
집 >데이터 베이스 >MySQL 튜토리얼 >MySQL의 스트리밍 쿼리 및 커서 쿼리 방법(요약 공유)
MySQL의 스트리밍 쿼리 및 커서 쿼리 방법(요약 공유)

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2022-08-17 18:08:304340검색
이 기사는 mysql에 대한 관련 지식을 제공합니다. MySQL의 스트리밍 쿼리 및 커서 쿼리 방법을 주로 소개하며 좋은 참조 가치가 있으므로 모든 사람에게 도움이 되기를 바랍니다.

추천 학습: mysql 비디오 튜토리얼
1. 비즈니스 시나리오
이제 비즈니스 시스템은 처리를 위해 MySQL 데이터베이스에서 5백만 개의 데이터 행을 읽어야 합니다
- 데이터 마이그레이션
- 데이터 내보내기
- 일괄 처리 데이터 처리
두 번째, 세 가지 처리 방법을 나열하세요
- 일반 쿼리: 500만 개의 데이터를 한 번에 JVM 메모리로 읽거나 페이지 단위로 읽습니다.
- 스트리밍 쿼리: 한 번에 한 조각씩 읽어 JVM 메모리에 로드합니다. 비즈니스 처리용
- 커서 쿼리: 스트리밍과 마찬가지로 한 번에 읽는 데이터 수는 fetchSize 매개 변수를 통해 제어됩니다
2.1 일반 쿼리
기본적으로 전체 검색 결과 집합은 메모리에 저장됩니다. . 대부분의 경우 이는 가장 효율적인 작동 방법이며 구현하기도 더 쉽습니다.
단일 테이블의 데이터량이 500만개라고 가정할 때, 누구도 한번에 메모리에 로드하지 않으며 일반적으로 페이징을 사용합니다.
여기서 테스트 데모는 JVM을 모니터링하기 위한 것이므로 페이징을 사용하지 않고 데이터가 한 번에 메모리에 로드됩니다.
@Test
public void generalQuery() throws Exception {
// 1核2G:查询一百条记录:47ms
// 1核2G:查询一千条记录:2050 ms
// 1核2G:查询一万条记录:26589 ms
// 1核2G:查询五万条记录:135966 ms
String sql = "select * from wh_b_inventory limit 10000";
ps = conn.prepareStatement(sql);
ResultSet rs = ps.executeQuery(sql);
int count = 0;
while (rs.next()) {
count++;
}
System.out.println(count);
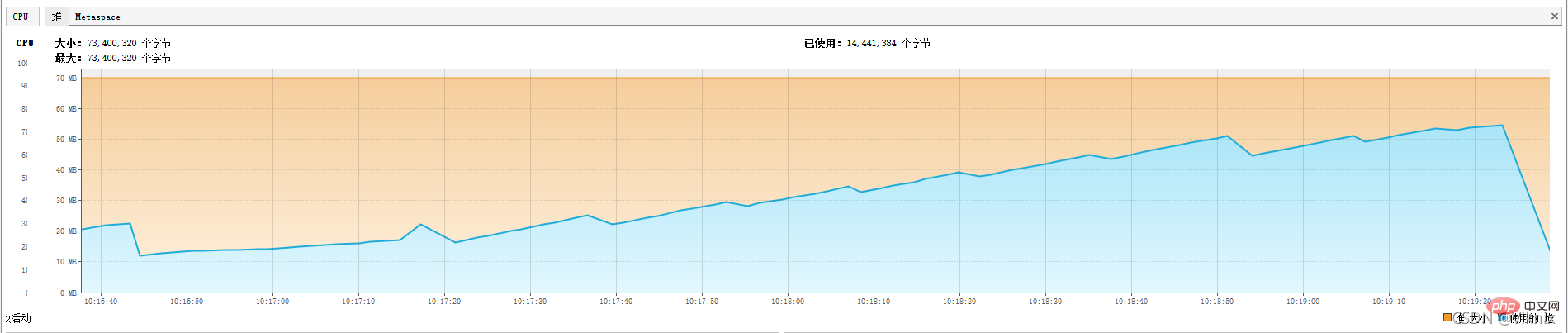
}JVM 모니터링
메모리를 -Xms70m -Xmx70m
으로 조정하겠습니다.전체 쿼리 프로세스에서 힙 메모리 사용량이 점차 증가하고 결국 OOM이 발생합니다.
