
Python에서 여러 스레드를 사용하여 동시에 그림을 다운로드하는 방법

- 青灯夜游앞으로
- 2022-09-22 13:43:003595검색

때로는 많은 수의 이미지를 다운로드하는 데 몇 시간이 걸립니다. 문제를 해결해 보겠습니다.
알겠습니다. 프로그램이 이미지를 다운로드할 때까지 기다리는 데 지쳤습니다. 때로는 몇 시간이 걸리는 수천 장의 이미지를 다운로드해야 하며, 프로그램이 이러한 어리석은 이미지 다운로드를 완료할 때까지 계속 기다릴 수 없습니다. 해야 할 중요한 일이 많이 있습니다.
텍스트 파일을 읽고 폴더에 나열된 모든 이미지를 초고속으로 다운로드하는 간단한 이미지 다운로더 스크립트를 만들어 보겠습니다.
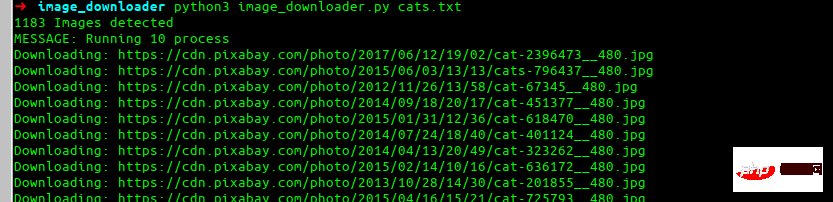
최종 효과
이것이 우리가 결국 만들게 될 것입니다.

