
데이터 정규화의 목적은 무엇입니까?

- 青灯夜游원래의
- 2021-05-07 16:33:1828024검색
데이터 정규화의 목적은 전처리된 데이터를 특정 범위로 제한하여 단일 샘플 데이터로 인한 부작용을 제거하는 것입니다. 데이터 정규화 후에는 최적의 해를 찾기 위한 경사 하강 속도가 빨라지고 정확도가 향상될 수 있습니다(예: KNN).

이 튜토리얼의 운영 환경: Windows 7 시스템, Dell G3 컴퓨터.
머신러닝 분야에서는 서로 다른 평가 지표(즉, 특징 벡터의 서로 다른 특징이 서로 다른 평가 지표입니다) 종종 다른 차원과 차원 단위를 가지게 됩니다. 이러한 상황은 지표 간의 차원적 영향을 제거하기 위해 데이터 지표 간의 비교 가능성 문제를 해결하기 위해 데이터 표준화 처리가 필요합니다. . 원본 데이터를 데이터 표준화를 통해 처리한 후 각 지표의 크기가 동일한 순서로 되어 있어 종합적인 비교 평가에 적합합니다. 그 중 가장 대표적인 것이 데이터의 정규화 처리입니다. (연구 참고 가능: 데이터 표준화/정규화)
간단히 말하면 정규화의 목적은 전처리된 데이터를 특정 범위(예: [0,1)로 제한하는 것입니다. ] 또는 [-1,1])을 사용하여 단일 표본 데이터로 인한 역효과를 제거합니다.
1) 통계에서 정규화의 구체적인 역할은 통일된 표본의 통계적 분포를 요약하는 것입니다. 0과 1 사이의 정규화는 통계적 확률 분포이고, -1과 +1 사이의 정규화는 통계적 좌표 분포입니다.
2) 특이 표본 데이터는 다른 입력 표본에 비해 유난히 크거나 작은 표본 벡터(즉, 특징 벡터)를 말합니다. 예를 들어 다음은 두 가지 특징을 갖는 표본 데이터 x1과 x2입니다. , x3, x4, x5, x6(특징 벡터 -> 열 벡터) 중 x6 샘플의 두 가지 특징이 다른 샘플과 상대적으로 다르기 때문에 x6은 단일 샘플 데이터로 간주됩니다.
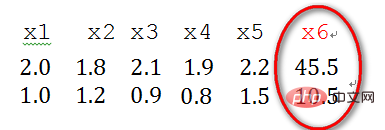
단일 샘플 데이터가 존재하면 훈련 시간이 길어지고 수렴에 실패할 수도 있습니다. 학습 전 전처리된 데이터를 정규화해야 합니다. 반대로 단일 샘플 데이터가 없으면 정규화를 수행할 필요가 없습니다.
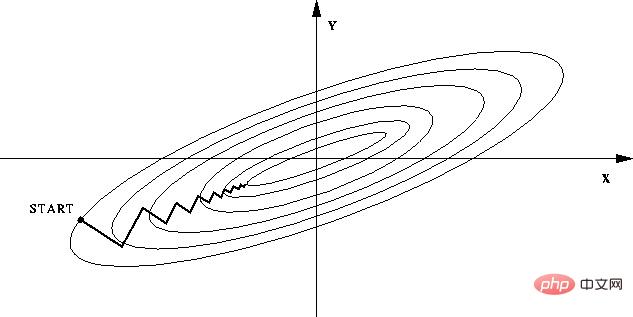
--정규화가 수행되지 않으면 특성의 서로 다른 특성 값의 큰 차이로 인해 목적 함수가 "플랫"이 됩니다. 벡터. 이와 같이 경사하강법을 수행할 때 경사의 방향이 최소값의 방향에서 벗어나 많은 우회를 하게 되어 훈련 시간이 너무 길어지게 됩니다.
--정규화되면 목적 함수가 더 "둥글게" 나타나므로 훈련 속도가 크게 향상되고 많은 우회를 피할 수 있습니다. 요약하면 정규화에는 다음과 같은 이점이 있습니다. 즉 1) 정규화 후 경사 하강이 가속화됩니다. 2) 정규화로 정확도가 향상될 수 있음(예: KNN) 참고: 단일 데이터가 없습니다. 표준화된 방법을 적용했습니다. 모든 문제와 모든 모델에 대해 알고리즘의 정확도를 높이고 알고리즘의 수렴 속도를 가속화할 수 있습니다. 관련 지식이 더 궁금하시다면 FAQ 칼럼을 방문해 주세요! 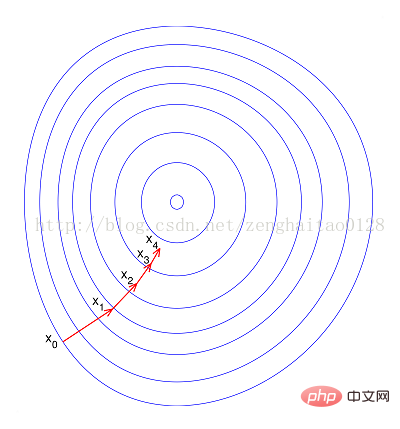
위 내용은 데이터 정규화의 목적은 무엇입니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!