
Node에서의 비동기 구현과 이벤트 구동에 대해 이야기해 보겠습니다.

- 青灯夜游앞으로
- 2022-11-08 20:14:441381검색
이 글은 Node의 비동기 구현과 이벤트 구동에 대해 설명합니다. 모든 사람에게 도움이 되기를 바랍니다.

Node의 기능
컴퓨터의 일부 작업은 일반적으로 두 가지 범주로 나눌 수 있습니다. 하나는 IO 집약적 작업이고 다른 하나는 컴퓨팅 집약적 작업입니다. 짜내려면 CPU 성능에 영향을 주지만 IO 집약적인 작업의 경우 이상적으로는 IO 장치에 처리를 알리고 잠시 후에 데이터를 가져오면 됩니다. [권장 관련 튜토리얼: nodejs 비디오 튜토리얼, 프로그래밍 비디오]
일부 시나리오의 경우 완료해야 하는 관련 없는 작업이 몇 가지 있습니다. 현재 주류 방법은 다음과 같습니다.
- 멀티 스레드 병렬 완성. : 멀티스레딩의 비용은 스레드를 생성하고 스레드 컨텍스트 전환을 수행하는 데 드는 오버헤드가 더 크다는 것입니다. 또한 복잡한 비즈니스에서 멀티 스레드 프로그래밍은 종종 잠금 및 상태 동기화와 같은 문제에 직면합니다.
- 단일 스레드 순차 실행: 표현하기 쉽지만 직렬 실행의 단점은 약간 느린 작업으로 인해 후속 코드가 발생한다는 것입니다. 그룹
node는 두 가지 이전에 솔루션을 제공했습니다. 단일 스레드를 사용하여 다중 스레드 교착 상태, 상태 동기화 및 기타 문제를 방지하고 비동기 IO를 사용하여 단일 스레드를 차단하지 않도록 하고, CPU를 더 잘 사용하려면node在两者之前给出了它的方案:利用单线程,远离多线程死锁、状态同步等问题;利用异步IO,让单线程远离阻塞,以更好地使用CPU
