
집 >데이터 베이스 >MySQL 튜토리얼 >MySQL 인덱스의 최하위 레이어와 최적화에 대해 이야기해 보겠습니다.
MySQL 인덱스의 최하위 레이어와 최적화에 대해 이야기해 보겠습니다.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2022-02-14 18:47:541943검색
이 글은 mysql의 기본 인덱스 및 최적화에 대한 관련 지식을 제공합니다. mysql의 인덱싱에 대한 지식 포인트를 정리해 보겠습니다. 모두에게 도움이 되기를 바랍니다.

Mysql 인덱스
최근 많은 웹사이트에서 인덱싱에 대해 읽었는데, 설명이 다양하지만, 일부 개념은 매우 모호합니다.
1. 먼저 인덱스가 무엇인지, 인덱스를 사용해야 하는 이유에 대해 이야기해 보겠습니다.
인덱스는 인덱스를 사용하지 않고 전체 레코드를 읽어야 합니다. 첫 번째 레코드부터 시작하여 해당 행을 찾을 때까지 테이블이 클수록 데이터를 쿼리하는 데 더 많은 시간이 걸립니다. 모든 데이터를 볼 필요 없이 이렇게 하면 많은 시간이 절약됩니다.
2. 인덱스 종류는
1.hash 인덱스
2.bTree
3으로 나누어집니다. 해시 인덱스와 bTree 인덱스를 간단히 분석해 보겠습니다.
1. 해시 테이블은 키-값 형식으로 데이터를 저장하는 구조입니다. 찾으려는 키, 즉 키를 입력하기만 하면 해당 값인 값을 찾을 수 있습니다. 해싱의 개념은 매우 간단합니다. 배열에 값을 넣고 해시 함수를 사용하여 키를 특정 위치로 변환한 다음 배열의 이 위치에 값을 넣습니다.
필수적으로 여러 키 값은 해시 함수로 변환된 후 동일한 값을 갖게 됩니다. 이 상황을 처리하는 한 가지 방법은 연결 목록을 꺼내는 것입니다.
2. bTree에 관해 말하자면 이진 트리를 언급해야 합니다. 이진 트리는 이진 검색 트리, 균형 이진 트리 등과 같은 여러 유형으로 나뉩니다. 물론 하이라이트인 빨간색과 검은색 나무도 있습니다.
1) 이진 검색 트리의 특징은 다음과 같습니다. 상위 노드의 왼쪽 하위 트리에 있는 모든 노드의 값은 상위 노드의 값보다 작습니다. 오른쪽 하위 트리에 있는 모든 노드의 값은 상위 노드의 값보다 큽니다. 이진 검색 트리를 설명하기 위해 그림을 예로 들어 보겠습니다.
| ID | name |
|---|---|
| 5 | Zhang Wu |
| 6 | Zhang 치 |
| 2 | 张이 |
| 1 | Zhang Yi |
| 4 | Zhang Si |
| 3 | Zhang San |
|
5) B+ 트리: 위에서 언급했듯이 BTree는 트리의 높이를 제어하므로 Mysql의 인덱싱 요구 사항을 충족할 수 있습니다. 그러나 결국 Mysq 인덱스 구현은 BTree가 아니라 B+ 트리입니다. 변환 후 B+ 트리가 얻어졌는데, 이는 B+ 트리가 B 트리의 업그레이드 버전으로 이해될 수도 있습니다. 이 그림에서 볼 수 있듯이 우리의 리프가 아닌 노드는 데이터가 아닌 인덱스만 저장하고 리프 노드는 포인터로 연결됩니다. B 트리의 리프 노드와 리프가 아닌 노드 모두 인덱스와 데이터를 저장하며 리프 노드의 포인터는 비어 있습니다. B+ 트리는 리프 노드가 아닌 노드에 더 많은 인덱스를 저장할 수 있도록 데이터를 리프 노드에 배치합니다. , 매번 디스크 IO에서 더 많은 인덱스를 얻을 수도 있습니다. 바이두와 많은 블로그에 그려진 B+ 트리가 잘못되었으므로 함정을 피하십시오. 4. 인덱스 분류1. 인덱스의 저장 연관에 따른 분류: 크게 두 가지 카테고리로 나뉜다 1.1) MySQL에 일반적으로 사용되는 두 가지 스토리지 엔진인 MyISAM과 InnoDB가 있다는 것은 누구나 알고 있지만 실제로 두 스토리지 엔진의 기본 데이터 스토리지 구조를 이해하셨나요? 2. 기능별로 분류 : 크게 5가지로 구분 3. 2.2에서 일반 인덱스에는 테이블 반환 작업이 필요하다고 언급했는데, 없는 걸까요? 테이블을 반환해야 합니까? 일반 인덱스의 경우 대답은 '예'입니다. 특정 쿼리에서는 인덱스가 쿼리 요구 사항을 충족합니다. 이때 테이블로 돌아갈 필요가 없습니다. 예: 다음은 이 테이블의 초기화 문입니다. mysql> create table T ( ID int primary key, k int NOT NULL DEFAULT 0, s varchar(16) NOT NULL DEFAULT '', index k(k)) engine=InnoDB; insert into T values(100,1, 'aa'),(200,2,'bb'), (300,3,'cc'),(500,5,'ee'),(600,6,'ff'),(700,7,'gg'); 위 테이블 T에서 select * from T(여기서 k는 3과 5 사이)를 실행하면 몇 개의 트리 검색 작업을 수행해야 하며 몇 개의 행을 스캔하게 됩니까? 이 프로세스에서 는 테이블 백 이라고 부르는 기본 키 인덱스 트리 검색 프로세스로 돌아갑니다. 이 쿼리 프로세스는 k 인덱스 트리의 3개 레코드를 읽고(1, 3, 5단계) 테이블을 두 번(2, 4단계) 반환하는 것을 볼 수 있습니다. 이 예에서는 쿼리 결과에 필요한 데이터가 기본 키 인덱스에만 있으므로 테이블로 반환해야 합니다. 실행된 문장이 T에서 ID를 선택하는 경우(여기서 k는 3~5 사이), 이때 ID 값만 확인하면 되며, ID 값은 이미 k 인덱스 트리에 있으므로 쿼리 결과는 다음과 같습니다. Table을 반납하지 않고 바로 제공 가능합니다. 