java.lang.OutOfMemoryError: GC 오버헤드 제한 초과
1. OOM에 숨겨진 위험이 있습니다
. 2.2 스트리밍 쿼리
2.2 스트리밍 쿼리
스트리밍 쿼리에 대해 주의할 점: 연결에서 다른 쿼리를 실행하기 전에 결과 집합의 모든 행을 읽거나 닫아야 합니다. 그렇지 않으면 예외가 발생하고 쿼리가 실행됩니다. 연결을 독점하게 됩니다.
테스트 결과 스트리밍 쿼리로는 쿼리 속도가 향상되지 않았습니다
@Test
public void streamQuery() throws Exception {
// 1核2G:查询一百条记录:138ms
// 1核2G:查询一千条记录:2304 ms
// 1核2G:查询一万条记录:26536 ms
// 1核2G:查询五万条记录:135931 ms
String sql = "select * from wh_b_inventory limit 50000";
statement = conn.createStatement(ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_READ_ONLY);
statement.setFetchSize(Integer.MIN_VALUE);
ResultSet rs = statement.executeQuery(sql);
int count = 0;
while (rs.next()) {
count++;
}
System.out.println(count);
}JVM 모니터링힙 메모리를 줄였습니다. -Xms70m -Xmx70m
힙 메모리가 70m에 불과하더라도 여전히 OOM
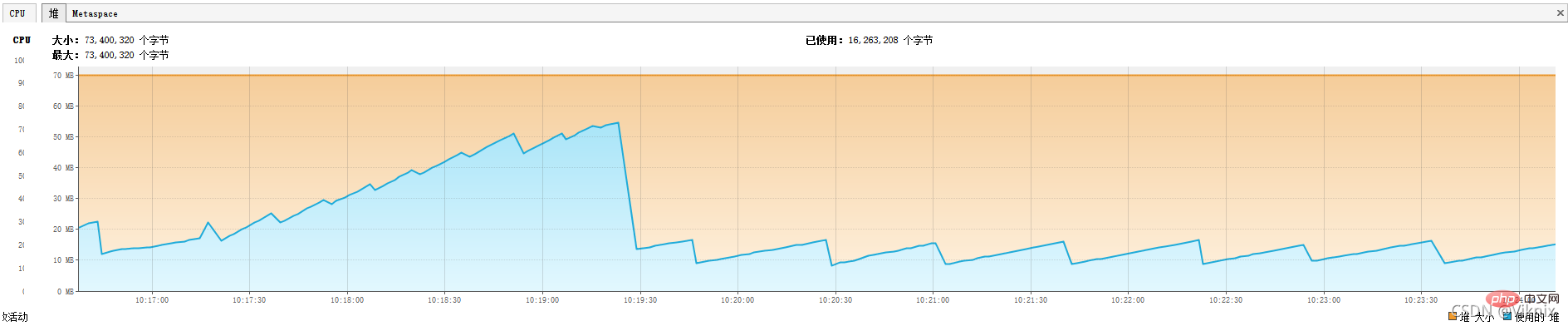 2.3 커서 쿼리
2.3 커서 쿼리
참고:
1. 데이터베이스 연결 정보에 매개변수를 연결해야 합니다.
