
Java 기반의 복잡한 관계식 필터 구현에 대한 예제 소개

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2022-08-01 14:56:321730검색
이 기사에서는 java에 대한 관련 지식을 제공합니다. 주로 Java 기반의 복잡한 관계식 필터를 구현하는 방법을 자세히 소개합니다. 기사의 샘플 코드를 자세히 살펴보겠습니다. 모두에게 도움이 되기를 바랍니다.

추천 학습: "java video tutorial"
Background
최근에는 백그라운드에서 복잡한 관계식을 설정하고 이를 기반으로 사용자가 조건을 충족하는지 분석해야 하는 새로운 요구 사항이 있습니다. 사용자가 지정한 ID, 백그라운드 설정은 ZenTao의 검색 조건과 유사합니다

단, 차이점은 ZenTao에는 그룹이 2개뿐이고, 각 그룹에는 최대 3개의 조건이 있습니다
여기서의 그룹 및 관계는 더 복잡할수록 그룹 내에 그룹이 있고 각 조건에는 AND 또는 관계가 있습니다. 기밀 유지상의 이유로 프로토타입은 공개되지 않습니다.
이 요구사항을 보고 백엔드로서 가장 먼저 생각한 것은 QLEpress와 같은 표현식 프레임워크였습니다. 표현식을 작성하면 표현식을 구문 분석하여 대상 사용자를 빠르게 필터링할 수 있습니다. -end classmate, Vue나 React를 사용하는 데이터 기반 프레임워크로는 표현식을 위의 형태로 변환하는 것이 너무 어렵기 때문에 고민하다가 데이터 구조를 직접 정의하여 표현식 파싱을 구현하기로 했습니다. 프론트엔드 학생들이 처리하기에 편리합니다.
분석 준비
식은 클래스를 사용하여 구현되지만 여전히 간단한 식을 열거해 보겠습니다. 조건이 a, b, c, d라고 가정하면 마음대로 식을 구성할 수 있습니다.
boolean result=a>100 && b=10 || (c != 3 && d c726c10349b1b4a3771343bf1a3a9eb7100 && b=10 || (c != 3 && d 5a1b319c9256b5adbf09f78b85738671100 中的100)。
另外,还有关联关系(且、或)和计算优先级这几个属性组成。
于是我们对表达式进行简化:
令a>100 =>A,b=10 =>B,c!=3=>C ,dc849c18f1683bfc1ac5adfe2d1f542bdD,于是我们得到:
result=A && B || (C && D)
现在问题来了,如何处理优先级呢?
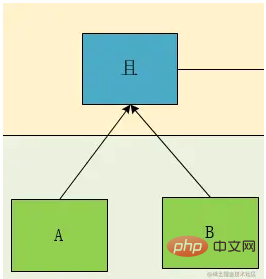