즉, 이 쿼리에서 인덱스 k는 쿼리 요구 사항을 "covered"하며 이를 커버링 인덱스라고 합니다. InnoDB에서는 테이블이 기본 키 순서에 따라 인덱스 형태로 저장됩니다. 이렇게 저장된 테이블을 인덱스 구성 테이블이라고 합니다. 그리고 앞서 언급했듯이 InnoDB는 B+ 트리 인덱스 모델을 사용하므로 데이터는 B+ 트리에 저장됩니다. 각 인덱스는 InnoDB의 B+ 트리에 해당합니다. 5. 인덱스 최적화1. 위는 인덱스의 기본 개념, 분류 및 기본 구조 관련 지식을 설명합니다. 인덱스 최적화 관련 지식에 대해 이야기해 보겠습니다.1.) 결합된 인덱스 중 하나의 열에만 null 값이 포함되면 인덱스가 무효화됩니다 2. 인덱스 최적화에 대한 설명다음과 같이 5가지 속성을 가진 새 직원 테이블을 생성합니다. create table employees(
id int primary key auto_increment comment '主键自增',
name varchar(30) not null default '' comment'名字',
age int not null default 1 comment '年龄',
id_card varchar(40) not null default '' comment '身份证号',
position varchar(40) not null default '' comment '位置'
);
-- 创建联合索引
create index name_index on employees (name,age,position);
-- 插入一条数据
insert into employees(name,age,id_card,position) values('张三',15,
'201124199011035321','北京');
-- 下面以10条sql测试,注意建立的联合索引顺序是 name,age,position 1.explain select * from employees where age=15 and position='北京' and name='张三'; 2.explain select * from employees where name='张三' and age=15 and position='北京'; 3.explain select * from employees where age=15 and name='张三'; 4.explain select * from employees where position='北京' and name='张三'; 5.explain select * from employees where position='北京' and age=15; 6.explain select * from employees where position='北京' and age>15 and name='张三'; 7.explain select * from employees where position='北京'; 8.explain select * from employees where age=15; 9.explain select * from employees where name='张三'; 10.explain select * from employees where name != '张三'; 以上10条sql有哪些是索引失效,有哪些是索引没有失效的呢? 相信同学们已经有了答案,但是答案对不对呢,下面我们一起分析下。 首先说第1条,查询条件把3个索引全部用上了,但是索引的顺序有变化,由name,age,position变成 了age,position,name,想到这里肯定有很多同学给出的答案就是索引失效,但是事实证明这个结果 是错的,索引生效,肯定有很多同学疑惑,为什么呢,这条sql不满足最左原则法则呀,这就要涉及到sql 的执行流程了,这里博主简单说下,sql执行有1个优化器的过程,优化器的作用之一就是索引的选择优化, 所以优化器帮我们把索引的顺序变成正确的了,所以索引生效。 下面是第1条按照索引顺序sql和第2条没有按照索引顺序sql的执行结果。 执行结果入下图:可以发现全部生效。 첫 번째 sql 유형의 값은 ref이고 바이트는 288이며 ref에는 3개의 const가 있으며 모두 유효합니다.
想学习sql的执行流程的可以看博主的另一篇关于sql执行流程的文章哦。 有的同学有疑问了,那最左原则没有用了吗? 答案:有用的。 现在我们说下第3、4、5条sql 第3条: explain select * from employees where age=15 and name='张三'; sql在执行的时候,优化器替我们把索引的顺序优化了,由 age -> name 变成 name -> age,这时 索引是生效的。 第4条: explain select * from employees where position='北京' and name='张三'; 索引顺序优化为name - > position,但是这时索引只有name索引生效,position没有生效,因为我 们建立的索引顺序是 name -> age - > position,你会发现跳过了age,索引本质也是一棵树,少 了一个节点,下面的索引当然不会生效了,这就没有满足最左原则法则。 第5条: explain select * from employees where position='北京' and age=15; 这就和第4条sql一样的道理了,第一个索引都不见了,后面的不可能生效。 执行结果如下: 세 번째 SQL 유형의 값은 ref이고 바이트는 126이며 ref에는 2개의 const가 있으며 모두 유효하다는 것을 알 수 있습니다.