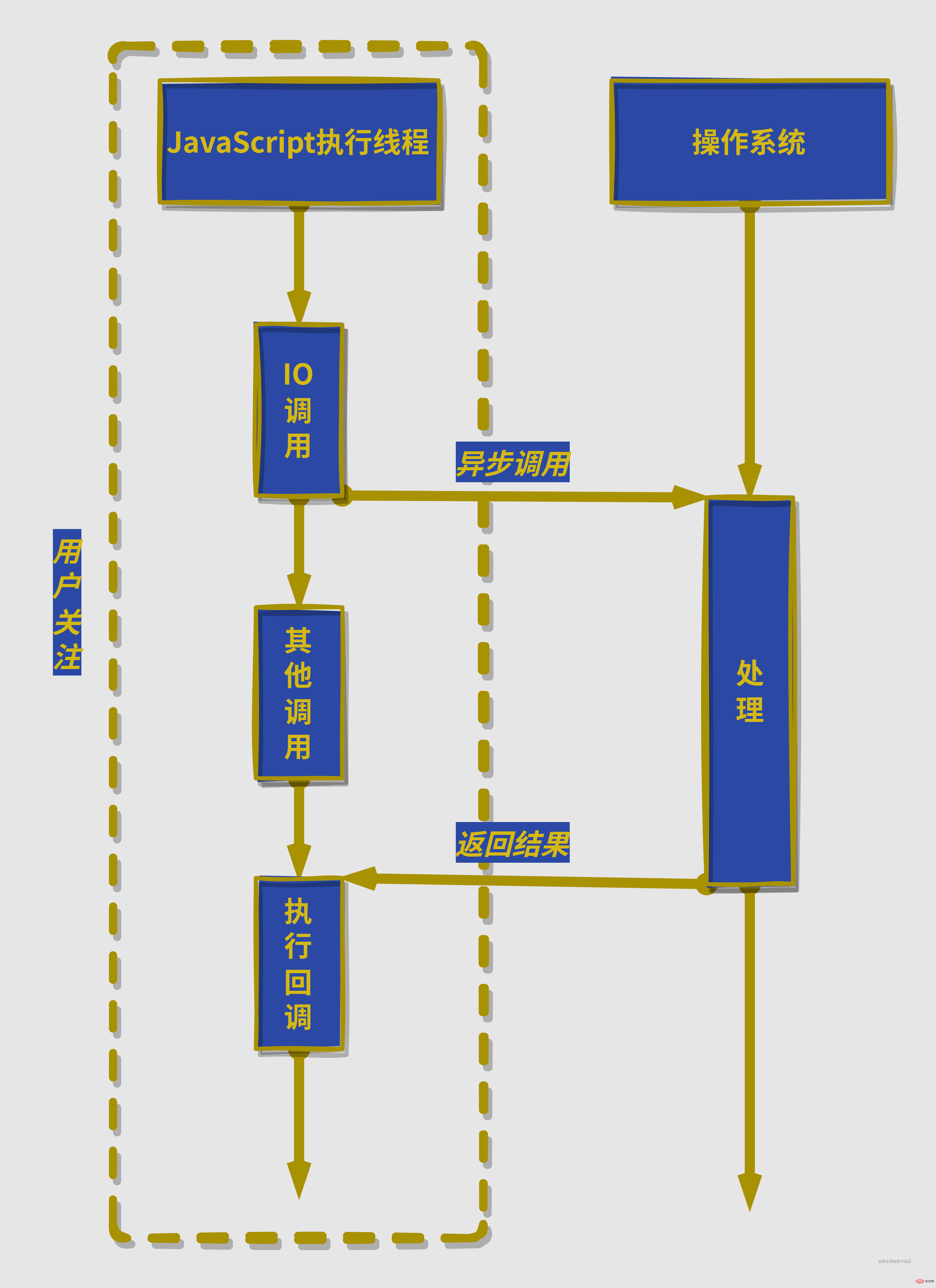
Node是如何实现异步的
刚才讲了
node在多任务处理的方案,但是node内部想要实现却并不容易,下面介绍操作系统的几个概念,方面后续大家更好理解,后面再讲一讲异步的实现以及node的事件循环机制:
阻塞IO与非阻塞IO
- 阻塞IO:应用层面发起IO调用之后,就一直等待数据,等操作系统内核层面完成所有操作后,调用才结束;
操作系统中一切皆文件,输入输出设备同样被抽象为了文件,内核在执行IO操作时,通过文件描述符进行管理
- 非阻塞IO:差别为调用后立即返回一个文件描述符,并不等待,这时候CPU的时间片就可以用来处理其他事务,之后可以通过这个文件描述符进行结果的获取;
非阻塞IO存在的一些问题:虽然其让CPU的利用率提高了,但是由于立即返回的是一个文件描述符,我们并不知道IO操作什么时候完成,为了确认状态变更,我们只能作轮询操作
不同的轮询方法
-
read:最原始、性能最低的一种,通过重复检查IO状态来完成完整数据的获取 -
select:通过对文件描述符上的事件状态来进行判断,相对来说消耗更少;缺点就是它采用了一个1024长度的数组来存储状态,所以它最多可以同时检查1024个文件描述符 -
poll:由于select的限制,poll改进为链表的存储方式,其他的基本都一致;但是当文件描述符较多的时候,它的性能还是非常低下的 -
eopll:该方案是linux下效率最高的IO事件通知机制,在进入轮询的时候如果没有检查IO事件,将会进行休眠,直到事件发生将它唤醒 -