如上表达式,很明显,这是一个大学里学过的标准的中序表达式,于是,我们画一下它的树形图:
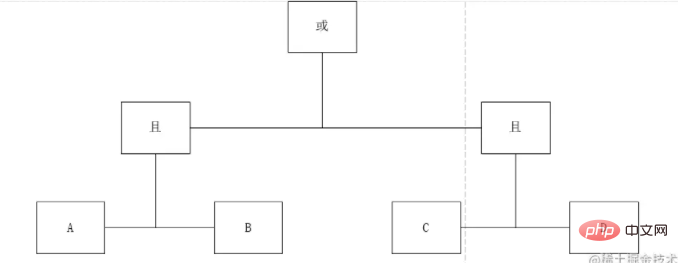
根据这个图,我们可以明显的看到,A且B 和C且D是同一级别,于是,我们按照这个理论设计一个层级的概念Deep,我们标注一下,然后再对节点的类型做一下区分,可得:
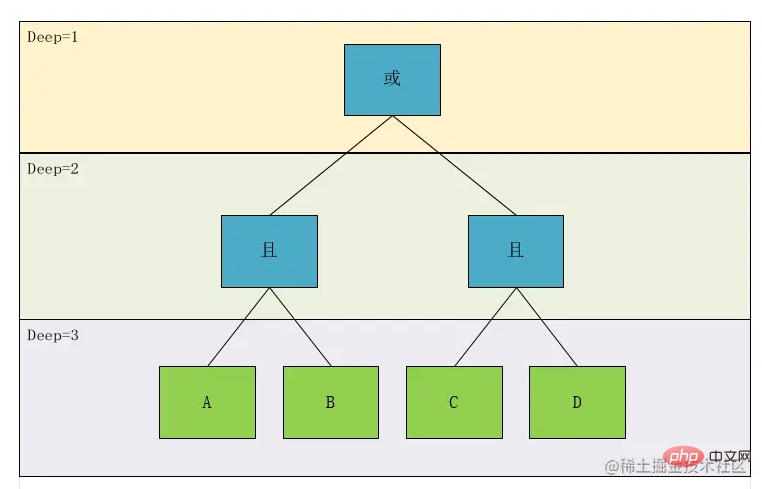
我们可以看到作为叶子节点(上图绿色部分),相对于其计算计算关系,遇到了一定是优先计算的,所以对于深度的优先级,我们仅需要考虑非叶子节点即可,即上图中的蓝色节点部分,于是我们得到了,计算优先级这个概念我们可以转换为表达式的深度。
我们再看上面这个图,Deep1 的关系是Deep2中 A且B 和 C且D两个表达式计算出的结果再进行与或关系的,我们设A 且B 为 G1, C且D为 G2,于是我们发现关系节点关联的类型有两种类型,一种是条件Condition ,一种是组Group
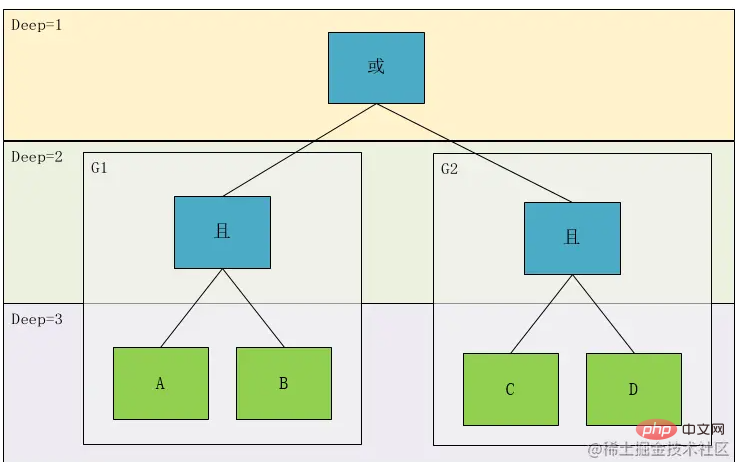
至此,这个类的雏形基本就确定了。这个类包含 关联关系(Relation)、判断字段(Field)、运算符(Operator)、运算值(Values)、类型(Type)、深度(Deep)
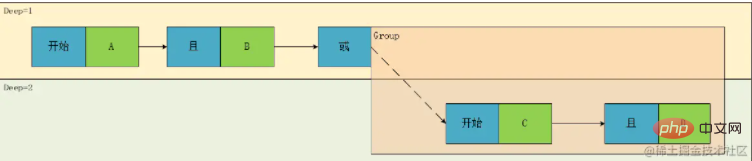
但是,有个问题,上面的分析中,我们在将表达式转换成树,现在我们试着将其还原,于是我们一眼可以得到其中一种表达式:
result=(A && B)||(C && D)
result=A && B || (C && D)🎜🎜이제 질문은 우선순위를 어떻게 처리할 것인가입니다. 🎜🎜위 표현식은 분명히 대학에서 배운 표준 중위 표현식이므로 트리 다이어그램을 그려보겠습니다. 🎜🎜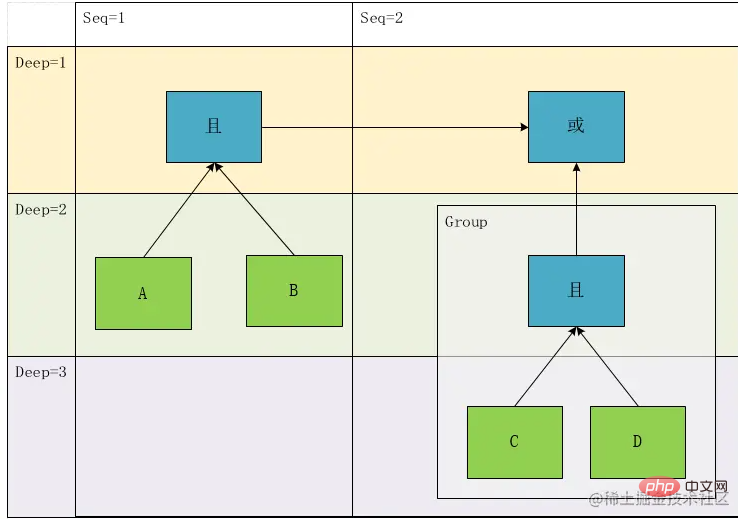 🎜🎜이 그림을 보면 A와 B, C와 D가 같은 수준에 있다는 것을 확실히 알 수 있으므로, 우리는 이 이론에 따라 Deep 계층적 개념을 설계합니다. 그런 다음 노드 유형을 구별하면 다음을 얻을 수 있습니다. "/>🎜🎜리프 노드(위 그림의 녹색 부분)로서 계산 계산 관계를 보면 마주치면 먼저 계산해야 하므로 깊이 우선순위의 경우 다음과 같이 하면 됩니다. 리프가 아닌 노드, 즉 위 그림의 파란색 노드 부분을 고려하면 우선순위를 계산하는 개념을 깊이라는 표현으로 변환할 수 있습니다. 🎜🎜다시 위 그림을 살펴보겠습니다. Deep1의 관계는 Deep2에서 A와 B, C와 D라는 두 표현식으로 계산한 결과 사이의 AND 또는 관계입니다. A와 B는 G1이고 C와 D는 G2입니다. . 