下面说第6条sql,剩下的sql都是和之前的sql一样的道理。 explain select * from employees where position='北京' and age>15 and name='张三'; 这条sql我们会发现,把索引字段全部使用了并且当作条件查询,不一样的是age是范围查找,优化器替我 们把索引顺序优化成 name -> age - > position ,按照我们索引优化第2条:在列上做计算索引失效,范围之后的索引全部失效,想必答案同学们都知道了。 执行结果如下: 6번째 sql은 126바이트에 불과하고 type의 값은 range, range search이며 이름과 나이 인덱스만 적용된다.
추천 학습: mysql 비디오 튜토리얼 |
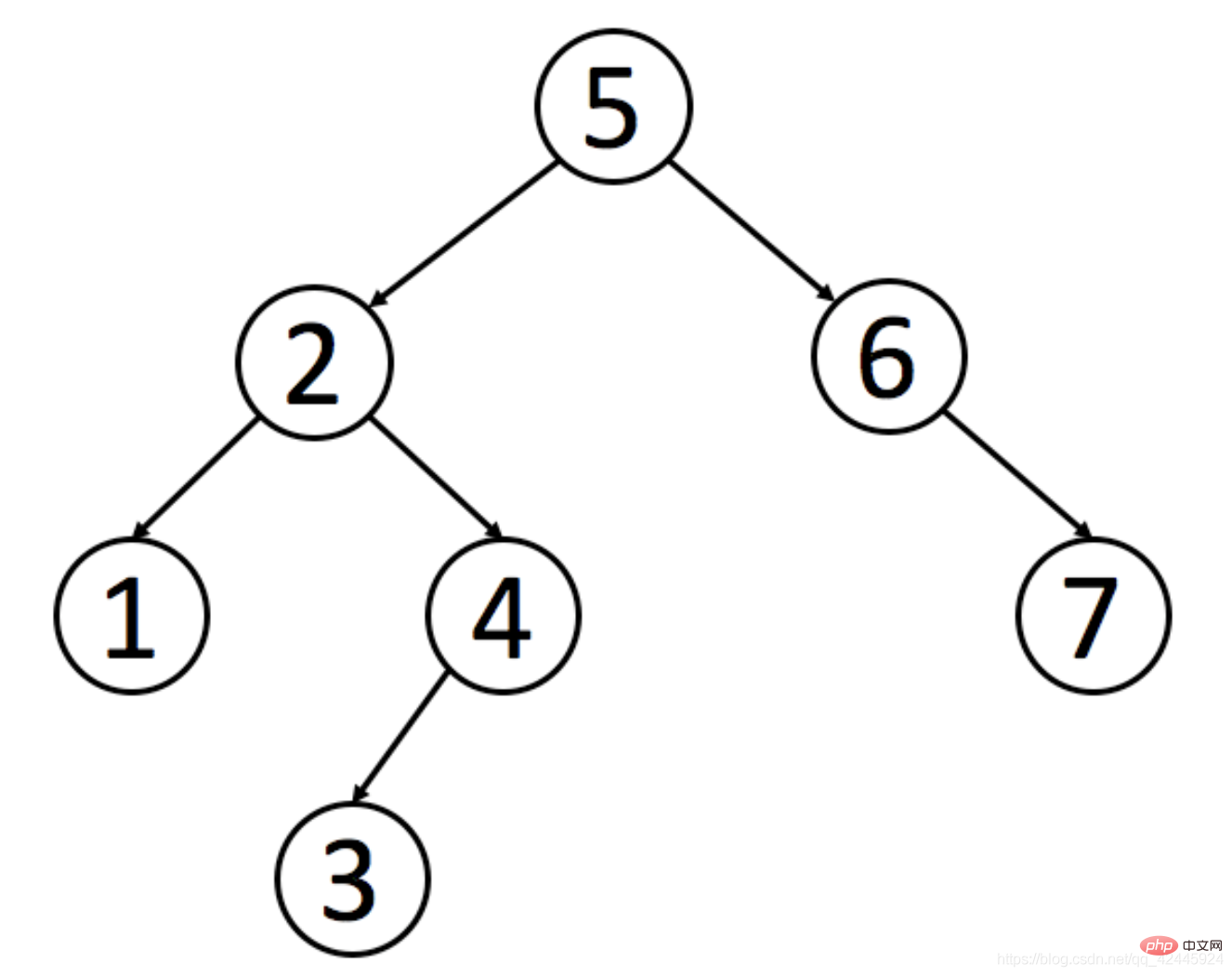 Zhang San을 찾는 요구 사항이 있습니다. 이진 검색 트리를 사용하지 않으면 7번 검색하면 됩니다. 이진 검색 트리를 사용하면 원하는 값을 찾으려면 4번만 검색하면 됩니다.
