
집 >데이터 베이스 >MySQL 튜토리얼 >InnoDB 데이터 저장 파일은 MyISAM과 다릅니다.
InnoDB 데이터 저장 파일은 MyISAM과 다릅니다.

- coldplay.xixi앞으로
- 2021-02-02 09:16:082602검색
MySQL Tutorial칼럼에 소개된 인덱스에 B+Tree를 사용하는 이유는 무엇입니까? 크라우드 펀딩 회사에서 면접관의 MySQL 관련 지식에 대해 첫 번째 질문을 했는데 당시에는 여전히 혼란스러웠습니다. 이 젊은이는 무술 윤리를 따르지 않았고 규칙도 지키지 않았습니다. MySQL 관련 지식에 대해 물었을 때 그는 그렇지 않았습니다. 그들은 모두 인덱스 최적화, 인덱스 실패 및 기타 관련 문제에 대해 묻는 것입니까? 저장파일이 다른 이유는 무엇인가요? MVCC 메커니즘을 조사하더라도 그럴 것입니다. 그래서 이번에는 지식 포인트 중 이 부분을 정리해보겠습니다.
인덱스를 구축해야 하는 이유는 무엇입니까? 우선, 인덱스를 구축하는 목적이 쿼리 속도를 향상시키는 것임을 우리 모두 알고 있는데, 인덱스를 사용하면 쿼리 속도가 향상될 수 있는 이유는 무엇일까요? 인덱스의 개략도를 살펴보겠습니다. 
select * from Table where id = 15 인덱스가 없으면 전체 테이블 스캔이 수행됩니다. 즉, 다음이 나올 때까지 하나씩 검색합니다. id가 15인 경우 이 레코드의 시간 복잡도는 O(n)입니다. 인덱스로 쿼리하면 어떻게 될까요? 먼저 id=15를 기준으로 인덱스 값에서 이진 검색을 수행합니다. 이진 검색의 효율성은 매우 높으며 시간 복잡도는 O(logn)입니다. 데이터의 양도 비교적 크기 때문에 일반적으로 메모리에 저장되지 않고 디스크에 직접 저장됩니다. 따라서 디스크에 있는 파일 내용을 읽으려면 필연적으로 디스크 IO가 필요합니다.
MySQL이 인덱싱을 위해 B+Tree를 사용하는 이유
위에서 말했듯이 인덱스 데이터는 일반적으로 디스크에 저장되지만, 인덱스 파일이 크고 그럴 수 없는 경우 데이터 계산은 메모리에서 수행되어야 합니다. 인덱스를 메모리에 한꺼번에 로드하므로 데이터 검색을 위해 인덱스를 사용할 경우 여러 디스크 IO를 수행하여 인덱스 데이터를 일괄적으로 메모리에 로드하게 됩니다. 따라서 Under 이후에는 좋은 인덱스 데이터 구조를 얻을 수 있습니다. 올바른 결과를 전제로 하는 것은 디스크 IO 수가 가장 적은 것이어야 합니다.
해시 유형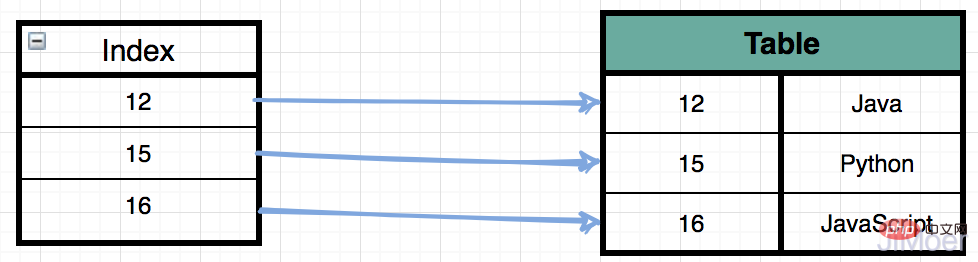
select * from Table where id = 15 那么在没有索引的情况下其实是会进行全表扫描的,就是挨个去找,直到找到id=15的这条记录,时间复杂度是O(n);
如果在有索引的情况下去进行查询呢。首先会根据id=15,在索引值里面进行二分查找,二分查找的效率是很高的,它的时间复杂度是O(logn);
这就是索引为什么能提高查询效率了,但是索引数据的量也是比较大的,所以一般并不是存储在内存中的,都是直接存储在磁盘中的,所以对磁盘中的文件内容进行读取,免不了要进行磁盘IO。
MySQL的索引为什么使用B+Tree
上面我们也说了,索引数据一般是存储在磁盘中的,但是计算数据都是要在内存中进行的,如果索引文件很大的话,并不能一次都加载进内存,所以在使用索引进行数据查找的时候是会进行多次磁盘IO,将索引数据分批的加载到内存中,<strong>因此一个好的索引的数据结构,在得到正确的结果前提下,一定是磁盘IO次数最少的。</strong>
Hash类型
目前MySQL其实是有两种索引数据类型可以选择的,一个是BTree(实际是B+Tree)、一个Hash。
但是为什么在实际的使用过程中,基本上大部分都是选择BTree呢?
因为如果使用Hash类型的索引,MySQL在创建索引的时候,会对索引数据进行一次Hash运算,这样根据Hash值就能快速的定位到磁盘指针了,就算数据量很大,也能快速精准的定位到数据。
- 但是像
select * from Table where id > 15현재 MySQL에는 실제로 선택할 수 있는 두 가지 인덱스 데이터 유형이 있습니다. 하나는 BTree(실제로는 B+Tree)이고 다른 하나는 Hash입니다. - 그런데 실제 사용 시 대부분의 사람들이 BTree를 선택하는 이유는 무엇일까요?