관계 노드 연결에는 두 가지 유형이 있음을 발견했습니다. 하나는 조건조건이고 다른 하나는 그룹그룹🎜🎜🎜🎜이 시점에서 이 클래스의 프로토타입이 기본적으로 결정됩니다. 이 클래스에는 관계(관계), 판단 필드(필드), 연산자(연산자), 연산 값 (값), >Type(Type), Depth(Deep) 🎜🎜그런데 위 분석에서는 문제가 있어서 표현식을 트리로 변환하고 이제 복원을 하려고 합니다. it 이므로 다음 표현식 중 하나를 한눈에 얻을 수 있습니다. 🎜🎜
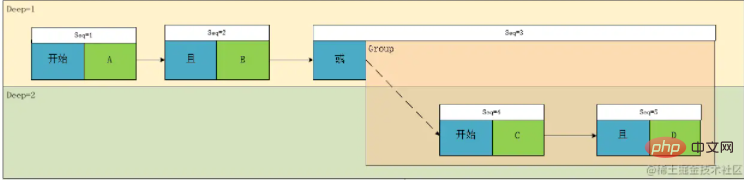
🎜🎜이 그림을 보면 A와 B, C와 D가 같은 수준에 있다는 것을 확실히 알 수 있으므로, 우리는 이 이론에 따라 Deep 계층적 개념을 설계합니다. 그런 다음 노드 유형을 구별하면 다음을 얻을 수 있습니다. "/>🎜🎜리프 노드(위 그림의 녹색 부분)로서 계산 계산 관계를 보면 마주치면 먼저 계산해야 하므로 깊이 우선순위의 경우 다음과 같이 하면 됩니다. 리프가 아닌 노드, 즉 위 그림의 파란색 노드 부분을 고려하면 우선순위를 계산하는 개념을 깊이라는 표현으로 변환할 수 있습니다. 🎜🎜다시 위 그림을 살펴보겠습니다. Deep1의 관계는 Deep2에서 A와 B, C와 D라는 두 표현식으로 계산한 결과 사이의 AND 또는 관계입니다. A와 B는 G1이고 C와 D는 G2입니다. . 관계 노드 연결에는 두 가지 유형이 있음을 발견했습니다. 하나는 조건조건이고 다른 하나는 그룹그룹🎜🎜🎜🎜이 시점에서 이 클래스의 프로토타입이 기본적으로 결정됩니다. 이 클래스에는 관계(관계), 판단 필드(필드), 연산자(연산자), 연산 값 (값), >Type(Type), Depth(Deep) 🎜🎜그런데 위 분석에서는 문제가 있어서 표현식을 트리로 변환하고 이제 복원을 하려고 합니다. it 이므로 다음 표현식 중 하나를 한눈에 얻을 수 있습니다. 🎜🎜result=(A && B)||(C && D)🎜분명히 원래 표현식과 일치하지 않습니다. 이는 위 표현식의 계산 순서만 기록할 수 있지만 표현식을 구문 분석하는 과정에서 이 표현식을 완전히 정확하게 표현할 수 없기 때문입니다. 깊이가 있지만 타이밍 관계도 있습니다. 즉, 왼쪽에서 오른쪽으로 순차적으로 표현됩니다. 이때 G1의 내용은 실제로 원래 표현의 깊이가 2가 아닌 1입니다. 그런 다음 개념을 소개합니다. 시퀀스 번호를 사용하면 트리가 유향 그래프가 됩니다.