Zhang San을 찾는 요구 사항이 있습니다. 이진 검색 트리를 사용하지 않으면 7번 검색하면 됩니다. 이진 검색 트리를 사용하면 원하는 값을 찾으려면 4번만 검색하면 됩니다. 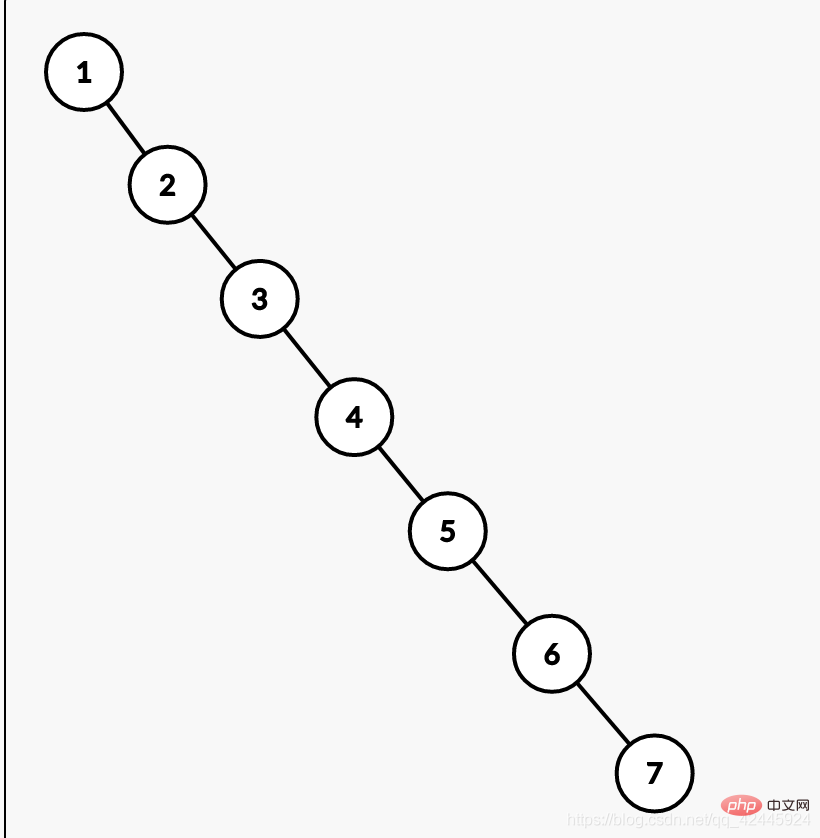
 3) 레드-블랙 트리: 레드-블랙 트리는 균형 잡힌 이진 트리보다 우수한 트리라고 이해할 수 있습니다. 레드-블랙 트리는 "완전한 균형"을 추구하지 않습니다. 균형 요구 사항을 충족하여 회전 요구 사항을 줄여 성능을 향상시킵니다. 또한, 설계상 불균형은 3회전 이내에 해결될 수 있습니다. 레드-블랙 트리에서는 알고리즘 시간 복잡도가 AVL과 동일하며 통계 성능으로 인해 AVL 트리가 더 높아집니다. 따라서 균형 이진 트리와 비교하면 레드-블랙 트리는 엄밀한 의미에서는 균형 이진 트리가 아니다. 레드-블랙 트리의 삽입 및 삭제 효율은 균형 이진 트리에 비해 상대적으로 낮다. 그러나 둘 사이의 쿼리 효율성 차이는 비교하면 기본적으로 무시할 수 있습니다. 레드-블랙 트리의 특징은 다음과 같습니다.
