
Python 분석에서 Namedtuple 함수 사용

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2022-09-01 14:38:111833검색

【관련 추천: Python3 동영상 튜토리얼】
소스 코드 설명:
def namedtuple(typename, field_names, *, rename=False, defaults=None, module=None):
"""Returns a new subclass of tuple with named fields.
>>> Point = namedtuple('Point', ['x', 'y'])
>>> Point.__doc__ # docstring for the new class
'Point(x, y)'
>>> p = Point(11, y=22) # instantiate with positional args or keywords
>>> p[0] + p[1] # indexable like a plain tuple
33
>>> x, y = p # unpack like a regular tuple
>>> x, y
(11, 22)
>>> p.x + p.y # fields also accessible by name
33
>>> d = p._asdict() # convert to a dictionary
>>> d['x']
11
>>> Point(**d) # convert from a dictionary
Point(x=11, y=22)
>>> p._replace(x=100) # _replace() is like str.replace() but targets named fields
Point(x=100, y=22)
"""문법 구조:
namedtuple(typename, field_names, *, rename=False, defaults=None, module=None)
- 유형 이름: 새로 생성된 튜플.
- field_names: 는 목록과 같은 ['x', 'y']
이름이 지정된 튜플인 튜플의 내용이므로 목록과 같은 키를 사용하여 튜플에 액세스할 수 있습니다. index)를 사용하여 액세스할 수 있습니다.
collections.namedtuple은 필드 이름과 명명된 클래스를 사용하여 튜플을 구성하는 데 사용할 수 있는 팩토리 함수입니다.
네임드 튜플을 생성하려면 두 개의 매개변수가 필요합니다. 하나는 클래스 이름이고 다른 하나는 클래스입니다. 필드.
해당 필드에 저장된 데이터는 일련의 매개변수 형식으로 생성자에 전달되어야 합니다(튜플 생성자는 반복 가능한 단일 객체만 허용한다는 점에 유의하세요).
이름이 지정된 튜플에는 고유한 속성도 있습니다. 가장 유용한 것은 클래스 속성 _fields, 클래스 메서드 _make(iterable) 및 인스턴스 메서드 _asdict()입니다.
샘플 코드 1:
from collections import namedtuple # 定义一个命名元祖city,City类,有name/country/population/coordinates四个字段 city = namedtuple('City', 'name country population coordinates') tokyo = city('Tokyo', 'JP', 36.933, (35.689, 139.69)) print(tokyo) # _fields 类属性,返回一个包含这个类所有字段名称的元组 print(city._fields) # 定义一个命名元祖latLong,LatLong类,有lat/long两个字段 latLong = namedtuple('LatLong', 'lat long') delhi_data = ('Delhi NCR', 'IN', 21.935, latLong(28.618, 77.208)) # 用 _make() 通过接受一个可迭代对象来生成这个类的一个实例,作用跟City(*delhi_data)相同 delhi = city._make(delhi_data) # _asdict() 把具名元组以 collections.OrderedDict 的形式返回,可以利用它来把元组里的信息友好地呈现出来。 print(delhi._asdict())
실행 결과:

샘플 코드 2:
from collections import namedtuple Person = namedtuple('Person', ['age', 'height', 'name']) data2 = [Person(10, 1.4, 'xiaoming'), Person(12, 1.5, 'xiaohong')] print(data2) res = data2[0].age print(res) res2 = data2[1].name print(res2)
실행 결과:

예제 코드 3:
from collections import namedtuple
card = namedtuple('Card', ['rank', 'suit']) # 定义一个命名元祖card,Card类,有rank和suit两个字段
class FrenchDeck(object):
ranks = [str(n) for n in range(2, 5)] + list('XYZ')
suits = 'AA BB CC DD'.split() # 生成一个列表,用空格将字符串分隔成列表
def __init__(self):
# 生成一个命名元组组成的列表,将suits、ranks两个列表的元素分别作为命名元组rank、suit的值。
self._cards = [card(rank, suit) for suit in self.suits for rank in self.ranks]
print(self._cards)
# 获取列表的长度
def __len__(self):
return len(self._cards)
# 根据索引取值
def __getitem__(self, item):
return self._cards[item]
f = FrenchDeck()
print(f.__len__())
print(f.__getitem__(3))실행 결과:

샘플 코드 4:
from collections import namedtuple person = namedtuple('Person', ['first_name', 'last_name']) p1 = person('san', 'zhang') print(p1) print('first item is:', (p1.first_name, p1[0])) print('second item is', (p1.last_name, p1[1]))
실행 결과:

샘플 코드 5: 【_make는 기존 시퀀스 또는 반복에서 인스턴스를 생성합니다】
from collections import namedtuple
course = namedtuple('Course', ['course_name', 'classroom', 'teacher', 'course_data'])
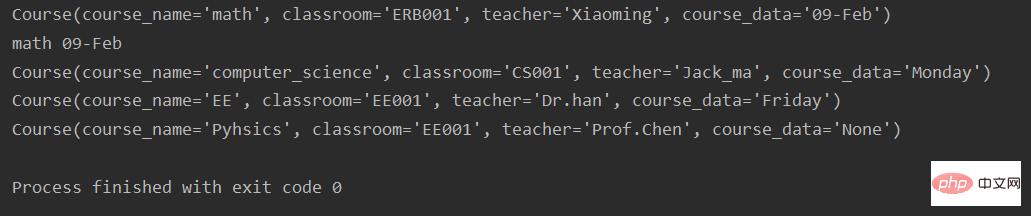
math = course('math', 'ERB001', 'Xiaoming', '09-Feb')
print(math)
print(math.course_name, math.course_data)
course_list = [
('computer_science', 'CS001', 'Jack_ma', 'Monday'),
('EE', 'EE001', 'Dr.han', 'Friday'),
('Pyhsics', 'EE001', 'Prof.Chen', 'None')
]
for k in course_list:
course_i = course._make(k)
print(course_i) 실행 결과:
예제 코드 6: [_asdict는 필드 이름을 해당 값에 매핑하는 새로운 정렬된 사전을 반환]
from collections import namedtuple person = namedtuple('Person', ['first_name', 'last_name']) zhang_san = ('Zhang', 'San') p = person._make(zhang_san) print(p) # 返回的类型不是dict,而是orderedDict print(p._asdict())
실행 결과:

예제 코드 7: [_re 장소 새 인스턴스를 반환하고 지정된 필드를 새 값으로 바꿉니다]
from collections import namedtuple person = namedtuple('Person', ['first_name', 'last_name']) zhang_san = ('Zhang', 'San') p = person._make(zhang_san) print(p) p_replace = p._replace(first_name='Wang') print(p_replace) print(p) p_replace2 = p_replace._replace(first_name='Dong') print(p_replace2)
실행 결과:

샘플 코드 8: [_fields는 필드 이름을 반환]
from collections import namedtuple person = namedtuple('Person', ['first_name', 'last_name']) zhang_san = ('Zhang', 'San') p = person._make(zhang_san) print(p) print(p._fields)
실행 결과:

샘플 코드 9: [필드를 사용하여 두 개의 명명된 튜플 결합]
from collections import namedtuple person = namedtuple('Person', ['first_name', 'last_name']) print(person._fields) degree = namedtuple('Degree', 'major degree_class') print(degree._fields) person_with_degree = namedtuple('person_with_degree', person._fields + degree._fields) print(person_with_degree._fields) zhang_san = person_with_degree('san', 'zhang', 'cs', 'master') print(zhang_san)
실행 결과:

샘플 코드 10: [field_defaults]
from collections import namedtuple person = namedtuple('Person', ['first_name', 'last_name'], defaults=['san']) print(person._fields) print(person._field_defaults) print(person('zhang')) print(person('Li', 'si'))
실행 결과:

샘플 코드 11: [namedtuple은 클래스이므로 하위 클래스를 통해 함수 변경 가능]
from collections import namedtuple
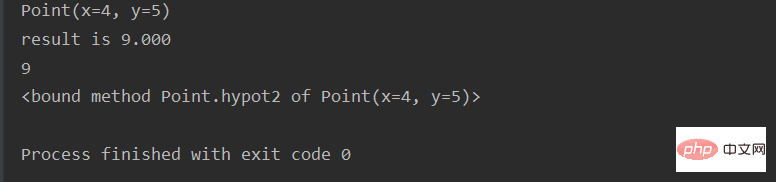
Point = namedtuple('Point', ['x', 'y'])
p = Point(4, 5)
print(p)
class Point(namedtuple('Point', ['x', 'y'])):
__slots__ = ()
@property
def hypot(self):
return self.x + self.y
def hypot2(self):
return self.x + self.y
def __str__(self):
return 'result is %.3f' % (self.x + self.y)
aa = Point(4, 5)
print(aa)
print(aa.hypot)
print(aa.hypot2)실행 결과:
샘플 코드 12: [참고 두 작성의 차이점을 관찰하세요. 방법】
from collections import namedtuple
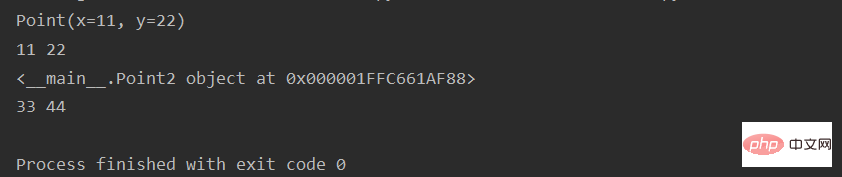
Point = namedtuple("Point", ["x", "y"])
p = Point(11, 22)
print(p)
print(p.x, p.y)
# namedtuple本质上等于下面写法
class Point2(object):
def __init__(self, x, y):
self.x = x
self.y = y
o = Point2(33, 44)
print(o)
print(o.x, o.y)실행 결과:
【관련 권장 사항:Python3 비디오 튜토리얼】
위 내용은 Python 분석에서 Namedtuple 함수 사용의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!