
Python은 Weibo 인기 검색어를 크롤링하고 이를 Mysql에 저장하는 것을 실현합니다.

- coldplay.xixi앞으로
- 2021-01-27 17:45:132406검색

무료 학습 권장 사항: python 비디오 튜토리얼
Python은 Weibo 인기 검색어를 크롤링하여 Mysql
- 최종 효과
- 사용된 라이브러리
- 타겟 분석
- 하나: 데이터 가져오기
- 두 번째: 데이터베이스에 연결
- 전체 코드
최종 효과
말도 안 되는 소리는 아니고 그냥 그림으로 가세요 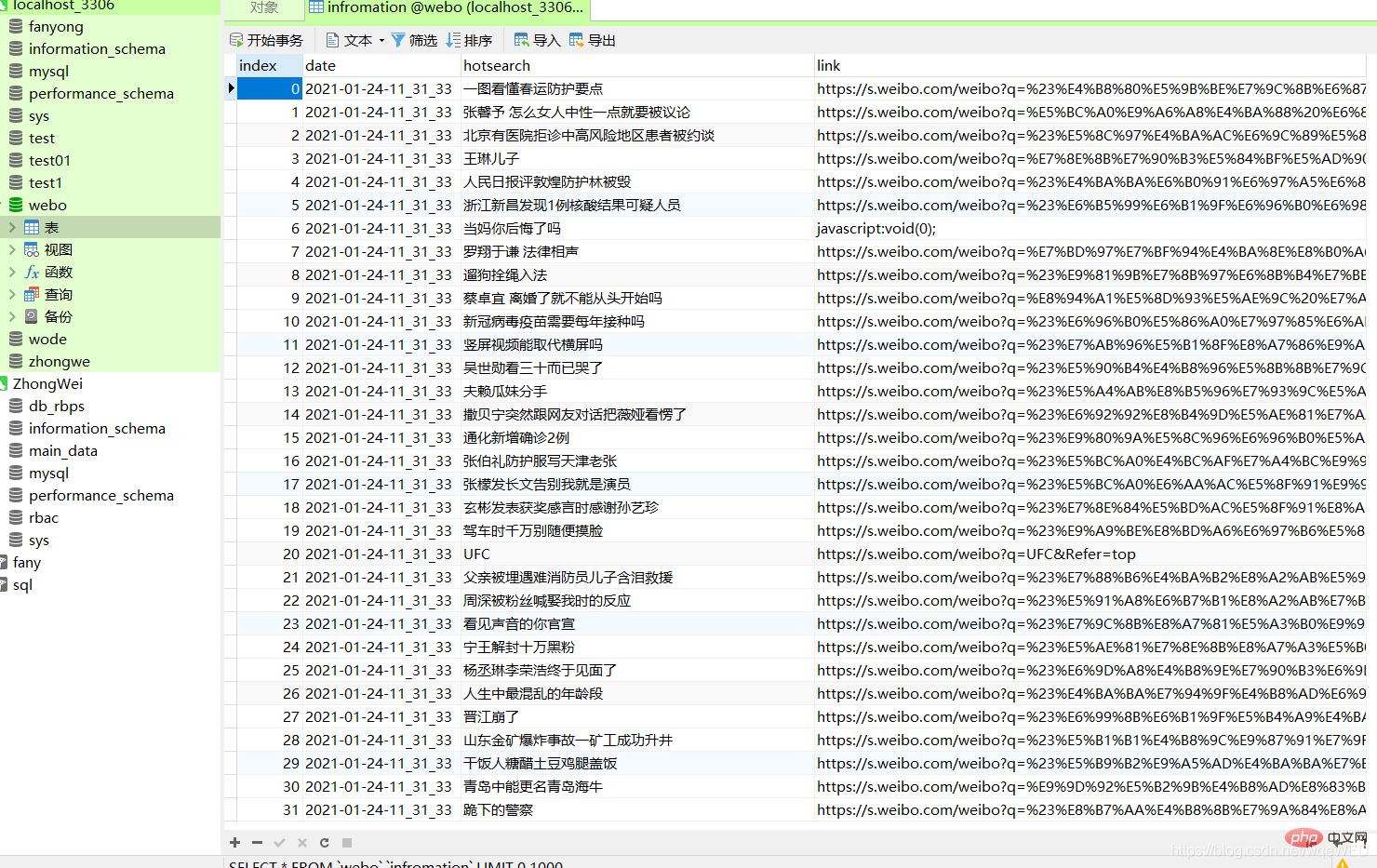
여기에서 데이터베이스에 날짜와 내용, 웹사이트 링크
구현 방법 분석
사용된 라이브러리
import requests from selenium.webdriver import Chrome, ChromeOptions import time from sqlalchemy import create_engine import pandas as pd
타겟 분석
웨이보에서 인기 검색어 링크입니다. 저를 클릭하시면 타겟 페이지로 이동합니다 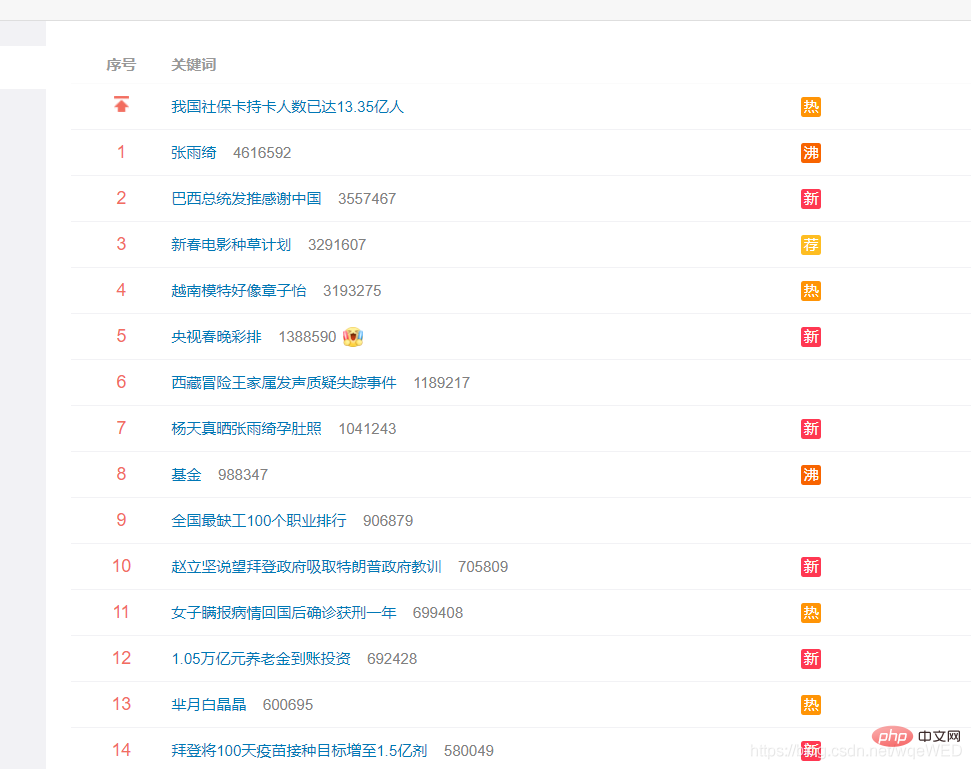
먼저 우리 셀레늄을 사용하여 대상 웹 페이지에서 요청합니다
그런 다음 xpath를 사용하여 웹 페이지 요소를 찾고 탐색하여 모든 데이터를 얻습니다
그런 다음 팬더를 사용하여 Dataframe 개체를 생성하고 데이터베이스에 직접 저장합니다
1: 데이터 가져오기
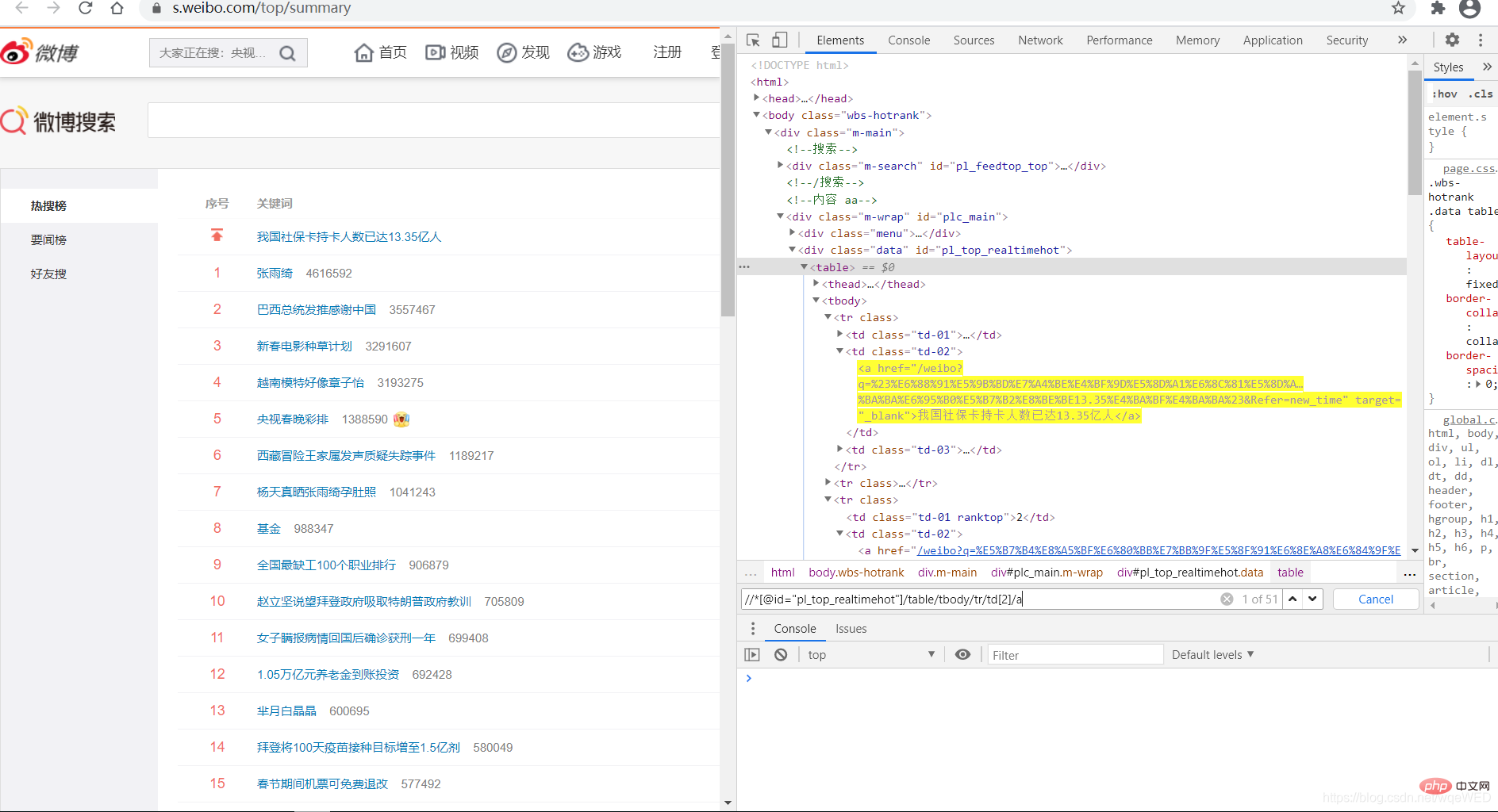
xpath를 사용하면 인기 검색어인 51개의 데이터를 얻을 수 있으며, 여기에서 링크와 제목 콘텐츠를 가져올 수 있습니다.
all = browser.find_elements_by_xpath('//*[@id="pl_top_realtimehot"]/table/tbody/tr/td[2]/a') #得到所有数据