3) 레드-블랙 트리: 레드-블랙 트리는 균형 잡힌 이진 트리보다 우수한 트리라고 이해할 수 있습니다. 레드-블랙 트리는 "완전한 균형"을 추구하지 않습니다. 균형 요구 사항을 충족하여 회전 요구 사항을 줄여 성능을 향상시킵니다. 또한, 설계상 불균형은 3회전 이내에 해결될 수 있습니다. 레드-블랙 트리에서는 알고리즘 시간 복잡도가 AVL과 동일하며 통계 성능으로 인해 AVL 트리가 더 높아집니다. 따라서 균형 이진 트리와 비교하면 레드-블랙 트리는 엄밀한 의미에서는 균형 이진 트리가 아니다. 레드-블랙 트리의 삽입 및 삭제 효율은 균형 이진 트리에 비해 상대적으로 낮다. 그러나 둘 사이의 쿼리 효율성 차이는 비교하면 기본적으로 무시할 수 있습니다. 레드-블랙 트리의 특징은 다음과 같습니다. 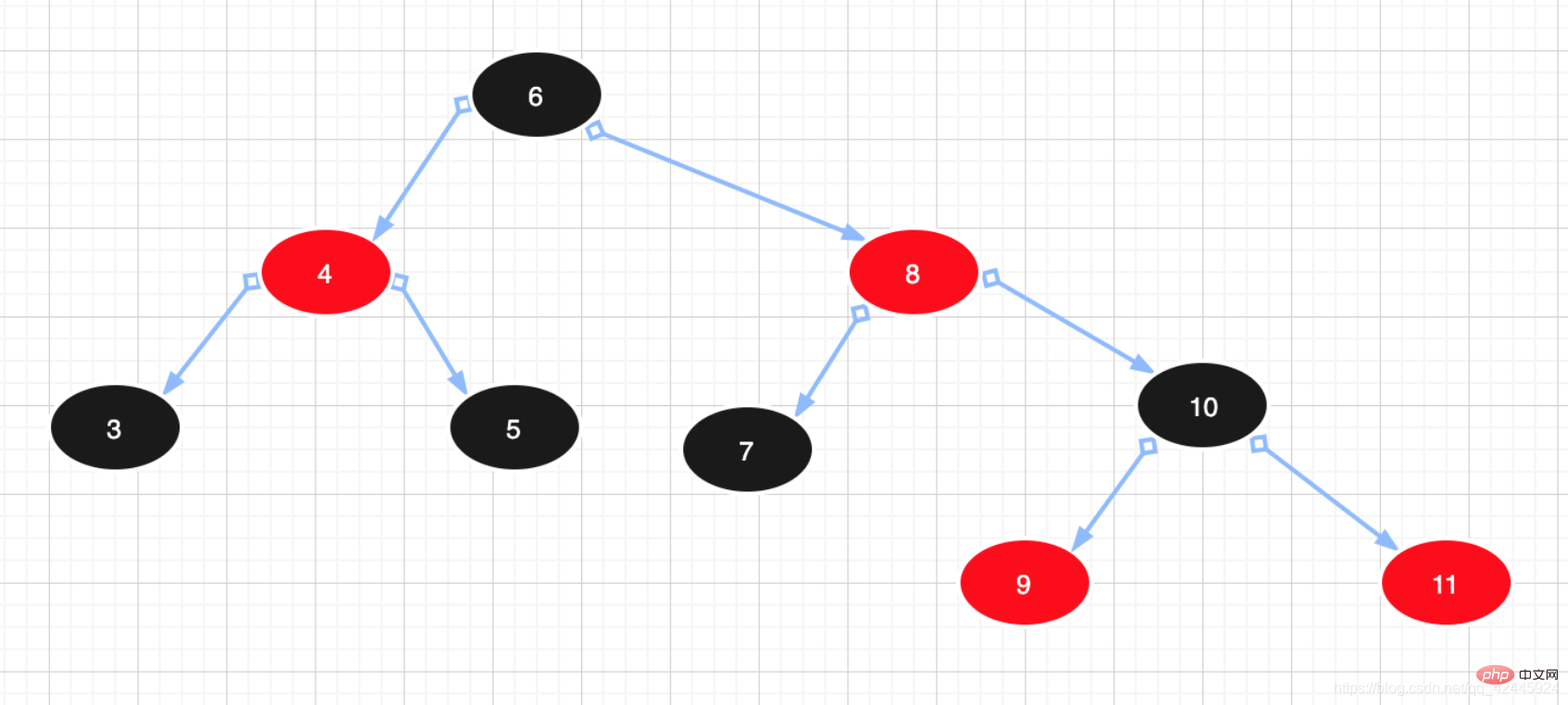