kqueue:与epoll类似,不过仅在FreeBSD系统下存在
尽管epoll利用了事件来降低对CPU的耗用,但休眠期间CPU几乎是闲置的;我们期待的异步IO应该是应用程序发起非阻塞调用,无须通过遍历或事件唤醒等方式轮询,可以直接处理下一个任务,只需IO完成后通过信号或者回调将数据传递给应用程序即可。
linux下还有中AIO方式就是通过信号或回调来传递数据的,不过只有Linux有,并且有限制无法利用系统缓存
node中对于异步IO的实现
先说结论,node对异步IO的实现是通过多线程实现的。可能会混淆的地方就是node内部虽然是多线程的,但是我们程序员开发的JavaScript
🎜 🎜Node가 비동기성을 구현하는 방법🎜🎜🎜🎜방금 node의 멀티 태스킹 솔루션에 대해 이야기했는데 node 내부적으로 구현하는 것은 쉽지 않습니다. 여기서는 나중에 더 잘 이해할 수 있도록 운영 체제의 몇 가지 개념을 소개합니다. 나중에 비동기 구현 구현과 노드의 이벤트 루프 메커니즘에 대해 이야기하겠습니다. 🎜🎜 🎜블로킹 IO 및 비블로킹 IO🎜
🎜🎜블로킹 IO: 애플리케이션 계층이 IO 호출을 시작한 후 운영 체제 커널 계층이 완료될 때까지 데이터를 기다립니다. 🎜🎜🎜 🎜운영체제의 모든 것은 파일이며, 커널이 IO 작업을 수행할 때 🎜파일 설명자🎜🎜🎜🎜🎜를 통해 관리됩니다. 비차단 IO: 차이점은 파일 설명자가 호출 직후 기다리지 않고 반환된다는 것입니다. 이때 CPU 타임 슬라이스를 사용하여 다른 트랜잭션을 처리할 수 있으며 결과는 이 파일 설명자를 통해 얻을 수 있습니다. 🎜🎜 비차단 IO의 몇 가지 문제: CPU 활용도는 향상되지만 파일 설명자가 즉시 반환되므로 IO 작업이 완료될 때 상태 변경을 확인하기 위해 알 수 없습니다. 폴링 작업만 수행합니다 🎜🎜 다름 폴링 방법 🎜