-
그러나
- 디스크 IO가 너무 많음: MySQL에서는 한 번의 IO 작업이 하나의 노드만 읽습니다. 노드에 최대 2개의 하위 노드가 있는 경우 이 두 하위 노드의 쿼리 범위만 있으므로 정확해야 합니다. 특정 데이터를 검색할 때 여러 번의 읽기가 필요합니다. 트리가 매우 깊은 경우 많은 양의 디스크 IO가 수행됩니다. 성능은 자연스럽게 저하됩니다.
- 낮은 공간 활용: 균형 이진 트리의 경우 각 노드 값은 키워드, 데이터 영역 및 두 하위 노드에 대한 포인터를 저장합니다. 결과적으로, 한 번의 힘든 IO 작업에서 이렇게 적은 양의 데이터만 로드하는 것은 정말 과잉입니다.
- 쿼리 효과가 불안정합니다: 높이가 매우 깊은 균형 이진 트리에서 쿼리된 데이터가 루트 노드인 경우 쿼리된 데이터가 리프 노드인 경우 빠르게 검색됩니다. 반환하려면 여러 디스크 IO가 필요하며 응답 시간은 루트 노드의 크기와 동일하지 않을 수 있습니다.
- 若是查询id=7的数据,先将关键字20的节点加载进内存,判断出7比20小;
- 那么加载第一个子节点,若查询的数据等于12或17则直接返回,不等于就继续向下找,发现7小于12;
- 那么继续加载第一个子节点中去,找到7之后,直接将7下面的data数据返回。
- 이제 id=2인 데이터를 쿼리하려면 먼저 루트 노드를 꺼내 메모리에 로드해야 합니다. 루트 노드에
id=2가 존재한다는 것을 알 수 있습니다. 데이터는 왼쪽 닫힌 간격에 저장되므로 id는 모두 루트 노드의 첫 번째 하위 노드에 있습니다. - B+Tree的查询采用的左闭合区间,这样能更好的支持了自增索引的查询效果,所以一般在创建主键的时候通常都是自增的。这一点和B-Tree是不一样的。
- B+Tree中的根节点和分支节点上是不保存数据的,关键字相关的数据只保存在叶子节点上,这样保证了查询效果的稳定,任何查询都要走到叶子节点才能获取数据。而B-Tree在分支节点中保存了数据,若是命中关键字则直接返回数据。
- B+Tree的叶子节点是顺序排列的,并且相邻的两个叶子节点中具有顺序引用的关系,这样能更好的支持了范围查询。而B-Tree是没有这个顺序关系的。
select * from Table where id >와 같은 범위 쿼리의 경우 해시 유형 인덱스를 처리할 수 없습니다. 또한, 전체 테이블을 직접 스캔합니다. 해시 유형 인덱스도 정렬할 수 없습니다. 또한 MySQL의 하위 계층에서 일련의 처리를 수행했지만 여전히 해시 충돌이 발생하지 않는다는 것을 완전히 보장할 수는 없습니다. 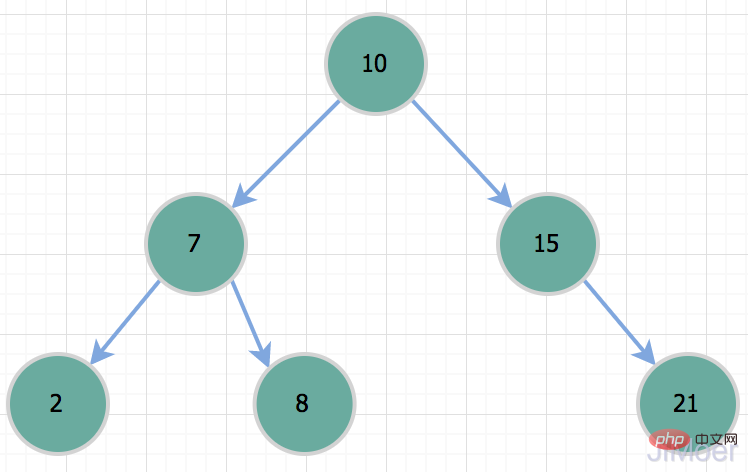
이진 트리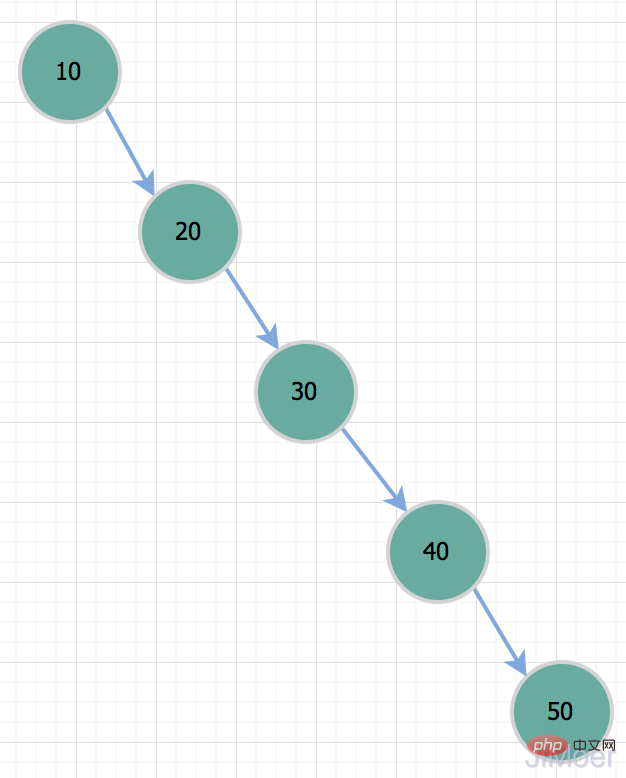
그렇다면 MySQL은 왜 인덱스 데이터 구조로 이진 트리를 갖지 않는 걸까요? 이진 트리는 이진 검색을 통해 데이터를 찾으므로 효과가 좋고 시간 복잡도는 O(logn)입니다. 그러나 이진 트리에는 문제가 있습니다. 즉, 특수한 상황에서는 퇴화됩니다. 트리로 스틱은 단방향 연결 목록입니다. 이때 시간 복잡도는 O(n)으로 변합니다.