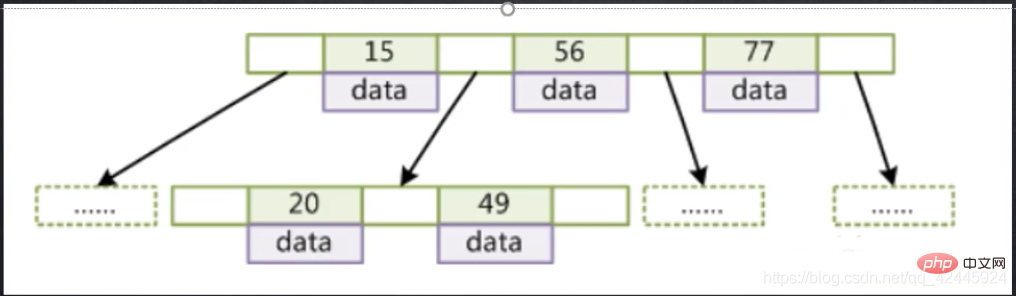 BTree의 특성을 반영하는 예시로 사용됩니다.
BTree의 특성을 반영하는 예시로 사용됩니다. 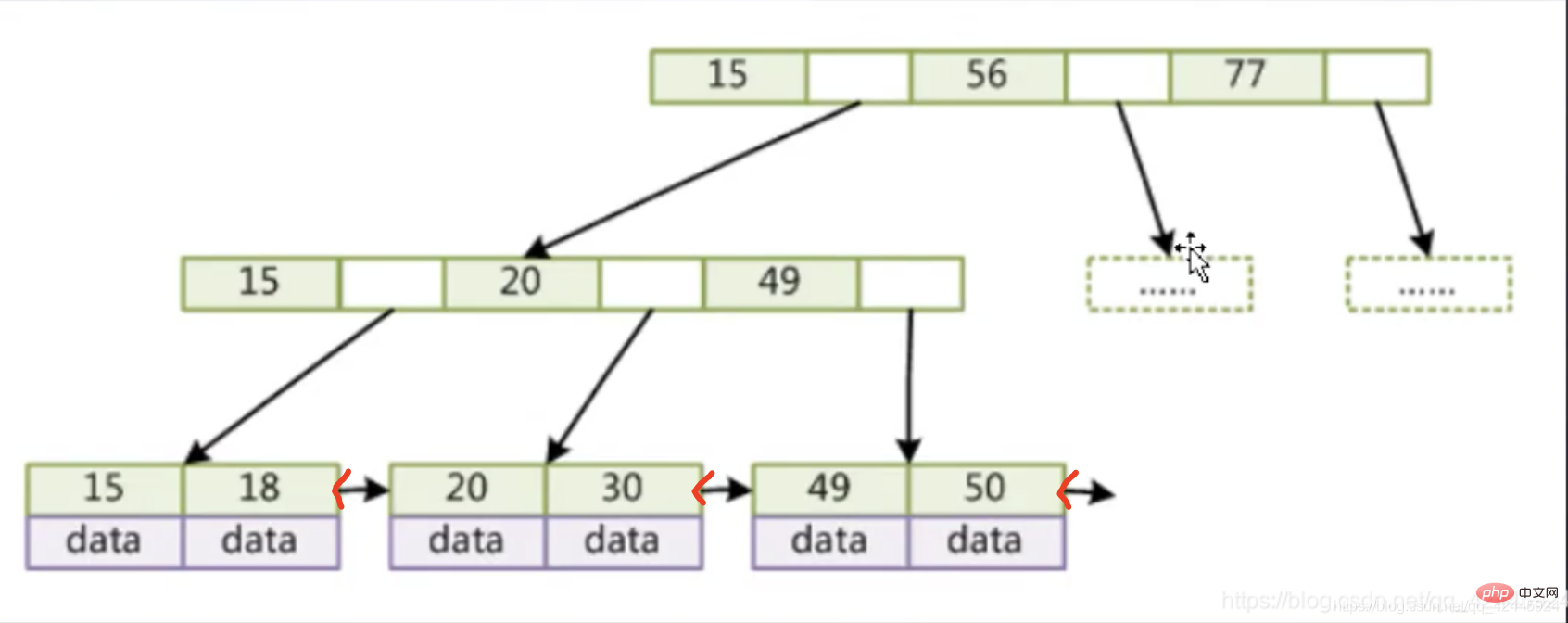
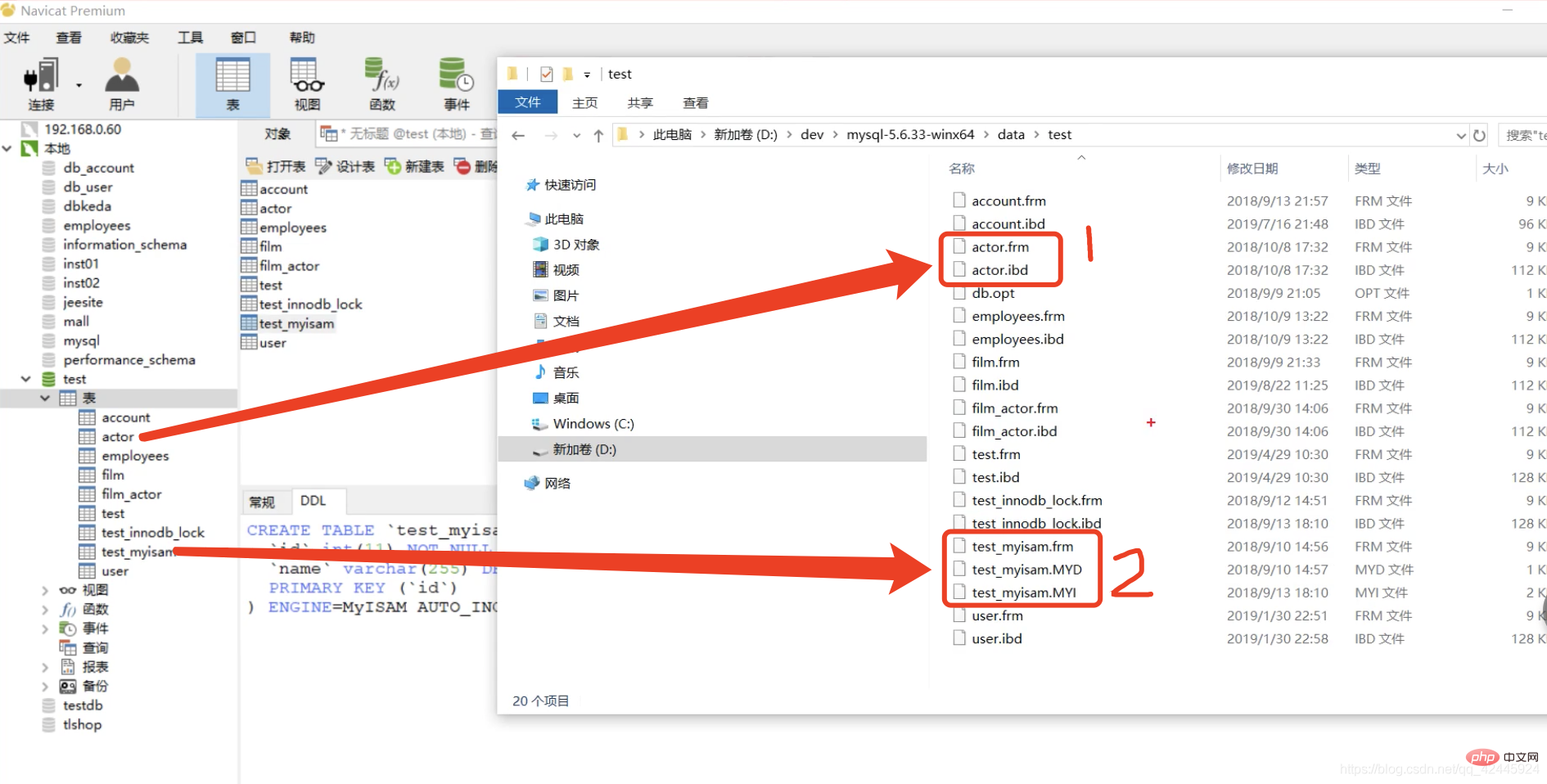 test.myisam 테이블은 MyISAM 스토리지 엔진이고 actor 테이블은 InnoDB 스토리지 엔진입니다. MyISAM 스토리지 엔진에는 frm, MYD라는 세 개의 파일이 있는 것을 볼 수 있습니다. , MYI의 약어로는 테이블 구조를 저장하고, MYD-MYData는 데이터를 저장하며, MYI-MYIndex는 인덱스와 데이터를 별도로 저장합니다. 또한 테이블의 구조인 IBD 파일은 InnoDB 및 MyISAM과 다른 인덱스와 데이터를 저장합니다.