🎜🎜read: 가장 원시적이고 성능이 가장 낮은 방법으로 획득을 완료합니다. 🎜반복적으로 IO 상태를 확인🎜🎜🎜select하여 완전한 데이터 확보: 판단은 🎜파일 설명자에서 이벤트 상태를 판단하여 🎜 이루어지며, 이는 상대적으로 비용이 적게 듭니다. 1024 길이의 배열로 상태를 저장하므로 동시에 최대 1024개의 파일 설명자를 확인할 수 있습니다. 🎜🎜poll: select의 제한으로 인해 poll은 연결리스트 저장 방식으로 개선되었으며 나머지는 기본적으로 동일하지만 파일 설명자가 대부분의 경우 성능이 매우 낮습니다🎜🎜eopll code>: 이 솔루션은 <code>linux에서 가장 효율적인 IO 이벤트 알림 메커니즘입니다. IO 이벤트가 없는 경우 이벤트가 발생하여 깨울 때까지 절전 모드로 유지됩니다🎜🎜kqueue: <code>epoll과 비슷하지만 FreeBSD 시스템에만 존재합니다🎜🎜🎜epoll는 CPU 소비를 줄이기 위해 이벤트를 사용하지만 절전 모드에서는 CPU가 거의 유휴 상태입니다. 우리가 예상하는 비동기 IO는 순회 또는 이벤트 깨우기를 통해 폴링할 필요 없이 애플리케이션에 의해 시작되는 비차단 호출이어야 하며, 신호나 콜백을 통해 애플리케이션에 데이터를 전달하기만 하면 다음 작업을 직접 처리할 수 있습니다. IO가 완료된 후. 