종속성 설치
모두가 좋아하는 요청 라이브러리를 설치해 봅시다.
pip install requests
이제 단일 URL을 다운로드하고 이미지 이름을 자동으로 찾는 몇 가지 기본 코드와 재시도 사용 방법을 살펴보겠습니다.
import requests
res = requests.get(img_url, stream=True)
count = 1
while res.status_code != 200 and count <p>여기에서는 실패할 경우를 대비해 이미지 다운로드를 5번 다시 시도합니다. 이제 자동으로 이미지 이름을 찾아 저장해 보겠습니다. </p><pre class="brush:php;toolbar:false">import more required library
import io
from PIL import Image
# lets try to find the image name
image_name = str(img_url[(img_url.rfind('/')) + 1:])
if '?' in image_name:
image_name = image_name[:image_name.find('?')]Explanation
우리가 다운로드하려는 URL이
instagram.fktm7-1.fna.fbcdn.net/vp...
아, 이건 엉망입니다. URL에 대해 코드가 수행하는 작업을 분석해 보겠습니다. 먼저 rfind를 사용하여 마지막 슬래시(/)를 찾은 다음 그 뒤의 모든 항목을 선택합니다. 결과는 다음과 같습니다. rfind 找到最后一个正斜杠(/),然后选择之后的所有内容。这是结果:
65872070_1200425330158967_6201268309743367902_n.jpg?_nc_ht=instagram.fktm7–1.fna.fbcdn.net&_nc_cat=111
现在我们的第二部分找到一个 ?,然后只取它前面的任何东西。
这是我们最终的图像名称:
65872070_1200425330158967_6201268309743367902_n.jpg
这个结果非常好,适用于大多数用例。
现在我们已经下载了图像名称和图像,我们将保存它。
i = Image.open(io.BytesIO(res.content)) i.save(image_name)
如果你在想,「我到底应该怎么使用上面的代码?」那么你的想法是正确的。这是一个漂亮的函数,我们在上面所做的一切都被扁平处理了。在这里,我们还测试了下载的类型是否为图像,以防找不到图像名称。
def image_downloader(img_url: str):
"""
Input:
param: img_url str (Image url)
Tries to download the image url and use name provided in headers. Else it randomly picks a name
"""
print(f'Downloading: {img_url}')
res = requests.get(img_url, stream=True)
count = 1
while res.status_code != 200 and count <p>现在,你可能会问:「这个人所说的多处理在哪里?」。</p><p>这很简单。我们将简单地定义我们的池并将我们的函数和图像 URL 传递给它。</p><pre class="brush:php;toolbar:false">results = ThreadPool(process).imap_unordered(image_downloader, images_url)
for r in results:
print(r)让我们把它放在一个函数中:
def run_downloader(process:int, images_url:list):
"""
Inputs:
process: (int) number of process to run
images_url:(list) list of images url
"""
print(f'MESSAGE: Running {process} process')
results = ThreadPool(process).imap_unordered(image_downloader, images_url)
for r in results:
print(r)再一次,你可能会说,「这一切都很好,但我想立即开始下载我的 1000 张图像列表。我不想复制和粘贴所有这些代码并试图弄清楚如何合并所有内容。」
这是一个完整的脚本。它执行以下操作:
以图像列表文本文件和进程号作为输入
按照您想要的速度下载它们
打印下载文件的总时间
还有一些不错的函数可以帮助我们读取文件名并处理错误和其他东西
完整的脚本
# -*- coding: utf-8 -*-
import io
import random
import shutil
import sys
from multiprocessing.pool import ThreadPool
import pathlib
import requests
from PIL import Image
import time
start = time.time()
def get_download_location():
try:
url_input = sys.argv[1]
except IndexError:
print('ERROR: Please provide the txt file\n$python image_downloader.py cats.txt')
name = url_input.split('.')[0]
pathlib.Path(name).mkdir(parents=True, exist_ok=True)
return name
def get_urls():
"""
通过读取终端中作为参数提供的 txt 文件返回 url 列表
"""
try:
url_input = sys.argv[1]
except IndexError:
print('ERROR: Please provide the txt file\n Example \n\n$python image_downloader.py dogs.txt \n\n')
sys.exit()
with open(url_input, 'r') as f:
images_url = f.read().splitlines()
print('{} Images detected'.format(len(images_url)))
return images_url
def image_downloader(img_url: str):
"""
输入选项:
参数: img_url str (Image url)
尝试下载图像 url 并使用标题中提供的名称。否则它会随机选择一个名字
"""
print(f'Downloading: {img_url}')
res = requests.get(img_url, stream=True)
count = 1
while res.status_code != 200 and count <p>将其保存到 Python에서 여러 스레드를 사용하여 동시에 그림을 다운로드하는 방법에서 여러 스레드를 사용하여 동시에 그림을 다운로드하는 방법 文件中,然后运行它。</p><pre class="brush:php;toolbar:false">python3 image_downloader.py cats.txt这是 GitHub 存储库的链接。
用法
python3 image_downloader.py <filename_with_urls_seperated_by_newline.txt> <num_of_process></num_of_process></filename_with_urls_seperated_by_newline.txt>
这将读取文本文件中的所有 URL,并将它们下载到名称与文件名相同的文件夹中。
num_of_process
65872070_1200425330158967_6201268309743367902_n.jpg?_nc_ht=instagram.fktm7–1.fna.fbcdn.net&_nc_cat=111
이제 두 번째 부분적으로 ? 무엇이든 받아들이세요. 앞쪽.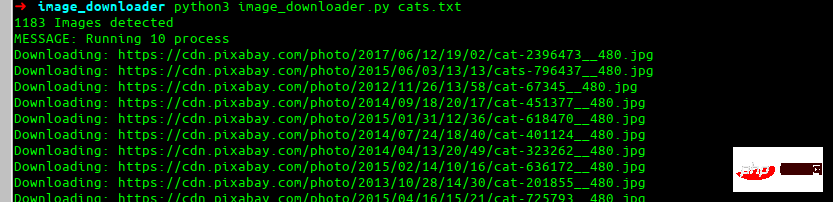 최종 이미지 이름은 다음과 같습니다.
최종 이미지 이름은 다음과 같습니다.
 65872070_1200425330158967_6201268309743367902_n.jpg
65872070_1200425330158967_6201268309743367902_n.jpg
"도대체 위 코드를 어떻게 사용해야 하지?"라고 생각하신다면 맞습니다. 이것은 아름다운 함수이며 우리가 수행한 모든 작업은 평면화되었습니다. 여기서는 이미지 이름을 찾을 수 없는 경우를 대비해 다운로드한 유형이 이미지인지 테스트합니다.이제 이미지 이름과 이미지를 다운로드했으므로 저장하겠습니다.
python3 image_downloader.py cats.txt
rrreee이제 "이 사람이 말하는 멀티프로세싱이 어디에 있나요?"라고 질문하실 수 있습니다.
쉽습니다. 간단히 풀을 정의하고 함수와 이미지 URL을 전달하겠습니다. 🎜rrreee🎜이것을 함수에 넣어봅시다: 🎜rrreee🎜다시 한 번, “이건 다 좋은데, 1000개의 이미지 목록을 즉시 다운로드하고 싶어요. 복사하고 싶지 않아요. 모두 붙여넣기 코드를 작성하고 모든 것을 병합하는 방법을 알아내려고 합니다. 🎜🎜이것은 완전한 스크립트입니다. 다음 작업을 수행합니다. 🎜- 🎜 원하는 속도로 이미지 목록 텍스트 파일과 프로세스 번호 🎜
- 🎜를 입력으로 사용합니다. 다운로드하고 싶습니다 🎜
- 🎜파일을 다운로드하는 데 걸린 총 시간을 인쇄하세요🎜
- 🎜파일 이름을 읽고 오류 및 기타 작업을 처리하는 데 도움이 되는 멋진 기능도 있습니다🎜
num_of_process는 선택 사항입니다(기본적으로 10개의 프로세스를 사용함). 🎜🎜🎜Example🎜🎜rrreee🎜🎜🎜🎜🎜🎜🎜이 문제를 더욱 개선하는 방법에 대한 답변을 보내주시면 기쁠 것입니다. 🎜🎜🎜영어 원본 주소: https://betterprogramming.pub/building-an-imagedownloader-with-multiprocessing-in-python-44aee36e0424🎜🎜🎜【관련 권장 사항: 🎜Python에서 여러 스레드를 사용하여 동시에 그림을 다운로드하는 방법에서 여러 스레드를 사용하여 동시에 그림을 다운로드하는 방법3 비디오 튜토리얼🎜】🎜위 내용은 Python에서 여러 스레드를 사용하여 동시에 그림을 다운로드하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!