useCursorFetch=true2. 두 번째로 매번 문이 읽는 데이터 수를 설정합니다. , 한 번에 1000개
테스트 결과에 따르면 커서 쿼리가 쿼리 속도를 어느 정도 단축시켰습니다
@Test
public void cursorQuery() throws Exception {
Class.forName("com.mysql.jdbc.Driver");
// 注意这里需要拼接参数,否则就是普通查询
conn = DriverManager.getConnection("jdbc:mysql://101.34.50.82:3306/mysql-demo?useCursorFetch=true", "root", "123456");
start = System.currentTimeMillis();
// 1核2G:查询一百条记录:52 ms
// 1核2G:查询一千条记录:1095 ms
// 1核2G:查询一万条记录:17432 ms
// 1核2G:查询五万条记录:90244 ms
String sql = "select * from wh_b_inventory limit 50000";
((JDBC4Connection) conn).setUseCursorFetch(true);
statement = conn.createStatement(ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_READ_ONLY);
statement.setFetchSize(1000);
ResultSet rs = statement.executeQuery(sql);
int count = 0;
while (rs.next()) {
count++;
}
System.out.println(count);
}JVM 모니터링
힙 메모리를 줄였습니다. -Xms70m -Xmx70m
단일 스레드의 경우 커서 쿼리 스트리밍 쿼리와 마찬가지로 OOM도 매우 잘 피할 수 있으며 커서 쿼리는 쿼리 속도를 최적화할 수 있습니다.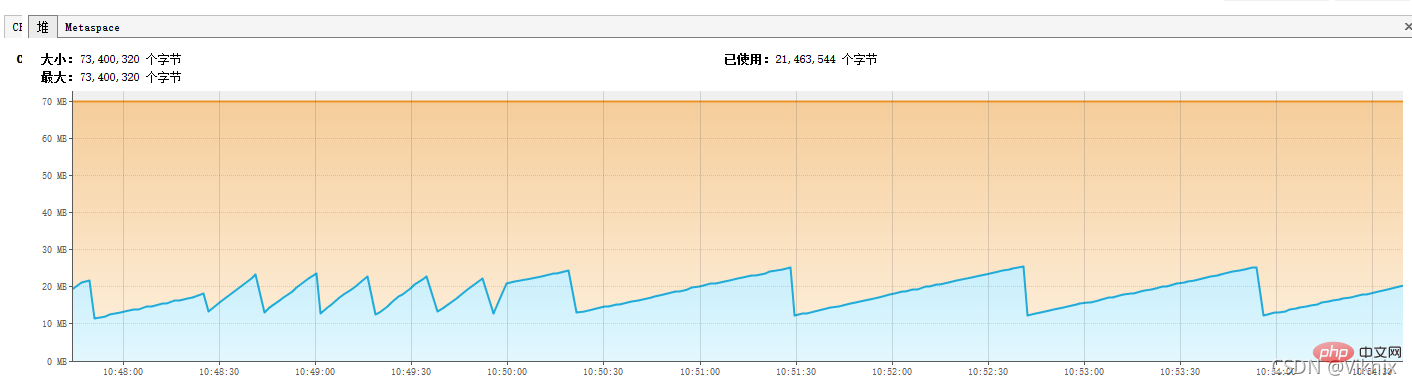
3. RowData
3.1 RowDataStatic
먼저 내부 버퍼에 반환되지 않은 데이터가 있는지 확인합니다.
- 모든 읽기가 완료되면 MySQL 서버에 새 읽기를 트리거하고 fetchSize 수량 결과
- 를 읽고 반환 결과를 내부 버퍼에 버퍼링한 다음 데이터의 첫 번째 행을 반환합니다.
- 요약:
기본 RowDataStatic은 모든 데이터를 클라이언트 메모리로 읽어 들이고 또한 JVM입니다. RowDataDynamic은 IO 호출당 하나의 데이터를 읽습니다.
RowDataCursor는 한 번에 fetchSize 행을 읽습니다. 소비가 완료된 후 요청 호출을 시작합니다.