🎜🎜🎜리눅스에도 시그널이나 콜백을 통해 데이터를 전송하는 AIO 방식이 있는데, 이는 리눅스에서만 사용할 수 있고 시스템 캐시를 사용할 수 없다는 제약이 있습니다🎜🎜🎜비동기 IO 구현을 위한 노드 🎜
🎜 먼저 결론부터 말씀드리겠습니다. node는 멀티 스레딩을 통해 비동기 IO를 구현합니다. 혼란스러울 수 있는 점은 node가 내부적으로 다중 스레드로 구성되어 있지만 프로그래머가 개발한 JavaScript 코드는 단일 스레드에서만 실행된다는 것입니다. 🎜
노드는 일부 스레드를 사용하여 차단 IO 또는 비차단 IO 및 폴링 기술을 수행하여 데이터 수집을 완료하고, 하나의 스레드가 계산 처리를 수행할 수 있도록 하며, 스레드 간 통신을 통해 IO에서 얻은 데이터를 전송할 수 있습니다. 비동기 IO 시뮬레이션을 쉽게 구현합니다. node通过部分线程进行阻塞IO或者非阻塞IO加上轮询技术来完成数据获取,让一个线程进行计算处理,通过线程之间的通信将IO得到的数据进行传递,这就轻松实现了异步IO的模拟。
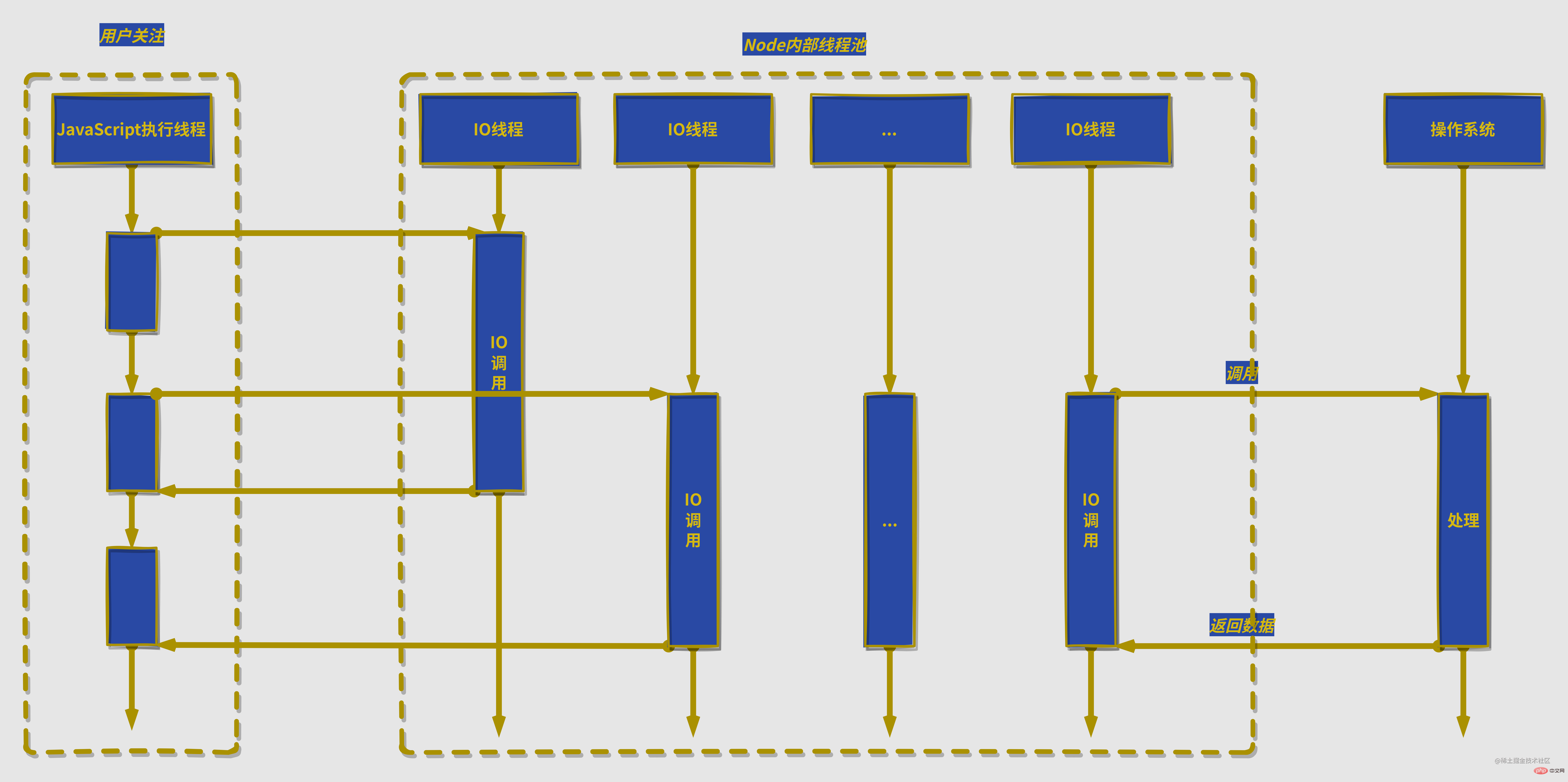
除了异步IO,计算机中的其他资源也适用,因为linux中一切皆文件,磁盘、硬件、套接字等几乎所有计算机资源都被抽象为了文件,接下来介绍对计算机资源的调用都以IO为例子。
事件循环
在进程启动时,node便会创建一个类似与while(true)的循环,每执行一次循环体的过程我们成为Tick;
下方为node中事件循环流程图:
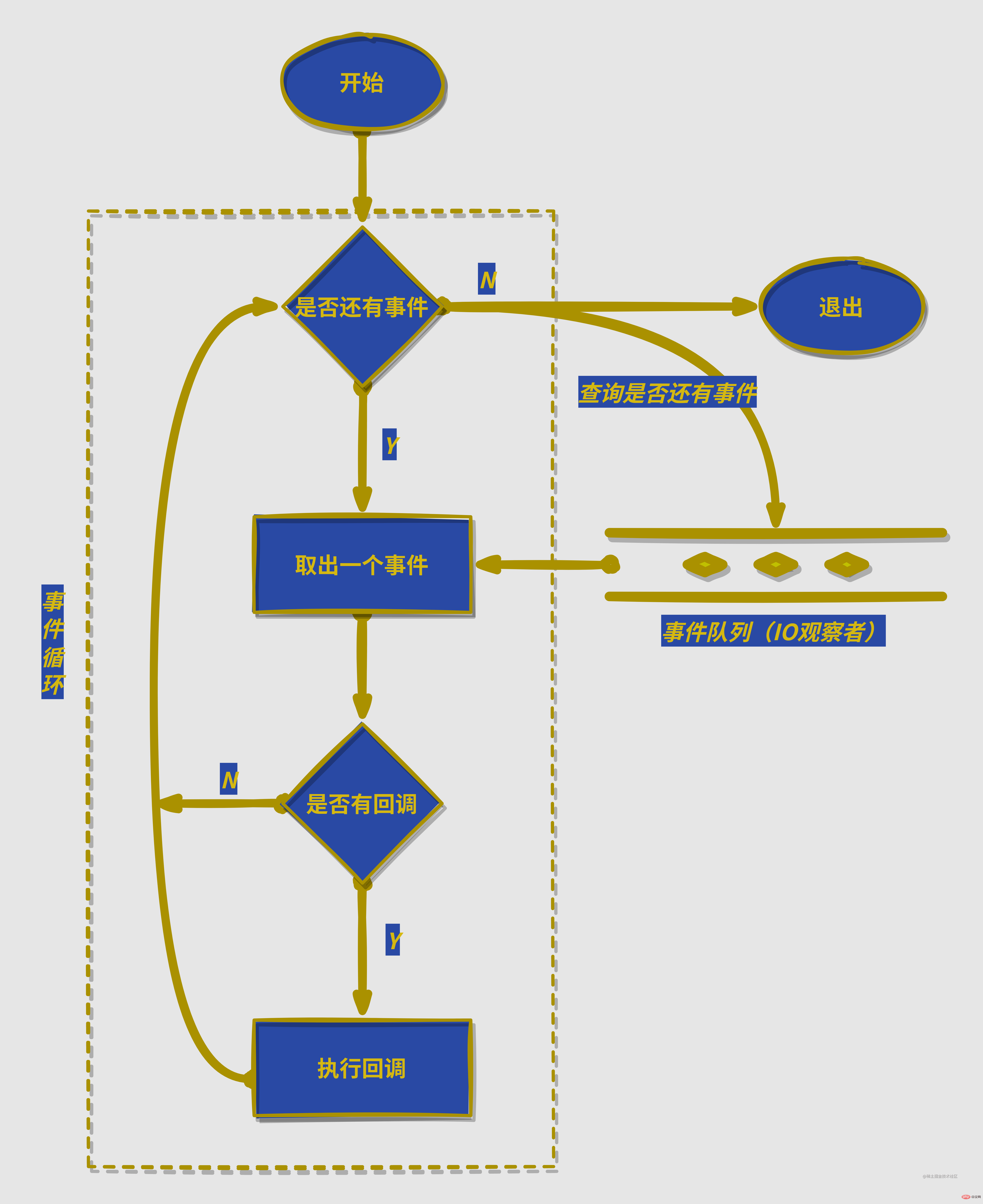