따라서 id=50인 레코드를 쿼리하려는 경우 실제로 전체 테이블 스캔과 동일합니다. 따라서 이러한 상황 때문에 이진 트리는 인덱스 데이터 구조로 적합하지 않습니다.
균형 이진 트리
그러면 이진 트리는 특별한 상황에서 연결 리스트로 변질되는데, 왜 균형을 이룰 수 없는 걸까요? 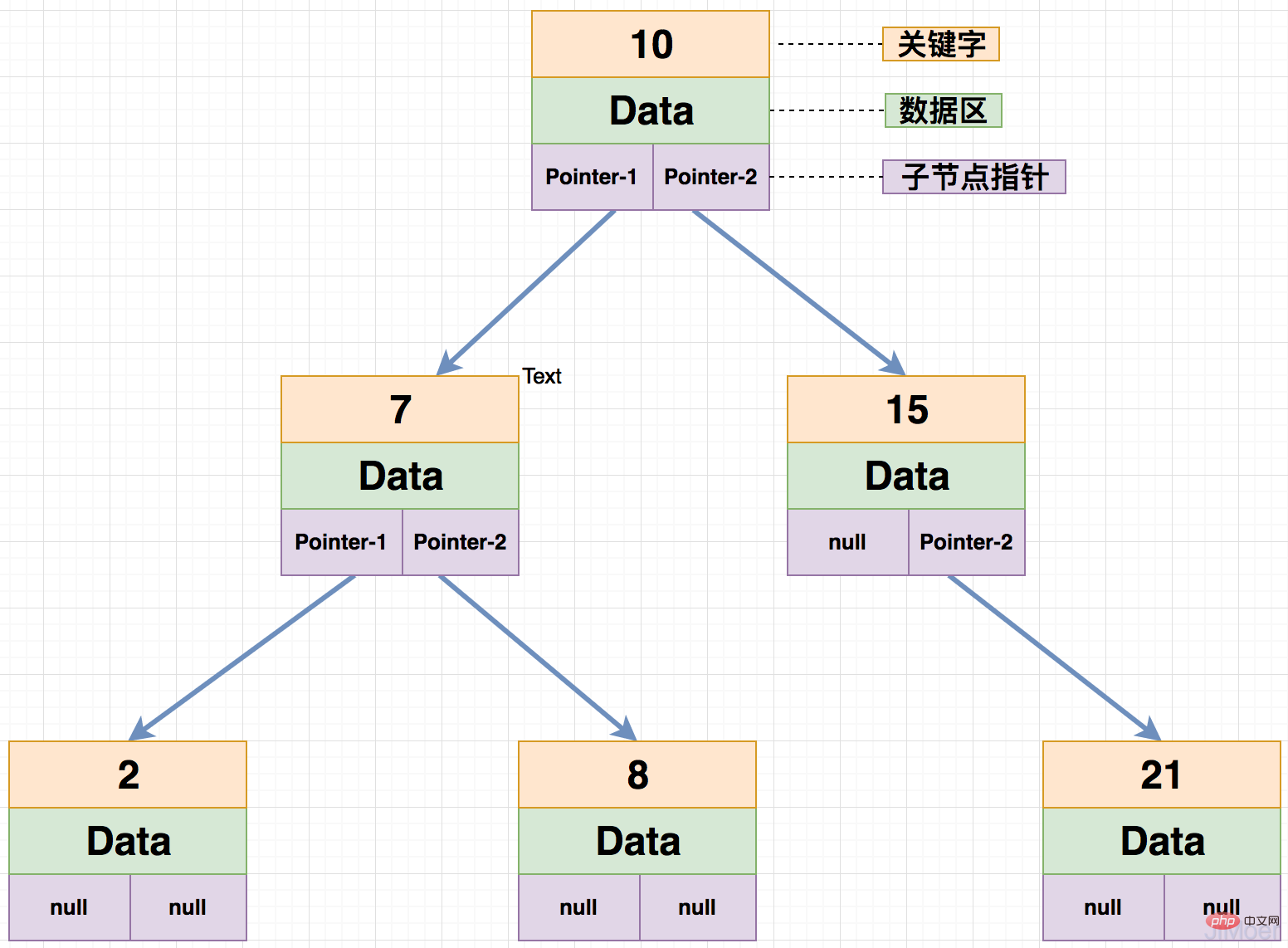 균형 이진 트리의 하위 노드 높이 차이는 1을 초과할 수 없습니다
균형 이진 트리의 하위 노드 높이 차이는 1을 초과할 수 없습니다
아래 그림의 이진 트리와 같이 키가 15인 노드의 왼쪽 하위 노드 높이는 0이고 오른쪽 하위 노드 높이는 0입니다. 1. 높이 차이가 1을 초과하지 않으므로 아래 트리는 균형 이진 트리입니다.
균형을 유지할 수 있기 때문에 쿼리 시간 복잡도는 O(logN)입니다. 균형을 유지하는 방법은 주로 왼쪽 회전, 오른쪽 회전 등을 수행합니다. 균형 유지에 대한 구체적인 내용은 다음과 같습니다. 이 글의 주요 내용은 아닙니다. 더 알고 싶으시면 직접 검색해 보세요.
🎜이 데이터 구조를 사용하여 MySQL 인덱스를 생성할 때 어떤 문제가 있나요? 🎜🎜이진 트리는 균형 문제를 해결하지만 새로운 문제도 가져옵니다. 즉, 자체 트리의 깊이로 인해 일련의 효율성 문제가 발생합니다.
그래서 이진 트리 균형 문제를 해결하기 위해서는 Balance Tree가 더 나은 선택이 되었습니다.