이 그래프에 따르면 다음 표현식만 복원할 수 있습니다. result= A && B ||(C && D) . result= A && B ||(C && D)。
好了,我们分析了半天,原理说完了,回到最初始的问题:前后端怎么实现?对着上图想象一下,貌似还是无法处理,因为这个结构还是太复杂了。对于前端,数据最好是方便遍历的,对于后端,数据最好是方便处理的,于是这时候我们需要将上面这个图转换成一个数组。
实现方式
上面说到了需要一个数组的结构,我们具体分析一下这个部分
我们发现作为叶子节点,可以始终优先计算,所以我们可以将其压缩,并将关系放置在其中一个表达式中形成 ^A -> &&B或 A&& -> B$ 的形式,这里我用正则的开始(^) 和结束($) 表示了一下开始 和 结束 的概念,这里为了与产品原型保持一致我们用第一种方式,即关系符号表示与前一个元素的关系,于是我们再分析一下:
再对序号进行改造:
于是我们得到最终的数据结构:
@Data
@AllArgsConstructor
@NoArgsConstructor
@Accessors(chain = true)
public class ExpressDto {
/**
* 序号
*/
private Integer seq;
/**
* 深度(运算优先级)
*/
private Integer deep;
/**
* 关系运算符
*/
private String relation;
/**
* 类型
*/
private String type;
/**
* 运算条件
*/
private String field;
/**
* 逻辑运算符
*/
private String operator;
/**
* 运算值
*/
private String values;
/**
* 运算结果
*/
private Boolean result;
}现在数据结构终于完成,既方便存储,又(相对)方便前台展示,现在构造一个稍微复杂的表达式
A &&(( B || C )|| (D && E)) && F
 우리는 리프 노드로서 항상 먼저 계산될 수 있다는 것을 알았으므로 이를 압축하고
우리는 리프 노드로서 항상 먼저 계산될 수 있다는 것을 알았으므로 이를 압축하고 ^A를 형성하는 표현식 중 하나에 관계를 배치할 수 있습니다. > &&B 또는 A&& -> B$, 여기서는 일반 start(^) 및 end($)를 사용합니다. 표현하다 시작과 끝의 개념을 살펴보고 제품 프로토타입과의 일관성을 유지하기 위해 첫 번째 방법인 관계 기호를 사용하여 이전 요소와의 관계를 표현하므로 다시 분석합니다.
일련번호 개혁:
그래서 우리는 최종 데이터 구조를 얻습니다: [
{"seq":1,"deep":1,relation:"BEGIN","type":"CONDITION","field"="A"...},
{"seq":2,"deep":1,relation:"AND","type":"GROUP","field":""...},
{"seq":3,"deep":2,relation:"BEGIN","type":"GROUP","field":""...},
{"seq":4,"deep":3,relation:"BEGIN","type":"CONDITION","field":"B"...},
{"seq":5,"deep":3,relation:"OR","type":"CONDITION","field":"C"...},
{"seq":6,"deep":2,relation:"OR","type":"GROUP","field":""...},
{"seq":7,"deep":3,relation:"BEGIN","type":"CONDITION","field":"D"...},
{"seq":8,"deep":3,relation:"AND","type":"CONDITION","field":"E"...},
{"seq":9,"deep":1,relation:"AND","type":"CONDITION","field":"F"...}
]이제 드디어 완성된 데이터 구조로 저장도 편리하고 (상대적으로) 프론트엔드 디스플레이도 편리하니 이제 조금 복잡한 표현식을 구성해 보세요
A &&(( B || C )|| (D && E) ) && F배열 객체로 변경하고 시작합니다. BEGIN으로 표시되며, 표현식 유형은 CONDITION으로, 그룹은 GROUP으로 표시됩니다. //关系 栈 Deque<String> relationStack=new LinkedList(); //结果栈 Deque<Boolean> resultStack=new LinkedList(); // 当前深度 Integer nowDeep=1;이제 마지막 질문이 남았습니다. 이 json을 통해 데이터를 필터링하는 방법배열 객체의 본질은 여전히 중위 표현식이므로 그 본질은 여전히 중위 표현식의 분석, 분석 원리에 대한 것입니다. 여기서는 별로 소개하지 않고 간단히 말해서 괄호(여기서는 그룹이라고 함)에 따라 데이터 스택과 기호 스택을 통과합니다. 더 알고 싶다면 다음 기사를 통해 검토할 수 있습니다.