很简单的一张图,简单解释一下:就是每次都从IO观察者里面获取执行完成的事件(是个请求对象,简单理解就是包含了请求中产生的一些数据),然后没有回调函数的话就继续取出下一个事件(请求对象),有回调就执行回调函数
异步IO细节
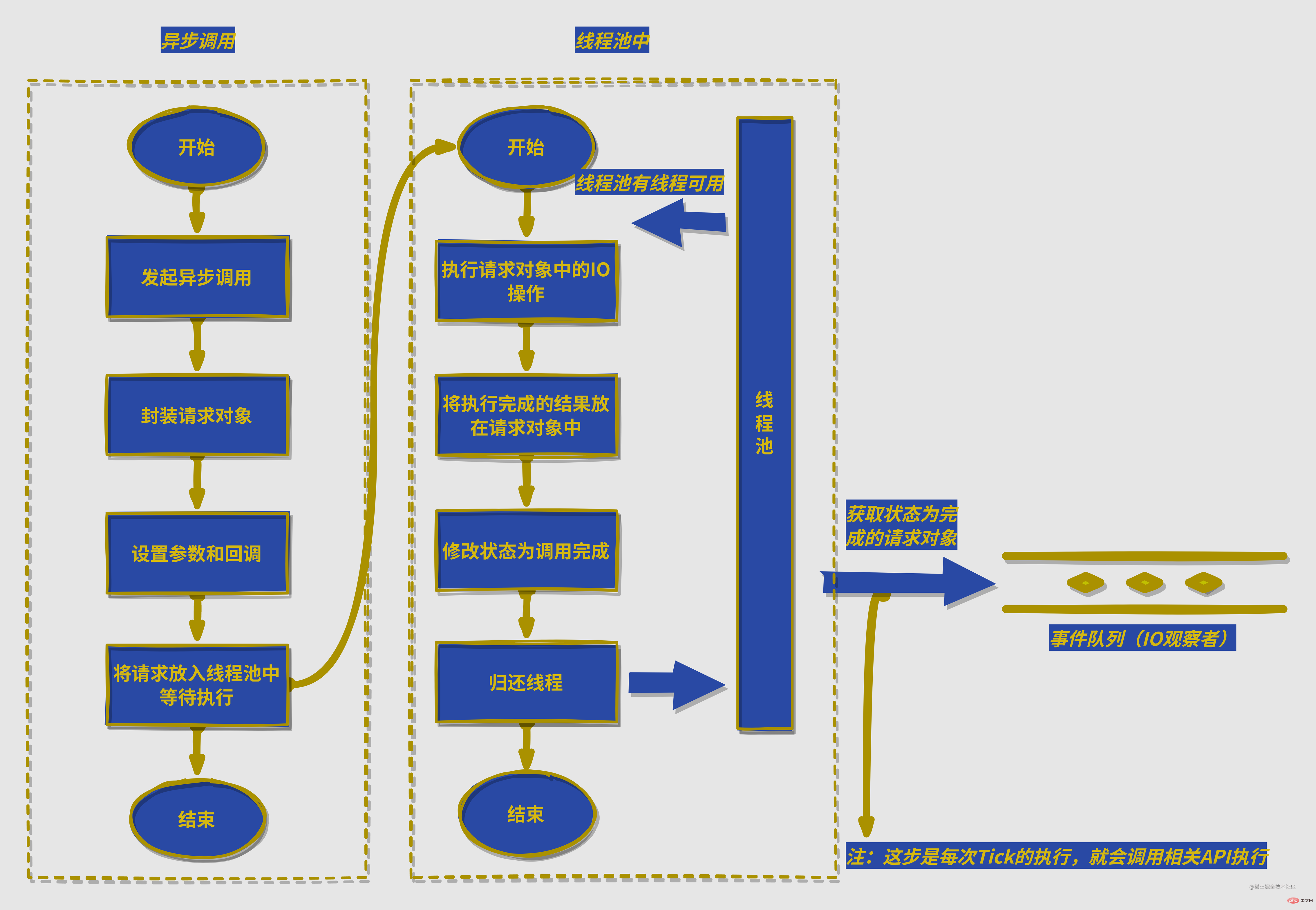
注:不同平台有不同的细节实现,这张图隐藏了相关平台兼容细节,比如windows下使用IOCP中的
PostQueuedCompletionStatus()提交执行状态,通过GetQueuedCompletionStatus获取执行完成的请求,并且IOCP内部实现了线程池的细节,而linux等平台通过eopll实现这个过程,并在libuv下自实现了线程池
setTimtout与setInterval
除了IO等计算机资源需要异步调用之外,node本身还存在一些与异步IO无关的一些其他异步API:
setTimeoutsetIntervalsetImmediateprocess.nextTick
该小节先讲解前面两个api
它们的实现原理与异步IO比较类似,只是不需要IO线程池的参与:
-
setTimtout与setInterval创建的定时器会被插入到定时器观察者内部的一个红黑树中 - 每次
tick - 비동기 외에도 IO, 이는 Linux의 모든 것이 파일이고 디스크, 하드웨어 및 소켓과 같은 거의 모든 컴퓨터 리소스가 파일로 추상화되기 때문에 컴퓨터의 다른 리소스에도 적용됩니다. 예.
이벤트 루프