4. JDBC 통신 원리
JDBC와 MySQL 서버 간의 상호 작용은 소켓을 통해 완료됩니다. 네트워크 프로그래밍에 따라 MySQL은 SocketServer로 간주될 수 있으므로 전체 요청 링크는 다음과 같아야 합니다.
JDBC 클라이언트 -> MySQL -> 데이터 반환 -> 네트워크 -> JDBC 클라이언트
4.1 일반 쿼리 일반 쿼리는 쿼리된 모든 데이터를 JVM에 로드한 후 처리합니다.
쿼리 데이터의 양이 너무 많으면 계속 GC가 발생하고 메모리 오버플로가 발생합니다.
4.2 streamQuery 스트리밍 쿼리
서버가 첫 번째 데이터에서 반환할 준비가 되면 로드됩니다. 데이터는 버퍼에 전달되며 TCP 링크는 클라이언트 시스템의 커널 버퍼에 삽입됩니다. JDBC의 inputStream.read() 메소드는 데이터를 읽을 때 활성화된다는 점입니다. 활성화되면 매번 커널에서만 읽습니다. 패키지 크기의 데이터를 가져오면 한 개의 데이터 행만 반환됩니다. 한 패키지가 한 개의 데이터 행을 어셈블할 수 없으면 다른 패키지를 읽습니다.
4.3cursorQuery Cursor Query
커서가 켜지면 서버가 데이터를 반환할 때 fetchSize의 크기에 따라 데이터를 반환하고 클라이언트가 데이터를 받을 때마다 모든 버퍼 데이터를 읽습니다. 데이터에 1억 개의 데이터가 있는 경우 FetchSize를 1000으로 설정하면 100,000회의 왕복 통신이 수행됩니다.
MySQL은 클라이언트가 언제 데이터 소비를 완료했는지 알지 못하므로 해당 테이블에 DML 쓰기 작업이 있을 수 있습니다. 이때 MySQL은 가져가야 할 데이터를 저장할 임시 공간을 만들어야 합니다.
useCursorFetch를 활성화하여 큰 테이블을 읽으면 MySQL에서 몇 가지 현상을 볼 수 있습니다.
1. IOPS가 급증합니다.- 2. 디스크 공간이 급증합니다.
- 3. 클라이언트 JDBC가 SQL을 시작한 후 오랜 시간이 걸립니다. 이 시간 동안 서버는 데이터 준비 중입니다
- 4. 데이터 준비가 완료되고 데이터 전송이 시작되면 네트워크 응답이 급증하기 시작하고 IOPS가 "읽기 및 쓰기"로 변경됩니다. "읽다".
- IOPS(Input/Output Per Second): 초당 디스크 읽기 및 쓰기 수
- 5. CPU 및 메모리가 일정 비율로 증가합니다.