그래서 우리는 세 가지 변수를 정의합니다.
for (ExpressDto expressDto:list) {
if(!StringUtils.equals(expressDto.getType(),"GROUP")){
//TODO 进行具体单个表达式计算并获取结果
resultStack.push(expressDto.getResult());
// 将关系放入栈中
relationStack.push(expressDto.getRelation());
if(deep==0 && resultStack.size()>1){ //由于已处理小于0的deep,当前deep理论上是>=0的,0表示同等级,需要立即运算
relationOperator(relationStack, resultStack);
}
}else{
// 将关系放入栈中
relationStack.push(expressDto.getRelation());
}
}
private void relationOperator(Deque<String> relationStack, Deque<Boolean> resultStack) {
Boolean lastResult= resultStack.pop();
Boolean firstResult= resultStack.pop();
String relation=relationStack.pop();
if(StringUtils.equals(relation,"AND")){
resultStack.push(firstResult&& lastResult) ;
return;
}
if(StringUtils.equals(relation,"OR")){
resultStack.push( firstResult|| lastResult);
return;
}else{
throw new RuntimeException("表达式解析异常:关系表达式错误");
}
}배열을 순회하여 관계와 결과를 스택에 푸시합니다. 우선 순위 계산이 필요하다고 판단되면 결과 스택에서 두 값을 꺼내고 관계 스택에서 관계 연산자를 꺼냅니다. , 계산 후 다시 스택에 푸시하고 다음 시간을 기다립니다.
/**
* 处理层级遗留元素
*
* @param relationStack
* @param resultStack
*/
private void computeBeforeEndGroup(Deque<String> relationStack, Deque<Boolean> resultStack) {
boolean isBeginSymbol=StringUtils.equals(relationStack.peek(),"BEGIN");//防止group中仅有一个判断条件
while(!isBeginSymbol){//上一个运算符非BEGIN,说明该group中还有运算需要优先处理,正常这里应该仅循环一次
relationOperator(relationStack, resultStack);
isBeginSymbol=StringUtils.equals(relationStack.peek(),"BEGIN");
}
if(isBeginSymbol){
relationStack.pop();//该优先级处理完毕,将BEGIN运算符弹出
}
}계산할 때 주의해야 할 경계 사항에 대해 이야기해 보겠습니다.
1. 우선 동일한 레벨에는 두 가지 유형의 관계만 있습니다. and, or, 그리고 이 두 가지 유형의 계산 우선순위는 동일합니다. 따라서 동일한 Deep에서 왼쪽에서 오른쪽으로 순회하고 계산하면 됩니다. 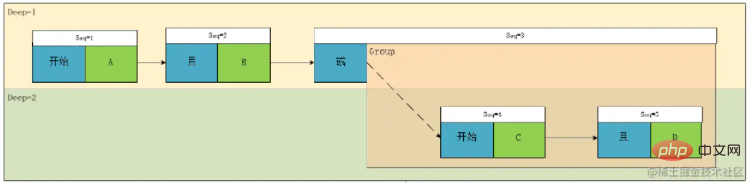
/**
* 表达式解析器
* 表达式规则:
* 关系relation属性有:BEGIN、AND、OR 三种
* 表达式类型 Type 属性有:GROUP、CONDITION 两种
* 深度 deep 属性 根节点为 1,每增加一个括号(GROUP)deep+1,括号结束deep-1
* 序号req:初始值为1,往后依次递增,用于防止表达式解析顺序错误
* exp1:表达式:A &&(( B || C )|| (D && E)) && F
* 分解对象:
* [
* {"seq":1,"deep":1,relation:"BEGIN","type":"CONDITION","field"="A"...},
* {"seq":2,"deep":1,relation:"AND","type":"GROUP","field":""...},
* {"seq":3,"deep":2,relation:"BEGIN","type":"GROUP","field":""...},
* {"seq":4,"deep":3,relation:"BEGIN","type":"CONDITION","field":"B"...},
* {"seq":5,"deep":3,relation:"OR","type":"CONDITION","field":"C"...},
* {"seq":6,"deep":2,relation:"OR","type":"GROUP","field":""...},
* {"seq":7,"deep":3,relation:"BEGIN","type":"CONDITION","field":"D"...},
* {"seq":8,"deep":3,relation:"AND","type":"CONDITION","field":"E"...},
* {"seq":9,"deep":1,relation:"AND","type":"CONDITION","field":"F"...}
* ]
*
* exp2:(A || B && C)||(D && E && F)
* [
* {"seq":1,"deep":1,relation:"BEGIN","type":"GROUP","field":""...},
* {"seq":2,"deep":2,relation:"BEGIN","type":"CONDITION","field":"A"...},
* {"seq":3,"deep":2,relation:"OR","type":"CONDITION","field":"B"...},