test.myisam 테이블은 MyISAM 스토리지 엔진이고 actor 테이블은 InnoDB 스토리지 엔진입니다. MyISAM 스토리지 엔진에는 frm, MYD라는 세 개의 파일이 있는 것을 볼 수 있습니다. , MYI의 약어로는 테이블 구조를 저장하고, MYD-MYData는 데이터를 저장하며, MYI-MYIndex는 인덱스와 데이터를 별도로 저장합니다. 또한 테이블의 구조인 IBD 파일은 InnoDB 및 MyISAM과 다른 인덱스와 데이터를 저장합니다. 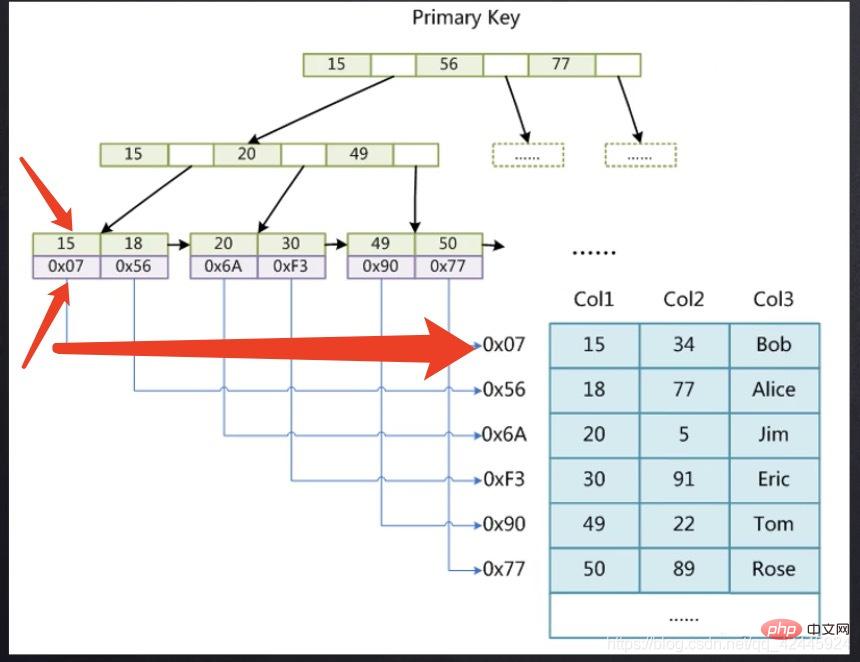 여기서 15는 기본 키 인덱스를 저장하고 0x07은 디스크 파일을 저장합니다. 우리와 같은 15행에 기록된 주소 포인터 15의 데이터를 찾으려면 먼저 기본 키 인덱스 트리를 통해 15에 해당하는 포인터를 찾은 다음 포인터를 찾은 다음 MyD 파일로 이동해야 합니다. 특정 데이터를 찾으려면 두 번째 검색이 필요합니다. 이 프로세스를 테이블 반환 작업이라고 합니다.