Balance Tree-B-Tree
B-Tree는 균형 잡힌 다중 트리를 의미합니다. 일반적으로 B-Tree의 노드가 몇 개의 하위 노드를 가지고 있는지를 B-Tree의 순서라고 합니다. 일반적으로 m은 차수를 나타내는 데 사용됩니다. m이 2인 경우 균형 이진 트리입니다.
B-Tree의 각 노드는 최대 m-1개의 키워드를 가질 수 있으며 최소한 Math.ceil(m/2)-1 키워드가 저장되어야 합니다. 모든 리프 노드는 모두 동일합니다. 바닥. 아래 사진은 4차 B-Tree 입니다. Math.ceil(m/2)-1个关键字,所有的叶子节点都在同一层。如下图就是一个4阶的B-Tree。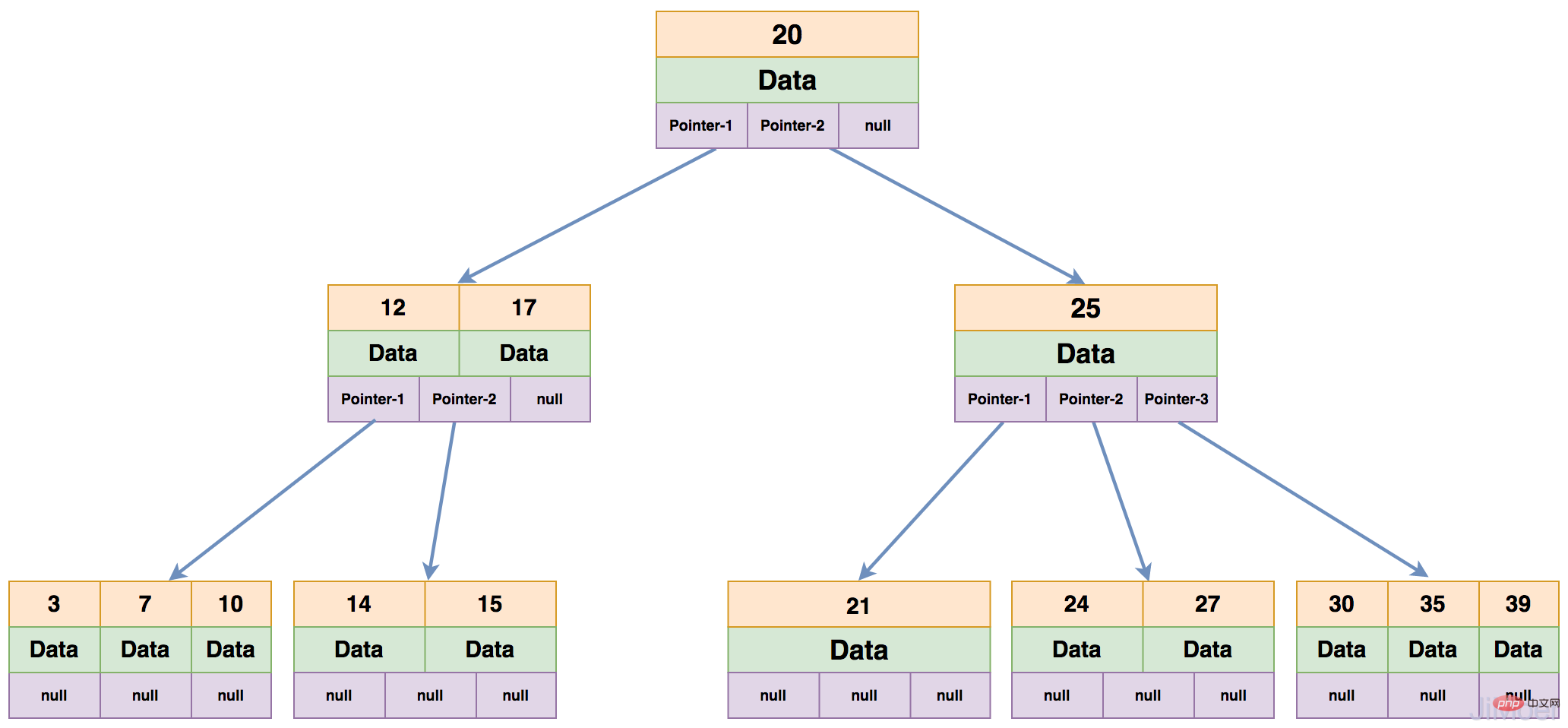
那么我们看一下B-Tree是如何进行查找数据的:
这样整个操作其实进行了3次IO操作,但实际上一般的B-Tree每层都是有很多分支(通常都大于100)。
MySQL为了能更好的利用磁盘的IO能力,将操作页的大小设置为了16K,即每个节点的大小为16K。如果每个节点中的关键字都是int类型的,那么就是4个字节,若数据区的大小为8个字节,节点指针再占4个字节,那么B-Tree的每个节点中可以保存的关键字个数为:(16*1000) / (4+8+4)=1000,每个节点最多可存储1000个关键字,每一个节点最多可以有1001个分支节点。
这样在查询索引数据的时候,一次磁盘IO操作可以将1000个关键字,读取到内存中进行计算,B-Tree的一次磁盘IO的操作,顶上平衡二叉数据的N次磁盘IO操作了。
要注意的是:B-Tree为了保证数据的平衡,会做一系列的操作,这个保持平衡的过程比较耗时间,所以在创建索引的时候,要选择合适的字段,并且不要过多的创建索引,创建索引过多的话,在更新数据的时候,更新索引的过程也比较耗时。
还有就是不要选择低区分度字段值作为索引,例如性别字段,总共就两个值,那么就有可能会造成B-Tree的深度过大,索引效率降低。
B+Tree
B-Tree已经很好的解决平衡InnoDB 데이터 저장 파일은 MyISAM과 다릅니다.的问题了,并且也能保证查询效率了,那么为什么会有B+Tree呢?