프로세스가 시작되면🎜n🎜🎜)🎜🎜🎜 🎜🎜🎜🎜🎜이 문제를 생각해 본 적이 있습니까? 타이머가 왜 필요하지 않습니까? 이전 장에서 비동기 IO의 구현 원리를 이해했다면, 당신이 그것을 설명할 수 있어야 한다고 믿으세요. 다음은 당신의 기억력을 심화시키는 이유에 대한 간략한 설명입니다: 🎜node는while과 유사한 이벤트를 생성합니다. (true)의 루프에서는 루프 본문이 실행될 때마다Tick이 됩니다.다음은
노드의 이벤트 루프 흐름도입니다.
setTimtout및setInterval에 의해 생성된 타이머 > 타이머 관찰자 내부의 레드-블랙 트리에 삽입됩니다
노드의 IO 스레드 풀은 IO를 호출하고 데이터가 반환될 때까지 기다리는 방법입니다(구체적인 구현 참조). 이를 통해 JavaScript의 단일 스레드를 호출할 수 있습니다. IO 비동기식이며 IO 실행이 완료될 때까지 기다릴 필요가 없으며(IO 스레드 풀이 수행하기 때문에) 최종 데이터를 얻을 수 있습니다(관찰자 모드를 통해: IO 관찰자는 실행 완료 이벤트를 IO 스레드 풀에서 얻습니다). 이벤트 루프 메커니즘은 후속 콜백 함수를 실행합니다)node中的IO线程池是用来调用IO并等待数据返回(看具体实现)的一种方式,它使JavaScript单线程得以异步调用IO,并且不需要等待IO执行完成(因为是IO线程池做了),并且能获取到最终的数据(通过观察者模式:IO观察者从线程池获取执行完成的事件,事件循环机制执行后续的回调函数)
上述这段话可能有点简略,如果你还不明白,可以看下之前的那几种图~
process.nextTick与setImmediate
这两个函数都是代表立即异步执行一个函数,那为什么不用setTimeout(() => { ... }, 0)来完成呢?