여기서 15는 기본 키 인덱스를 저장하고 0x07은 디스크 파일을 저장합니다. 우리와 같은 15행에 기록된 주소 포인터 15의 데이터를 찾으려면 먼저 기본 키 인덱스 트리를 통해 15에 해당하는 포인터를 찾은 다음 포인터를 찾은 다음 MyD 파일로 이동해야 합니다. 특정 데이터를 찾으려면 두 번째 검색이 필요합니다. 이 프로세스를 테이블 반환 작업이라고 합니다. 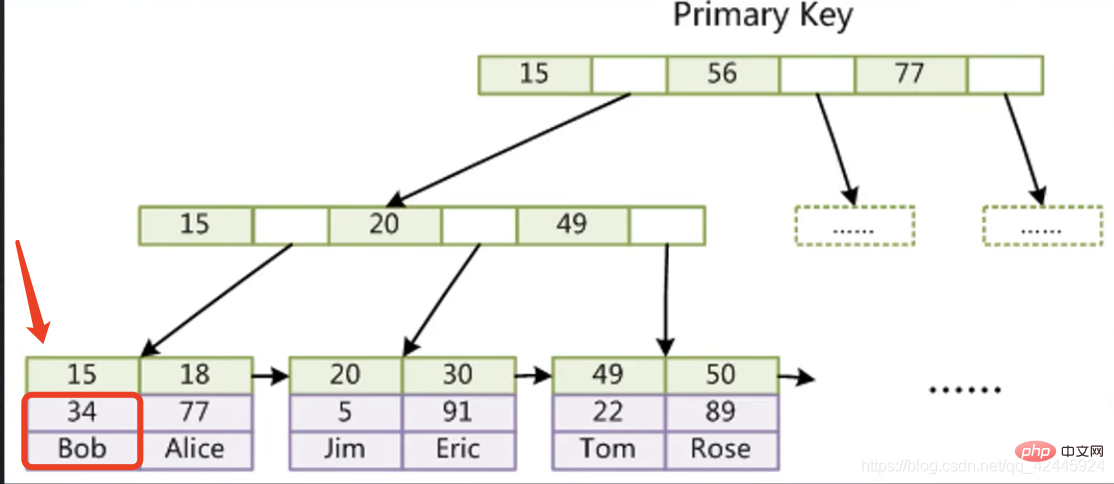 InnoDB 스토리지 엔진 하위 노드는 먼저 15번째 행에 인덱스를 저장하고, 15번째 이하의 열에는 해당 인덱스가 있는 행의 다른 모든 필드가 저장됩니다. 15개 중에서 트리를 두 번 검색하지 않고도 직접 찾을 수 있습니다.
InnoDB 스토리지 엔진 하위 노드는 먼저 15번째 행에 인덱스를 저장하고, 15번째 이하의 열에는 해당 인덱스가 있는 행의 다른 모든 필드가 저장됩니다. 15개 중에서 트리를 두 번 검색하지 않고도 직접 찾을 수 있습니다. 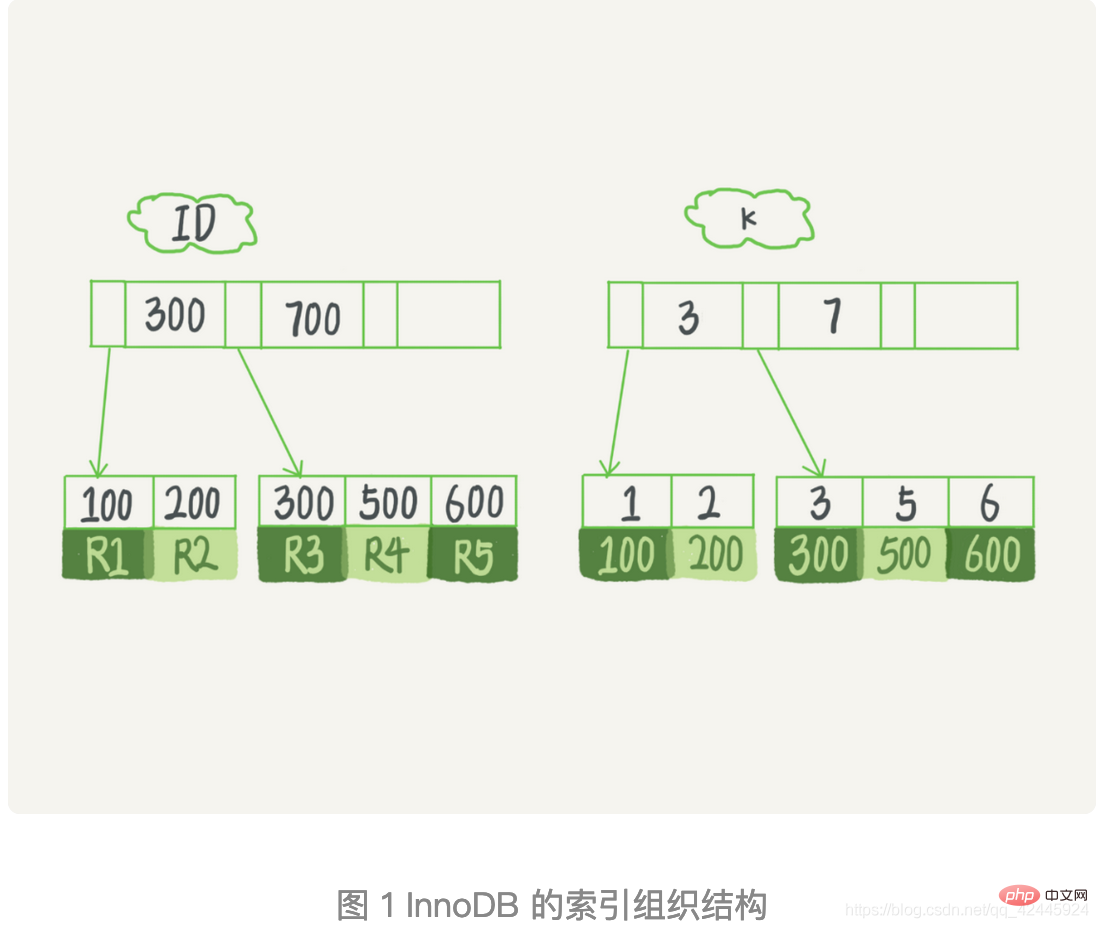






위 내용은 MySQL 인덱스의 최하위 레이어와 최적화에 대해 이야기해 보겠습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!