我们先来B+Tree是什么样子的。
B+Tree是B-Tree的变种,B+Tree的每个节点关键字和m阶的公式关系和B-Tree的不一样了。
首先每个节点的子节点数量和每个节点可存储的关键字比例是1:1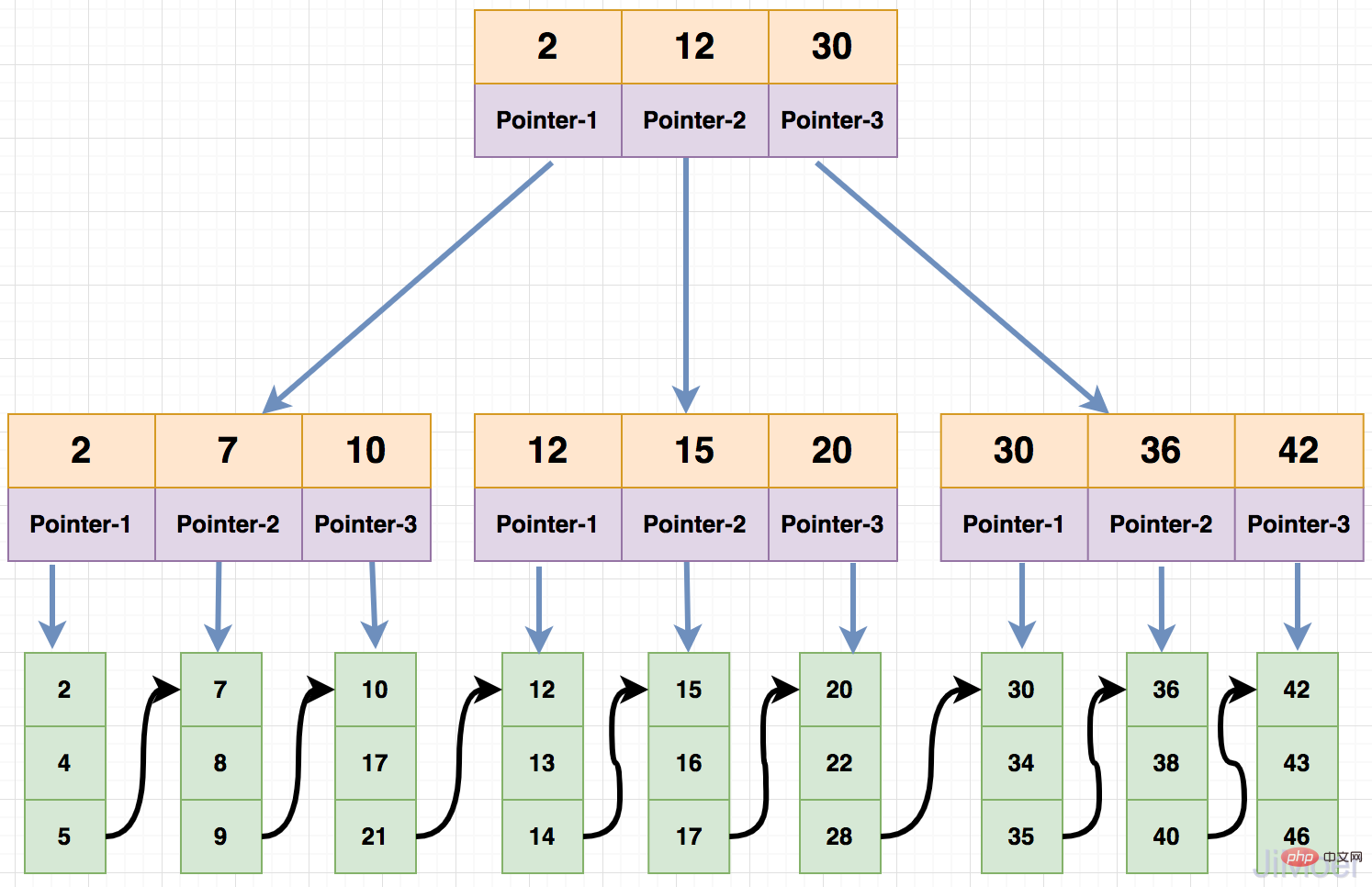 그럼 살펴보겠습니다. B -트리가 데이터를 검색하는 방법
그럼 살펴보겠습니다. B -트리가 데이터를 검색하는 방법
:
(16*1000) / (4+8+4)=1000입니다. 각 노드는 최대 1000개의 키워드를 저장할 수 있으며, 각 노드는 최대 1001개의 분기 노드를 가질 수 있습니다. 🎜🎜이렇게 하면 인덱스 데이터를 쿼리할 때 한 번의 디스크 IO 작업으로 1000개의 키워드를 메모리로 읽어와서 계산할 수 있습니다. 🎜🎜🎜주의할 점🎜: 🎜B-Tree는 데이터의 균형을 유지하기 위해 일련의 작업을 수행합니다. 이 균형을 유지하는 과정은 시간이 많이 걸리므로 인덱스를 생성할 때 , 적절한 필드를 선택해야 하며 인덱스를 너무 많이 생성하지 마십시오. 인덱스를 너무 많이 생성하면 데이터를 업데이트할 때 인덱스 업데이트 프로세스에 더 많은 시간이 소요됩니다. 🎜🎜🎜또한, 🎜성별 필드와 같이 총 2개의 값만 갖는 낮은 차별성 필드 값을 인덱스로 선택하지 마십시오. 이로 인해 B-Tree의 깊이가 너무 커질 수 있습니다. 그리고 인덱싱 효율이 감소합니다. 🎜🎜🎜🎜B+Tree🎜🎜🎜B-Tree는 균형 이진 트리 문제를 매우 잘 해결했으며 쿼리 효율성도 보장할 수 있는데 왜 B+Tree가 있는 걸까요? 🎜🎜먼저 B+Tree가 어떤 모습인지 살펴보겠습니다. 🎜🎜B+Tree는 B-Tree의 변형입니다. B+Tree의 각 노드 키워드와 m 순서 간의 공식 관계는 B-Tree와 다릅니다. 🎜🎜우선, 각 노드에 저장할 수 있는 키워드에 대한 각 노드의 하위 노드 수의 비율은 1:1이고, 두 번째로, 데이터를 쿼리할 때 왼쪽 폐구간은 다음과 같습니다. 쿼리에 사용되며 분기 노드에는 데이터가 없습니다. 키워드와 하위 노드 포인트만 저장되고 리프 노드에는 데이터가 저장됩니다. 🎜🎜🎜 그럼 B+Tree에서 데이터 쿼리를 수행하는 방법을 살펴보겠습니다. 🎜🎜예: 🎜id=2存在于根节点,因为是左闭合区间存储数据,所以id的都在根节点的第一个子节点上;<li>那么取出第一个子节点,加载到内存中,发现当前节点存在<code>id=2的关键字,并且已经到了叶子节点了,那么直接取出叶子节点中的数据返回。
现在来看一下B-Tree和B+Tree的区别
MySQL的索引为什么选择了B+Tree
经过上面的层层分析,现在我们可以总结一下MySQL为什么选择了B+Tree作为它索引的数据结构呢。
首先和平衡InnoDB 데이터 저장 파일은 MyISAM과 다릅니다.相比,B+Tree的深度更低,节点保存关键字更多,磁盘IO次数更少,查询计算效率更好。
B+Tree的全局扫描能力更强,若是想根据索引数据对数据表进行全局扫描,B-Tree会将整棵树进行扫描,然后逐层遍历。而B+Tree呢,只需要遍历叶子节点即可,因为叶子节点之间存在顺序引用的关系。
B+Tree的磁盘IO读写能力更强,因为B+Tree的每个分支节点上只保存了关键字,这样每次磁盘IO在读写的时候,一页16K数据量可以存储更多的关键字了,每个节点上保存的关键字也比B-Tree更多了。这样B+Tree的一次磁盘IO加载的数据比B-Tree的多很多了。
B+Tree数据结构中有天然的排序能力,比其他数据结构排序能力更强而且排序时,是通过分支节点来进行的,若是需要将分支节点加载到内存中排序,一次加载的数据更多。
B+Tree的查询效果更稳定,因为所有的查询都是需要扫描到叶子节点才将数据返回的。效果只是稳定而不一定是最优,若是直接查询B-Tree的根节点数据,那么B-Tree只需要一次磁盘IO就可以直接将数据返回,反而是效果最优。