* {"seq":4,"deep":2,relation:"AND","type":"CONDITION","field":"C"...},
* {"seq":5,"deep":1,relation:"OR","type":"GROUP","field":""...},
* {"seq":6,"deep":2,relation:"BEGIN","type":"CONDITION","field":"D"...},
* {"seq":7,"deep":2,relation:"AND","type":"CONDITION","field":"E"...},
* {"seq":8,"deep":2,relation:"AND","type":"CONDITION","field":"F"...}
* ]
*
*
* @param list
* @return
*/
public boolean expressProcessor(Listlist){
//关系 栈
Deque relationStack=new LinkedList();
//结果栈
Deque resultStack=new LinkedList();
// 当前深度
Integer nowDeep=1;
Integer seq=0;
for (ExpressDto expressDto:list) {
// 顺序检测,防止顺序错误
int checkReq=expressDto.getSeq()-seq;
if(checkReq!=1){
throw new RuntimeException("表达式异常:解析顺序异常");
}
seq=expressDto.getSeq();
//计算深度(计算优先级),判断当前逻辑是否需要处理括号
int deep=expressDto.getDeep()-nowDeep;
// 赋予当前深度
nowDeep=expressDto.getDeep();
//deep 减小,说明有括号结束,需要处理括号到对应的层级,deep减少数量等于组(")")结束的数量
while(deep++ < 0){
computeBeforeEndGroup(relationStack, resultStack);
}
if(!StringUtils.equals(expressDto.getType(),"GROUP")){
//TODO 进行具体单个表达式计算并获取结果
resultStack.push(expressDto.getResult());
// 将关系放入栈中
relationStack.push(expressDto.getRelation());
if(deep==0 && resultStack.size()>1){ //由于已处理小于0的deep,当前deep理论上是>=0的,0表示同等级,需要立即运算
relationOperator(relationStack, resultStack);
}
}else{
// 将关系放入栈中
relationStack.push(expressDto.getRelation());
}
}
//遍历完毕,处理栈中未进行运算的节点
while(nowDeep-- > 0){ // 这里使用 nowdeep>0 的原因是最后deep=1的关系表达式也需要进行处理
computeBeforeEndGroup(relationStack, resultStack);
}
if(resultStack.size()!=1){
throw new RuntimeException("表达式解析异常:解析结果数量异常解析数量:"+resultStack.size());
}
return resultStack.pop();
}
/**
* 处理层级遗留元素
*
* @param relationStack
* @param resultStack
*/
private void computeBeforeEndGroup(Deque<String> relationStack, Deque<Boolean> resultStack) {
boolean isBeginSymbol=StringUtils.equals(relationStack.peek(),"BEGIN");//防止group中仅有一个判断条件
while(!isBeginSymbol){//上一个运算符非BEGIN,说明该group中还有运算需要优先处理,正常这里应该仅循环一次
relationOperator(relationStack, resultStack);
isBeginSymbol=StringUtils.equals(relationStack.peek(),"BEGIN");
}
if(isBeginSymbol){
relationStack.pop();//该优先级处理完毕,将BEGIN运算符弹出
}
}
/**
* 关系运算处理
* @param relationStack
* @param resultStack
*/
private void relationOperator(Deque relationStack, Deque resultStack) {
Boolean lastResult= resultStack.pop();
Boolean firstResult= resultStack.pop();
String relation=relationStack.pop();
if(StringUtils.equals(relation,"AND")){
resultStack.push(firstResult&& lastResult) ;
return;
}
if(StringUtils.equals(relation,"OR")){
resultStack.push( firstResult|| lastResult);
return;
}else{
throw new RuntimeException("表达式解析异常:关系表达式错误");
}
} 🎜4. 순회 끝에서 마지막 요소 Deep이 1이 아닌 것이 발견되면 이때 괄호의 끝도 처리해야 함을 의미합니다🎜 🎜마지막으로 전체 코드는 다음과 같습니다. 🎜 /**
* 表达式:A
*/
@Test
public void expTest0(){
