进行投票选举
如果票数过半时,那么发送命令的哨兵节点将成为主节点,并进行故障转移。
当选举出主哨兵后,那么这个主哨兵就会过滤掉宕机的redis节点,重新选举出Master节点。首先会根据redis节点的优先级进行选举(slave-priority),数值越大的从节点将会被选举为主节点。如果这个优先级相同,那么主哨兵节点就会选择数据最全的从节点作为新的主节点。如果还是选举失败,那么就会选举出进程id最小的从节点作为主节点。
脑裂
在集群环境下会由于网络等原因出现脑裂的情况,所谓的脑裂就是由于主节点和从节点和哨兵处于不同的网络分区,由于网络波动等原因,使得哨兵没有能够即使接收到主节点的心跳,所以通过选举的方式选举了一个从节点为新的主节点,这样就存在了两个主节点,就像一个人有两个大脑一样,这样会导致客户端还在像老的主节点那里写入数据,新节点无法同步数据,当网络恢复后,哨兵会将老的主节点降为从节点,这时再从新主节点同步数据,这会导致大量数据丢失。如果需要避免脑裂的问题,可以配置下面两行信息。
min-replicas-to-write 3 # 最少从节点为3 min-replicas-max-lag 10 # 表示数据复制和同步的延迟不能超过10秒
优缺点
优点:除了拥有主从复制的优点外,还可以进行故障转移,主从切换,系统更加可靠。
缺点:故障转移需要花费一定的时间,在高并发场景下容易出现数据丢失。不容易实现在线扩容。
클러스터 모드
센티넬 모드에서는 마스터 노드가 다운된 상태에서도 마스터-슬레이브 전환이 가능하지만, 전환 과정에 10초 이상이 소요되어 일부 데이터가 손실될 수 있습니다. 동시성이 높지 않으면 이 클러스터 모드를 사용할 수 있지만 동시성이 높을 경우 이 10초가 심각한 결과를 초래할 수 있으므로 많은 인터넷 회사에서는 클러스터 클러스터 아키텍처를 사용합니다. 클러스터 클러스터는 여러 개의 Redis 노드로 구성됩니다. 각 Redis 서비스 노드에는 마스터 노드와 여러 개의 슬레이브 노드가 있습니다. 데이터를 저장할 때 Redis는 데이터 키에 대해 해시 작업을 수행하고 작업 결과에 따라 이를 다른 슬롯에 할당합니다. . 조금. 일반적인 상황에서 클러스터 클러스터 아키텍처에는 6개의 노드(마스터 3개와 슬레이브 3개)가 필요합니다.
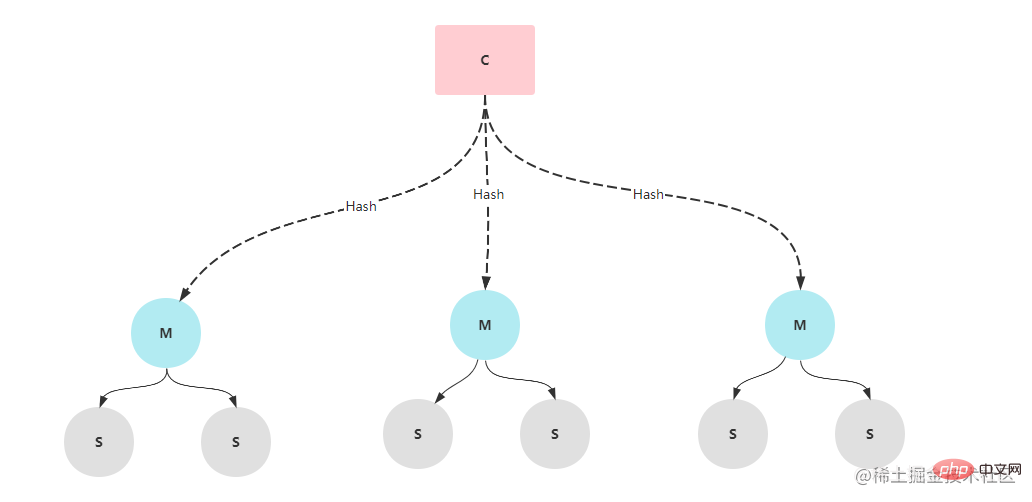
환경 설정
가상 머신이 3개뿐이므로 각 서버에 각각 포트 6379와 6380을 사용하여 2개의 Redis 서비스를 구축해야 합니다. 이렇게 하면 노드 6개를 구축할 수 있습니다.