经过以上几点的分析,MySQL最终选择了B+Tree作为了它的索引的数据结构。
InnDB的数据存储文件和MyISAM的有何不同?
上面总结了MySQL的索引的数据结构,这次就可以说第二个问题了,因为这个问题其实和MySQL的索引还是有一定的关系的。
下面来看一下,先找到服务器桑MySQL存储数据的目录:
登录MySQL,打开MySQL的命令行界面:输入show variables like '%datadir%';,就能看到存储数据的目录了。
我的服务器中MySQL的存储数据的目录是在:
/var/lib/mysql/
进入到这个目录里后,能看到所有数据库的目录,新建一个study_test的数据库。
然后就进入
/var/lib/mysql/study_test
这个目录下,目前就只有一个文件,这个文件是用来记录创建数据库时配置的字符集的内容。
-rw-r----- 1 mysql mysql 60 1月 31 10:28 db.opt
现在新建两个表,第一个表的引擎类型选择InnoDB,第二个表的引擎类型选择MyISAM。
student_innodb:
CREATE TABLE `student_innodb` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `name` varchar(50) COLLATE utf8mb4_bin DEFAULT NULL, `age` int(11) DEFAULT NULL, `address` varchar(100) COLLATE utf8mb4_bin DEFAULT NULL, PRIMARY KEY (`id`), KEY `idx_name` (`name`) USING BTREE COMMENT 'name索引') ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='innodb引擎表';
student_myisam:
CREATE TABLE `student_myisam` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `name` varchar(50) COLLATE utf8mb4_bin DEFAULT NULL, `age` int(11) DEFAULT NULL, `address` varchar(100) COLLATE utf8mb4_bin DEFAULT NULL, PRIMARY KEY (`id`), KEY `idx_name` (`name`) USING BTREE COMMENT 'name索引') ENGINE=MyISAM DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='myISAM引擎类型表';
将两个表创建完成后,我们再进入到/var/lib/mysql/study_test그런 다음 첫 번째 하위 노드를 꺼내서 로드합니다. 메모리에서 현재 노드에 id= 2 키워드가 있고 리프 노드에 도달한 것을 확인한 다음 리프 노드에 있는 데이터를 직접 검색하여 반환합니다.
B+Tree의 쿼리는 왼쪽 폐구간을 사용하므로 더 나을 수 있습니다. 자동 증가 인덱스의 쿼리 효과를 지원하므로 일반적으로 기본 키를 생성할 때 자동 증가됩니다. 이는 B-Tree와 다릅니다.
B+Tree에서는 루트 노드와 분기 노드에 데이터가 저장되지 않습니다. 키워드 관련 데이터는 리프 노드에만 저장되므로 쿼리 효과가 보장됩니다. 쿼리는 데이터를 얻기 위해 리프 노드로 이동해야 합니다. B-Tree는 Branch 노드에 데이터를 저장하고, 해당 키워드가 맞으면 해당 데이터가 바로 반환됩니다. 🎜B+Tree의 리프 노드는 순차적으로 배열되며 인접한 두 리프 노드는 순차적인 참조 관계를 가지므로 범위 쿼리를 더 잘 지원할 수 있습니다. B-Tree에는 이러한 순서 관계가 없습니다.MySQL이 인덱스로 B+Tree를 선택한 이유는 무엇입니까?