ExpressDto E1=new ExpressDto().setDeep(1).setResult(false).setSeq(1).setType("CONDITION").setField("A").setRelation("BEGIN");
List<ExpressDto> list = new ArrayList();
list.add(E1);
boolean re=expressProcessor(list);
Assertions.assertFalse(re);
}
/**
* 表达式:(A && B)||(C || D)
*/
@Test
public void expTest1(){
ExpressDto E1=new ExpressDto().setDeep(1).setSeq(1).setType("GROUP").setRelation("BEGIN");
ExpressDto E2=new ExpressDto().setDeep(2).setResult(true).setSeq(2).setType("Condition").setField("A").setRelation("BEGIN");
ExpressDto E3=new ExpressDto().setDeep(2).setResult(false).setSeq(3).setType("Condition").setField("B").setRelation("AND");
ExpressDto E4=new ExpressDto().setDeep(1).setSeq(4).setType("GROUP").setRelation("OR");
ExpressDto E5=new ExpressDto().setDeep(2).setResult(true).setSeq(5).setType("Condition").setField("C").setRelation("BEGIN");
ExpressDto E6=new ExpressDto().setDeep(2).setResult(false).setSeq(6).setType("Condition").setField("D").setRelation("OR");
List<ExpressDto> list = new ArrayList();
list.add(E1);
list.add(E2);
list.add(E3);
list.add(E4);
list.add(E5);
list.add(E6);
boolean re=expressProcessor(list);
Assertions.assertTrue(re);
}
/**
* 表达式:A && (B || C && D)
*/
@Test
public void expTest2(){
ExpressDto E1=new ExpressDto().setDeep(1).setResult(true).setSeq(1).setType("Condition").setField("A").setRelation("BEGIN");
ExpressDto E2=new ExpressDto().setDeep(1).setSeq(2).setType("GROUP").setRelation("AND");
ExpressDto E3=new ExpressDto().setDeep(2).setResult(false).setSeq(3).setType("Condition").setField("B").setRelation("BEGIN");
ExpressDto E4=new ExpressDto().setDeep(2).setResult(false).setSeq(4).setType("Condition").setField("C").setRelation("OR");
ExpressDto E5=new ExpressDto().setDeep(2).setResult(true).setSeq(5).setType("Condition").setField("D").setRelation("AND");
List<ExpressDto> list = new ArrayList();
list.add(E1);
list.add(E2);
list.add(E3);
list.add(E4);
list.add(E5);
boolean re=expressProcessor(list);
Assertions.assertFalse(re);
E4.setResult(true);
list.set(3,E4);
re=expressProcessor(list);
Assertions.assertTrue(re);
E1.setResult(false);
list.set(0,E1);
re=expressProcessor(list);
Assertions.assertFalse(re);
}
@Test
public void expTest3(){
ExpressDto E1=new ExpressDto().setDeep(1).setResult(true).setSeq(1).setType("Condition").setField("A").setRelation("BEGIN");
ExpressDto E2=new ExpressDto().setDeep(1).setSeq(2).setType("GROUP").setRelation("OR");
ExpressDto E3=new ExpressDto().setDeep(2).setResult(true).setSeq(3).setType("Condition").setField("B").setRelation("BEGIN");
ExpressDto E4=new ExpressDto().setDeep(2).setSeq(4).setType("GROUP").setRelation("AND");
ExpressDto E5=new ExpressDto().setDeep(3).setResult(true).setSeq(5).setType("Condition").setField("C").setRelation("BEGIN");