| IP | 마스터/슬레이브 노드 | Port | Version |
|---|---|---|---|
| 192.168.36.128 | - | 6379 | 5.0 .14 |
| 192.168.36.128 | - | 6380 | 5.0.14 |
| 192.168.36.130 | - | 6379 | 5.0.14 |
| 192.168.36.130 | - | 6380 | 5.0.14 |
| 192.168.36.131 | - | 6379 | 5.0.14 |
| 192.168.36.131 | - | 6380 | 5.0.14 |
为了看起来不是那么混乱,可以为cluster新建一个文件夹,并将redis的文件拷贝到cluster文件夹中,并修改文件夹名为redis-6379,reids-6380。
新建完成后,修改每个节点的redis.conf配置文件,找到cluster相关的配置位置,将cluster-enable更改为yes,表示开启集群模式。开启后,需要修改集群节点连接的超时时间cluster-node-timeout,节点配置文件名cluster-config-file等等,需要注意的是,同一台机器上面的服务节点记得更改端口号。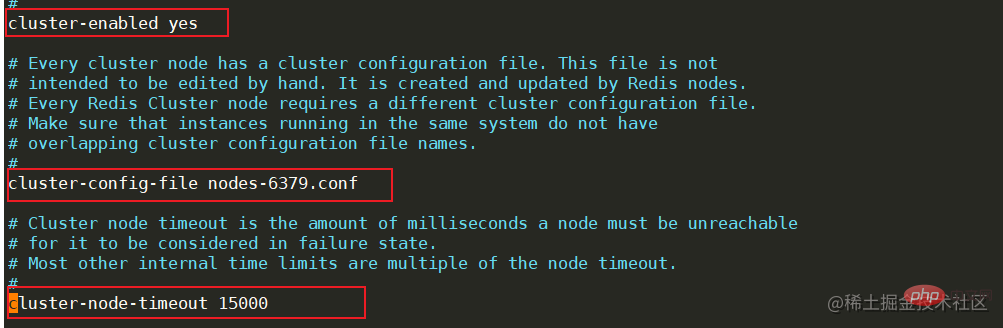



在每个节点都配置完成后,可以依次启动各节点。启动成功后,可以查看redis的进程信息,后面有明显的标识为[cluster]。

现在虽然每个节点的redis都已经正常启动了,但是每个节点之间并没有任何联系啊。所以这个时候还需要最后一步,将各节点建立关系。在任意一台机器上运行下面的命令-- cluster create ip:port,进行集群创建。命令执行成功后,可以看到槽位的分布情况和主从关系。
./src/redis-cli --cluster create 192.168.36.128:6379 192.168.36.128:6380 192.168.36.130:6379 192.168.36.130:6380 192.168.36.131:6379 192.168.36.131:6380 --cluster-replicas 1复制代码
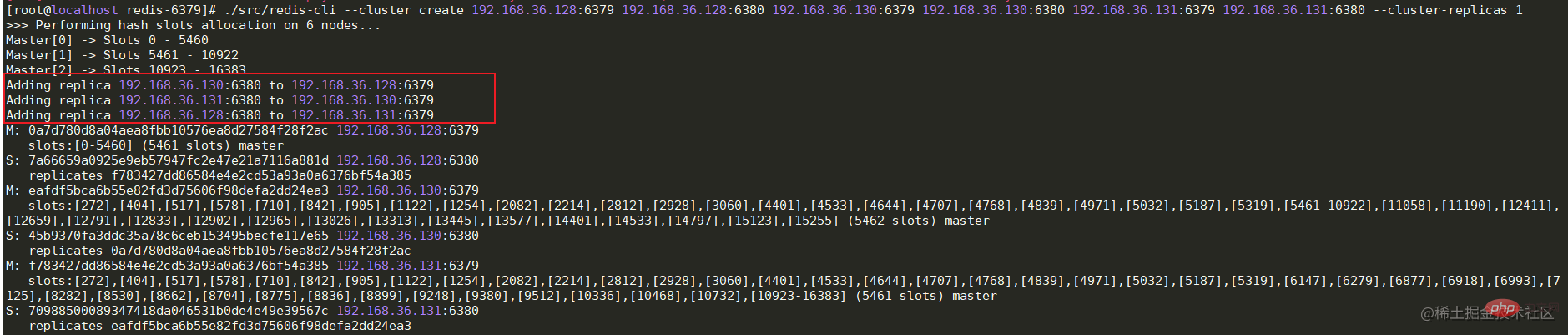
cluster成功启动后,可以在代码中简单的测试一下,这里的代码依旧采用哨兵模式中的测试代码,只是将sentinel相关的信息注释掉并加上cluster的节点信息即可。
spring: redis: cluster: nodes: 192.168.36.128:6379,192.168.36.128:6380,192.168.36.130:6379,192.168.36.130:6380,192.168.36.131:6379,192.168.36.131:6380# sentinel:# master: mymaster# nodes: 192.168.36.128:26379,192.168.36.130:26379,192.168.36.131:26379 timeout: 3000 lettuce: pool: max-active: 80 min-idle: 50