🎜위의 분석 계층을 마친 후 이제 MySQL이 B+Tree를 인덱스로 선택한 이유를 요약할 수 있습니다. index.인덱스의 데이터 구조는 어떻습니까? 🎜- 🎜🎜우선 B+Tree는 균형 이진 트리에 비해 깊이가 낮고, 더 많은 노드가 키워드를 저장하고, 디스크 IO 횟수가 적고, 쿼리 계산 효율성이 더 좋습니다. 🎜🎜🎜B+Tree에는 인덱스 데이터를 기반으로 데이터 테이블을 전역적으로 스캔하려는 경우 B-Tree가 전체 트리를 스캔한 다음 계층화합니다. 레이어 트래버스. B+Tree의 경우 리프 노드 사이에는 순차 참조 관계가 있으므로 리프 노드만 순회하면 됩니다. 🎜🎜🎜B+Tree의 디스크 IO 읽기 및 쓰기 기능이 더욱 강력해졌습니다. B+Tree의 각 분기 노드에는 키워드만 저장되므로 디스크 IO를 읽고 쓸 때마다 당시에는 16K 데이터 페이지에 더 많은 키워드를 저장할 수 있었고, 각 노드는 B-Tree보다 더 많은 키워드를 저장할 수 있었습니다. 이런 방식으로 B+Tree는 B-Tree보다 하나의 디스크 IO에 훨씬 더 많은 데이터를 로드합니다. 🎜🎜🎜B+Tree 데이터 구조는 다른 데이터 구조보다 강력한 정렬 기능을 가지고 있으며 분기 노드가 필요한 경우 정렬이 수행됩니다. 한 번에 더 많은 데이터를 로드하면서 메모리에 정렬됩니다. 🎜🎜🎜모든 쿼리는 데이터를 반환하기 전에 리프 노드를 스캔해야 하기 때문에 B+Tree의 쿼리 효과가 더 안정적입니다. 효과는 안정적일 뿐 반드시 최적은 아닙니다. B-Tree의 루트 노드 데이터를 직접 쿼리하면 B-Tree는 한 번의 디스크 IO만으로 데이터를 직접 반환할 수 있지만 효과는 최적입니다. 🎜
먼저 MySQL 서버가 데이터를 저장하는 디렉터리를 찾으세요.
MySQL에 로그인하고 MySQL 명령줄 인터페이스를 엽니다.
'%datadir%'와 같은 변수 표시를 입력하세요. 를 클릭하면 데이터가 저장된 디렉터리를 확인할 수 있습니다. <br> 내 서버에서 MySQL이 데이터를 저장하는 디렉터리는 🎜<pre class="brush:php;toolbar:false">-rw-r----- 1 mysql mysql 60 1月 31 10:28 db.opt-rw-r----- 1 mysql mysql 8650 1月 31 10:41 student_innodb.frm-rw-r----- 1 mysql mysql 114688 1月 31 10:41 student_innodb.ibd-rw-r----- 1 mysql mysql 8650 1月 31 10:58 student_myisam.frm-rw-r----- 1 mysql mysql 0 1月 31 10:58 student_myisam.MYD-rw-r----- 1 mysql mysql 1024 1月 31 10:58 student_myisam.MYI</pre>🎜이 디렉터리에 들어가면 모든 데이터베이스의 디렉터리를 볼 수 있고 <code>study_test라는 새 데이터베이스를 생성할 수 있습니다. 그런 다음 🎜rrreee🎜 디렉터리를 입력하세요. 현재 이 파일은 데이터베이스 생성 시 구성한 문자 집합의 내용을 기록하는 데 사용됩니다. 🎜rrreee🎜이제 두 개의 새 테이블을 생성하고 첫 번째 테이블의 엔진 유형으로 InnoDB를 선택하고 두 번째 테이블의 엔진 유형으로 MyISAM을 선택합니다. 🎜🎜student_innodb: 🎜rrreee🎜student_myisam: 🎜rrreee🎜 두 테이블을 생성한 후
/var/lib/mysql/study_test를 입력합니다. 살펴보세요: 🎜rrreee🎜 디렉터리의 파일을 통해 테이블을 생성한 후 여러 개의 파일이 더 있다는 것을 알 수 있습니다. 이는 InnoDB 엔진 유형 테이블과 MyISAM 엔진 유형 테이블 간의 파일 차이점도 보여줍니다. 🎜🎜각 파일에는 고유한 역할이 있습니다.🎜<ul>
<li>InnoDB 엔진에는 두 개의 테이블 파일이 있습니다: <ul>
<li>*.frm 이 유형의 파일은 테이블의 정의 파일입니다. </li>
<li>*.ibd 이 유형의 파일은 데이터 및 인덱스 저장 파일입니다. 테이블 데이터와 인덱스가 집계되어 저장되며, 인덱스를 통해 데이터를 직접 조회할 수 있습니다. </li>
</ul>
</li>
<li>MyIASM 엔진에는 세 개의 테이블 파일이 있습니다: <ul>
<li>*.frm 이 유형의 파일은 테이블의 정의 파일입니다. </li>
<li>*.MYD 이 파일 형식은 테이블 데이터 파일로, 테이블의 모든 데이터가 이 파일에 저장됩니다. </li>
<li>*.MYI 이런 종류의 파일은 테이블의 인덱스 파일로, MyISAM 스토리지 엔진의 인덱스 데이터가 별도로 저장된다. </li>
</ul>
</li>
</ul>
<p><strong>MyISAM 데이터 저장 엔진, 인덱스 및 데이터 저장 구조</strong></p>
<p>MyISAM 스토리지 엔진은 인덱스를 저장할 때 인덱스 데이터를 별도로 저장하며, 인덱스의 B+Tree는 궁극적으로 데이터가 존재하는 물리적 위치를 가리킨다. 특정 데이터가 아닌 주소입니다. 그런 다음 물리 주소에 따라 데이터 파일(*.MYD)에서 특정 데이터를 찾습니다. </p>