context = [i.text for i in c] # 得到标题内容
links = [i.get_attribute('href') for i in c] # 得到link
그런 다음 zip 기능을 사용하여 날짜, 컨텍스트를 병합합니다. , 및 링크
zip 기능은 여러 목록을 하나의 목록으로 결합하고, 인덱스별로 나누어진 목록의 데이터를 튜플로 병합하여 팬더 객체를 생성할 수 있습니다.
dc = zip(dates, context, links) pdf = pd.DataFrame(dc, columns=['date', 'hotsearch', 'link'])
날짜는 시간 모듈을 사용하여 얻을 수 있습니다
둘: 데이터베이스 연결
매우 쉽습니다
enging = create_engine("mysql+pymysql://root:123456@localhost:3306/webo?charset=utf8")
pdf.to_sql(name='infromation', con=enging, if_exists="append")
전체 코드
from selenium.webdriver import Chrome, ChromeOptions
import time
from sqlalchemy import create_engine
import pandas as pd
def get_data():
url = r"https://s.weibo.com/top/summary" # 微博的地址
option = ChromeOptions()
option.add_argument('--headless')
option.add_argument("--no-sandbox")
browser = Chrome(options=option)
browser.get(url)
all = browser.find_elements_by_xpath('//*[@id="pl_top_realtimehot"]/table/tbody/tr/td[2]/a')
context = [i.text for i in all]
links = [i.get_attribute('href') for i in all]
date = time.strftime("%Y-%m-%d-%H_%M_%S", time.localtime())
dates = []
for i in range(len(context)):
dates.append(date)
# print(len(dates),len(context),dates,context)
dc = zip(dates, context, links)
pdf = pd.DataFrame(dc, columns=['date', 'hotsearch', 'link'])
# pdf.to_sql(name=in, con=enging, if_exists="append")
return pdf
def w_mysql(pdf):
try:
enging = create_engine("mysql+pymysql://root:123456@localhost:3306/webo?charset=utf8")
pdf.to_sql(name='infromation', con=enging, if_exists="append")
except:
print('出错了')
if __name__ == '__main__':
xx = get_data()
w_mysql(xx)
모두에게 도움이 되기를 바랍니다. 함께 발전하고 성장합시다. !
모두 새해 복 많이 받으세요! ! !
관련 무료 학습 권장 사항: python 튜토리얼(동영상)
위 내용은 Python은 Weibo 인기 검색어를 크롤링하고 이를 Mysql에 저장하는 것을 실현합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!