- 定时器精度不够
- 定时器使用红黑树来创建定时器对象和迭代操作,浪费性能
- 即
process.nextTick更加轻量
轻量具体来说:我们在每次调用process.nextTick的时候,只会将回调函数放入队列中,在下一轮Tick时取出执行。定时器中采用红黑树的方式时,nextTick为
那process.nextTick与setImmediate又有什么区别呢?毕竟它们都是将回调函数立即异步执行
-
process.nextTick的回调执行优先级高于setImmediate -
process.nextTick的回调函数保存在一个数组中,每轮事件循环下全部执行,setImmediate的结果则是保存在链表中,每轮循环按序执行第一个回调
注意:之所以process.nextTick的回调执行优先级高于setImmediate,因为事件循环对观察者的检查是有顺序的,process.nextTick属于idle观察者,setImmediate属于check观察者。iedl观察者 > IO 观察者 > check观察者
高性能服务器
对于网络套接字的处理,
node也应用到了异步IO,网络套接字上侦听到的请求都会形成事件交给IO观察者,事件循环会不停地处理这些网络IO事件,如果我们在JavaScrpt层面上有传入对应的回调函数,这些回调函数就会在事件循环中执行(处理这些网络请求)
常见的服务器模型:
- 同步式
- 每进程-->每请求
- 每线程-->每请求
而node采用的是事件驱动的方式处理这些请求,无需对每个请求创建额外的对应线程,可以省略掉创建线程和销毁线程的开销,同时操作系统的调度任务因为线程较少(只有node
🎜process .nextTick 및 setImmediate
🎜두 함수 모두 함수의 즉각적인 비동기 실행을 나타냅니다. setTimeout(() => { ... }, 0)을 사용하여 완료하시겠습니까? 🎜- 타이머가 충분히 정확하지 않습니다
- 타이머는 레드-블랙 트리를 사용하여 타이머 개체와 반복 작업을 생성하므로 성능이 낭비됩니다.
- 예:
process.nextTick더 가벼워짐
process.nextTick을 호출할 때마다 다음과 같이 콜백 함수만 대기열에 넣습니다. 한 번의 Tick 라운드 후에 실행됩니다. 타이머에서 레드-블랙 트리 방법을 사용하는 경우O(l og2 스팬 >n), nextTickO(1) 🎜🎜process.nextTick과 setImmediate의 차이점은 무엇인가요? 결국 모두 비동기적으로 즉시 콜백 함수를 실행합니다🎜-
process.nextTick의 콜백 실행 우선순위가setImmediate의 콜백 실행 우선순위보다 높습니다. - process.nextTick
setImmediate의 결과는 링크에 저장됩니다. 목록에 있으며 루프의 각 라운드는 첫 번째 콜백을 순서대로 실행합니다.🎜참고: process.nextTick의 콜백 실행 우선순위가 그보다 높은 이유는 다음과 같습니다. setImmediate는 이벤트 루프가 관찰자를 확인하기 때문입니다. 순서대로 process.nextTick는 idle 관찰자에 속하고 setImmediate는 는 check 관찰자에 속합니다. iedl 관찰자> IO 관찰자🎜🎜고성능 서버
🎜For 네트워크 처리🎜공통 서버 모델: 🎜node는 비동기 IO에도 적용됩니다. 네트워크 소켓에서 수신되는 요청은 이벤트를 형성하고 통과하는 경우 이벤트 루프가 이러한 네트워크 IO를 지속적으로 처리합니다.JavaSccrpt수준의 해당 콜백 함수에서 이러한 콜백 함수는 이벤트 루프에서 실행됩니다(이러한 네트워크 요청 처리) 🎜
- 동기식
- 프로세스당-->요청당
- 스레드당-->요청당
노드에 의해 내부적으로 구현된 일부 스레드만) 컨텍스트 전환이 저렴합니다. 🎜
고전적인 문제--Avalanche 문제해결책:
문제 설명: 서버가 방금 시작되었을 때 캐시에 데이터가 없습니다. 액세스 양이 많으면 동일한 SQL이 실행됩니다. 반복되는 쿼리를 위해 데이터베이스로 전송되어 성능에 영향을 줍니다. SQL会被发送到数据库中反复查询,影响性能。
解决方案:
const proxy = new events.EventEmitter();
let status = "ready"; // 状态锁,避免反复查询
const select = function(callback) {
proxy.once("selected", callback); // 绑定一个只执行一次名为selected的事件
if(status === "ready") {
status = "pending";
// sql
db.select("SQL", (res) => {
proxy.emit("selected", res); // 触发事件,返回查询数据
status = "ready";
})
}
}使用once
위 내용은 Node에서의 비동기 구현과 이벤트 구동에 대해 이야기해 보겠습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!