<p>아래 그림과 같이: <br><img src="/static/imghwm/default1.png" data-src="https://img.php.cn/upload/article/000/000/052/26588e767b94b5a39e8f185e76cae063-6.png" class="lazy" alt="InnoDB 데이터 저장 파일은 MyISAM과 다릅니다."><br> 그러면 여러 개의 인덱스가 있는 경우 여러 개의 인덱스가 동일한 물리적 주소를 가리킵니다. <br> 아래 그림과 같이 <br><img src="/static/imghwm/default1.png" data-src="https://img.php.cn/upload/article/000/000/052/26588e767b94b5a39e8f185e76cae063-7.png" class="lazy" alt="InnoDB 데이터 저장 파일은 MyISAM과 다릅니다."><br> 이 구조를 통해 MyISAM의 스토리지 엔진의 인덱스는 모두 동일한 레벨에 있으며 기본 키와 비기본 키 인덱스 구조 및 쿼리 방법이 완전히 동일함을 알 수 있습니다. . </p>
<p><strong>InnoDB 데이터 저장 엔진, 인덱스 및 데이터 저장 구조</strong></p>
<p>먼저 InnoDB의 인덱스는 클러스터형 인덱스와 비클러스터형 인덱스로 나누어지며 각 B+Tree에는 키워드가 저장됩니다. 분기 노드와 데이터는 리프 노드에 저장됩니다. <br> "<strong>클러스터링</strong>"은 데이터 행이 특정 순서에 따라 하나씩 밀접하게 저장된다는 의미입니다. 테이블에 데이터를 저장하는 방법은 한 가지뿐이므로 클러스터형 인덱스는 하나만 가질 수 있습니다. 일반적으로 기본 키가 클러스터형 인덱스로 사용되면 InnoDB는 숨겨진 열을 기본으로 생성합니다. 기본적으로 키. </p>
<p>아래 그림과 같이 <br><img src="/static/imghwm/default1.png" data-src="https://img.php.cn/upload/article/000/000/052/27f866e22cb81ea08dc42142d3144f58-8.png" class="lazy" alt="InnoDB 데이터 저장 파일은 MyISAM과 다릅니다."><br> Non-clustered index, Secondary index라고도 불리며 B+Tree의 각 가지 노드에도 키워드가 저장되지만 리프 노드에는 저장된 데이터가 아닌 Primary Key 값이 저장됩니다. 보조 인덱스를 통해 데이터를 쿼리하면 해당 데이터에 해당하는 기본 키를 먼저 쿼리한 다음 기본 키를 기준으로 특정 데이터 행을 쿼리합니다. </p>
<p>아래 그림과 같이: <br><img src="/static/imghwm/default1.png" data-src="https://img.php.cn/upload/article/000/000/052/15fa41611b09e0b7309f0c140547ed0f-9.png" class="lazy" alt="InnoDB 데이터 저장 파일은 MyISAM과 다릅니다."><br> 비클러스터형 인덱스의 설계 구조로 인해 쿼리 시 비클러스터형 인덱스를 두 번 인덱싱해야 한다는 이점이 있습니다. 이때 기본 키 인덱스만 업데이트하면 되며 비클러스터형 인덱스는 건드릴 필요가 없습니다. 또한 MyISAM 인덱스와 같은 물리적 주소를 저장하고 데이터 마이그레이션 중에 모든 인덱스를 다시 유지해야 하는 문제를 피할 수 있습니다. </p>
<p><strong>요약</strong></p>
<p>이번에는 MySQL 인덱스의 데이터 구조와 파일 저장 구조를 명확하게 정리했습니다. 나중에 실제 작업 과정에서 인덱스를 설계할 때 데이터 구조도 더 종합적으로 고려할 수 있습니다. 실제로 SQL을 작성할 때 어떤 상황이 인덱싱되고 어떤 상황이 인덱싱되지 않는지 고려할 수 있습니다. </p>
<ul>
<li>MySQL은 B+Tree를 인덱스의 데이터 구조로 사용하는데, 이는 B+Tree의 깊이가 낮기 때문에 노드에 더 많은 키워드를 저장하고 디스크 IO 수가 적어 쿼리 효율성이 더 높아집니다. </li>
<li>B+Tree는 기본 키 인덱스이든 비기본 키 인덱스이든 상관없이 MySQL의 쿼리 효과가 안정적인지 확인할 수 있습니다. 매번 리프 노드를 쿼리하여 데이터를 반환해야 합니다. B+Tree는 동일하며 자동 증가 기본 키를 더 잘 지원하기 위해 B+Tree의 쿼리 노드 범위는 왼쪽이 닫히고 오른쪽이 열립니다. </li>
<li>MyISAM 스토리지 엔진인 <strong>테이블 데이터</strong>와 <strong>인덱스 데이터</strong>는 각각 두 개의 파일에 저장됩니다. 자체 인덱스의 B+Tree 리프 노드가 테이블 데이터의 디스크 주소를 가리키기 때문입니다. 기본 키와 비기본 키로 구분되지 않아 통합적으로 인덱스를 관리하기 위해 별도로 저장됩니다. </li>
<li>MySQL의 InnoDB 스토리지 엔진, <strong>테이블 데이터</strong> 및 <strong>인덱스 데이터</strong>는 파일에 저장됩니다. 클러스터형 인덱스의 리프 노드는 쿼리 효과의 안정성을 보장하기 위해 인덱스 검색을 수행할 때 먼저 보조 인덱스를 통해 데이터를 검색합니다. 기본 키 값을 검색한 다음 기본 키를 기반으로 클러스터형 인덱스에서 특정 데이터를 검색합니다. </li>
</ul>
<blockquote><p><strong>관련 무료 학습 권장사항: </strong><a href="https://www.php.cn/course/list/51.html" target="_blank"><strong>mysql 비디오 튜토리얼</strong></a></p></blockquote>위 내용은 InnoDB 데이터 저장 파일은 MyISAM과 다릅니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!