- 5. 동시성 시나리오
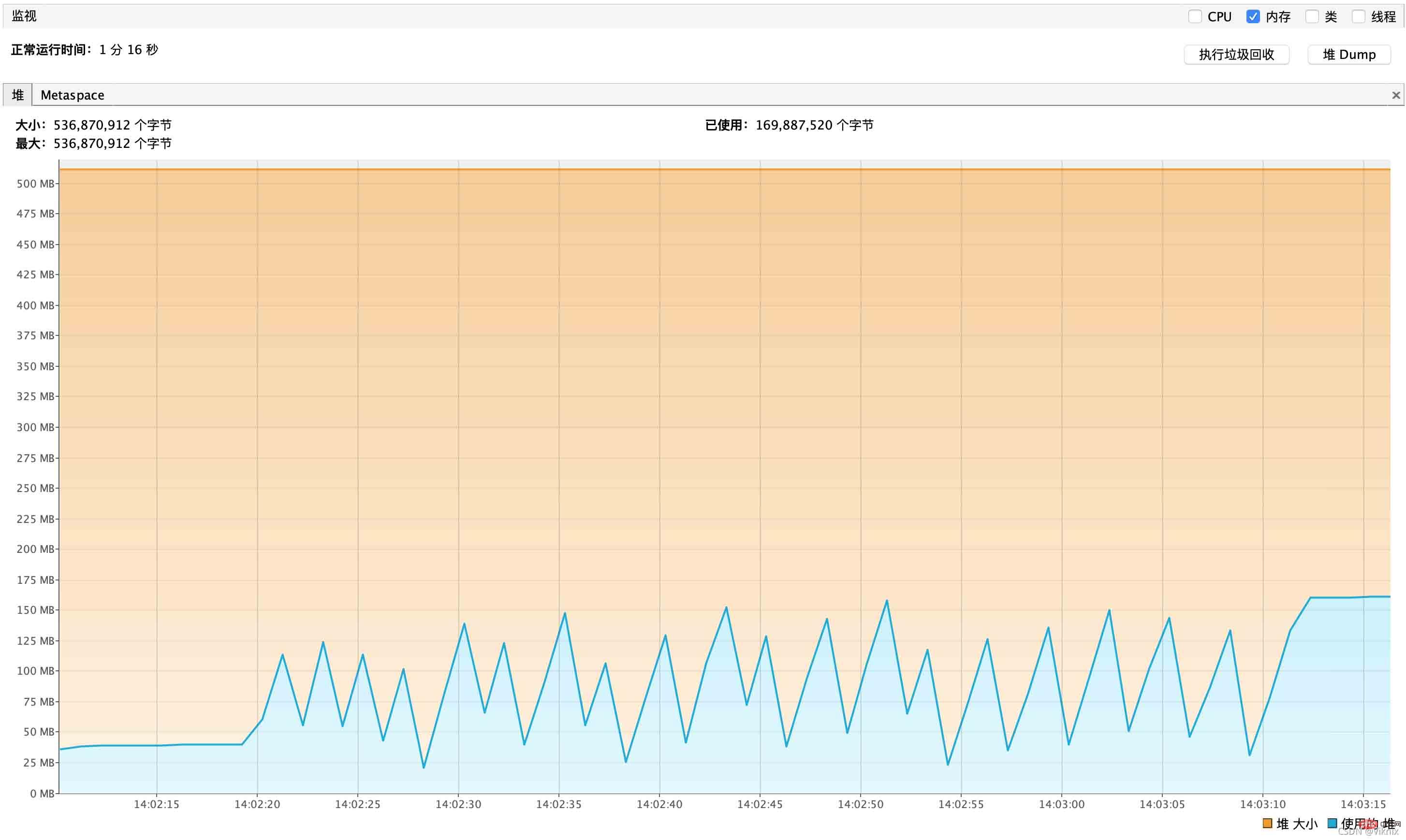
동시 호출: Jmete 10개 스레드가 동시에 1초
스트림 쿼리 호출의 메모리 성능 보고서는 다음과 같습니다
동시 호출도 메모리 사용량에 매우 좋으며 중첩 증가도 없습니다
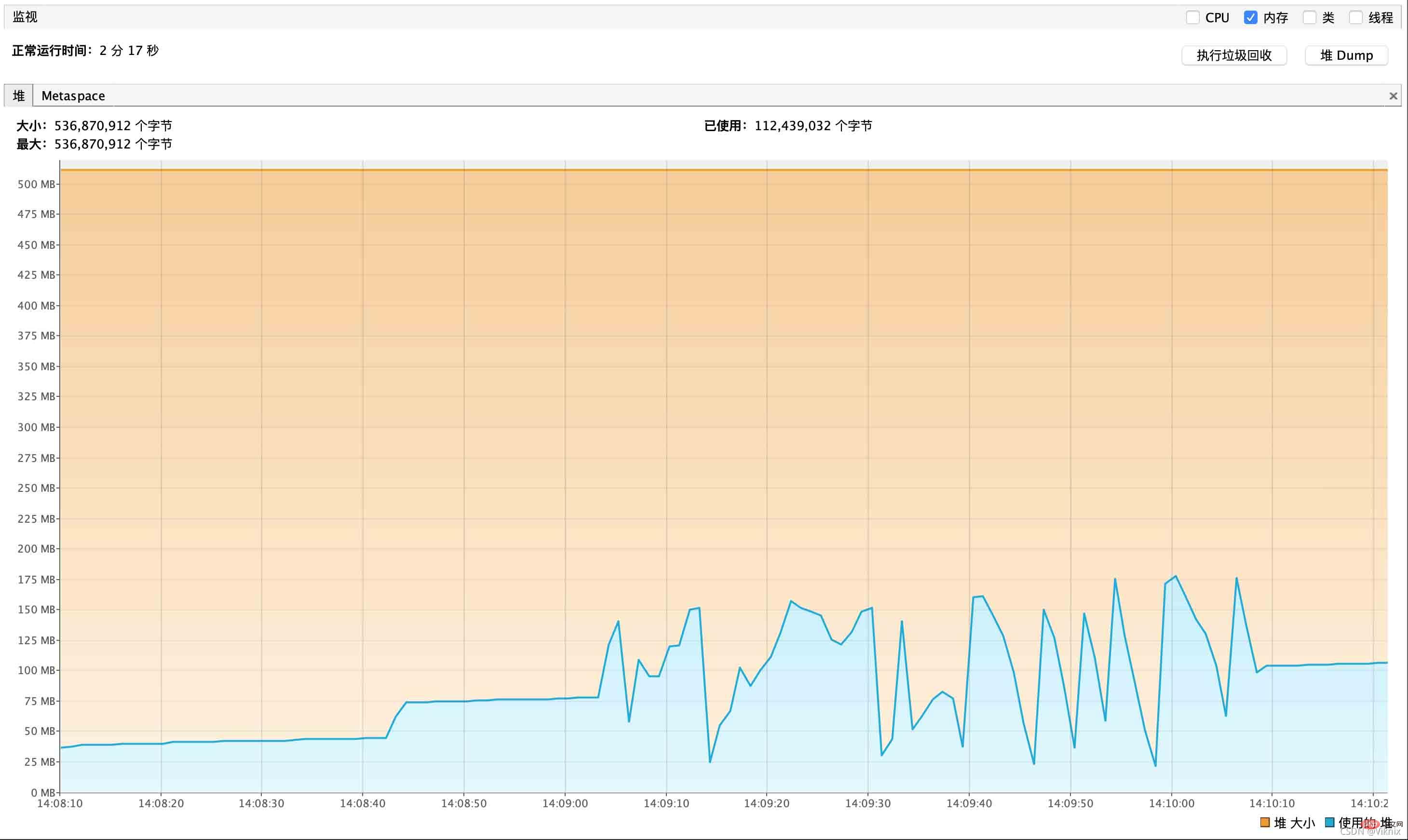
 커서 쿼리의 메모리 성능 보고서는 다음과 같습니다
커서 쿼리의 메모리 성능 보고서는 다음과 같습니다
 6. 요약
6. 요약
1. 단일 스레드에서 커서 쿼리와 스트리밍 쿼리 모두 OOM을 피할 수 있습니다.
2. 쿼리 속도 측면에서 커서 쿼리는 스트리밍 쿼리보다 빠르며 스트리밍 쿼리는 쿼리 시간을 단축할 수 없습니다. 일반 쿼리 사용
3. 동시 시나리오에서는 스트리밍 쿼리 힙 메모리의 추세가 더 안정적이며 추가 증가가 없습니다.
추천 학습:
mysql 비디오 튜토리얼위 내용은 MySQL의 스트리밍 쿼리 및 커서 쿼리 방법(요약 공유)의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!