数据分片
Cluster模式下由于存在多个Master节点,所以在存储数据时,需要确定将这个数据存储到哪台机器上。上面在启动集群成功后可以看到每台Master节点都有自己的一个槽位(Slots)范围,Master[0]的槽位范围是0 - 5460,Master[1]的槽位范围是5461 - 10922,Master[2]的槽位范围是10922 - 16383。redis在存储前会通过CRC16方法计算出key的hash值,并与16383进行位运算来确定最终的槽位值。所以,可以知道确定槽位的方式就是 CRC16(key) & 16383。计算出槽位后,此时在java服务端并不知道这个槽位对应到哪一台redis服务,其实在java服务端启动服务时会将redis的相关槽位和映射的ip信息进行一个本地缓存,所以知道槽位后,就会知道对应槽位的ip。
选举机制
cluster模式中的选举与哨兵中的不同。当某个从节点发现自己的主节点状态变为fail状态时,便尝试进行故障转移。由于挂掉的主节点可能会有多个从节点,从而存在多个从节点竞争成为新主节点 。其选举过程大概如下:
从节点将自己记录的集群currentEpoch加1,并广播FAILOVER_AUTH_REQUEST信息,通知集群中的所有节点,需要进行重新选举了。
其他节点收到该信息,但只有master节点会进行响应,判断请求者的合法性,并发送 FAILOVER_AUTH_ACK,对每一个epoch只发送一次ack。
发送通知的从节点会收集各master主节点返回的FAILOVER_AUTH_ACK。
如果该从节点收到的ack数过半,那么该节点就会被选举为新的Master主节点。成为主节点后,广播通知其他小集群节点
优缺点
优点:
有多个主节点,做到去中心化。
数据可以槽位进行分布存储
扩展性更高,可用性更高。cluster集群中的节点可以在线添加或删除,官方推荐节点数不超1000。当部分Master节点不可用时,整个集群任然可以正常工作。
缺点:
数据通过异步复制,不保证数据的强一致性
Slave节点在集群中充当冷备,不能缓解读压力
요약
reids는 오늘날 매우 인기 있는 미들웨어입니다. 캐시로 사용하여 DB에 대한 부담을 줄이고 시스템 성능을 향상시킬 수 있습니다. 동시성 보안을 보장하기 위해 분산 잠금으로 사용할 수도 있습니다. 또한 시스템의 결합을 줄이기 위해 MQ 메시지 대기열로 사용할 수도 있습니다. 독립형 모드, 마스터-슬레이브 복제, 센트리 및 클러스터 모드를 지원합니다. 각 모드에는 고유한 장점과 단점이 있습니다. 실제 프로젝트에서는 비즈니스 요구 사항과 동시성 정도에 따라 선택할 수 있습니다.
추천 학습: Redis 비디오 튜토리얼
위 내용은 Redis 고가용성 아키텍처 구축부터 원리 분석까지의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!