ExpressDto E6=new ExpressDto().setDeep(3).setResult(false).setSeq(6).setType("Condition").setField("D").setRelation("OR");
List<ExpressDto> list = new ArrayList();
list.add(E1);
list.add(E2);
list.add(E3);
list.add(E4);
list.add(E5);
list.add(E6);
boolean re=expressProcessor(list);
Assertions.assertTrue(re);
}
/**
* 表达式:A &&(( B || C )|| (D && E))
*/
@Test
public void expTest4(){
ExpressDto E1=new ExpressDto().setDeep(1).setSeq(1).setType("CONDITION").setResult(true).setField("A").setRelation("BEGIN");
ExpressDto E2=new ExpressDto().setDeep(1).setSeq(2).setType("GROUP").setRelation("AND");
ExpressDto E3=new ExpressDto().setDeep(2).setSeq(3).setType("GROUP").setRelation("BEGIN");
ExpressDto E4=new ExpressDto().setDeep(3).setSeq(4).setType("CONDITION").setResult(true).setField("B").setRelation("BEGIN");
ExpressDto E5=new ExpressDto().setDeep(3).setSeq(5).setType("CONDITION").setResult(true).setField("C").setRelation("OR");
ExpressDto E6=new ExpressDto().setDeep(2).setSeq(6).setType("GROUP").setRelation("OR");
ExpressDto E7=new ExpressDto().setDeep(3).setSeq(7).setType("CONDITION").setResult(false).setField("D").setRelation("BEGIN");
ExpressDto E8=new ExpressDto().setDeep(3).setSeq(8).setType("CONDITION").setResult(false).setField("E").setRelation("AND");
List<ExpressDto> list = new ArrayList();
list.add(E1);
list.add(E2);
list.add(E3);
list.add(E4);
list.add(E5);
list.add(E6);
list.add(E7);
list.add(E8);
boolean re=expressProcessor(list);
Assertions.assertTrue(re);
}
/**
* 表达式:(A)
*/
@Test
public void expTest5(){
ExpressDto E1=new ExpressDto().setDeep(1).setSeq(1).setType("GROUP").setRelation("BEGIN");
ExpressDto E2=new ExpressDto().setDeep(2).setResult(true).setSeq(2).setType("Condition").setField("A").setRelation("BEGIN");
List<ExpressDto> list = new ArrayList();
list.add(E1);
list.add(E2);
boolean re=expressProcessor(list);
Assertions.assertTrue(re);
E2.setResult(false);
list.set(1,E2);
Assertions.assertFalse(expressProcessor(list));
}🎜간단히 몇 가지 테스트 사례를 작성했습니다.🎜rrreee🎜테스트 결과:🎜🎜🎜🎜🎜마지막에 작성되었습니다🎜🎜이 시점에서 표현식 분석이 완료되었습니다. 이 사진을 다시 보세요:🎜🎜🎜🎜실제로 Seq3의 기능은 그룹의 시작을 식별하고 그룹과 동일한 수준의 다른 요소 간의 연관성을 기록하는 것임을 알 수 있습니다. 실제로 여기에서 최적화가 수행될 수 있습니다. 그룹의 시작 첫 번째 노드의 사전 연결 관계는 Begin, Deep+1이어야 합니다. 실제로 이 노드에 그룹의 연결을 배치한 다음 Deep의 증가 또는 감소를 통해서만 그룹의 관계를 제어하는 것을 고려할 수 있습니다. 이런식으로 표현형이나 그룹형의 이 필드는 필수이고 그에 따라 배열 길이도 줄어들겠지만 개인적으로는 이해하기가 좀 더 번거로울 것 같습니다. 다음은 변환에 대한 일반적인 아이디어이며 코드는 공개되지 않습니다.
- deep = 1의 차이로 판단하기 위해 코드에서 Type="GROUP"에 대한 판단을 변경합니다
- 깊이 판단 스택 논리 수정
- In 관계 기호를 저장할 때 동일한 깊이를 가진 레거시 요소를 처리할 때 관계 기호에 해당하는 깊이도 저장해야 합니다. 즉, 방법에서 원래 방법은 Begin 요소를 사용하는 것입니다. 이제 그룹이 처리되었는지 구별해야 합니다. 이제 다음과 같이 변경해야 합니다. 기호의 깊이가 현재 깊이와 동일한지 확인하고 BEGIN 요소에 대한 팝업 로직을 삭제하세요
computeBeforeEndGroup()권장 학습: "
위 내용은 Java 기반의 복잡한 관계식 필터 구현에 대한 예제 소개의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!